 如何正确保护共享数据编写并行程序
如何正确保护共享数据编写并行程序
非阻塞型同步 (Non-blocking Synchronization) 简介
如何正确有效的保护共享数据是编写并行程序必须面临的一个难题,通常的手段就是同步。同步可分为阻塞型同步(Blocking Synchronization)和非阻塞型同步( Non-blocking Synchronization)。
阻塞型同步是指当一个线程到达临界区时,因另外一个线程已经持有访问该共享数据的锁,从而不能获取锁资源而阻塞,直到另外一个线程释放锁。常见的同步原语有 mutex、semaphore 等。如果同步方案采用不当,就会造成死锁(deadlock),活锁(livelock)和优先级反转(priority inversion),以及效率低下等现象。
为了降低风险程度和提高程序运行效率,业界提出了不采用锁的同步方案,依照这种设计思路设计的算法称为非阻塞型算法,其本质特征就是停止一个线程的执行不会阻碍系统中其他执行实体的运行。
比较流行的 Non-blocking Synchronization 实现方案有三种:
- 1、Wait-free
- Wait-free 是指任意线程的任何操作都可以在有限步之内结束,而不用关心其它线程的执行速度。Wait-free 是基于 per-thread 的,可以认为是 starvation-free 的。非常遗憾的是实际情况并非如此,采用 Wait-free 的程序并不能保证 starvation-free,同时内存消耗也随线程数量而线性增长。目前只有极少数的非阻塞算法实现了这一点。
- 2、Lock-free
- Lock-Free 是指能够确保执行它的所有线程中至少有一个能够继续往下执行。由于每个线程不是 starvation-free 的,即有些线程可能会被任意地延迟,然而在每一步都至少有一个线程能够往下执行,因此系统作为一个整体是在持续执行的,可以认为是 system-wide 的。所有 Wait-free 的算法都是 Lock-Free 的。
- 3、Obstruction-free
- Obstruction-free 是指在任何时间点,一个孤立运行线程的每一个操作可以在有限步之内结束。只要没有竞争,线程就可以持续运行。一旦共享数据被修改,Obstruction-free 要求中止已经完成的部分操作,并进行回滚。所有 Lock-Free 的算法都是 Obstruction-free 的。
综上所述,不难得出 Obstruction-free 是 Non-blocking synchronization 中性能最差的,而 Wait-free 性能是最好的,但实现难度也是最大的,因此 Lock-free 算法开始被重视,并广泛运用于正在运行的程序中,比如 linux 内核。
一般采用原子级的 read-modify-write 原语来实现 Lock-Free 算法,其中 LL 和 SC 是 Lock-Free 理论研究领域的理想原语,但实现这些原语需要 CPU 指令的支持,非常遗憾的是目前没有任何 CPU 直接实现了 SC 原语。根据此理论,业界在原子操作的基础上提出了著名的 CAS(Compare - And - Swap)操作来实现 Lock-Free 算法,Intel 实现了一条类似该操作的指令:cmpxchg8。
CAS 原语负责将某处内存地址的值(1 个字节)与一个期望值进行比较,如果相等,则将该内存地址处的值替换为新值,CAS 操作伪码描述如下:
清单 1. CAS 伪码
{
if( *addr == expected )
{
*addr = newValue;
return true;
}
else
return false;
}
在实际开发过程中,利用 CAS 进行同步,代码如下所示:
清单 2. CAS 实际操作
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
加锁的层级
根据复杂程度、加锁粒度及运行速度,可以得出如下图所示的锁层级:
图 1. 加锁层级
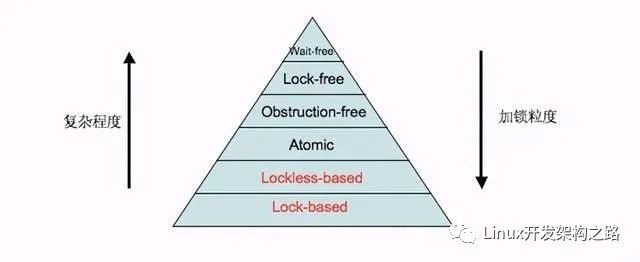
其中标注为红色字体的方案为 Blocking synchronization,黑色字体为 Non-blocking synchronization。Lock-based 和 Lockless-based 两者之间的区别仅仅是加锁粒度的不同。图中最底层的方案就是大家经常使用的 mutex 和 semaphore 等方案,代码复杂度低,但运行效率也最低。
Linux 内核中的无锁分析
Linux 内核可能是当今最大最复杂的并行程序之一,它的并行主要来至于中断、内核抢占及 SMP 等。内核设计者们为了不断提高 Linux 内核的效率,从全局着眼,逐步废弃了大内核锁来降低锁的粒度;从细处下手,不断对局部代码进行优化,用无锁编程替代基于锁的方案,如 seqlock 及 RCU 等;不断减少锁冲突程度、降低等待时间,如 Double-checked locking 和原子锁等。
内核无锁第一层级 — 少锁
无论什么时候当临界区中的代码仅仅需要加锁一次,同时当其获取锁的时候必须是线程安全的,此时就可以利用 Double-checked Locking 模式来减少锁竞争和加锁载荷。目前 Double-checked Locking 已经广泛应用于单例 (Singleton) 模式中。内核设计者基于此思想,巧妙的将 Double-checked Locking 方法运用于内核代码中。
当一个进程已经僵死,即进程处于 TASK_ZOMBIE 状态,如果父进程调用 waitpid() 系统调用时,父进程需要为子进程做一些清理性的工作,代码如下所示:
清单 3. 少锁操作
985 struct siginfo __user *infop,
986 int __user *stat_addr, struct rusage __user *ru)
987 {
……
1103 if (p->real_parent != p->parent) {
1104 write_lock_irq(&tasklist_lock);
1105 /* Double-check with lock held. */
1106 if (p->real_parent != p->parent) {
1107 __ptrace_unlink(p);
1108 // TODO: is this safe?
