 Python 优化—算出每条语句执行时间
Python 优化—算出每条语句执行时间
用Python写的程序,确实在性能上会比其他语言差一些,这是因为Python为了最大化 开发效率 ,牺牲了一定的 运行效率 。开发效率和运行效率往往是鱼与熊掌不可兼得的关系。
不过,程序性能较差有很多原因,并不能全把锅甩到Python身上,我们应该首先从自己的代码上找原因,找原因最快的方法就是算出自己写的语句或函数的 执行时间 。这时候,很多人都会选择用以下的形式打印出语句的执行时间:
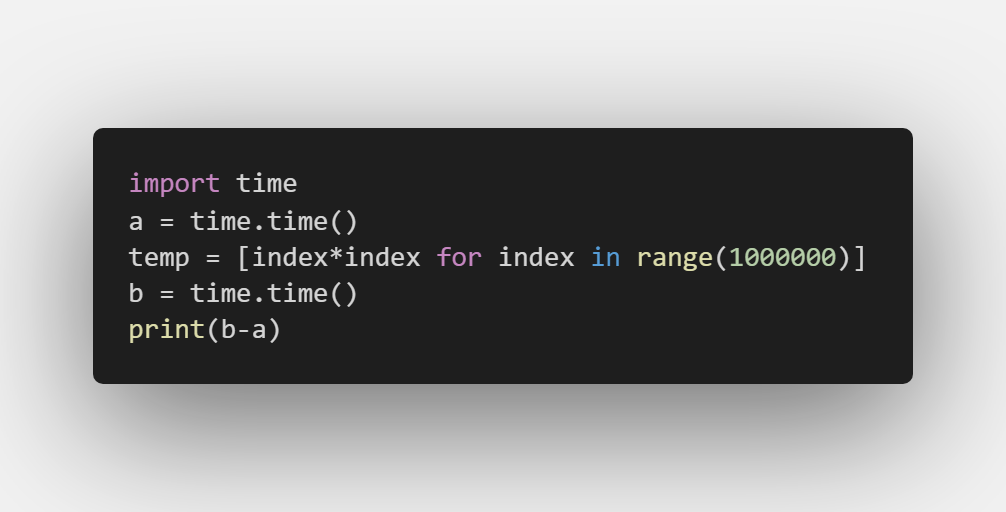
这是一种比较低效的做法,如果你有上万条语句要测试,想用这个方法来找到瓶颈简直是大海捞针。幸好,得益于Python强大的社区功能,我们有很多关于效率的模块可以使用,今天要介绍的是 line_profiler , 它可以算出函数里每条语句的占用时间。
我们将使用上次电影人脸识别中的代码进行讲解:Python 识别电影中的人脸,不过要注意,这篇推送里的函数少传递了几个参数,正确参数请点击该推送下方的阅读原文进行查看哦。
1.准备
Python环境当然是必备的,如果你还没有安装Python,可以看这篇文章:超详细Python安装指南。
打开cmd/terminal输入以下命令安装line_profile:
pip install line_profiler
windows机器如果出现 Microsoft Visual C++ 14.0 is required 这样的错误,请前往微软官网,下载vs2015勾选"适用于visual C++2015的公共工具" 进行安装。
如果出现:ModuleNotFoundError: No module named 'skbuild'的情况,请输入以下命令安装scikit-build:
pip install scikit-build
实在还是安装不上的话 ,可以下载anaconda,输入以下命令安装:
conda install -c anaconda line_profiler
2.使用
使用方式非常简单,比如原来我们在读取人脸的代码中,主函数是这样的:

我们要测的是read_pic_save_face函数中所有语句的执行时间,只需要这样调用line_profiler:

这样就可以获得该函数所有语句的执行时间报表。当然,它还有许多其他的调用方法,具体可以看line_profiler说明文档: *
https://github.com/rkern/line_profiler*
3.阅读报告
line_profiler报告包括几个部分:
Line: 语句位于第几行 **
Hits: 该行被执行的次数
Time: 该语句运行的总时间
Per Hit: 该语句运行一次的平均耗时
% Time: 该语句占总时间的比重**

可以看到,我们的这份代码主要是在face_cascade.detectMultiScale 耗时最久,这是opencv的分类器执行效率问题。知道了是这里的效率问题,优化就有一个目标了。
这一部分的优化,我们可以从硬件方面入手,让OpenCV在GPU上运行算法,这样做性能将远超在CPU上运行的性能,这是绝招。其次就是利用多线程计算(没试过,不确定是否有用,或许下次可以试一下)。
-
模块
+关注
关注
7文章
2747浏览量
47982 -
程序
+关注
关注
117文章
3801浏览量
81603 -
代码
+关注
关注
30文章
4851浏览量
69372 -
python
+关注
关注
56文章
4812浏览量
85186
发布评论请先 登录
相关推荐
如何计算AURIX微控制器指令执行时间?
嵌套循环执行时间计算
请问C2000中寻址结构体或者共同体需要的执行时间长吗?
如何计算执行时间
如何使用CYCLECOUNTER快速的测量执行时间?
如何在MCU上测量代码执行时间?
RTThread Studio该如何查看代码执行时间
MPC5744p如何优化程序执行时间?
如何测量ARM Cortex-M MCU代码的执行时间

MCU上的代码执行时间

使用STM32定时器测量程序执行时间的方法详解
TPT19新特性之最坏情况执行时间的指示






 工商网监
工商网监
评论