 TorchScript model与eager model的性能区别
TorchScript model与eager model的性能区别
JIT Trace
torch.jit.trace使用eager model和一个dummy input作为输入,tracer会根据提供的model和input记录数据在模型中的流动过程,然后将整个模型转换为TorchScript module。看一个具体的例子:
我们使用BERT(Bidirectional Encoder Representations from Transformers)作为例子。
from transformers import BertTokenizer, BertModel
import numpy as np
import torch
from time import perf_counter
def timer(f,*args):
start = perf_counter()
f(*args)
return (1000 * (perf_counter() - start))
# 加载bert model
native_model = BertModel.from_pretrained("bert-base-uncased")
# huggingface的API中,使用torchscript=True参数可以直接加载TorchScript model
script_model = BertModel.from_pretrained("bert-base-uncased", torchscript=True)
script_tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', torchscript=True)
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = script_tokenizer.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
indexed_tokens = script_tokenizer.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
然后分别在CPU和GPU上测试eager mode的pytorch推理速度。
# 在CPU上测试eager model推理性能
native_model.eval()
np.mean([timer(native_model,tokens_tensor,segments_tensors) for _ in range(100)])
# 在GPU上测试eager model推理性能
native_model = native_model.cuda()
native_model.eval()
tokens_tensor_gpu = tokens_tensor.cuda()
segments_tensors_gpu = segments_tensors.cuda()
np.mean([timer(native_model,tokens_tensor_gpu,segments_tensors_gpu) for _ in range(100)])
再分别在CPU和GPU上测试script mode的TorchScript模型的推理速度
# 在CPU上测试TorchScript性能
traced_model = torch.jit.trace(script_model, [tokens_tensor, segments_tensors])
# 因模型的trace时,已经包含了.eval()的行为,因此不必再去显式调用model.eval()
np.mean([timer(traced_model,tokens_tensor,segments_tensors) for _ in range(100)])
# 在GPU上测试TorchScript的性能
最终运行结果如表
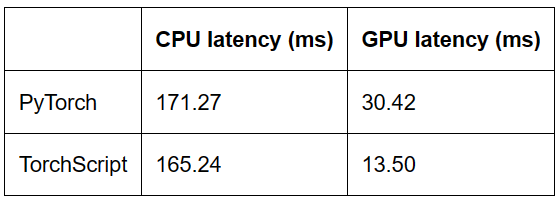
我使用的硬件规格是google colab,cpu是Intel(R) Xeon(R) CPU @ 2.00GHz,GPU是Tesla T4。
从结果来看,在CPU上,TorchScript比pytorch eager快了3.5%,在GPU上,TorchScript比pytorch快了55.6%。
然后我们再用ResNet做一个测试。
import torchvision
import torch
from time import perf_counter
import numpy as np
def timer(f,*args):
start = perf_counter()
f(*args)
return (1000 * (perf_counter() - start))
# Pytorch cpu version
model_ft = torchvision.models.resnet18(pretrained=True)
model_ft.eval()
x_ft = torch.rand(1,3, 224,224)
print(f'pytorch cpu: {np.mean([timer(model_ft,x_ft) for _ in range(10)])}')
# Pytorch gpu version
model_ft_gpu = torchvision.models.resnet18(pretrained=True).cuda()
x_ft_gpu = x_ft.cuda()
model_ft_gpu.eval()
print(f'pytorch gpu: {np.mean([timer(model_ft_gpu,x_ft_gpu) for _ in range(10)])}')
# TorchScript cpu version
script_cell = torch.jit.script(model_ft, (x_ft))
print(f'torchscript cpu: {np.mean([timer(script_cell,x_ft) for _ in range(10)])}')
# TorchScript gpu version
script_cell_gpu = torch.jit.script(model_ft_gpu, (x_ft_gpu))
print(f'torchscript gpu: {np.mean([timer(script_cell_gpu,x_ft.cuda()) for _ in range(100)])}')
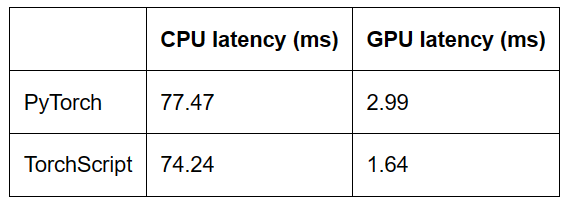
TorchScript相比PyTorch eager model,CPU性能提升4.2%,GPU性能提升45%。与Bert的结论一致。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
cpu
+关注
关注
68文章
10943浏览量
213812 -
数据
+关注
关注
8文章
7222浏览量
90135 -
模型
+关注
关注
1文章
3409浏览量
49461
发布评论请先 登录
相关推荐
DAC5672的model 有没有其他格式的?
