 NeurIPS 2023 | 如何从理论上研究生成式数据增强的效果?
NeurIPS 2023 | 如何从理论上研究生成式数据增强的效果?

代码链接:
https://github.com/ML-GSAI/Understanding-GDA

概述
生成式数据扩增通过条件生成模型生成新样本来扩展数据集,从而提高各种学习任务的分类性能。然而,很少有人从理论上研究生成数据增强的效果。为了填补这一空白,我们在这种非独立同分布环境下构建了基于稳定性的通用泛化误差界。基于通用的泛化界,我们进一步了探究了高斯混合模型和生成对抗网络的学习情况。
在这两种情况下,我们证明了,虽然生成式数据增强并不能享受更快的学习率,但当训练集较小时,它可以在一个常数的水平上提高学习保证,这在发生过拟合时是非常重要的。最后,高斯混合模型的仿真结果和生成式对抗网络的实验结果都支持我们的理论结论。

主要的理论结果
2.1 符号与定义
让 作为数据输入空间, 作为标签空间。定义 为 上的真实分布。给定集合 ,我们定义 为去掉第 个数据后剩下的集合, 为把第 个数据换成 后的集合。我们用 表示 total variation distance。
我们让 为所有从 到 的所有可测函数, 为学习算法,为从数据集 中学到的映射。对于一个学到的映射 和损失函数,真实误差 被定义为。相应的经验的误差 被定义为。
我们文章理论推导采用的是稳定性框架,我们称算法 相对于损失函数 是一致 稳定的,如果
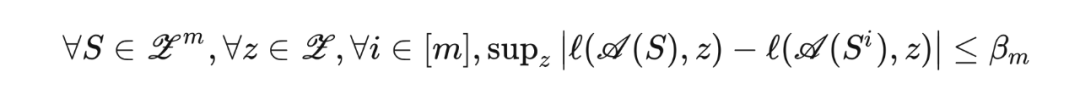
2.2 生成式数据增强
给定带有 个 i.i.d. 样本的 数据集,我们能训练一个条件生成模型 ,并将学到的分布定义为 。基于训练得到的条件生成模型,我们能生成一个新的具有 个 i.i.d. 样本的数据集 。我们记增广后的数据集 大小为 。我们可以在增广后的数据集上学到映射 。为了理解生成式数据增强,我们关心泛化误差 。据我们所知,这是第一个理解生成式数据增强泛化误差的工作。2.3 一般情况
我们可以对于任意的生成器和一致 稳定的分类器,推得如下的泛化误差: ▲ general一般来说,我们比较关心泛化误差界关于样本数 的收敛率。将 看成超参数,并将后面两项记为 generalization error w.r.t. mixed distribution,我们可以定义如下的“最有效的增强数量”:
▲ general一般来说,我们比较关心泛化误差界关于样本数 的收敛率。将 看成超参数,并将后面两项记为 generalization error w.r.t. mixed distribution,我们可以定义如下的“最有效的增强数量”:


▲ corollary
2.4 高斯混合模型为了验证我们理论的正确性,我们先考虑了一个简单的高斯混合模型的 setting。 混合高斯分布。我们考虑二分类任务 。我们假设真实分布满足 and 。我们假设 的分布是已知的。 线性分类器。我们考虑一个被 参数化的分类器,预测函数为 。给定训练集, 通过最小化负对数似然损失函数得到,即最小化
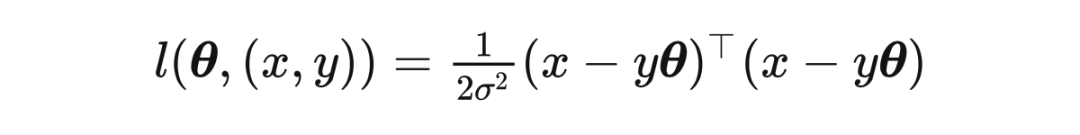
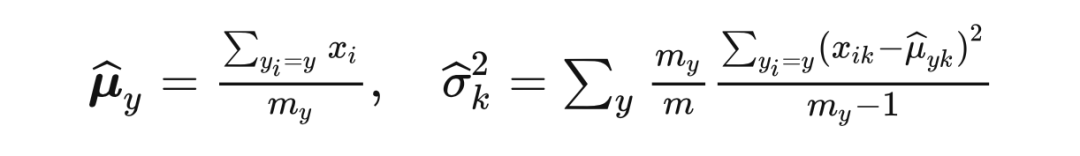

