 北大&华为提出:多模态基础大模型的高效微调
北大&华为提出:多模态基础大模型的高效微调
很荣幸我们近期的工作Parameter-efficient Tuning of Large-scaleMultimodal Foundation Model被NeurIPS2023录用!

https://arxiv.org/abs/2305.08381
这是我们第一篇拓展至多模态领域的高效微调的工作,在该工作中我们首次采用模式逼近(mode apprximation)的方法来进行大模型的轻量化高效微调,仅需训练预训练大模型0.04%的参数。同时我们设计了两个启发性模块来增强高效微调时极低参数条件下的模态对齐。实验上,我们在六大跨模态基准测试集上进行全面评估显示,我们的方法不仅超越当前的sota, 还在一些任务上优于全量微调方法。
论文的相关代码也会开源在这个GitHub项目:
github.com/WillDreamer/Aurora
大模型的高效微调是一个非常新且日渐繁荣的task,欢迎小伙伴们一起学习交流~
一、背景
深度学习的大模型时代已经来临,越来越多的大规模预训练模型在文本、视觉和多模态领域展示出杰出的生成和推理能力。然而大模型巨大的参数量有两个明显缺点。第一,它带来巨大的计算和物理存储成本,使预训练和迁移变得非常昂贵。第二,微调限制了预训练知识在小规模数据量的下游任务中的应用效果。这两点阻碍了大模型从特定数据集扩展到更广泛场景。
为缓解预训练大模型的高昂成本,一系列参数高效微调方法相继提出。其通用范式是冻结大模型的骨干网络,并引入少量额外参数。最近,一些工作开始关注多模态领域的高效微调任务,例如UniAdapter、VL-Adapter和MAPLE。但是,它们的通用思路是将自然语言处理领域的现有架构用于多模态模型并组合使用,然后直接在单模态和多模态分支的骨干网络中插入可训练参数以获得良好表现。直接、简单的设计无法将参数高效迁移的精髓融入多模态模型。此外,还有两个主要挑战需要面对: (1)如何在极轻量级高效微调框架下进行知识迁移;(2)在极低参数环境下如何提高各模态间的对齐程度。

图1:与现有主流的高效微调方法的对比
在这篇文章中,我们尝试解决这两种挑战,贡献可以总结为:
介绍了名为Aurora的多模态基础大模型高效微调框架,它解决了当前大规模预训练和微调策略的局限性。
提出了模式近似(mode approximation)方法来生成轻量级可学习参数,并提出了两个启发性模块来更好地增强模态融合。
通过六个跨模态任务和两个零样本任务进行实验验证,结果显示Aurora相比其他方法取得了最先进的性能,同时也只使用最少的可学习参数。
二、高效微调的轻量化架构的设计

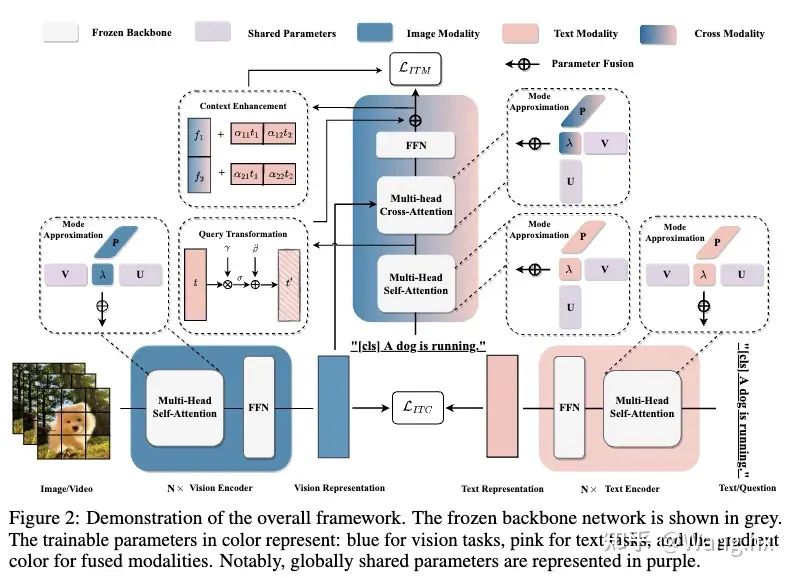
Aurora的整体过程示意图。
三、高效微调的模态对齐的设计
3.1 Informative Context Enhancement
该模块的目标是为了实现更好的模态对齐,在交叉注意力模块后的融合特征中提供提示文本来更好的激活。受“上下文学习”这一领域的进步启发,我们意识到为提示词提供示范模板是很重要的。最直观的方法是对图像与文本对进行对齐,以获得更多跨模态上下文信息。但是,即使与相关图像区域匹配,描述这些区域的文本可能还是有多个选择。一些文本可能准确概括图像内容,而另一些可能不行。在没有事先匹配文本信息的先验情况下,我们决定引入上下文增强模块来涵盖各个方面的可能的文本信息。

