 借助亚马逊云科技大语言模型等多种服务打造下一代企业知识库
借助亚马逊云科技大语言模型等多种服务打造下一代企业知识库
背景
知识库需求在各行各业中普遍存在,例如制造业中历史故障知识库、游戏社区平台的内容知识库、电商的商品推荐知识库和医疗健康领域的挂号推荐知识库系统等。为保证推荐系统的实效性和准确性,需要大量的数据/算法/软件工程师的人力投入和包括硬件在内的物力投入。其次,为了进一步提高搜索准确率,如何引导用户搜索描述更加准确和充分利用用户行为优化搜索引擎也是常见的用户痛点。此外,如何根据企业知识库直接给出用户提问的答案也是众多企业中会遇见的技术瓶颈。
本文旨在介绍一些企业知识库的典型实用场景,以及如何使用智能搜索,结合大语言模型,针对企业知识库提供基于搜索的精准问答。
各行各业中有很多场景需要基于企业知识库进行搜索和问答
1.构建装备维护知识库和问答系统:使用历史维保记录和维修手册构建企业知识库,维修人员可依靠该知识库,快速地进行问题定位和维修。
2.构建IT/HR系统智能问答系统:使用企业内部IT/HR使用手册构建企业知识库,企业内部员工可通过该知识库快速解决在IT/HR上遇到的问题。
3.构建电商平台的搜索和问答系统:使用商品信息构建商品数据库,消费者可通过检索+问答的方式快速了解商品的详细信息。
4.构建游戏社区自动问答系统:使用游戏的信息(例如游戏介绍,游戏攻略等)构建社区知识库,可根据该知识库自动回复社区成员提供的问题。
5.构建智能客户聊天机器人系统:通过与呼叫中心/聊天机器人服务结合,可自动基于企业知识库就客户提出的问题进行聊天回复。
6.构建智能教育辅导系统:使用教材和题库构建不同教育阶段的知识库,模拟和辅助老师/家长对孩子进行教学。
为解决上述场景需求,可通过结合搜索和大语言模型的方式来实现。首先,可以利用企业自身积累的数据资产建立一个知识库。其次,对于特定的问答任务,可以使用搜索功能对知识库进行有效的召回,然后将召回的知识进行利用,增强大语言模型。通过这一方法,可以实现对问答任务的解决。
在企业知识库建立和搜索服务方面,亚马逊云科技拥有云端托管式搜索服务Amazon OpenSearch和基于AI/ML的智能企业搜索服务Amazon Kendra。虽然上述服务能够提供基本的搜索引擎和框架,解决了用户在硬件投入大和管理难的痛点,然而上述服务并且不能够满足基于文档的进行问答需求。为了解决用户需求和亚马逊云科技服务之间的差距,借助亚马逊云科技的服务,构建了基于智能搜索的大语言模型增强方案。该方案以Amazon OpenSearch/Amazon Kendra为基础构建搜索引擎,结合托管到Amazon SageMaker上的大语言模型,提供一站式的智能知识库搜索问答平台。
