 英伟达H100的最强替代者
英伟达H100的最强替代者
在我们(指代servethehome)撰写本文时,NVIDIA H100 80GB PCIe 在 CDW 等在线零售商处的售价为 3.2 万美元,并且缺货了大约六个月。可以理解的是,NVIDIA 的高端(几乎)万能 GPU 的价格非常高,需求也是如此。NVIDIA 为许多人工智能用户和那些在企业中运行混合工作负载的用户提供了一种替代方案,但这种方案并不引人注目,但这是非常好的。NVIDIA L40S 是面向图形的 L40 的变体,它正迅速成为人工智能领域最保守的秘密。让我们深入了解原因。
NVIDIA A100、NVIDIA L40S 和 NVIDIA H100
首先,我们首先要说的是,如果您现在想要训练基础模型(例如 ChatGPT),那么 NVIDIA H100 80GB SXM5 仍然是首选 GPU。一旦基础模型经过训练,通常可以在成本和功耗显着降低的部件上根据特定领域的数据或推理来定制模型。
NVIDIA H100
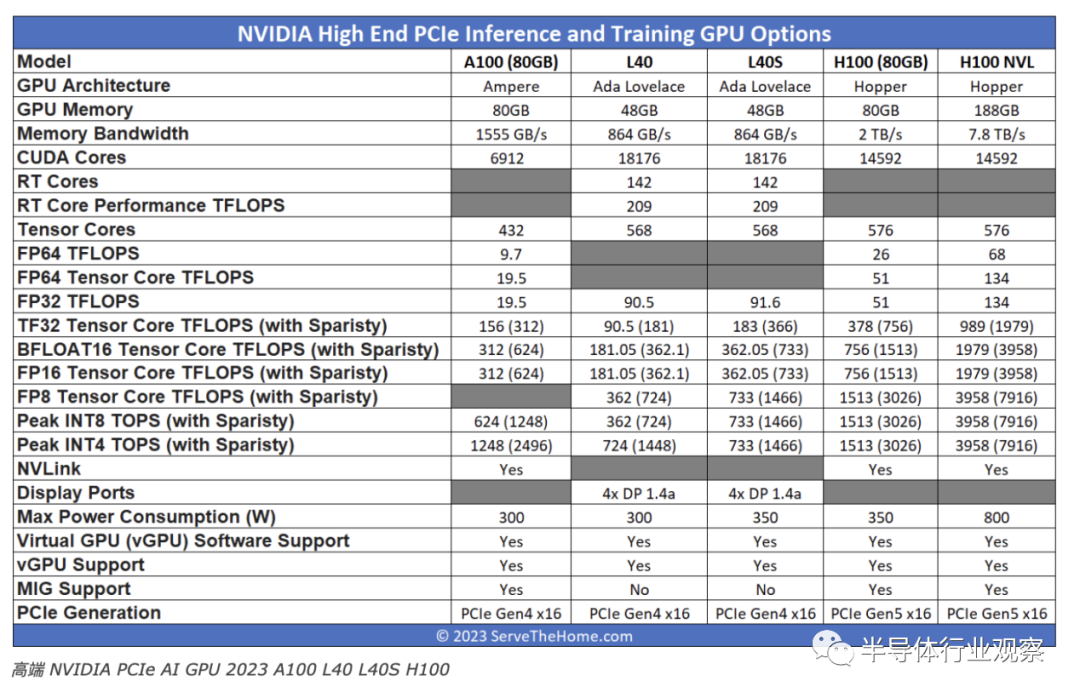
目前,用于高端推理的 GPU 主要有三种:NVIDIA A100、NVIDIA H100 和新的 NVIDIA L40S。我们将跳过NVIDIA L4 24GB,因为它更像是低端推理卡。
NVIDIA H100 L40S A100 堆栈顶部
NVIDIA A100 和 H100 型号基于该公司各自代的旗舰 GPU。由于我们讨论的是 PCIe 而不是 SXM 模块,因此外形尺寸之间两个最显着的差异是 NVLink 和功耗。SXM 模块专为更高功耗而设计(大约是 PCIe 版本的两倍),并通过 NVLink 和多 GPU 组件中的 NVSwitch 拓扑进行互连。
NVIDIA A100 PCIe于 2020 年以 40GB 型号推出,然后在 2021 年中期,该公司将产品更新为A100 80GB PCIe 附加卡。多年后,这些卡仍然很受欢迎。
NVIDIA A100 80GB PCIe
NVIDIA H100 PCIe是专为主流服务器设计的低功耗 H100。考虑 PCIe 卡的一种方法是,在电压/频率曲线的不同部分运行相似数量的芯片,旨在降低性能,但功耗也低得多。
NVIDIA H100 型号和 NVLink
即使在 H100 系列内也存在一些差异。NVIDIA H100 PCIe 仍然是 H100,但在 PCIe 外形规格中,它降低了性能、功耗和一些互连(例如 NVLink 速度)。
L40S 则完全不同。NVIDIA 采用了基础 L40(一款使用 NVIDIA 最新 Ada Lovelace 架构的数据中心可视化 GPU),并更改了调整,使其更多地针对 AI 而不是可视化进行调整。
