 上线一周就2.1k star!单张图像直接转为3D模型!
上线一周就2.1k star!单张图像直接转为3D模型!
0. 笔者个人体会
提问:给你一张2D图像,要求获得完整的三维模型,你会怎么做?
我第一反应是拿SolidWorks自己画一个~
最近就看到了这样的一项开源工作Wonder3D,可以直接从2D图像生成3D模型,感觉很神奇。读了读文章,发现这项工作是基于扩散模型实现的,这里也不得不感叹扩散模型确实在AI绘画和图像生成领域有无限前景。今天笔者也将带领读者阅读一下这项工作,当然笔者水平有限,如果有理解不当的地方欢迎大家一起探讨,共同学习。
1. 效果展示
Wonder3D仅需2~3分钟即可从单视图图像重建高细节纹理网格。Wonder3D首先通过跨域扩散模型生成一致的多视法线图与相应的彩色图像,然后利用一种法线融合方法来实现快速和高质量的重建。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。

对不同风格的图像也都适用。

甚至对各种小动物也适用:
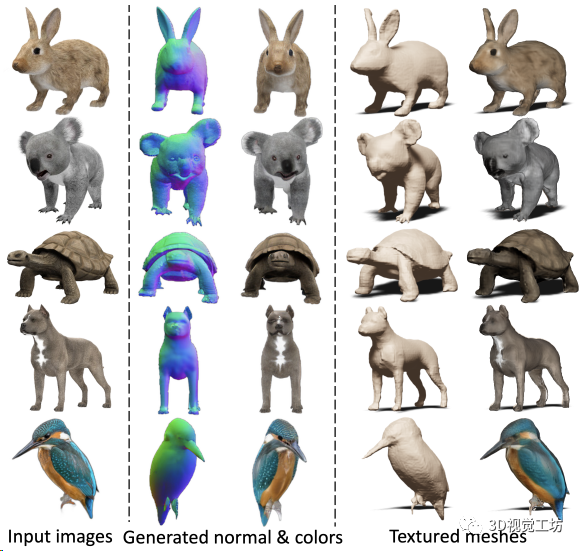
代码已经开源了,而且他们的官方主页还放上了Live Demo的链接,感兴趣的读者可以上传自己的图像来尝试,下面展示一下笔者自己的测试结果。
原始图像:

生成的多视角图像:

2. 摘要
在这篇文章中,我们介绍了Wonder3D,一种从单视图图像中高效生成高保真纹理网格的新方法。基于分数蒸馏采样(SDS)的最近方法已经显示出从2D扩散先验恢复3D几何形状的潜力,但是它们通常遭受每个形状优化的耗时和不一致的几何形状。相比之下,某些作品通过快速网络推理直接产生3D信息,但其结果通常质量较低且缺乏几何细节。为了从整体上提高图像到3D任务的质量、一致性和效率,我们提出了一种跨域扩散模型来生成多视图法线贴图和相应的彩色图像。为了确保一致性,我们采用了一种多视图跨域关注机制,该机制有助于跨视图和模态的信息交换。最后,我们介绍了一种几何感知法向融合算法,从多视图2D表示中提取高质量的表面。我们的大量评估表明,与先前的工作相比,我们的方法实现了高质量的重建结果、鲁棒的泛化以及相当好的效率。
3. 算法解析
先让我们重新审视一下这个问题:
给定单张图像,绘制其三维模型。
传统方法会怎么做呢?
使用SLAM或SfM?单张图像做初始化都不够。
使用MVS方法?没有多视角图像就没有视差图。
用NeRF?最吃数据了,视角大一点都不行。
直接训模型学习?思路上可以,实操起来效果非常差。
这个任务本身就非常反人类,因为只有一个视角,没有先验信息谁也不知道完整的三维模型长什么样。
那怎么做呢?
这篇文章的思路很巧妙,没有像NeRF那样直接从2D图像生成3D模型,而是先用扩散模型生成多个视角的2D图像和法线图,再融合生成3D模型。
这么做有啥好处呢?
最大的好处就是可以直接利用Stable Diffusion这种经过数十亿张图像训练过的2D扩散模型,实际上相当于引入了非常强的先验信息。而且法线图可以表征物体的起伏和表面几何信息,进而计算3D模型的高保真几何元素。
这样,整个任务就变为了建立一个马尔科夫链,然后从中采样颜色和法线信息的过程。
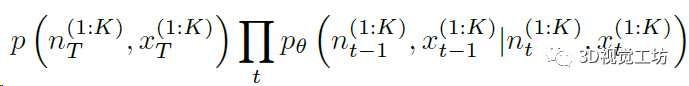
其中p代表高斯噪声,n代表法线图,x代表RGB图,K代表图像数量。
不太对,扩散模型只能处理一个域,怎么出来RGB和法线两个域了?
的确是这样,最直观的改动思路就是给扩散模型添加一个头,重新训练模型,直接输出RGB和法线信息,这也是前两年多任务网络的常用做法。但是实际操作过程中会发现收敛很慢,而且泛化性差。
另一个思路是直接训练两个扩散模型,但这样不光增加了计算量,还会导致性能下降。
Wonder3D的做法是设计了一个域转换器(Domain Switcher),实际上是一个标注域信息的一维向量。域转换器先做位置编码,聚合时间embedding信息,再把它也输送给扩散模型,就可以让扩散模型同时处理两个域的信息。
这一点可以先放一个定性对比图来观察:
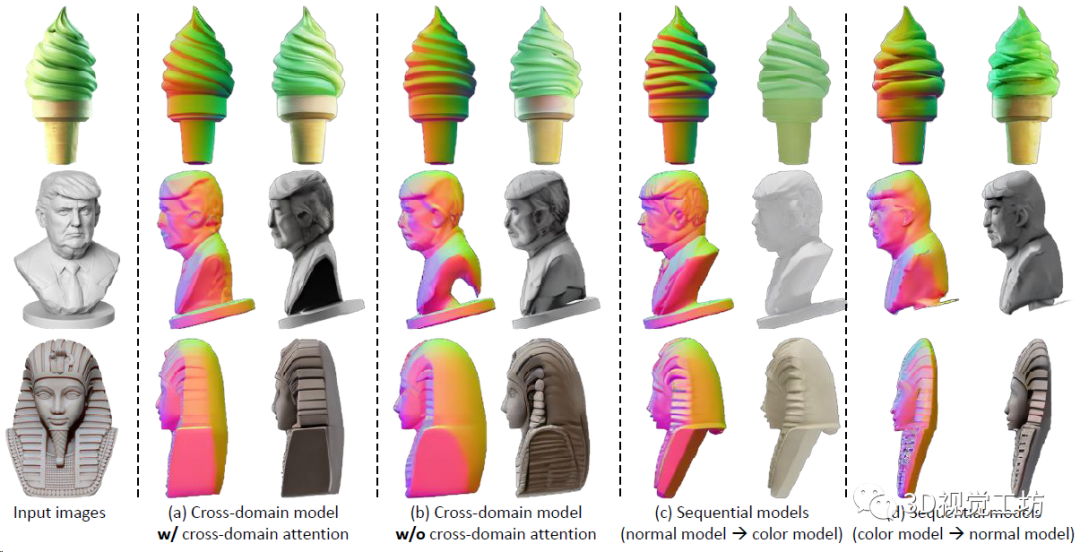
还有问题,RGB和法线是独立生成的,多视角的RGB图也未必就几何一致。
在这里,Wonder3D引入了一个注意力机制,分别处理多个时间RGB几何不一致的问题,以及RGB和法线图的关联问题。
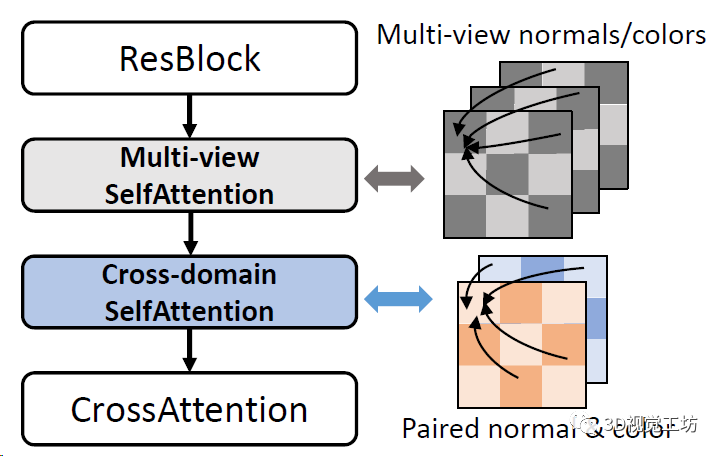
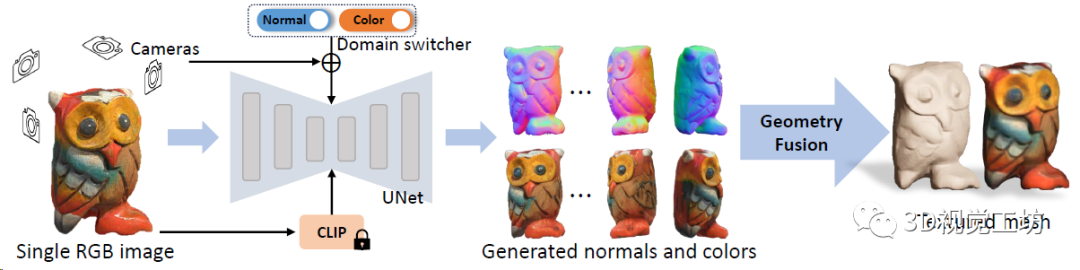
到这里,Wonder3D具体的Pipeline就出来了:
输入一幅图像,Wonder3D取原始图像、CLIP产生的文本embedding、多视角相机参数,以及一个域转换器作为条件,生成一致的多视点法线图和彩色图。随后,Wonder3D借助法线融合算法,将2D表征重建为高质量的3D几何图形,产生高保真的纹理网格。
最后再看看这个几何融合是怎么做的:
Wonder3D是优化神经隐式SDF场,来从匹配的RGB和法线图中提取完整的三维信息。
刚才不是说NeRF需要稠密的图像序列吗?
如果直接做NeRF-SDF重建的话,误差非常大,并且会一直累计下去。Wonder3D的做法是引入了一系列损失函数来约束优化:
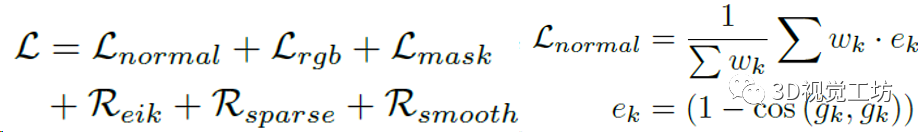
4. 实验
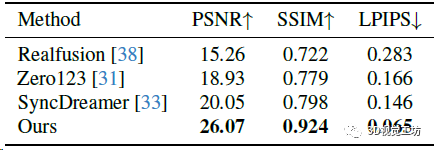
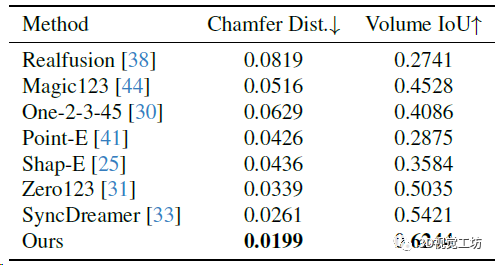
训练数据集是LVIS子集,batch size是512,在8块A800上训练了3天(果然普通人还是玩不起)。从2D图像生成3D模型的方法还是用的Instant NGP(论NeRF在各个领域的入侵haaaaa)。评估使用Google Scanned Object数据集。评估指标方面,3D重建用Chamfer Distances (CD)和Volume IoU,生成图像质量用PSNR、SSIM、LPIPS这几个常见指标。对比的方案也都是目前的SOTA,包括Zero123、RealFusion、Magic123、One-2-3-45、Point-E、Shap-E、SyncDreamer这些。
新视点合成对比,Zero 123缺乏多视图一致性,SyncDreamer对输入图像的仰角比较敏感,但是Wonder3D生成具有语义一致性和几何一致性的图像。这里也推荐「3D视觉工坊」新课程《彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进》。