基于智能搜索的大语言模型增强方案介绍
架构图
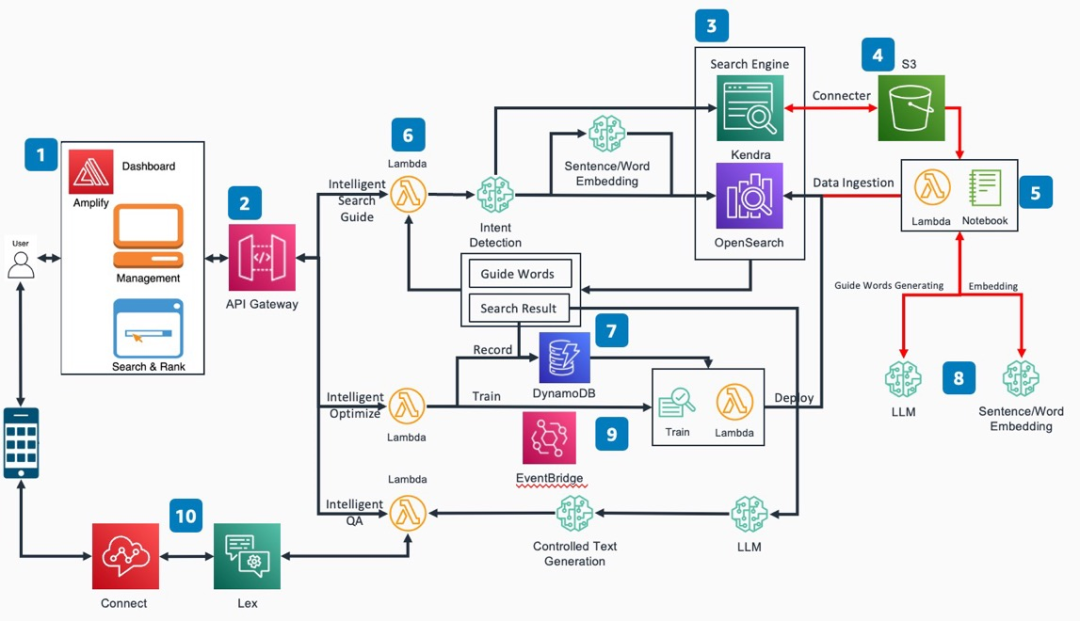
该平台将包括五大核心内容
1. 智能搜索
传统仅依靠关键词匹配的分词搜索的方式在很多场景下可以提供快速有效的查询,但是也存在一些固有的局限性。例如匹配一些包括停用词在内的无关词汇,无法识别同义词和缺乏抽象能力。为了解决这些问题,本方案中一方面使用意图识别模型,对关键信息进行提取,从而可以有效的避免停用词等无法词汇对搜索造成的干扰。另一方面,引入AI/ML的方法来辅助实现语意搜索。具体来讲,使用同一个向量编码的模型对搜索语句和文档数据库进行语意编码,在检索的过程中,使用knn方法进行向量匹配。以下是一个传统分词搜索与语意向量搜索的对比展示。可以看到,使用向量搜索功能后,可以召回更多自然语意上相近而关键词无关的内容,增加召回范围和提升搜索准确性。
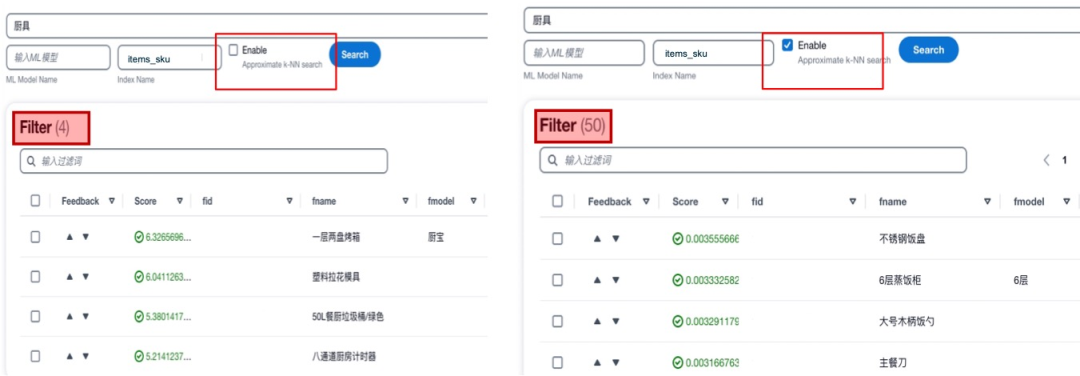
在本方案中,以Amazon OpenSearch和Amazon Kendra为基础构建搜索引擎。提供分词搜索,模糊查询和AI/ML辅助搜索功能。不在局限于某一种搜索方式,而是将所有搜索方法取长补短,进行有机的整合。
智能引导
造成搜索不准确的原因,一方面是由于搜索引擎本身的能力不足,另外一方面的原因是因为搜索的语句不够准确和具体。因此,本方案中提出了一种引导式的搜索机制来帮助检索人员逐步丰富输入的搜索语句,最终达到提升搜索准确性的目的。
以下面制造业大型设备维保知识库的搜索流程为例。该知识库存储历史维修记录,包括故障现象,故障原因,维修方案等字段。
当用户输入检索词“电路”后,除了从知识库中返回与电路相关的条目之外,还会给予一些提示词,例如“门系统”、“控制系统”等,这些词代表与“电路”相关的故障往往伴随可能出现问题的系统,提示用户进一步丰富当前的搜索描述。
当用户进一步输入“主板”后,会将“电路”和“主板”进行联合查询,返回相关的条目,并进一步给出新的提示词。
用户可以重复以上过程,直到搜索出来更为精准的结果。

提示词的获取:根据实际情况,可以采用人工打标、无监督聚类、有监督分类、大语言模型(LLM)等方法进行提取,并提前注入到数据库中。
智能优化
通常情况下,由于知识库的迭代更新,检索的准确率可能会随时时间的推荐逐步降低,一方面是因为我们往往不能保证,数据库和搜索引擎一次性构建完成后就达到很好的效果。另外一方面是因为对于过时的知识没有进行有效的处理。因此,本方案提出以用户行为对搜索引擎进行持续优化。
具体来讲包括两个步骤:
用户行为收集:将历史用户的行为进行收集,例如用户对某个搜索词条的打分。