- 当数据量 足够时,即使我们采用“最有效的增强数量”,生成式数据增强也难以提高下游任务的分类性能。
- 当数据量 较小的,此时主导泛化误差的是维度等其他项,此时进行生成式数据增强可以常数级降低泛化误差,这意味着在过拟合的场景下,生成式数据增强是很有必要的。
2.5 生成对抗网络
我们也考虑了深度学习的情况。我们假设生成模型为 MLP 生成对抗网络,分类器为 层 MLP 或者 CNN。损失函数为二元交叉熵,优化算法为 SGD。我们假设损失函数平滑,并且第 层的神经网络参数可以被 控制。我们可以推得如下的结论:

- 当数据量 足够时,生成式数据增强也难以提高下游任务的分类性能,甚至会恶化。
- 当数据量 较小的,此时主导泛化误差的是维度等其他项,此时进行生成式数据增强可以常数级降低泛化误差,同样地,这意味着在过拟合的场景下,生成式数据增强是很有必要的。

实验
3.1 高斯混合模型模拟实验
我们在混合高斯分布上验证我们的理论,我们调整数据量 ,数据维度 以及 。实验结果如下图所示:
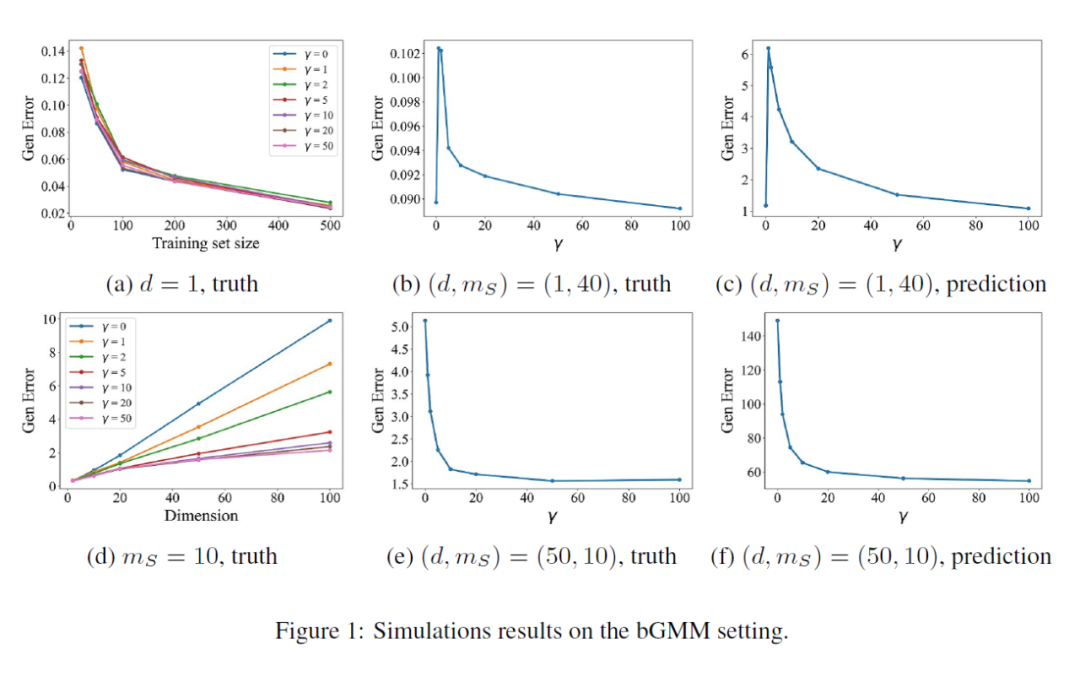
▲ simulation
- 观察图(a),我们可以发现当 相对于 足够大的时候,生成式数据增强的引入并不能明显改变泛化误差。
- 观察图(d),我们可以发现当 固定时,真实的泛化误差确实是 阶的,且随着增强数量 的增大,泛化误差呈现常数级的降低。
- 另外 4 张图,我们选取了两种情况,验证了我们的 bound 能在趋势上一定程度上预测泛化误差。
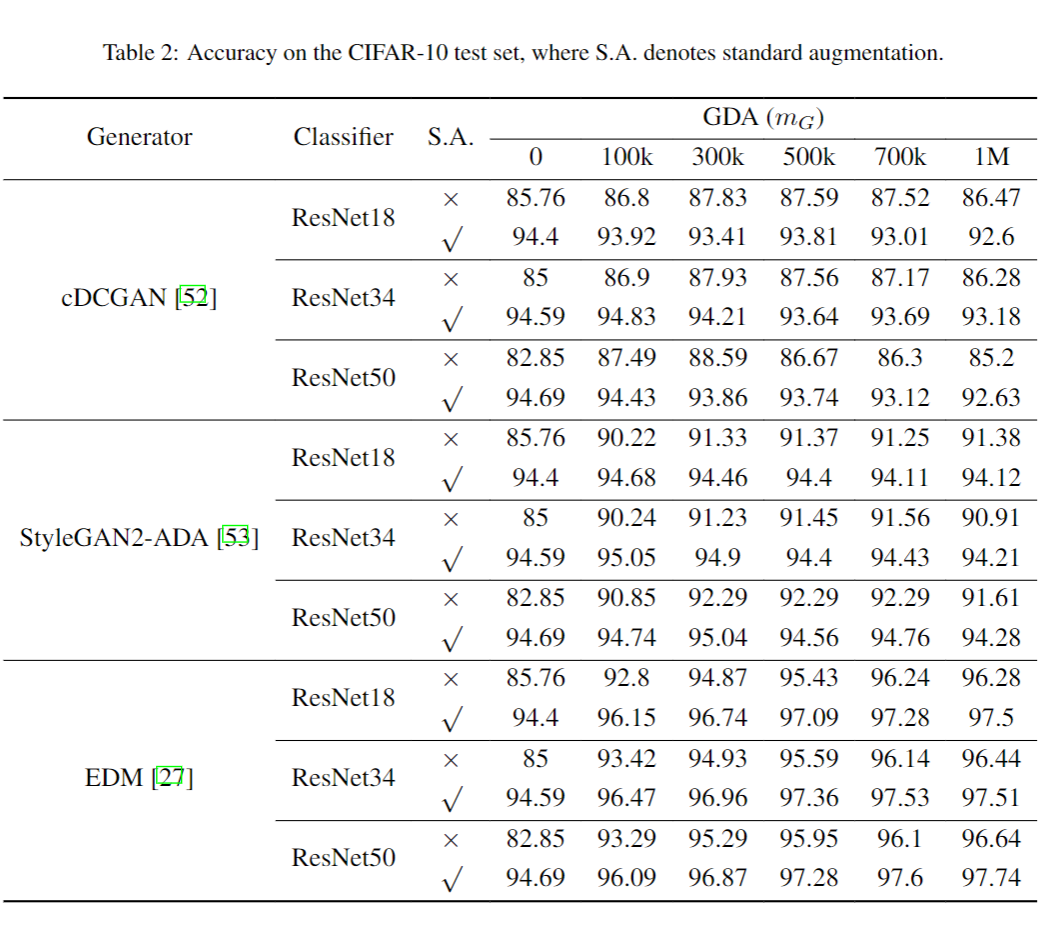
▲ deep
- 在没有额外数据增强的时候, 较小,分类器陷入了严重的过拟合。此时,即使选取的 cDCGAN 很古早(bad GAN),生成式数据增强都能带来明显的提升。
- 在有额外数据增强的时候, 充足。此时,即使选取的 StyleGAN 很先进(SOTA GAN),生成式数据增强都难以带来明显的提升,在 50k 和 100k 增强的情况下甚至都造成了一致的损害。
-