NVIDIA L40S 是一款令人着迷的 GPU,因为它保留了 L40 的光线追踪核心和 DisplayPort 输出以及支持 AV1 的 NVENC / NVDEC 等功能。与此同时,NVIDIA 将更多的功率用于驱动 GPU 人工智能部分的时钟。
NVIDIA L40S 4x DisplayPort
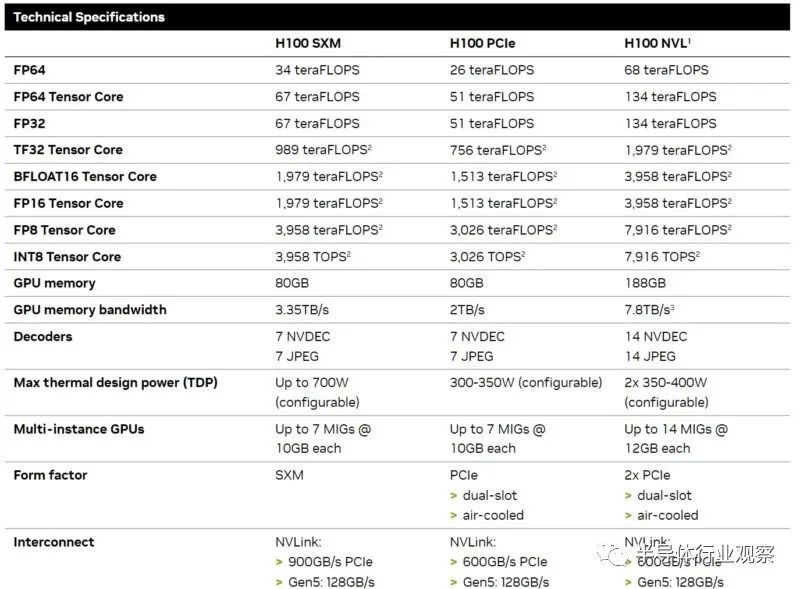
我们将其放在图表上以便更容易可视化。NVIDIA 的规格有时甚至会根据 NVIDIA 来源单一视图而有所不同,因此这是我们能找到的最好的规格,如果我们获得规格更新,我们将对其进行更新。我们还包括双卡H100 NVL,它有两个增强型 H100,它们之间有一个 NVLink 桥,因此将其视为双卡解决方案,而其余的都是单卡。
这里有几点值得关注:
与 L40 相比,L40S 是一款在人工智能训练和推理方面大幅改进的卡,但人们可以很容易地看到共同的传统。
如果您需要绝对的内存容量、带宽或 FP64 性能,则 L40 和 L40S 不适合。鉴于目前 AI 工作负载取代传统 FP64 计算的相对份额,大多数人都会接受这种权衡。
L40S 的内存看起来可能比 NVIDIA A100 少得多,而且物理上确实如此,但这并不是故事的全部。NVIDIA L40S 支持NVIDIA Transformer Engine和 FP8。使用 FP8 可以极大地减小数据大小,因此,与 FP16 值相比,FP8 值可以使用更少的内存,并且需要更少的内存带宽来移动。NVIDIA 正在推动 Transformer Engine,因为 H100 也支持它,有助于降低其 AI 部件的成本或提高其性能。
L40S 有一组更注重可视化的视频编码/解码,而 H100 则专注于解码方面。
NVIDIA H100 速度更快。它还花费更多。从某种意义上说,在我们撰写本文时,在列出公开价格的 CDW 上,H100 的价格约为 L40S 价格的 2.6 倍。
另一个重要问题是可用性。如今,获得 NVIDIA L40S 比排队等待 NVIDIA H100 快得多。
秘密在于,在 AI 硬件方面取得领先的一种新的常见方法是不使用 H100 进行模型定制和推理。相反,我们又回到了我们多年前介绍过的熟悉的架构,即密集 PCIe 服务器。2017 年,当我们进行DeepLearning11 时,将 NVIDIA GeForce GTX 1080 Ti 塞进服务器中的 10 倍 NVIDIA GTX 1080 Ti 单根深度学习服务器甚至是大公司(例如世界某些地区的搜索/网络超大规模企业)的首选架构驾驶公司。
NVIDIA 更改了其 EULA,禁止此类配置,并且使其软件更加关注用于 AI 推理和训练的数据中心部分,因此现在情况有所不同。
到 2023 年,考虑同样的概念,但采用 NVIDIA L40S 技术(并且没有服务器“humping”。)
