 protobuf的编码和存储方式
protobuf的编码和存储方式
一、protobuf简介:
1.1 protobuf的定义:
protobuf是用来干嘛的?
protobuf是一种用于 对结构数据进行序列化的工具,从而实现 数据存储和交换。
(主要用于网络通信中 收发两端进行消息交互。所谓的“结构数据”是指类似于struct结构体的数据,可用于表示一个网络消息。当结构体中存在函数指针类型时,直接对其存储或传输相当于是“浅拷贝”,而对其序列化后则是“深拷贝”。)
序列化:将结构数据或者对象转换成能够用于存储和传输的格式。
反序列化:在其他的计算环境中,将序列化后的数据还原为数据结构和对象。
从“序列化”字面上的理解,似乎使用C语言中的struct结构体就可以实现序列化的功能:将结构数据填充到定义好的结构体中的对应字段即可,接收方再对结构体进行解析。
在单机的不同进程间通信时,使用struct结构体这种方法实现“序列化”和“反序列化”的功能问题不大,但是,在网络编程中,即面向网络中不同主机间的通信时,则不能使用struct结构体,原因在于:
(1)跨语言平台,例如发送方是用C语言编写的程序,接收方是用Java语言编写的程序,不同语言的struct结构体定义方式不同,不能直接解析;
(2)struct结构体存在 内存对齐 和 CPU不兼容的问题。
因此,在网络编程中,实现“序列化”和“反序列化”功能需要使用通用的组件,如 Json、XML、protobuf 等。
1.2 protobuf的优缺点:
1.2.1 优点:
① 性能高效:
与XML相比,protobuf更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
② 语言无关、平台无关:
protobuf支持Java、C++、Python等多种语言,支持多个平台。
③ 扩展性、兼容性强:
只需要使用protobuf对结构数据进行一次描述,即可从各种数据流中读取结构数据,更新数据结构时不会破坏原有的程序。
Protobuf与XML、Json的性能对比:
测试10万次序列化:
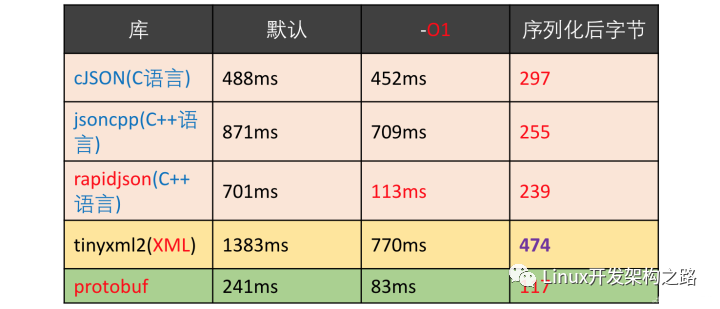
测试10万次反序列化:

1.2.2 缺点:
① 自解释性较差,数据存储格式为二进制,需要通过 .proto 文件才能了解到内部的数据结构;
② 不适合用来对 基于文本的标记文档(如HTML) 建模。
1.3 protobuf中的数据类型限定修饰符:
protobuf 2 中有三种数据类型限定修饰符:
required表示字段必选,optional表示字段可选,repeated表示一个数组类型。
其中, required 和 optional 已在 proto3 弃用了。
1.4 protobuf中常用的数据类型:
double, 64位浮点数
float, 32位浮点数
int32, 32位整数
int64, 64位整数
uint64, 64位无符号整数
sint32, 32位整数,处理负数效率更高
sint64, 64位整数,处理负数效率更高
string, 只能处理ASCII字符
bytes, 用于处理多字节的语言字符
enum, 枚举类型
二、protobuf的使用流程:
下载protobuf压缩包后,解压、配置、编译、安装,即可使用 protoc 命令 查看Linux中是否安装成功:
libprotoc 3.15.8
使用protobuf时,需要先根据应用需求编写 .proto 文件 定义消息体格式,例如:
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
int32 id = 1;
repeated string name = 2;
}
其中,syntax 关键字表示使用的protobuf的版本,如不指定则默认使用 "proto2";package关键字 表示“包”,生成目标语言文件后对应C++中的namespace命名空间,用于防止不同的消息类型间的命名冲突。
(syntax单词字面含义:句法,句法规则,语构)
然后使用 protobuf编译器(protoc命令)将编写好的 .proto 文件生成 目标语言文件(例如目标语言是C++,则会生成 .cc 和 .h 文件),例如:
其中:
**SRC_DIR 表示 .proto文件所在的源目录;**DST_DIR 表示生成目标语言代码的目标目录;xxx.proto 表示要对哪个.proto文件进行解析;--cpp_out 表示生成C++代码。
编译完成后,将会在目标目录中生成 xxx.pb.h 和 pb.cc, 文件,将其引入到我们的C++工程中即可实现使用protobuf进行序列化:
在C++源文件中包含 xxx.pb.h 头文件,在g++编译时链接 xxx.pb.cc源文件即可:
三、C++使用protobuf实现序列化的示例:
在protobuf源码中的 /examples 目录下有官方提供的protobuf使用示例:addressbook.proto
参考官方示例实现C++使用protobuf进行序列化和反序列化:
addressbook.proto :
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
}
生成的addressbook.pb.h 文件内容摘要:
class Person;
class Person_PhoneNumber;
};
class Person_PhoneNumber : public MessageLite {
public:
Person_PhoneNumber();
virtual ~Person_PhoneNumber();
public:
//string number = 1;
void clear_number();
const string& number() const;
void set_number(const string& value);
//int32 id = 2;
void clear_id();
int32 id() const;
void set_id(int32 value);
//string email = 3;
//...
