 基于高度感知的鸟瞰图分割和神经地图的重定位
基于高度感知的鸟瞰图分割和神经地图的重定位

ICCV2023 SOTA U-BEV:基于高度感知的鸟瞰图分割和神经地图的重定位
论文标题:U-BEV: Height-aware Bird's-Eye-View Segmentation and Neural Map-based Relocalization
论文链接:https://arxiv.org/abs/2310.13766
1. 本文概览
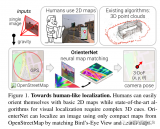
高效的重定位对于GPS信号不佳或基于传感器的定位失败的智能车辆至关重要。最近,Bird’s-Eye-View (BEV) 分割的进展使得能够准确地估计局部场景的外观,从而有利于车辆的重定位。然而,BEV方法的一个缺点是利用几何约束需要大量的计算。本文提出了U-BEV,一种受U-Net启发的架构,通过在拉平BEV特征之前对多个高度层进行推理,扩展了当前的最先进水平。我们证明了这种扩展可以提高U-BEV的性能高达4.11%的IoU。此外,我们将编码的神经BEV与可微分的模板匹配器相结合,在神经SD地图数据集上执行重定位。所提出的模型可以完全端到端地进行训练,并在nuScenes数据集上优于具有相似计算复杂度的基于Transformer的BEV方法1.7到2.8%的mIoU,以及基于BEV的重定位超过26%的召回率。
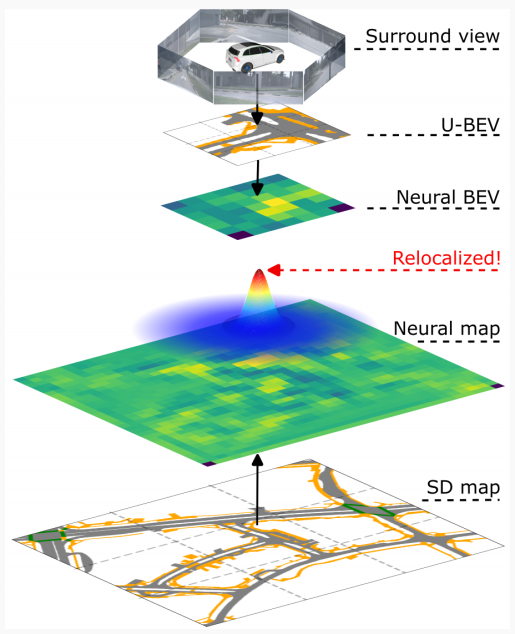
图1:,U-BEV 提出了一种新的环境图像 BEV 表示方法,在 SD 地图数据中实现了高效的神经重定位。
2. 方法详解
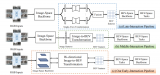
本方案的完整算法是在SD地图中定位一组环视图像。它从环视图像生成本地BEV表示,并从给定粗略3D位置先验的SD地图tile中生成神经地图编码(例如来自航海设备的嘈杂GPS信号和指南针)。深度模板匹配器然后在神经BEV上滑动全局神经地图,产生相似度图。最后,定位通过返回相似度图的Soft-Argmax来完成。我们的方法概述如图2所示。
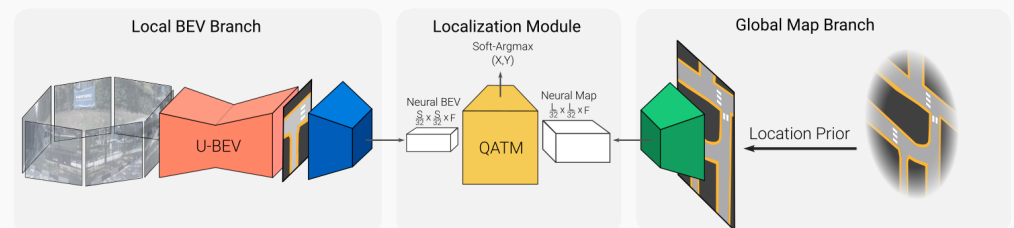
图2:U-BEV神经重定位模型概述。U-BEV从一组环视摄像头预测局部BEV(左)。地图编码器从根据位置先验裁剪的全局SD地图中提取特征(右)以构建神经地图表示。QATM匹配模块(中心)计算最佳匹配位置。
A. Bird眼视角重建
我们提出了一种新颖的轻量级且准确的BEV架构U-BEV,用于从一组环视图像重建汽车周围环境。我们的模型受计算机视觉分割任务中广泛使用的架构U-Net的启发。概述如图4所示。