通过购买 L40S 服务器并获得比使用 H100 更低成本的 GPU,人们可以获得类似的性能,而且价格可能更低。
NVIDIA L40S 与 H100 的其他考虑因素
L40S 还有其他几个方面需要考虑。一是它支持NVIDIA Virtual GPU vGPU 16.1,而 H100 仍然只支持 vGPU 15。NVIDIA 正在将其 AI 芯片从 vGPU 支持方面进行一些拆分。

对于那些想要部署一种 GPU 机器然后能够运行不同类型的工作负载的人来说,像 L40S 这样的东西是有意义的。鉴于其可视化根源,它还拥有支持 AV1 和 RT 内核的 NVIDIA 视频编码引擎。
L40S 不支持一项功能,那就是 MIG。我们之前已经研究过 MIG,但它允许将 H100 分成最多 7 个不同大小的分区。这对于在公共云中拆分 H100 GPU 非常有用,以便可以在客户之间共享 GPU 资源。对于企业来说,这通常是一个较低兴奋度的功能。
此外,部署 L40S 的功耗较低,仅为 SXM5 系统功耗的一半。这对于那些想要横向扩展但每个机架可能没有大量电力预算的人来说非常有吸引力。
最重要的是,L40S 的速度不如 H100,但凭借 NVIDIA 的 FP8 和 Transformer Engine 支持,对于许多人来说,它比 H100 更可用、更容易部署,而且通常价格更低。
最后的话
关于 NVIDIA H100 PCIe 与 L40S 以及为什么人们会使用任一版本,目前有很多非常糟糕的信息。希望这有助于在更大程度上澄清这一点。对我们来说,L40S 并不便宜,但它让我们想起 6 多年前,当时人工智能领域的做法是在服务器中使用成本较低的 NVIDIA GPU,然后使用更多的 GPU。NVIDIA 再次推出该型号,使用 L40S 和官方认可的架构,支持多达数千个 GPU。
-
NVIDIA
+关注
关注
14文章
4935浏览量
102801 -
gpu
+关注
关注
28文章
4700浏览量
128694 -
PCIe
+关注
关注
15文章
1217浏览量
82434
原文标题:英伟达H100的最强替代者
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英伟达H100芯片市场降温
英伟达或取消B100转用B200A代替
首批1024块H100 GPU,正崴集团将建中国台湾最大AI计算中心
英伟达芯片“倒爷”风光不再,市场热度降温
英特尔的最强AI芯片要来了,声称性能完胜英伟达H100
英伟达H200带宽狂飙
英伟达H200显卡价格
英伟达:预计下一代AI芯片B100短缺,计划扩产并采用新架构
AI计算需求激增,英伟达H100功耗成挑战
AMD正式发布 MI300X AI 加速器,力压英伟达H100

英伟达H100 GPU Q3售出50万块,科技巨头争抢





 工商网监
工商网监
评论