DAC问题
谁可以提供DAC5672的 *** model,或提供与DAC5672性能相近的DAC的model 也可以,还是说TI的网站上,对于DAC除了有IBIS格式的,没有其他格式的吗?希望大家给个准信!
发表于 01-21 06:14


PSpice如何利用Model Editor建立模拟用的Model
PSpice 提供Model Editor 建立组件的Model,从组件供货商那边拿该组件的Datasheet,透过描点的方式就可以简单的建立组件的Model,来做电路的模拟。PSpice 如何利用
发表于 03-31 11:38
IC设计基础:说说wire load model
说起wire load model,IC设计EDA流程工程师就会想到DC的两种工具模式:线负载模式(wire load mode)和拓扑模式(topographicalmode)。为什么基本所有深亚
发表于 05-21 18:30
Model B的几个PCB版本
尽管树莓派最新版的型号Model B+目前有着512 MB的内存和4个USB端口,但这些都不会是一成不变的。除了Model B+外,标准的Model B还有两个变种的型号。如果你买到的是一个双面的树莓派
发表于 08-08 07:17
Model3电机是什么
—Model3电机拆解 汽车攻城狮交流异步电机交流异步电机也叫感应电机,由定子和转子组成。定子铁芯一般由硅钢片叠压而成,有良好的导磁性能,定子铁芯的内圆上有分布均匀的槽口,这个槽口是用来安放定子绕组的
发表于 08-26 09:12
Cycle Model Studio 9.2版用户手册
高性能可链接对象,称为Cycle Model,它既精确于循环,又精确于寄存器。循环模型提供了与验证环境对接的功能。
此外,Cycle Model Studio可以编译与特定设计平台兼容的模型,如SoC
发表于 08-12 06:26
性能全面升级的特斯拉Model S/Model X到来
据外媒7月3日消息,在全新车型Model 3即将上市之际,特斯拉公布了对其现有两款车型Model S和Model X的一系列升级,旨在提高其非性能车型的加速能力。
发表于 07-06 09:13
•1518次阅读
Model Y车型类似Model3 但续航里程会低于Model3
马斯克在连续发布了Model3标准版上市、关闭线下门店等多项重大消息之后,继续放大招,在Twitter上,马斯克表示,将于3月14日在洛杉矶发布旗下跨界SUV Model Y纯电动汽车根据马斯克此前
发表于 03-05 16:17
•2307次阅读
仿真器与Model的本质区别
仿真器所需的“时间”和“精度”怎么协调?想快就向Digital仿真器靠拢;想准就向Analog靠拢。做Model不是做加法、就是做减法。做Analog出身的熟悉Schematic
特斯拉再次调整Model 3/Model Y长续航版的售价
2月22日消息,据国外媒体报道,在对标准续航升级版和Performance高性能版价格进行调整后,特斯拉再次调整Model 3/Model Y长续航版的起售价。
特斯拉Model Y高性能版国内正式交付
近日,首批特斯拉Model Y高性能版车型已经正式启动交付,新款特斯拉Model Y在动力方面比标准版和长续航版更强。目前Model Y已经取得了不错的销量,特斯拉
TorchScript的重要特性和用途
PyTorch支持两种模式:eager模式和script模式。eager模式主要用于模型的编写、训练和调试,script模式主要是针对部署的,其包含PytorchJIT和TorchScript(一种





 工商网监
工商网监
评论