给定一组6张图像及其内参和外参,我们预测一个BEV ,其中S是BEV的像素大小,N是地图中可用标签的数量。我们遵循nuScenes数据集中的约定,使用后轴心中心作为我们的原点。
特征提取:我们使用轻量级的预训练EfficientNet backbone从所有6张图像中提取不同分辨率的特征,这在较小的模型中是常见的方法。具体来说,我们以步长2、4、8、16提取特征,并为计算原因删除最后一个步长。提取的特征在整个架构中用作跳过连接。(图4中的蓝色框)
高度预测: U-BEV的一个关键贡献是从地面估计高度以在3D空间进行推理。我们利用提取的特征和轻量级解码器对每个像素执行此像素式操作(图4中的橙色部分)。与BEV文献中广泛预测隐式或显式深度的做法相反,我们认为从地面到观察到的每个像素的高度是一种更有效的表示。这主要基于以下观察:对于驾驶应用程序,需要在x、y地面平面上进行高分辨率,而垂直轴可以更粗略地离散化。此外,如图3所示,深度通常分布在更长的范围上,例如[0-50]米,这需要大量的离散间隔。可以有意义地将高度离散化在较低范围内,例如[0-5]米来解释周围环境。较少的bin数量对模型有直接影响:它显着降低了投影的复杂性(在我们的例子中20),并降低了内存占用。最后,最相关的信息,即路面、标记、路缘等集中在该范围的下部。
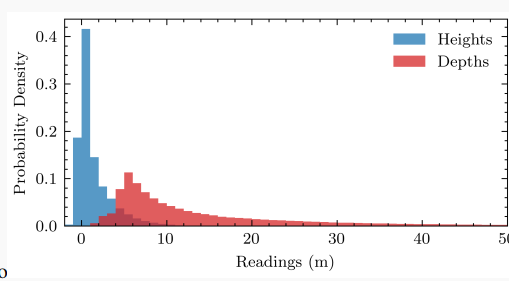
图3:当车辆坐标系中点离地面的高度和作为点离摄像头的距离时,重新投影到图像平面上的激光雷达读数分布,来自nuScenes。
因此,我们将高度预测任务设置为分类问题,仅使用作为bin。更具体地说,我们的解码器输出预测,其中 是输入图像的形状。通过以下方式可以获得特定像素在索引处的实际高度预测:
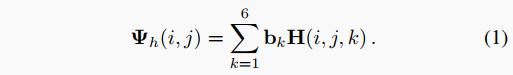
我们利用这个离散化的高度预测根据在每个bin中的可能性对每个特征进行加权。
投影:我们将更深层的特征投影到更粗糙的BEV中,将更早期的高分辨率特征投影到更高分辨率的BEV中。这允许我们以经典的编码器-解码器方式上采样BEV,其中更详细的BEV充当跳过连接(图4中的绿色部分)。
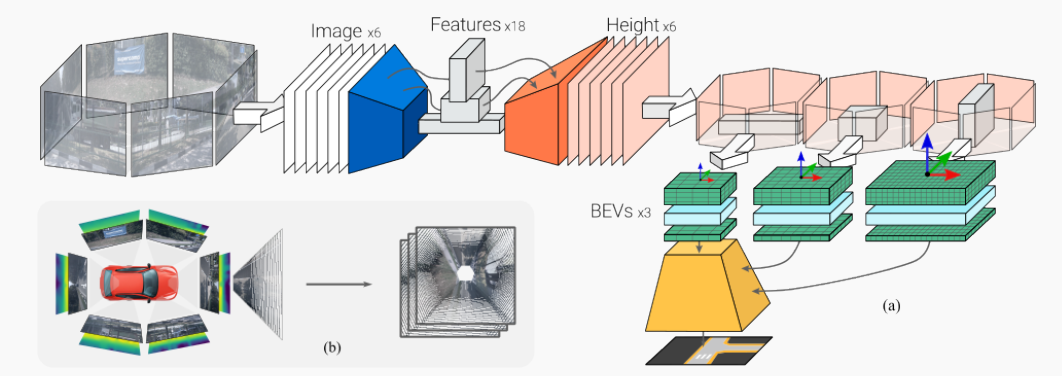
图4:U-BEV模型架构。(a)预训练的backbone(蓝色)从汽车周围的所有6个摄像头中提取特征。第一个解码器(橙色)预测每个输入图像上的每个像素的高度。这个高度用于将每个摄像头的特征投影到3D空间的单个BEV中(绿色)。更深层的特征被投影到较低分辨率的BEV中,然后以编码器-解码器方式上采样(黄色),具有跳跃连接。(b)说明从环视图像和高度到不同BEV层的投影操作。
