 Linux I/O 接口的类型及处理流程
Linux I/O 接口的类型及处理流程
Linux I/O 接口
Linux I/O 接口可以分为以下几种类型:
文件 I/O 接口:用于对文件进行读写操作的接口,包括 open()、read()、write()、close()、lseek() 等。
网络 I/O 接口:用于网络通信的接口,包括 socket()、connect()、bind()、listen()、accept() 等。

设备 I/O 接口:用于对设备(e.g. 字符设备、块设备)进行读写操作的接口,包括 ioctl()、mmap()、select()、poll()、epoll() 等。
其他 I/O 接口:如管道接口、共享内存接口、信号量接口等。
Linux I/O 处理流程
下面以最常用的 read() 和 write() 函数来介绍 Linux 的 I/O 处理流程。
read() 和 write()
read() 和 write() 函数,是最基本的文件 I/O 接口,也可用于在 TCP Socket 中进行数据读写,属于阻塞式 I/O(Blocking I/O),即:如果没有可读数据或者对端的接收缓冲区已满,则函数将一直等待直到有数据可读或者对端缓冲区可写。
函数原型:
fd 参数:指示 fd 文件描述符。
buf 参数:指示 read/write 缓冲区的入口地址。
count 参数:指示 read/write 数据的大小,单位为 Byte。
函数返回值:
- 返回实际 read/write 的字节数。
- 返回 0,表示已到达文件末尾。
- 返回 -1,表示操作失败,可以通过 errno 全局变量来获取具体的错误码。
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
处理流程
下面以同时涉及了 Storage I/O 和 Network I/O 的一次网络文件下载操作来展开 read() 和 write() 的处理流程。
read() 的处理流程:
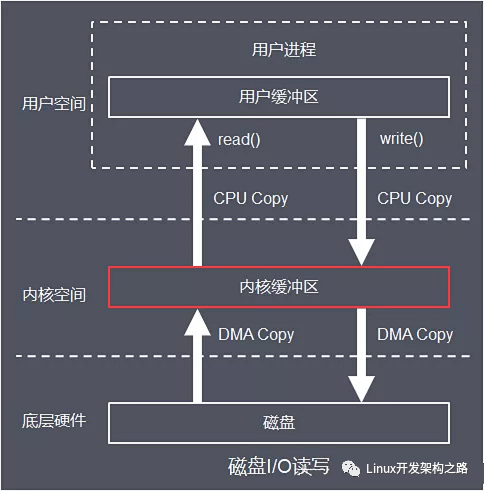
- Application 调用 read(),CPU 模式从用户态切换到内核态。
- Kernel 根据 file fd 查表(进程文件符表),找到对应的 file 结构体(普通文件),从而找到此文件的 inode 编号。
- Kernel 将 buf 和 count 参数、以及文件指针位置等信息传递给 Device Driver(磁盘驱动程序)。
- Driver 将请求的数据从 Disk Device 中 DMA Copy 到 Kernel PageCache Buffer 中。
- Kernel 将数据从 Kernel PageCache Buffer 中 CPU Copy 到 Userspace Buffer 中(Application 不能直接访问 Kernel space)。
- read() 最终返回读取的字节数或错误代码给 Application,CPU 模式从内核态切换到用户态。
write() 的处理流程:
- Application 调用 write(),CPU 模式从用户态切换到内核态。
- Kernel 根据 socket fd 查表,找到对应的 file 结构体(套接字文件),从而找到该 Socket 的 sock 结构体。
- Kernel 将 buf 和 count 参数、以及文件指针位置等信息传递给 Device Driver(网卡驱动程序)。
- Driver 将请求的数据从 Userspace Buffer 中 CPU Copy 到 Kernel Socket Buffer 中。
- Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 NIC Device。
- write() 最终返回写入的字节数或错误代码给 Application,CPU 模式从内核态切换到用户态。
可见,在一次常规的 I/O(read/write)操作流程中 处理流程中,总共需要涉及到:
- 4 次 CPU 模式切换:当 Application 调用 SCI 时,CPU 从用户态切换到内核态;当 SCI 返回时,CPU 从内核态切换回用户态。
- 2 次 CPU Copy:CPU 执行进程数据拷贝指令,将数据从 User Process 虚拟地址空间 Copy 到 Kernel 虚拟地址空间。
- 2 次 DMA Copy:CPU 向 DMA 控制器下达设备数据拷贝指令,将数据从 DMA 物理内存空间 Copy 到 Kernel 虚拟地址空间。