四、实验结果
4.1 实验设置
数据集与基准比较。我们在六个跨模态任务领域的benchmark上评估了Aurora,这些任务包括图片文本检索、问答(QA)、视频文本检索和视频QA。我们将Aurora与两类方法进行比较:完全微调后的SOTA方法以及Frozen重要部分的LoRA和UniAdapter方法。更多细节请参阅附录。
实现细节。我们的实现基于Salesforce开源代码库。与UniAdapter一致,我们使用BLIP-base作为所有多模态下游任务的视觉语言初始化权重。我们使用PyTorch在8台NVIDIA V100 GPU(32G)设备上实现所有实验。我们使用AdamW优化器,设置权重衰减为0.05,学习率通过网格搜索得到为1e-4。需要注意的是,在微调过程中,参数组只更新交叉注意模块的权重, backbone初始化权重不更新。
4.2 实验结果
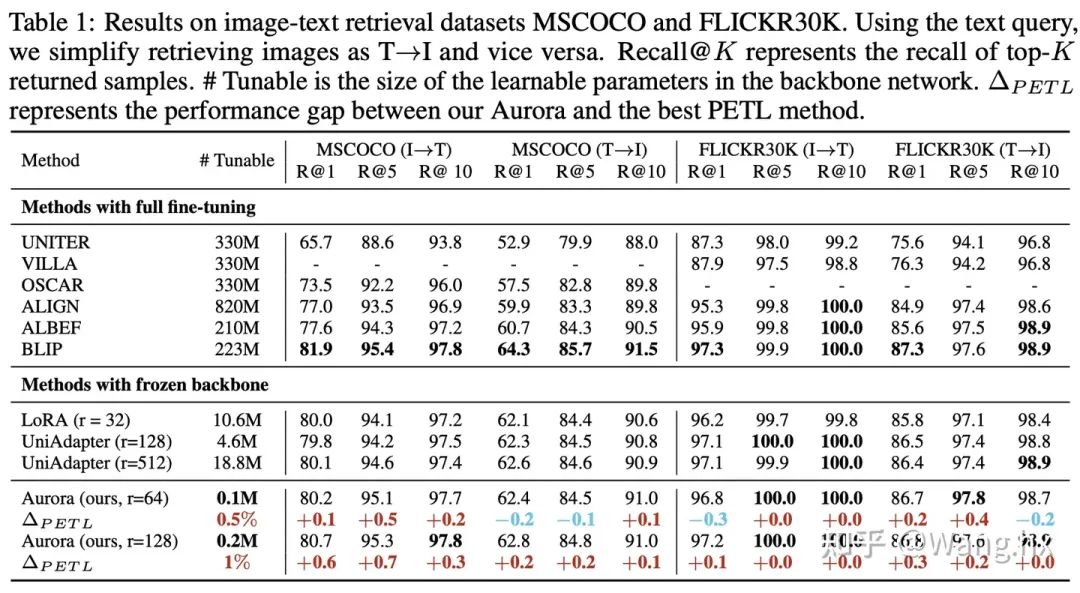
Image-Text Retrieval
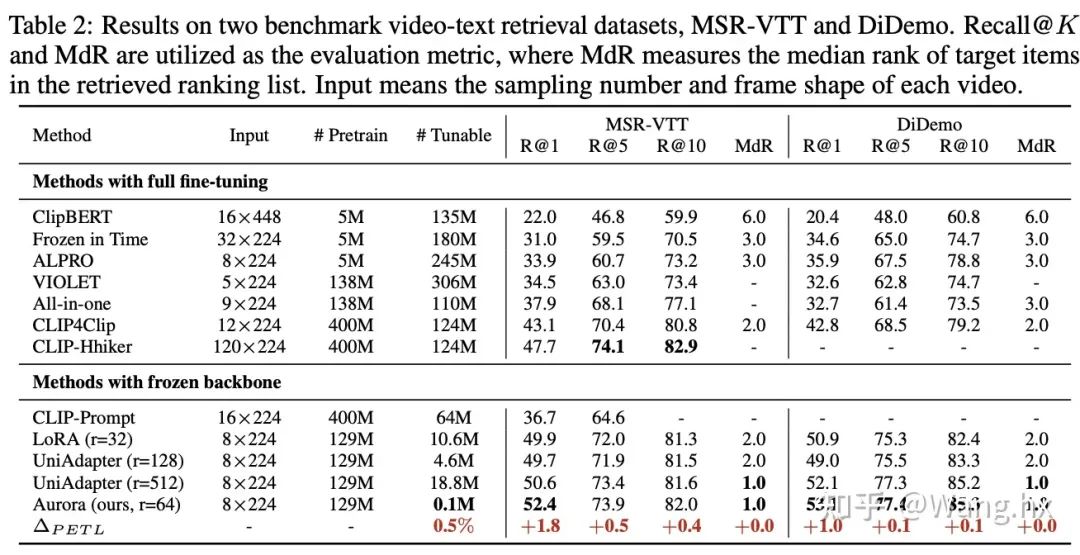
Video-Text Retrieval
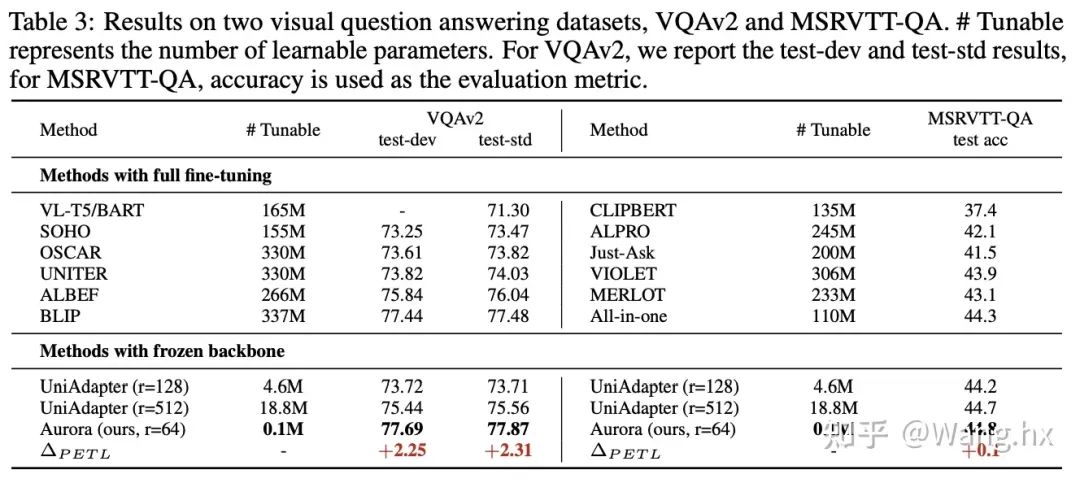
VQA
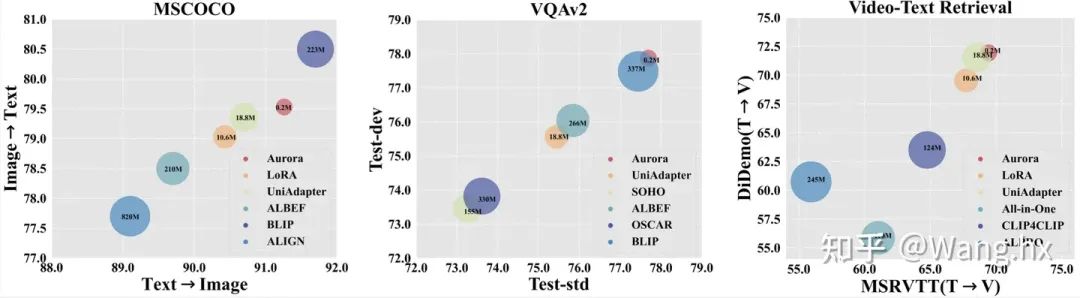
实验气泡图