我们应用经修改的逆投影映射(IPM)将图像坐标中的特征展开到BEV坐标中(参见图4 b)。要从像素投影每个特征,我们使用已知的外在投影矩阵和相机的内在参数。要在高度处投影,我们利用矩阵形式的翻译变换将参考系统提升到所需高度,并在处执行标准IPM。
IPM公式将这些变量相关联为:
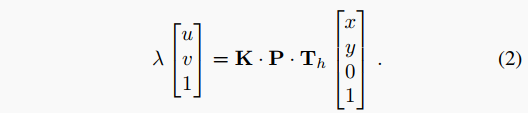
这种形式方便地允许删除矩阵的第三列,这使我们能够对其进行求逆并求出。该操作可以在GPU上对所有特征并行化,并在所有高度上执行,从而产生一个占用体积。
BEV解码:最后,我们用两个卷积层挤压高度维度的每个BEV。通过保持分辨率和通道的比率不变,我们可以将它们与跳过连接一起插入经典的解码器样式,产生最终的BEV输出(图4中的黄色部分)。
B. 地图编码
地图以布尔型通道离散化表面栅格化的形式输入到我们的系统中,其中是类的数量,即每个语义类被分配一个独立的通道。在多边形表示的情况下,如自动驾驶SD地图中的常见情况,我们通过将每个类的多边形栅格化到通道来预处理地图。
C. 定位
为了进行定位,我们利用本地BEV 和给定粗略位置先验裁剪的全局地图平铺。
给定拟议的U-BEV模型重建的BEV与地图平铺在比例上相符合,定位通过模板匹配来实现。为了补偿本地BEV重建的不完美,定位模块从地图平铺和本地BEV中提取神经表示,并在地图平铺上构建概率图。
在特征空间匹配神经BEV预测和神经地图增强了定位模块对本地BEV中的错误和不完美的鲁棒性,这可能是由于遮挡或者在定位场景中感知降级(例如,照明不足或恶劣天气)引起的,以牺牲分辨率为代价。
我们应用二维softmax $ ilde{M} = ext{softmax}{2D}(M{prob}) xy$方向上执行soft-argmax提取预测,其中
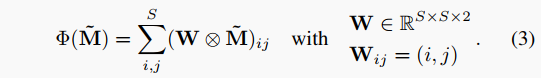
3. 实验结果
本文的实验结果主要涉及BEV分割和重定位的性能比较。在BEV方面,作者使用了U-BEV和CVT两种方法进行比较,通过计算IoU来评估两种方法在不同类别的地面、路面和十字路口上的表现。实验结果显示,U-BEV在所有类别上的IoU表现均优于CVT,并且在路面和人行道分割上的表现提升尤为明显。此外,U-BEV相较于CVT具有更低的计算复杂度,可实现相当的性能提升。在重定位方面,作者通过比较不同方法在不同距离的召回准确率(1m, 2m, 5m, 10m)上的表现,发现U-BEV相较于其他基于BEV的方法和当代基于BEV的重定位方法,在10m上的召回准确率提高了26.4%。总的来说,实验结果证明了U-BEV方法在BEV分割和重定位方面取得了更好的性能表现。

