 TCMalloc 的架构设计细节
TCMalloc 的架构设计细节
本节将专注于TCMalloc 的架构设计细节,来整体看一下TCMalloc 的设计特性。
主要的几个特性如下:
- 高性能。大多数对象的分配和释放都不需要产生太多的竞争,因为tcmalloc 维护了thread-cache 来提供当前线程的内存分配需求。所以,应用大多数的内存申请需求不会有锁的竞争,而且在多核场景有较好的扩展性。
- 灵活的使用内存资源。用户不使用的内存,tcmalloc会选择服复用或者归还操作系统。
- 降低了每个请求的内存开销。通过分配相同大小的page 降低内存使用的开销,这在小对象场景较为有效。
- 内部信息统计开销较低。能够开启细粒度的应用内存占用信息,来帮助用户展示tcmalloc内部内存使用的细节。
如何使用
安装tcmalloc,应用编译加入 -ltcmalloc即可默认将glibc的malloc 替换为tcmalloc的malloc 。
架构概览
前面的文章中在介绍整体的tcmalloc的时候已经介绍过了,大体分为三个部分:

- Front-end,主要维护线程cache,用来为应用提供 快速分配以及释放内存的需求。
- Middle-end,主要负责为font-end 中的thread-cache 填充内存。
- back-end,负责从os直接获取内存。
需要注意的是front-end 的 thread-cache 可以在每一个cpu下维护 或者 每一个线程下维护,back-end` 则能够支持大内存的pageheap管理,也能支持小内存的pageheap 管理。
接下来,我们进入每一个组件详细看一下其设计细节。
1. TCMalloc Front-end
Front-end 提供了Cache ,能够缓存一部分内存 用来分配给应用 ,也能够持有应用释放的内存。这个Cache 作为per-cpu/per-thread 存在,其同一时刻只能由一个线程访问,所以本身不需要任何的锁,这也是多线程下内存分配释放高效的原因。
如果Front-end 持有的内存大小足够,其能够满足应用线程任何内存需求。如果持有的内存为空了,那它会从 middle-end 组件请求一批内存页进行填充。
Middle-end 是由 CentralFreeList 和 TransferCache 两部分组成,后续会详细介绍这两个组件。
如果用户请求的内存大小超过了front-end 本身能缓存的大小(大内存需求),或者middle-end 缓存的内存页也被用尽了,那这个时候会直接让从back-end分配内存给用户。
Front-end 在 TCMalloc 的演进过程中有两种类型的实现:
- 最开始的时候只支持 per-thread 的cache 模式,这也是TCMalloc 名字 Thread-Cacheing malloc的由来。然而这种场景会随着用户线程的大量增加,出现了一些内存问题:每个线程只能有极小的thread-cache,需要消耗较多的CPU资源来聚合每个线程的内存资源。
- 较新版本的TCMalloc 支持了 per-CPU 模式。这种模式下每一个逻辑CPU 会有自己的的thread-cache 用来为运行在这个cpu的现场分配内存。在x86系统上,每一个逻辑cpu 和 一个超线程等价,我们lscpu 命令看到的cpu core是包括超线程的个数在内的。
1.1 小对象和大对象的内存分配过程
针对小内存对象的分配,Front-end的cache 会按照其大小将其映射到 60-80个size-classes 中的一个,实际的内存分配会按照该大小对应的size-class 的大小进行分配,size-class也是front-end 分配内存的粒度。
比如12B 的对象会best-fit到16B 的size-class中。设置这么多的size-class 还是为了尽可能得降低内存的浪费,比如原本的内存分配粒度都是2的n次幂,那对于23字节的内存需求就需要分配一个32字节的内存区域,而在tcmalloc的size-class的配置中只需要分配24字节即可。
Tcmalloc 在编译的时候可以配置 size-class 的 内存分配是按照多少 Bytes 对齐,比如指定了__STDCPP_DEFAULT_NEW_ALIGNMENT__ <= 8,那size-class 内部可选的内存大小配置就是 8bytes 对齐,即8 bytes的倍数。如果编译时指定了大于 8bytes,那后续所有的 ::operator new 的内存申请都会按照 16 bytes 进行对齐。
对于大内存需求的对象来说,内存大小的需求超过kMaxSize 256K,则会直接从back-end 分配。因此,这一部分的内存需求不会缓存再 front-end 以及 middle-end 中,由back-end的page-heap 进行管理。对于大内存对象的实际内存分配会按照tcmalloc page size 进行对齐。