I/O 性能优化机制
I/O buff/cache
Linux Kernel 为了提高 I/O 性能,划分了一部分物理内存空间作为 I/O buff/cache,也就是内核缓冲区。当 Kernel 接收到 read() / write() 等读写请求时,首先会到 buff/cache 查找,如果找到,则立即返回。如果没有则通过驱动程序访问 I/O 外设。
查看 Linux 的 buff/cache:
total used free shared buff/cache available
Mem: 7.6G 4.2G 2.9G 10M 547M 3.1G
Swap: 4.0G 0B 4.0G
实际上,Cache(缓存)和 Buffer(缓冲)从严格意义上讲是 2 个不同的概念,Cache 侧重加速 “读”,而 Buffer 侧重缓冲 “写”。但在很多场景中,由于读写总是成对存在的,所以并没有严格区分两者,而是使用 buff/cache 来统一描述。
Page Cache

Page Cache(页缓存)是最常用的 I/O Cache 技术,以页为单位的,内容就是磁盘上的物理块,用于减少 Application 对 Storage 的 I/O 操作,能够令 Application 对文件进行顺序读写的速度接近于对内存的读写速度。
页缓存读策略:当 Application 发起一个 Read() 操作,Kernel 首先会检查需要的数据是否在 Page Cache 中:
- 如果在,则直接从 Page Cache 中读取。
- 如果不在,则按照原 I/O 路径从磁盘中读取。同时,还会根据局部性原理,进行文件预读,即:将已读数据随后的少数几个页面(通常是三个)一同缓存到 Page Cache 中。
页缓存写策略:当 Application 发起一个 write() 操作,Kernel 首先会将数据写到 Page Cache,然后方法返回,即:Write back(写回)机制,区别于 Write Through(写穿)。此时数据还没有真正的写入到文件中去,Kernel 仅仅将已写入到 Page Cache 的这一个页面标记为 “脏页(Dirty Page)”,并加入到脏页链表中。然后,由 flusher(pdflush,Page Dirty Flush)kernel thread(回写内核线程)周期性地将脏页链表中的页写到磁盘,并清理 “脏页” 标识。在以下 3 种情况下,脏页会被写回磁盘:
- 当空闲内存低于一个特定的阈值时,内核必须将脏页写回磁盘,以便释放内存。
- 当脏页在内存中驻留时间超过一个特定的阈值时,内核必须将超时的脏页写回磁盘。
- 当 Application 主动调用 sync、fsync、fdatasync 等 SCI 时,内核会执行相应的写回操作。
flusher 刷新策略由以下几个内核参数决定(数值单位均为 1/100 秒):
$ sysctl vm.dirty_writeback_centisecs
vm.dirty_writeback_centisecs = 500
# 内存中驻留 30 秒以上的脏数据将由 flush 在下一次执行时写入磁盘
$ sysctl vm.dirty_expire_centisecs
vm.dirty_expire_centisecs = 3000
# 若脏页占总物理内存 10% 以上,则触发 flush 把脏数据写回磁盘
$ sysctl vm.dirty_background_ratio
vm.dirty_background_ratio = 10
综上可见,Page Cache 技术在理想的情况下,可以在一次 Storage I/O 的流程中,减少 2 次 DMA Copy 操作(不直接访问磁盘)。

Buffered I/O
下图展示了一个 C 程序通过 stdio 库中的 printf() 或 fputc() 等输出函数来执行数据写入的操作处理流程。过程中涉及到了多处 I/O Buffer 的实现:
- stdio buffer:在 Userspace 实现的 Buffer,因为 SCI 的成本昂贵,所以,Userspace Buffer 用于 “积累“ 到更多的待写入数据,然后再通过一次 SCI 来完成真正的写入。另外,stdio 也支持 fflush() 强制刷新函数。
- Kernel buffer cache:处理包括上文以及提到的 Page Cache 技术之外,磁盘设备驱动程序也提供块级别的 Buffer 技术,用于 “积累“ 更多的文件系统元数据和磁盘块数据,然后在合适的时机完成真正的写入。

零拷贝技术(Zero-Copy)
零拷贝技术(Zero-Copy),是通过尽量避免在 I/O 处理流程中使用 CPU Copy 和 DMA Copy 的技术。实际上,零拷贝并非真正做到了没有任何拷贝动作,它更多是一种优化的思想。
下列表格从 CPU Copy 次数、DMA Copy 次数以及 SCI 次数这 3 个方面来对比了几种常见的零拷贝技术。可以看见,2 次 DMA Copy 是不可避免的,因为 DMA 是外设 I/O 的基本行为。零拷贝技术主要从减少 CPU Copy 和 CPU 模式切换这 2 个方面展开。