1109 p->exit_state = EXIT_ZOMBIE;
……
1120 }
1121 write_unlock_irq(&tasklist_lock);
1122 }
……
1127 }
如果将 write_lock_irq 放置于 1103 行之前,锁的范围过大,锁的负载也会加重,影响效率;如果将加锁的代码放到判断里面,且没有 1106 行的代码,程序会正确吗?在单核情况下是正确的,但在双核情况下问题就出现了。一个非主进程在一个 CPU 上运行,正准备调用 exit 退出,此时主进程在另外一个 CPU 上运行,在子进程调用 release_task 函数之前调用上述代码。子进程在 exit_notify 函数中,先持有读写锁 tasklist_lock,调用 forget_original_parent。主进程运行到 1104 处,由于此时子进程先持有该锁,所以父进程只好等待。在 forget_original_parent 函数中,如果该子进程还有子进程,则会调用 reparent_thread(),将执行 p->parent = p->real_parent; 语句,导致两者相等,等非主进程释放读写锁 tasklist_lock 时,另外一个 CPU 上的主进程被唤醒,一旦开始执行,继续运行将会导致 bug。
严格的说,Double-checked locking 不属于无锁编程的范畴,但由原来的每次加锁访问到大多数情况下无须加锁,就是一个巨大的进步。同时从这里也可以看出一点端倪,内核开发者为了降低锁冲突率,减少等待时间,提高运行效率,一直在持续不断的进行改进。
内核无锁第二层级 — 原子锁
原子操作可以保证指令以原子的方式执行——执行过程不被打断。内核提供了两组原子操作接口:一组针对于整数进行操作,另外一组针对于单独的位进行操作。内核中的原子操作通常是内联函数,一般是通过内嵌汇编指令来完成。对于一些简单的需求,例如全局统计、引用计数等等,可以归结为是对整数的原子计算。
内核无锁第三层级 — Lock-free
- Lock-free 应用场景一 —— Spin Lock
Spin Lock 是一种轻量级的同步方法,一种非阻塞锁。当 lock 操作被阻塞时,并不是把自己挂到一个等待队列,而是死循环 CPU 空转等待其他线程释放锁。Spin lock 锁实现代码如下:
清单 4. spin lock 实现代码
{
……
do {
preempt_enable();
while (spin_is_locked(lock))
cpu_relax();
preempt_disable();
} while (!_raw_spin_trylock(lock));
}
static inline int _raw_spin_trylock(spinlock_t *lock)
{
char oldval;
__asm__ __volatile__(
"xchgb %b0,%1"
:"=q" (oldval), "=m" (lock->lock)
:"0" (0) : "memory");
return oldval > 0;
}
汇编语言指令 xchgb 原子性的交换 8 位 oldval( 存 0) 和 lock->lock 的值,如果 oldval 为 1(lock 初始值为 1),则获取锁成功,反之,则继续循环,接着 relax 休息一会儿,然后继续周而复始,直到成功。
对于应用程序来说,希望任何时候都能获取到锁,也就是期望 lock->lock 为 1,那么用 CAS 原语来描述 _raw_spin_trylock(lock) 就是 CAS(lock->lock,1,0);
如果同步操作总是能在数条指令内完成,那么使用 Spin Lock 会比传统的 mutex lock 快一个数量级。Spin Lock 多用于多核系统中,适合于锁持有时间小于将一个线程阻塞和唤醒所需时间的场合。
pthread 库已经提供了对 spin lock 的支持,所以用户态程序也能很方便的使用 spin lock 了,需要包含 pthread.h 。在某些场景下,pthread_spin_lock 效率是 pthread_mutex_lock 效率的一倍多。美中不足的是,内核实现了读写 spin lock 锁,但 pthread 未能实现。
- Lock -free 应用场景二 —— Seqlock
手表最主要最常用的功能是读时间,而不是校正时间,一旦后者成了最常用的功能,消费者肯定不会买账。计算机的时钟也是这个功能,修改时间是小概率事件,而读时间是经常发生的行为。以下代码摘自 2.4.34 内核:
清单 5. 2.4.34 seqlock 实现代码
444 {
……
448 read_lock_irqsave(&xtime_lock, flags);
……
455 sec = xtime.tv_sec;
456 usec += xtime.tv_usec;
457 read_unlock_irqrestore(&xtime_lock, flags);
……
466 }
468 void do_settimeofday(struct timeval *tv)
469 {
470 write_lock_irq(&xtime_lock);
……
490 write_unlock_irq(&xtime_lock);
491 }
不难发现获取时间和修改时间采用的是 spin lock 读写锁,读锁和写锁具有相同的优先级,只要读持有锁,写锁就必须等待,反之亦然。
Linux 2.6 内核中引入一种新型锁——顺序锁 (seqlock),它与 spin lock 读写锁非常相似,只是它为写者赋予了较高的优先级。也就是说,即使读者正在读的时候也允许写者继续运行。当存在多个读者和少数写者共享一把锁时,seqlock 便有了用武之地,因为 seqlock 对写者更有利,只要没有其他写者,写锁总能获取成功。根据 lock-free 和时钟功能的思想,内核开发者在 2.6 内核中,将上述读写锁修改成了顺序锁 seqlock,代码如下:
清单 6. 2.6.10 seqlock 实现代码
{
unsigned ret = sl->sequence;
smp_rmb();
return ret;
}
static inline int read_seqretry(const seqlock_t *sl, unsigned iv)
{
smp_rmb();
return (iv & 1) | (sl->sequence ^ iv);
}
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
++sl->sequence;
smp_wmb();
}
void do_gettimeofday(struct timeval *tv)
{
unsigned long seq;
unsigned long usec, sec;
unsigned long max_ntp_tick;
……
do {
unsigned long lost;
seq = read_seqbegin(&xtime_lock);
……
sec = xtime.tv_sec;
usec += (xtime.tv_nsec / 1000);
} while (read_seqretry(&xtime_lock, seq));
……
tv->tv_sec = sec;
tv->tv_usec = usec;
}
int do_settimeofday(struct timespec *tv)
{
……
write_seqlock_irq(&xtime_lock);
……
write_sequnlock_irq(&xtime_lock);
clock_was_set();
return 0;
}
Seqlock 实现原理是依赖一个序列计数器,当写者写入数据时,会得到一把锁,并且将序列值加 1。当读者读取数据之前和之后,该序列号都会被读取,如果读取的序列号值都相同,则表明写没有发生。反之,表明发生过写事件,则放弃已进行的操作,重新循环一次,直至成功。不难看出,do_gettimeofday 函数里面的 while 循环和接下来的两行赋值操作就是 CAS 操作。
采用顺序锁 seqlock 好处就是写者永远不会等待,缺点就是有些时候读者不得不反复多次读相同的数据直到它获得有效的副本。当要保护的临界区很小,很简单,频繁读取而写入很少发生(WRRM--- Write Rarely Read Mostly)且必须快速时,就可以使用 seqlock。但 seqlock 不能保护包含有指针的数据结构,因为当写者修改数据结构时,读者可能会访问一个无效的指针。
- Lock -free 应用场景三 —— RCU
在 2.6 内核中,开发者还引入了一种新的无锁机制 -RCU(Read-Copy-Update),允许多个读者和写者并发执行。RCU 技术的核心是写操作分为写和更新两步,允许读操作在任何时候无阻碍的运行,换句话说,就是通过延迟写来提高同步性能。RCU 主要应用于 WRRM 场景,但它对可保护的数据结构做了一些限定:RCU 只保护被动态分配并通过指针引用的数据结构,同时读写控制路径不能有睡眠。以下数组动态增长代码摘自 2.4.34 内核:
清单 7. 2.4.34 RCU 实现代码
其中 ipc_lock 是读者,grow_ary 是写者,不论是读或者写,都需要加 spin lock 对被保护的数据结构进行访问。改变数组大小是小概率事件,而读取是大概率事件,同时被保护的数据结构是指针,满足 RCU 运用场景。以下代码摘自 2.6.10 内核:
清单 8. 2.6.10 RCU 实现代码
#define rcu_read_unlock() preempt_enable()
#define rcu_assign_pointer(p, v) ({
smp_wmb();
(p) = (v);
})
struct kern_ipc_perm* ipc_lock(struct ipc_ids* ids, int id)
{
……
rcu_read_lock();
entries = rcu_dereference(ids->entries);
if(lid >= entries->size) {
rcu_read_unlock();
return NULL;
}
out = entries->p[lid];
if(out == NULL) {
rcu_read_unlock();
return NULL;
}
……
return out;
}
static int grow_ary(struct ipc_ids* ids, int newsize)
{
struct ipc_id_ary* new;
struct ipc_id_ary* old;
……
new = ipc_rcu_alloc(sizeof(struct kern_ipc_perm *)*newsize +
sizeof(struct ipc_id_ary));
if(new == NULL)
return size;
new->size = newsize;
memcpy(new->p, ids->entries->p, sizeof(struct kern_ipc_perm *)*size
+sizeof(struct ipc_id_ary));
for(i=size;i new->p[i] = NULL;
}
old = ids->entries;
/*
* Use rcu_assign_pointer() to make sure the memcpyed contents
* of the new array are visible before the new array becomes visible.