4.3 消融实验
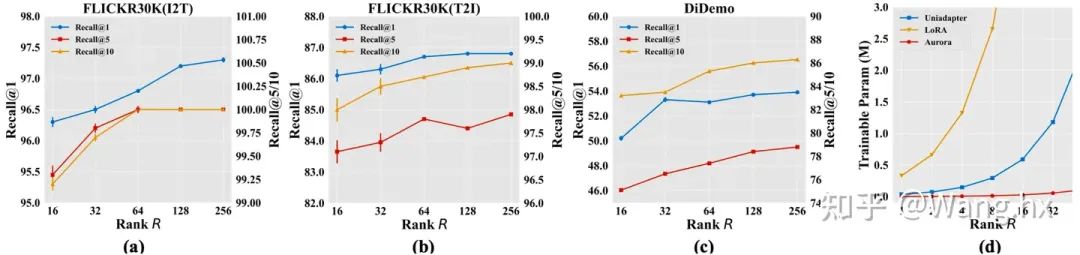
How Rank of CP Decomposition Affects Aurora?
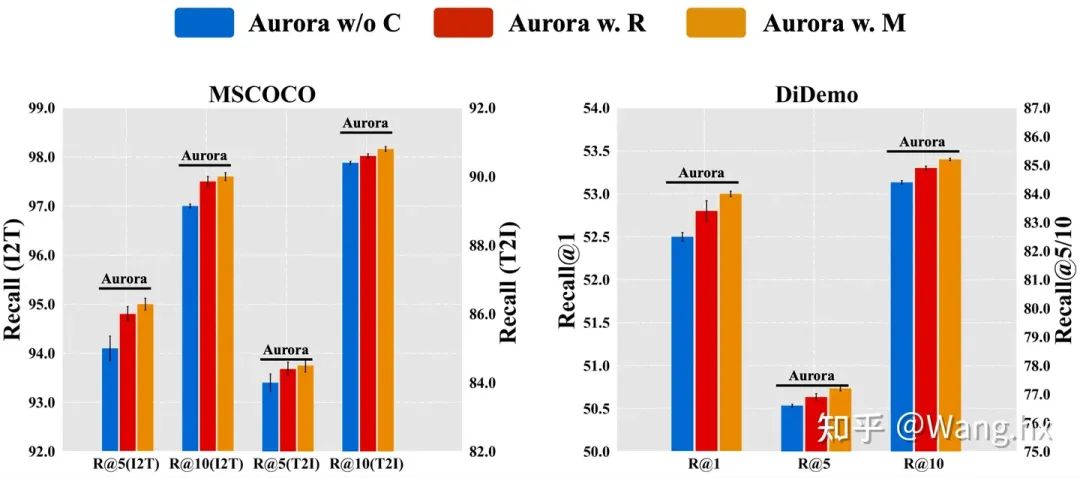
How Does Aurora Benefit from Informative Context Enhancement
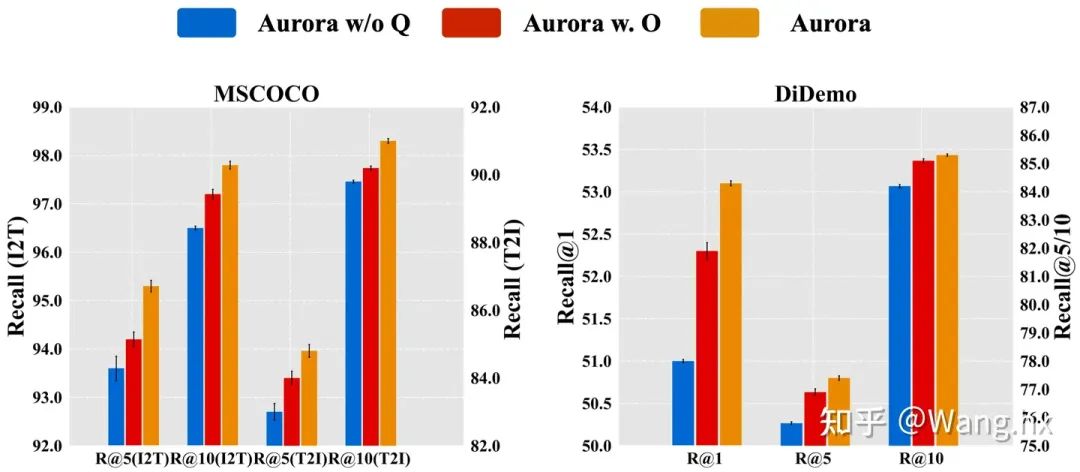
How Does Aurora Benefit from Gated Query Transformation?