};
add_person.cpp :
#include
#include
#include "pbs/addressbook.pb.h"
using namespace std;
void serialize_process() {
cout << "serialize_process" << endl;
tutorial::Person person;
person.set_name("Obama");
person.set_id(1234);
person.set_email("1234@qq.com");
tutorial::Person::PhoneNumber *phone1 = person.add_phones();
phone1->set_number("110");
phone1->set_type(tutorial::Person::MOBILE);
tutorial::Person::PhoneNumber *phone2 = person.add_phones();
phone2->set_number("119");
phone2->set_type(tutorial::Person::HOME);
fstream output("person_file", ios::out | ios::trunc | ios::binary);
if( !person.SerializeToOstream(&output) ) {
cout << "Fail to SerializeToOstream." << endl;
}
cout << "person.ByteSizeLong() : " << person.ByteSizLong() << endl;
}
void parse_process() {
cout << "parse_process" << endl;
tutorial::Person result;
fstream input("person_file", ios::in | ios::binary);
if(!result.ParseFromIstream(&input)) {
cout << "Fail to ParseFromIstream." << endl;
}
cout << result.name() << endl;
cout << result.id() << endl;
cout << Buy and Sell Domain Names() << endl;
for(int i = 0; i < result.phones_size(); ++i) {
const tutorial::Person::PhoneNumber &person_phone = result.phones(i);
switch(person_phone.type()) {
case tutorial::Person::MOBILE :
cout << "MOBILE phone : ";
break;
case tutorial::Person::HOME :
cout << "HOME phone : ";
break;
case tutorial::Person::WORK :
cout << "WORK phone : ";
break;
default:
cout << "phone type err." << endl;
}
cout << person_phone.number() << endl;
}
}
int main(int argc, char *argv[]) {
serialize_process();
parse_process();
google::protobuf::ShutdownProtobufLibrary(); //删除所有已分配的内存(Protobuf使用的堆内存)
return 0;
}
输出结果:
person.ByteSizeLong() : 39
[parse_process]
Obama
1234
1234@qq.com
MOBILE phone : 110
HOME phone : 119
3.1 protobuf提供的序列化和反序列化的API接口函数:
public:
//序列化:
bool SerializeToOstream(ostream* output) const;
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input);
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};
三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应用场景使用。
序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容, 而是将序列化的结果保存到函数入参指定的地址中。
3.2 .proto文件中的 option 选项:
.proto文件中的option选项用于配置protobuf编译后生成目标语言文件中的代码量,可设置为 SPEED, CODE_SIZE, LITE_RUNTIME 三种。
默认option选项为 SPEED,常用的选项为 LITE_RUNTIME。
三者的区别在于:
① SPEED(默认值):表示生成的代码运行效率高,但是由此生成的代码编译后会占用更多的空间。② CODE_SIZE:与SPEED恰恰相反,代码运行效率较低,但是由此生成的代码编译后会占用更少的空间,
通常用于资源有限的平台,如Mobile。③ LITE_RUNTIME:生成的代码执行效率高,同时生成代码编译后的所占用的空间也非常少。这是以牺牲Protobuf提供的反射功能为代价的。因此我们在C++中链接Protobuf库时仅需链接libprotobuf-lite,而非protobuf。
SPEED 和 LITE_RUNTIME相比,在于调试级别上,例如 msg.SerializeToString(&str); 在 SPEED 模式下会利用反射机制打印出详细字段和字段值,但是 LITE_RUNTIME 则仅仅打印字段值组成的字符串。
因此:可以在调试阶段使用 SPEED 模式,而上线以后提升性能使用 LITE_RUNTIME 模式优化。
最直观的区别是使用三种不同的 option 选项时,编译后产生的 .pb.h 中自定义的类所继承的 protobuf类不同:
// .proto 文件:
option optimize_for = SPEED;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//2. CODE_SIZE模式:(自定义的类继承自 Message 类)
// .proto 文件:
option optimize_for = CODE_SIZE;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//3. LITE_RUNTIME模式:(自定义的类继承自 MessageLite 类)
// .proto 文件:
option optimize_for = LITE_RUNTIME;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::MessageLite {};
四、protobuf的编码和存储方式:
① protobuf 将消息里的每个字段进行编码后,再利用TLV或者TV的方式进行数据存储;
② protobuf 对于不同类型的数据会使用不同的编码和存储方式;
③ protobuf 的编码和存储方式是其性能优越、数据体积小的原因。
-
存储
+关注
关注
13文章
4257浏览量
85647 -
编码
+关注
关注
6文章
935浏览量
54759 -
函数指针
+关注
关注
2文章
56浏览量
3775
发布评论请先 登录
相关推荐
【LeMaker Guitar试用体验】8.Lemuntu系统中编译protobuf源代码和简单示例
存储器的编码方法
利用protobuf通信原理
什么是protobuf?怎么使用?
基于加密技术和编码技术的存储分割编码技术
protobuf是什么?protobuf有什么作用支持什么数据类型?
深入剖析ProtoBuf原理与工程实践






 工商网监
工商网监
评论