1、Userspace Direct I/O
Userspace Direct I/O(用户态直接 I/O)技术的底层原理由 Kernel space 中的 ZONE_DMA 支持。ZONE_DMA 是一块 Kernel 和 User Process 都可以直接访问的 I/O 外设 DMA 物理内存空间。基于此, Application 可以直接读写 I/O 外设,而 Kernel 只会辅助执行必要的虚拟存储配置工作,不直接参与数据传输。因此,该技术可以减少 2 次 CPU Copy。
Userspace Direct I/O 的缺点:
- 由于旁路了 要求 Kernel buffer cache 优化,就需要 Application 自身实现 Buffer Cache 机制,称为自缓存应用程序,例如:数据库管理系统。
- 由于 Application 直接访问 I/O 外设,会导致 CPU 阻塞,浪费 CPU 资源,这个问题需要结合异步 I/O 技术来规避。

具体流程看下图:Using Direct I/O with DMA

2、mmap() + write()
mmap() SCI 用于将 I/O 外设(e.g. 磁盘)中的一个文件、或一段内存空间(e.g. Kernel Buffer Cache)直接映射到 User Process 虚拟地址空间中的 Memory Mapping Segment,然后 User Process 就可以通过指针的方式来直接访问这一段内存,而不必再调用传统的 read() / write() SCI。

申请空间函数原型:
- addr 参数:分配 MMS 映射区的入口地址,由 Kernel 指定,调用时传入 NULL。
- length 参数:指示 MMS 映射区的大小。
- prot 参数:指示 MMS 映射区的权限,可选:PROT_READ、PROT_WRITE、PROT_READ|PROT_WRITE 类型。
- flags 参数:标志位参数,可选:
- MAP_SHARED:映射区所做的修改会反映到物理设备(磁盘)上。
- MAP_PRIVATE:映射区所做的修改不会反映到物理设备上。
- fd 参数:指示 MMS 映射区的文件描述符。
- offset 参数:指示映射文件的偏移量,为 4k 的整数倍,可以映射整个文件,也可以只映射一部分内容。
- 函数返回值:
- 成功:更新 addr 入口地址。
- 失败:更新 MAP_FAILED 宏。
释放空间函数原型:
- addr 参数:分配 MMS 映射区的入口地址,由 Kernel 指定,调用时传入 NULL。
- length 参数:指示 MMS 映射区的大小。
- 函数返回值:
- 成功:返回 0。
- 失败:返回 -1。

可见,mmap() 是一种高效的 I/O 方式。通过 mmap() 和 write() 结合的方式,可以实现一定程度的零拷贝优化。
buf = mmap(diskfd, len);
// 写
write(sockfd, buf, len);
mmap() + write() 的 I/O 处理流程如下。
mmap() 映射:
- Application 发起 mmap() 调用,进行文件操作,CPU 模式从用户态切换到内核态。
- mmap() 将指定的 Kernel Buffer Cache 空间映射到 Application 虚拟地址空间。
- mmap() 返回,CPU 模式从内核态切换到用户态。
- 在 Application 后续的文件访问中,如果出现 Page Cache Miss,则触发缺页异常,并执行 Page Cache 机制。通过已经建立好的映射关系,只使用一次 DMA Copy 就将文件数据从磁盘拷贝到 Application User Buffer 中。
write() 写入:
- Application 发起 write() 调用,CPU 模式从用户态切换到内核态。
- 由于此时 Application User Buffer 和 Kernel Buffer Cache 的数据是一致的,所以直接从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer,并最终从 NIC 发出。
- write() 返回,CPU 模式从内核态切换到用户态。
可见,mmap() + write() 的 I/O 处理流程减少了一次 CPU Copy,但没有减少 CPU 模式切换的次数。另外,由于 mmap() 的进程间共享特性,非常适用于共享大文件的 I/O 场景。
mmap() + write() 的缺点:当 mmap 映射一个文件时,如果这个文件被另一个进程所截获,那么 write 系统调用会因为访问非法地址被 SIGBUS 信号终止,SIGBUS 默认会杀死进程并产生一个 coredump。解决这个问题通常需要使用文件租借锁实现。在 mmap 之前加锁,操作完之后解锁。即:首先为文件申请一个租借锁,当其他进程想要截断这个文件时,内核会发送一个实时的 RT_SIGNAL_LEASE 信号,告诉当前进程有进程在试图破坏文件,这样 write 在被 SIGBUS 杀死之前,会被中断,返回已经写入的字节数,并设置 errno 为 success。