How Does Aurora Benefit from Parameter Sharing?
4.4 可视化分析
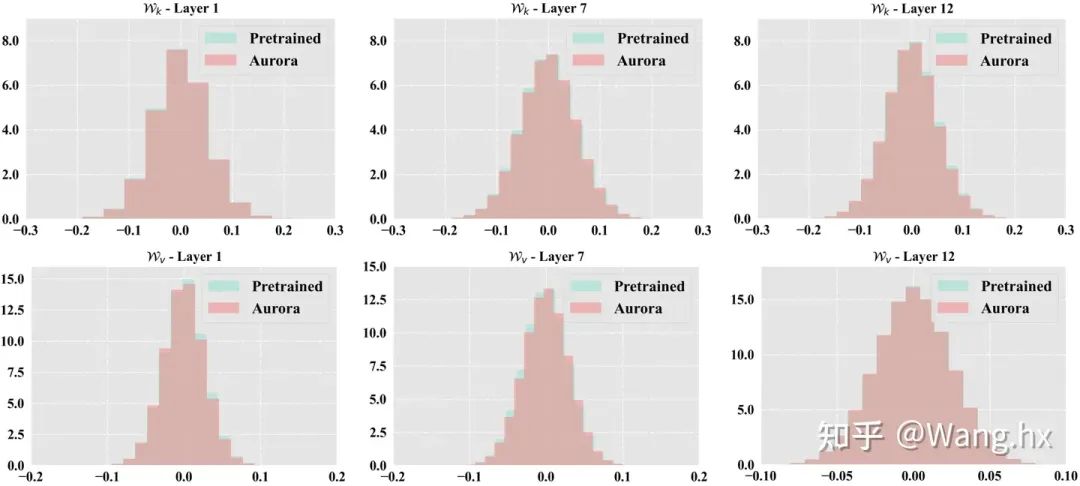
参数分布可视化

Video-Text retrieval cases on MSRVTT

Video Question Answering cases on MSRVTT-QA
-
框架
+关注
关注
0文章
403浏览量
17603 -
深度学习
+关注
关注
73文章
5527浏览量
121833 -
大模型
+关注
关注
2文章
2762浏览量
3413
原文标题:NeurIPS 2023 | 北大&华为提出:多模态基础大模型的高效微调
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读

单张消费级显卡微调多模态大模型

更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

中科大&amp;字节提出UniDoc:统一的面向文字场景的多模态大模型
用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单

大模型+多模态的3种实现方法

基于AX650N芯片部署MiniCPM-V 2.0高效端侧多模态大模型






 工商网监
工商网监
评论