新视点合成的定量对比。
3D重建质量的对比,Shape-E的重建结果不完整且扭曲。SyncDreamer的重建结生成图像大致对齐,但纹理质量不好。相比之下Wonder3D实现几何和纹理上最高的重建质量。

3D重建的定量对比。
最后3D生成模型中各项损失函数的消融实验,验证损失函数的必要性:

还是一个消融实验,验证多视图几何一致性和RGB-法线对其的注意力机制的作用:

5. 总结
本文为各位读者介绍了Wonder3D,可以从单张图像直接生成完整的三维模型,整个模型的设计思路很巧妙,而且也开源。渲染速度也达到了2~3分钟,这项工作的应用也很广泛,建图、VR、AR、动画、影视等等都可以用。感觉Wonder3D还是很神奇的,有点长见识了。
-
3D
+关注
关注
9文章
2926浏览量
108364 -
图像
+关注
关注
2文章
1091浏览量
40669 -
模型
+关注
关注
1文章
3406浏览量
49457
原文标题:上线一周就2.1k star!单张图像直接转为3D模型!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
腾讯混元3D AI创作引擎正式发布
腾讯混元3D AI创作引擎正式上线
AN-1249:使用ADV8003评估板将3D图像转换成2D图像

uvled光固化3d打印技术

淘宝携手Rokid上线3D购物新体验
安宝特产品 安宝特3D Analyzer:智能的3D CAD高级分析工具
安宝特产品 3D Evolution : 基于特征实现无损CAD格式转换
欢创播报 腾讯元宝首发3D生成应用

裸眼3D笔记本电脑——先进的光场裸眼3D技术
烘焙vs渲染:3D模型制作中的效率与质量之争






 工商网监
工商网监
评论