我们也测试了一个 SOTA 的扩散模型 EDM,发现即使在有额外数据增强的时候,生成式数据增强也能提升分类效果。这意味着扩散模型学习分布的能力可能会优于 GAN。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2911文章
44849浏览量
375373
原文标题:NeurIPS 2023 | 如何从理论上研究生成式数据增强的效果?
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
检索增强型生成(RAG)系统详解
流畅且类似人类的文本方面表现出色,但它们有时在事实准确性上存在困难。当准确性非常重要时,这可能是一个巨大的问题。 那么,这个问题的解决方案是什么呢?答案是检索增强型生成(RAG)系统。 RAG集成了像GPT这样的模型的强大功能,
ADS9234R的采样速率理论上是多少,在正常设计中是否还会降低?
请问,传统四线SPI的情况下,在一区传输模式中,利用MCU(SPI给的60MHZ最大;MCU主频480MHZ),它的采样速率理论上是多少,在正常设计中是否还会降低?
发表于 11-13 06:04
生成式AI工具作用
生成式AI工具是指那些能够自动生成文本、图像、音频、视频等多种类型数据的人工智能技术。在此,petacloud.ai小编为您整理生成
运放THS4551理论上输入是线性的,DC扫描,输出也是线性的,为什么我们的输出不是线性的?
运放THS4551 理论上输入是线性的,DC扫描,输出也是线性的,为什么我们的输出不是线性的?是哪里存在问题吗?请帮忙解决,谢谢
发表于 08-15 07:20
如何用C++创建简单的生成式AI模型
生成式AI(Generative AI)是一种人工智能技术,它通过机器学习模型和深度学习技术,从大量历史数据中学习对象的特征和规律,从而能够生成
请问移动端生成式AI如何在Arm CPU上运行呢?
2023 年,生成式人工智能 (Generative AI) 领域涌现出诸多用例。这一突破性的人工智能 (AI) 技术是 OpenAI 的 ChatGPT 和 Google 的 Gemini AI 模型的核心