3、sendfile()
Linux Kernel 从 v2.1 开始引入了 sendfile(),用于在 Kernel space 中将一个 in_fd 的内容复制到另一个 out_fd 中,数据无需经过 Userspace,所以应用在 I/O 流程中,可以减少一次 CPU Copy。同时,sendfile() 比 mmap() 方式更具安全性。
函数原型:
- out_fd 参数:目标文件描述符,数据输入文件。
- in_fd 参数:源文件描述符,数据输出文件。该文件必须是可以 mmap 的。
- offset 参数:指定从源文件的哪个位置开始读取数据,若不需要指定,传递一个 NULL。
- count 参数:指定要发送的数据字节数。
- 函数返回值:
- 成功:返回复制的字节数。
- 失败:返回 -1,并设置 errno 全局变量来指示错误类型。
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
sendfile() 处理流程:
- Application 调用 sendfile(),CPU 从用户态切换到内核态。
- Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
- Kernel 将数据从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer。
- Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 I/O 网卡设备。
- sendfile() 返回,CPU 从内核态切换到用户态。

4、sendfile() + DMA Gather Copy
上文知道 sendfile() 还具有一次 CPU Copy,通过结合 DMA Gather Copy 技术,可以进一步优化它。
DMA Gather Copy 技术,底层有 I/O 外设的 DMA Controller 提供的 Gather 功能支撑,所以又称为 “DMA 硬件辅助的 sendfile()“。借助硬件设备的帮助,在数据从 Kernel Buffer Cache 到 Kernel Socket Buffer 之间,并不会真正的数据拷贝,而是仅拷贝了缓冲区描述符(fd + size)。待完成后,DMA Controller,可以根据这些缓冲区描述符找到依旧存储在 Kernel Buffer Cache 中的数据,并进行 DMA Copy。
显然,DMA Gather Copy 技术依旧是 ZONE_DMA 物理内存空间共享性的一个应用场景。
sendfile() + DMA Gather Copy 的处理流程:
- Application 调用 sendfile(),CPU 从用户态切换到内核态模式。
- Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
- Kernel 将数据的缓冲区描述符从 Kernel Buffer Cache 中 CPU Copy 到 Kernel Socket Buffer(几乎不费资源)。
- 基于缓冲区描述符,CPU 利用 DMA Controller 的 Gather / Scatter 操作直接批量地将数据从 Kernel Buffer Cache 中 DMA Copy 到网卡设备。
- sendfile() 返回,CPU 从内核态切换到用户态。

5、splice()
splice() 与 sendfile() 的处理流程类似,但数据传输方式有本质不同。
- sendfile() 的传输方式是 CPU Copy,且具有数据大小限制;
- splice() 的传输方式是 Pipeline,打破了数据范围的限制。但也要求 2 个 fd 中至少有一个必须是管道设备类型。
函数原型:
- fd_in 参数:源文件描述符,数据输出文件。
- off_in 参数:输出偏移量指针,表示从源文件描述符的哪个位置开始读取数据。
- fd_out 参数:目标文件描述符,数据输入文件。
- off_out 参数:输入偏移量指针,表示从目标文件描述符的哪个位置开始写入数据。
- len 参数:指示要传输的数据长度。
- flags:控制数据传输的行为的标志位。
#include
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
splice() 的处理流程如下:
- Application 调用 splice(),CPU 从用户态切换到内核态。
- Kernel 将数据通过 DMA Copy 从磁盘设备写入 Kernel Buffer Cache。
- Kernel 在 Kernel Buffer Cache 和 Kernel Socket Buffer 之间建立 Pipeline 传输。
- Kernel 将数据从 Kernel Socket Buffer 中 DMA Copy 到 I/O 网卡设备。
- splice() 返回,CPU 从内核态切换到用户态。

6、缓冲区共享技术
缓冲区共享技术,是对 Linux I/O 的一种颠覆,所以往往需要由 Application 和设备来共同实现。
其核心思想是:每个 Applications 都维护着一个 Buffer Pool,并且这个 Buffer Pool 可以同时映射到 Kernel 虚拟地址空间,这样 Userspace 和 Kernel space 就拥有了一块共享的空间。以此来规避掉 CPU Copy 的行为。

-
接口
+关注
关注
33文章
8775浏览量
152396 -
Linux
+关注
关注
87文章
11373浏览量
211288 -
内存
+关注
关注
8文章
3081浏览量
74591 -
网络通信
+关注
关注
4文章
818浏览量
30317
发布评论请先 登录
相关推荐
PLC I/O接口的作用及选择
Linux系统中网络I/O性能改进方法的研究
Linux 系统应用编程之标准I/O详解
基于FPGA I/O接口的五大优势与FPGA深层分析
学会处理Linux内核访问外设I/O资源的方式
Linux中如何使用信号驱动式I/O?
深入理解Linux传统的System Call I/O
PLC系统的I/O接口该如何选择
探究I/O虚拟化及Virtio接口技术(上)
探究I/O虚拟化及Virtio接口技术(下)





 工商网监
工商网监
评论