*/
rcu_assign_pointer(ids->entries, new);
ipc_rcu_putref(old);
return newsize;
};i++)>
纵观整个流程,写者除内核屏障外,几乎没有一把锁。当写者需要更新数据结构时,首先复制该数据结构,申请 new 内存,然后对副本进行修改,调用 memcpy 将原数组的内容拷贝到 new 中,同时对扩大的那部分赋新值,修改完毕后,写者调用 rcu_assign_pointer 修改相关数据结构的指针,使之指向被修改后的新副本,整个写操作一气呵成,其中修改指针值的操作属于原子操作。在数据结构被写者修改后,需要调用内存屏障 smp_wmb,让其他 CPU 知晓已更新的指针值,否则会导致 SMP 环境下的 bug。当所有潜在的读者都执行完成后,调用 call_rcu 释放旧副本。同 Spin lock 一样,RCU 同步技术主要适用于 SMP 环境。
内核无锁第四层级 — 免锁
环形缓冲区是生产者和消费者模型中常用的数据结构。生产者将数据放入数组的尾端,而消费者从数组的另一端移走数据,当达到数组的尾部时,生产者绕回到数组的头部。
如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(Ring Buffer)。写入索引只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据结构。同理,读取索引也只允许消费者访问并修改。
图 2. 环形缓冲区实现原理图
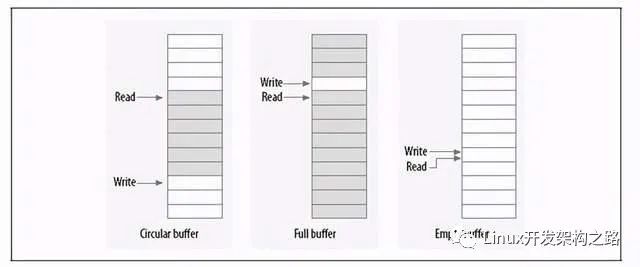
如图所示,当读者和写者指针相等时,表明缓冲区是空的,而只要写入指针在读取指针后面时,表明缓冲区已满。
清单 9. 2.6.10 环形缓冲区实现代码
* __kfifo_put - puts some data into the FIFO, no locking version
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}
/*
* __kfifo_get - gets some data from the FIFO, no locking version
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}
以上代码摘自 2.6.10 内核,通过代码的注释(斜体部分)可以看出,当只有一个消费者和一个生产者时,可以不用添加任何额外的锁,就能达到对共享数据的访问。
总结
通过对比 2.4 和 2.6 内核代码,不得不佩服内核开发者的智慧,为了提高内核性能,一直不断的进行各种优化,并将业界最新的 lock-free 理念运用到内核中。
在实际开发过程中,进行无锁设计时,首先进行场景分析,因为每种无锁方案都有特定的应用场景,接着根据场景分析进行数据结构的初步设计,然后根据先前的分析结果进行并发模型建模,最后在调整数据结构的设计,以便达到最优。
-
数据
+关注
关注
8文章
7045浏览量
89062 -
线程
+关注
关注
0文章
505浏览量
19690 -
并行程序
+关注
关注
0文章
4浏览量
5895
发布评论请先 登录
相关推荐
面向多核处理器的低级并行程序验证
AD7606并行读取数据没有读出正确的数据
如何确保正确的到达顺序读取正确的数据?
单片机前后台顺序执行程序
MPI并行程序设计的负载平衡实现方法
正确保护iSCSI存储系统的五大绝招
串行程序如何并行化,串行和并行的区别
消息传递并行程序的变异测试
支持容错的任务并行程序设计模型FT-TPP
自制CPU(四)程序编写
如何使用OpenMP实现电磁场FDTD多核并行程序的设计







 工商网监
工商网监
评论