模型训练和部署:通过用户行为,整理得到搜索词条和知识库之间的相关度。使用该相关度训练和部署一个重排模型,该重排模型可以根据历史的用户行为,给予用户更加偏好的内容更高的权重得分。
值得注意的是,该模型是基于传统机器学习模型xgboost的,所以所需要的训练数据量和推理所需要的资源都是很小的(例如只需要几十条数据和t3.small机型),因此可以基于不同的用户/用户群训练不同的重排模型,达到千人千面,个性化搜索的目的。
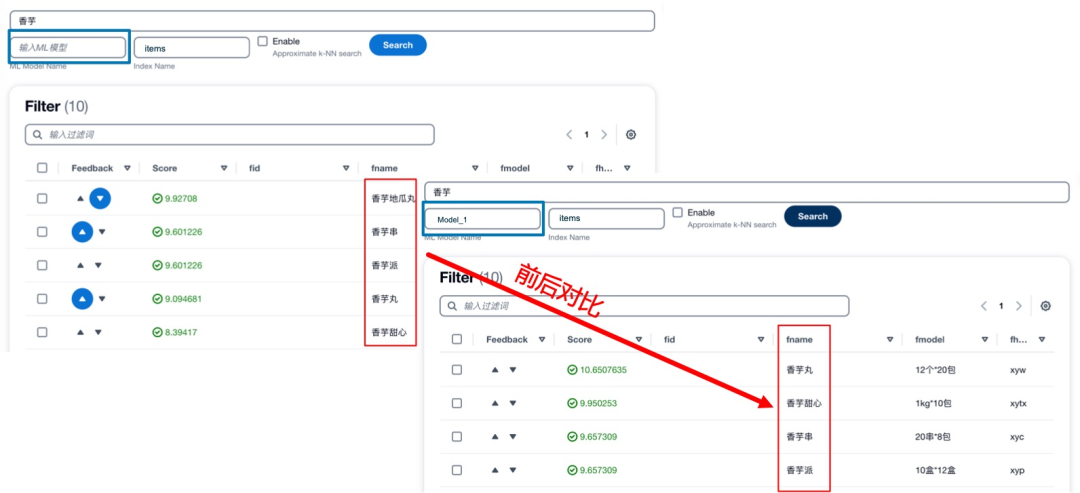
4.智能问答
基于私有知识库进行问答是另外一个广泛应用的场景,例如智能客户聊天机器人系统,IT/HR系统智能问答系统等。
如果仅使用搜索引擎,只能基于问题从数据库中提取与该问题相关的内容,而不能直接给出答案。
如果仅使用大语言模型(Large Language Model,LLM),不能基于私有知识库进行问答。一种可行的方式是将私有知识库和问题直接以prompt的形式直接一次性给到LLM,然后让LLM给出回答。但是受限于LLM Token的限制,无法一次性输入过多的知识库。
因此,在本方案中,将两者结合。如下图所示,当用户提出一个问题后,首先使用搜索提取与问题相关的知识,然后再将问题和提取的知识给到LLM进行总结,最后直接给出问题答案。
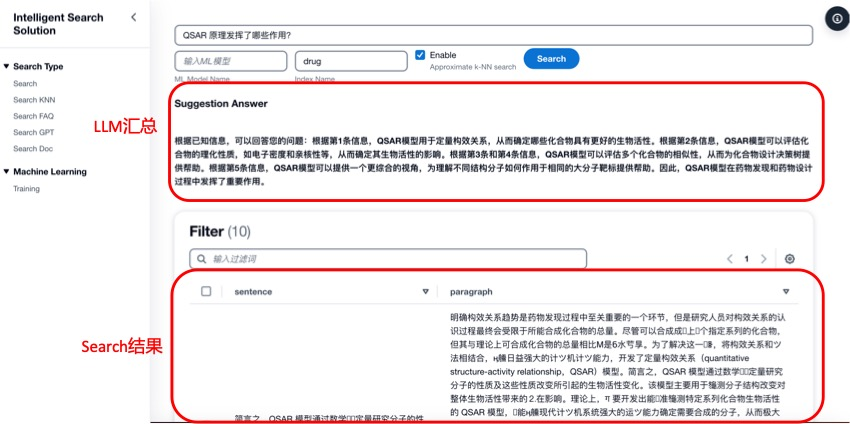
5. 非结构化数据注入
可供搜索引擎进行检索的企业知识库是一种结构化的数据,但往往企业的原始知识都是以非结构化的数据进行存储的,来自多个渠道,也包含了多种格式,例如Words,PDF,Excel等。
为了能够帮助企业快速将这些结构化数据利用起来,本方案提供了非结构化数据注入功能,该功能将企业的知识文档进行自动段落拆分和向量编码,建立结构化企业知识库。
模型技术细节
LLM
最近半年,大语言模型(LLM)在自然语言处理领域取得了飞速的发展。大语言模型通常基于Transformer架构,在大规模的网络文本数据上进行训练,其核心是使用一个自我监督的目标来预测部分句子中的下一个单词。亚马逊云科技已推出大语言模型Titan和大语言模型平台Amazon Bedrock,另外还有许多研究机构推出开源大语言模型,如斯坦福大学的Alpaca和清华大学的ChatGLM等。这些大语言模型都具备强大的文本处理能力,广泛应用在智能问答、文本总结、文本生成等场景。
Embedding
各类非结构化数据广泛存在于我们的生活和工作场景,如文本、图片、视频等,为了处理这些非结构化数据,亚马逊云科技通常使用Embedding模型提取这些数据的特征,并把数据特征转化成向量,通过特征向量对这些非结构化数据进行分析和检索。通用的预训练语言模型都有把文本进行向量化的功能,可以根据不同的场景和语种,选用合适的预训练模型作为Embedding模型。