Bria利用NVIDIA NeMo和Picasso为企业打造负责任的生成式AI
随着视觉生成式 AI 从研究阶段迈入到商用阶段,企业正在寻求负责任的方式来将这项技术集成到其产品中。
检索增强生成(RAG)如何助力企业为各种企业用例创建高质量的内容?
在生成式 AI 时代,机器不仅要从数据中学习,还要生成类似人类一样的文本、图像、视频等。检索增强生成(RAG)则是可以实现的一种突破性方法。
NVIDIA生成式AI研究实现在1秒内生成3D形状
NVIDIA 研究人员使 LATTE3D (一款最新文本转 3D 生成式 AI 模型)实现双倍加速。

商汤集团2023全年业绩亮眼,生成式AI业务爆发式增长
商汤集团近日发布了截至2023年12月31日的经审核全年业绩报告,展现了集团在AI领域的强劲增长势头。在全新的战略布局下,商汤明确了三大业务板块:生成式AI、传统AI和智能汽车,并以生成
生成式 AI 制作动画:周期短、成本低!
电子发烧友网报道(文/李弯弯)生成式AI在动画市场中的应用正在迅速崛起。根据市场机构数据,预计到2023年生成

名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
。
为了使更多的自然语言处理研究人员和对大语言模型感兴趣的读者能够快速了解大模型的理论基础,并开展大模型实践,复旦大学张奇教授团队结合他们在自然语言处理领域的研究经验,以及分布式系统和
发表于 03-11 15:16
请问下stm32G0系列理论上的外部中断响应时间是多少?
大佬们,请问下stm32G0系列理论上的外部中断响应时间是多少?我在spec里面没有找到对这块的详细描述,只有如下描述;
看之前的帖子stm32F103的外部中断响应时间是12个时钟周期,实际上应该会比这个时间长,G0也是一样的吗?
发表于 03-08 07:41
生成式人工智能和感知式人工智能的区别
生成新的内容和信息的人工智能系统。这些系统能够利用已有的数据和知识来生成全新的内容,如图片、音乐、文本等。生成式人工智能通常基于深度学习技术





 工商网监
工商网监
评论