1.2 内存释放过程
如果要释放一个对象,编译期间如果能够知道这个对象的大小,编译器会直接告诉分配器这个对象的大小。大多数的时候,编译期间并不清楚对象的大小,会从pagemap中查找这个对象。如果这个对象是一个小内存对象,释放的时候会告诉front-end cache进行管理,如果是一个超过kMaxSize 的对象,则会直接释放给back-end 的 pageheap。
1.3 Per-CPU mode
Per-cpu mode 和 per-thread mode 是 tcmalloc 的font-end 主体部分的两种模式。因为per-thread mode 受到系统进程的线程数的影响,在大量线程的情况下会让每个thread-cache 只能够处理一小部分的内存申请释放需求,还会消耗大量的cpu 来 由middle-end 进行不同thread-cache 之间的内存迁移。
所以 tcmalloc 提供了优化版本的 per-cpu mode,即每一个逻辑核 维护一个 ‘cpu-cache’ ,用来处理运行在当前核的线程的内存申请/释放需求。
大体形态如下:
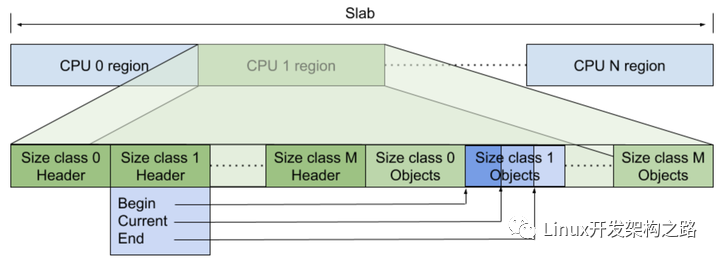
Per-cpu mode 下会申请一个大内存块(也可以称为slab),这个slab 会被多个cpu共享,其中每一个cpu会 持有slab 的一部分内存,并在其上存储一系列元数据管理对应线程的内存对象。
上图中的cpu1 会管理 on slab 的绿色部分内存区域,在这一部分区域中会先存储一些元数据和指针来管理不同大小的 size-classes 的内存对象。其中元数据中包含一个header指针 和 每一个size-class 的索引block。
每一个size-class 的header 指针数据结构会有指向某一种实际存储内存对象的指针数组,即是一个数组,每一个元素是一个指针,总共是三个指针,分别指向这一种size-class 内存对象区域的起始地址块,当前地址块(后续分配这个size-class 大小对象的时候会从current 开始分配),最大地址。
每一个cpu 能够缓存的内存大小是通过SetMaxPerCpuCacheSize 配置的,也就是当前font-end 能够缓存的内存总大小取决去当前系统的cpu核心数,拥有更好核心数的机器使用tcmalloc 能够缓存更多的内存。为了避免 perf-cpu 长时间持有内存,tcmalloc 允许通过MallocExtension::ReleaseCpuMemory 接口来 指定释放某一个cpu的内存。
void MallocExtension::SetMaxPerCpuCacheSize(int32_t value) {
#if ABSL_INTERNAL_HAVE_WEAK_MALLOCEXTENSION_STUBS
if (MallocExtension_Internal_SetMaxPerCpuCacheSize == nullptr) {
return;
}
MallocExtension_Internal_SetMaxPerCpuCacheSize(value); // 实际的执行函数
#else
(void)value;
#endif
}
// 释放某一个cpu cache的内存
size_t MallocExtension::ReleaseCpuMemory(int cpu) {
#if ABSL_INTERNAL_HAVE_WEAK_MALLOCEXTENSION_STUBS
if (MallocExtension_Internal_ReleaseCpuMemory != nullptr) {
return MallocExtension_Internal_ReleaseCpuMemory(cpu);
}
#endif
return 0;
}
当每一个cpu cache 的内存被分配耗尽,想要从 middle-end 获取内存来缓存更多的对象时,也需要考虑对size-class进行扩容。如果这个size-class 的内存分配需求还在持续增加,则这个size-class的容量会持续增加,直到达到这个size-class 容量的hard-code。
1.4 Per-thread mode
用户可以指定使用某一个thread 的cache,也就是指定thread-local cache。小内存的申请和释放会根据thread-cache的需求在middle-end 之间迁移。
每一个 thread-cache 内部 不同size-class 对象会各自构造一个单链表(如果有 n 个size-classes,也就会有对应 n 个单链表),类似如下图:
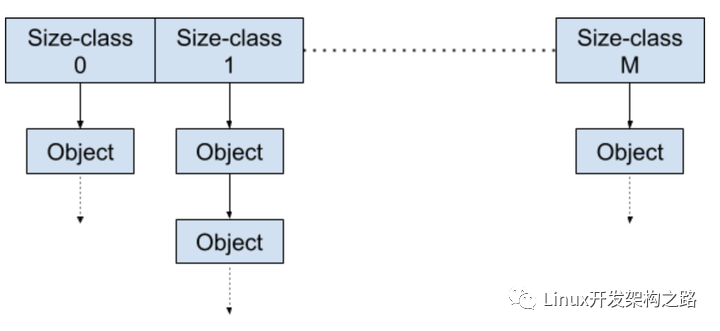
分配某一个对应size-class 对象的时候,对应 size-class 链表对象会被从单链表移除(free-list),表示这个指针对应地址的内存可以被用户使用。释放对象的时候,则会将这个对象地址追加到thread-cache 管理的 size-class 的链表。
在这个过程中,如果thread-cache 管理的内存不够,或者超限,则会从 middle-end 获取更多的内存对象或者将多余的内存对象释放给 middle-end。
对于per-thread caches来说,可以通过 MallocExtension::SetMaxTotalThreadCacheBytes 设置最大的可用内存大小。每一个线程有自己的最小的 thread-cache 大小 KMinThreadCacheSize 512K,如果当前线程内存申请需求较大,内存容量也会通过middle-end 将其他线程的可用内存迁移到当前线程。
通过 middle-end 来协调当前的thread-cache 内存,通过ThreadCache::Scavenge(); 进行。
如果当前线程退出,则会将自己的thread-cache 的内存返回给 middle-end。
1.5 per-cpu 和 per-thread 运行时内存管理算法对比
对于thread-cache 和 per-cpu cache来说,在应用程序运行的时候如果 front-end 的cache 内存太小,那就需要频繁从 central-freelist 也就是 middle-end 中获取内存;但如果太大,就会让过多的内存被闲置。如何配置一个合理的 front-end cache 的大小,这里两种模式都提供了动态配置 cache大小的算法。
- Per-thread 模式下,cache 内部的最大存储对象容量 达到当前最大阈值时就会从middle-end 获取更多的对象,从而增大这个限制。降低最大限制的前提是发现了较多的未被使用的对象,则会将这一些对象根据需求还给middle-end。
- Per-cpu 模式下,增加cache 容量的前提是当前cache 是否在频繁的从 middle-end 获取内存 以及 释放内存交替,则需增加容量限制,有更多的空间来缓存这一些内存对象。降低容量限制的前提是发现有一些空闲容量长时间没有被使用。
这里在代码细节上有很多的设计,比如如何设置合理的空闲时间的长度?如何界定 内存申请是频繁的?都是一些动态规划的最优思想的设计,值得去探索代码细节。
2. TCMalloc Middle-end
到此,font-end 部分大体设计描述完。从前面的设计中可以看到,middle-end 的作用在 per-cpu和per-thread 模式都有非常重要的作用。
Middle-end 的主要作用为 font-end 提供内存申请需求,并将空闲内存返回给 back-end。
Middle-end 的组成主要有 Transfer cache 和 Central free list。对于每一个size-class,都会有有一个各自的 transfer cache 和 central free list。这一些caches 会有自己的 mutex lock,所以对于这一些cache的访问, 因为锁粒度较低,则不会有过多的冲突,保证了访问的性能。
2.1 Transfer Cache
当 front-end 请求内存 或者 释放内存的时候,会先到达 transfer cache。
Transfer cache 会持有 一个数组指针进行内存的释放 或者 将新的内存对象填充进来并返回给font-end。
Transfer cache 会将一个cpu/tthread 释放的内存分配给另一个cpu/thread 对内存的需求,这个类似于内存池的 内存对象流动在两个不同的cpu/threads 之间可以非常迅速。
2.2 Central Free List
Central free list 通过 span 数据结构来管理内存,一个span 可以管理一个或者多个tcmalloc page,span 数据结构会在下文详细描述。
Font-end 如果从 central free list 请求一个或者多个内存对象的时候,central free list 会从span中提取对应大小的对象,如果此时span 没有足够的pages 返回,则会从back-end 请求更多的span。
当内存对象返回给central free list,则这一些对象会通过 pagemap 被映射到对应的span中进行管理,如果所有的对象都返回给span,这个span就可以被释放给back-end.