表1:以1米,2米,5米,10米处的召回准确率为指标的定位结果。
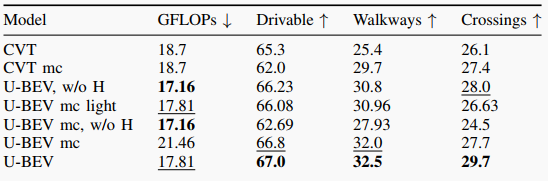
表2: U-BEV和CVT的BEV性能IoU。mc表示多类模型,w/o H表示不带高度的模型。
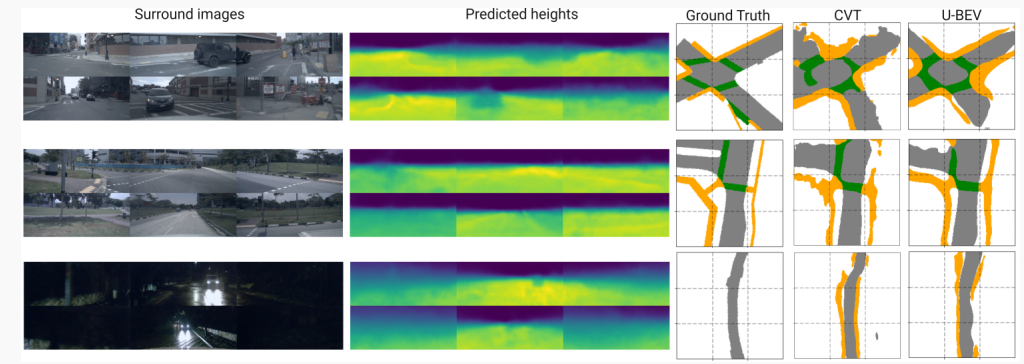
图5:U-BEV的输入和输出示例,包括环视图像,预测高度和预测和真值BEV。与CVT相比,U-BEV更准确地重建了可驾驶表面和人行道。
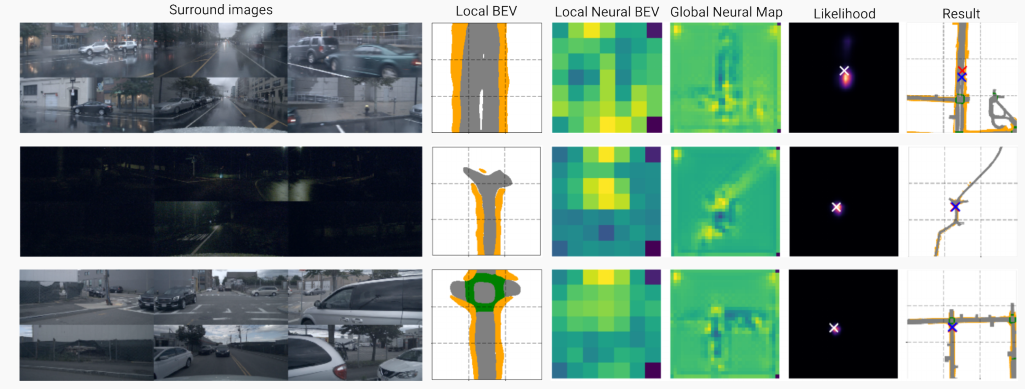
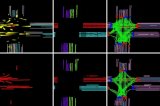
图6 定位过程的输入和输出示例,包括环绕图像、局部BEV、局部BEV和地图块的神经编码、预测的可能性以及结果的可视化。在可视化中,蓝十字为地面真实姿态,红十字为预测姿态。
4. 结论
本文提出了一种新的U-Net启发的BEV架构“U-BEV”,它利用多个高度层的中间分割。该架构在分割性能上优于现有的基于Transformer的BEV架构1.7到2.8%的IoU。此外,我们提出了一种新颖的重定位方法,利用拟议的U-BEV与神经编码的SD地图进行匹配。重定位扩展显著优于相关方法,在10米内的召回率提高了26.4%以上。值得注意的是,仅需要地图数据的几个类别,特别是道路表面,为在无特征环境中重定位铺平了道路。
-
传感器
+关注
关注
2578文章
55567浏览量
794232 -
模板
+关注
关注
0文章
111浏览量
21131 -
模型
+关注
关注
1文章
3831浏览量
52287
原文标题:ICCV2023 SOTA U-BEV:基于高度感知的鸟瞰图分割和神经地图的重定位
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
《炬丰科技-半导体工艺》在硅上生长的 InGaN 基激光二极管的腔镜的晶圆制造
什么是高精度地图
基于改进深度信息的手势分割与定位
Apollo定位、感知、规划模块的基础-高精地图
特斯拉完全自动驾驶套件车辆新增“向量空间鸟瞰图“功能
利用激光雷达探测车辆路径上的障碍物
介绍一种对标Tesla Occupancy的开源3D语义场景补全⽅法
基于神经匹配的二维地图视觉定位
基于纯视觉的感知方法
高德地图公布“奇境”引擎,应用神经渲染等前沿技术打造“时空地图”

智行者科技发布基于***的“重感知、轻地图”智驾解决方案
基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法



评论