Intent Detection
搜索意图识别主要功能是分析用户的核心搜索需求,例如在电商场景,用户找的电子产品,是电脑类的,还是手机类的,是家庭场景用的,还是户外场景用的等等,如果意图识别不准,会有很多不相关的商品展现给用户,导致产生非常差的用户体验,因此精准的意图识别非常重要。意图识别主要包括类目预测和实体识别模型,类目预测模型主要采用文本多分类模型,根据平台的用户行为数据,将查询文本预测属于各个类目的概率。实体识别模型将查询文本中的实体词识别出来,实体词是描述商品的维度信息,如品牌、颜色、材质等,通过实体识别模型识别出查询文本的实体词后,再到搜索引擎进行精准查询。
可控文本生成是在传统文本生成的基础上,增加对生成文本的控制,如指定生成文本的关键词、格式、风格等,从而使生成的文本符合我们的预期,比如生成与某人相同风格的文本,生成有固定内容格式的报告,根据简单的故事线生成完整的小说等等。可控文本生成有对预训练模型finetune、重新训练文本生成模型和重构预训练模型输出结果等方式。在大语言模型推出后,目前可以方便的通过Prompt提示词,指导大语言模型进行可控文本生成,针对不同的场景和文本生成目标,设计不同格式和内容的提示词,生成满足需求的文本。
审核编辑 黄宇
-
机器人
+关注
关注
212文章
28910浏览量
209651 -
AI
+关注
关注
87文章
32439浏览量
271617 -
数据库
+关注
关注
7文章
3868浏览量
65005 -
语言模型
+关注
关注
0文章
550浏览量
10423 -
亚马逊
+关注
关注
8文章
2687浏览量
83980
发布评论请先 登录
相关推荐
《AI Agent 应用与项目实战》阅读心得3——RAG架构与部署本地知识库
如何从零开始搭建企业AI知识库?

聚云科技荣获亚马逊云科技生成式AI能力认证
聚云科技荣获亚马逊云科技生成式AI能力认证 助力企业加速生成式AI应用落地
基于华为云 Flexus 云服务器 X 搭建部署——AI 知识库问答系统(使用 1panel 面板安装)

华为云 Flexus 云服务器 X 实例之 openEuler 系统下搭建 MaxKB 开源知识库问答系统
从零开始训练一个大语言模型需要投资多少钱?

【实操文档】在智能硬件的大模型语音交互流程中接入RAG知识库
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
北京灵奥科技基于亚马逊云科技打造大模型中间件
如何手撸一个自有知识库的RAG系统
英特尔集成显卡+ChatGLM3大语言模型的企业本地AI知识库部署





 工商网监
工商网监
评论