 pandas中合并数据的5个函数
pandas中合并数据的5个函数
今天借着这个机会,就为大家盘点一下pandas中合并数据的5个函数。
join
join是基于索引的横向拼接,如果索引一致,直接横向拼接。如果索引不一致,则会用Nan值填充。
索引一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[0, 1, 2])
x.join(y)
结果如下:

索引不一致
x = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=[0, 1, 2])
y = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=[1, 2, 3])
x.join(y)
结果如下:

merge
merge是基于指定列的横向拼接,该函数类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
pd.merge(x,y,how="left")
结果如下:

concat
concat函数既可以用于横向拼接,也可以用于纵向拼接。
纵向拼接
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
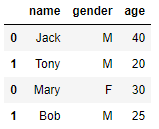
z = pd.concat([x,y],axis=0)
z
结果如下:
横向拼接
x = pd.DataFrame({'姓名': ['张三', '李四', '王五'],
'班级': ['一班', '二班', '三班']})
y = pd.DataFrame({'专业': ['统计学', '计算机', '绘画'],
'班级': ['一班', '三班', '四班']})
z = pd.concat([x,y],axis=1)
z
结果如下:

append
append主要用于纵向追加数据。
x = pd.DataFrame([['Jack','M',40],['Tony','M',20]], columns=['name','gender','age'])
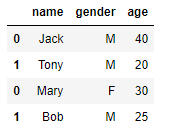
y = pd.DataFrame([['Mary','F',30],['Bob','M',25]], columns=['name','gender','age'])
x.append(y)
结果如下:
combine
conbine可以通过使用函数,把两个DataFrame按列进行组合。
x = pd.DataFrame({"A":[3,4],"B":[1,4]})
y = pd.DataFrame({"A":[1,2],"B":[5,6]})
x.combine(y,lambda a,b:np.where(a>b,a,b))
结果如下:

注:上述函数,用于返回对应位置上的最大值。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
数据
+关注
关注
8文章
7085浏览量
89228 -
函数
+关注
关注
3文章
4338浏览量
62770 -
索引
+关注
关注
0文章
59浏览量
10485
发布评论请先 登录
相关推荐
从Excel到Python-最常用的36个Pandas函数
本文涉及pandas最常用的36个函数,通过这些函数介绍如何完成数据生成和导入、数据清洗、预处理
Python工具pandas筛选数据的15个常用技巧
pandas是Python数据分析必备工具,它有强大的数据清洗能力,往往能用非常少的代码实现较复杂的数据处理 今天,总结了pandas筛选

盘点Pandas的100个常用函数
分析过程中,必然要做一些数据的统计汇总工作,那么对于这一块的数据运算有哪些可用的函数可以帮助到我们呢?具体看如下几张表。 import pandas

数据处理中pandas的groupby小技巧
pandas的groupby是数据处理中一个非常强大的功能。虽然很多同学已已经非常熟悉了,但有些小技巧还是要和大家普及一下的。为了给大家演示,我们采用一个公开的
分享pandas中超级好用的str矢量化字符串函数
的数据清洗方法,会让你的能力调高100倍。 本文基于此, 讲述pandas中超级好用的str矢量化字符串函数 ,学了之后,瞬间感觉自己的数据

解读12 种 Numpy 和 Pandas 高效函数技巧
本文分享给大家 12 种 Numpy 和 Pandas 函数,这些高效的函数会令数据分析更为容易、便捷。最后,读者也可以在 GitHub 项目中找到本文所用代码的 Jupyter No
超强图解Pandas,建议收藏
Pandas是数据挖掘常见的工具,掌握使用过程中的函数是非常重要的。本文将借助可视化的过程,讲解Pandas的各种操作。

如何使用Python和pandas库读取、写入文件
= pd.read_excel(' data .xlsx') 此代码中,我们首先导入 pandas 库并将其重命名为 pd。使用 pd.read_excel() 函数读取 'data.xlsx' 文件并将其存储在
Pandas:Python中最好的数据分析工具
使用 Pandas 分析数据的能力。 常见的比如说: 在处理货币值时使用货币符号。例如,如果您的数据包含值 25.00,您不会立即知道该值是人民币、美元、英镑还是其他某种货币。 百分比是另一个
Pandas函数的三个接口介绍
本文主要介绍pandas.DataFrame的三个接口,即assign、eval、query,分别用于赋值、查询和执行计算。 01 assign 在数据分析处理中,赋值产生新的列是非常






 工商网监
工商网监
评论