2.3 Pagemap 和 Spans
tcmalloc 管理的堆内存会在编译期间确定一个page-size,并将这么多内存映射为对应size的一个个page。一系列正在被使用的pages 可以被一个span 对象描述,一个span 对象可以管理一个大的内存对象,也可以按照size-class 管理多个小对象。
pagemap 则是用来查找一个内存对象属于哪一个span的,或者申请一个指定size-class 的内存对象。pagemap 是一个 2层或者3层的 radix-tree。下图展示了一个两层的 page-map 如何管理 span的,其中 spanA 管理了2个page,spanB 管理了三个page。
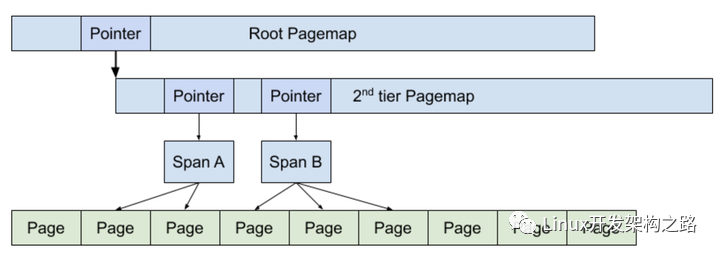
Span 这个数据结构 在 middle-end中用来 管理回收的内存对象;在back-end 用来管理 对应大小的pages,负责给central-list 提供对应大小的span。
3. TCMalloc Backend
tcmalloc 的back-end 主要有三个工作线程:
- 管理未使用的大块内存区域
- 负责从 os 中获取内存,来满足其他组件的内存需求
- 负责将其他组件不需要返回的内存,还给os
还有两个后端组件:
- legacy pageheap. 管理tcmalloc 的pages
- 管理大页内存的 pageheap。用来提升应用程序大页内存的申请需求,降低TLB的miss。
3.1 Legacy Pageheap
legacy pageheap 是一个数组的freelist,统一管理可用内存页。数组的每一个节点是一个free list,也就是单链表。一般这个数组的大小 k < 256,对于第k 个数组元素来说,它的链表中的每一个节点都管理了 k 个pages。
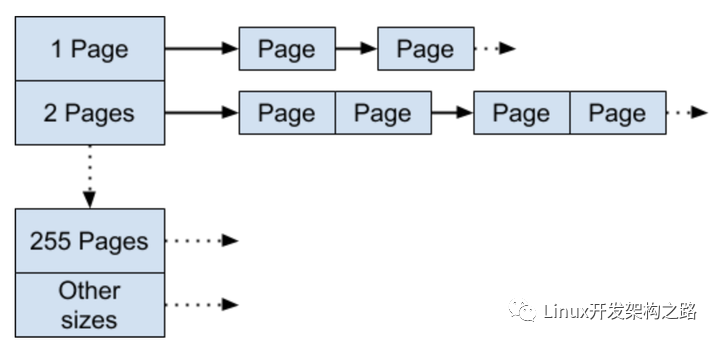
如果想要申请 k 个pages,则直接查找这个数组的第k 个元素,从free list中取一个节点即可。如果这个free list是空的,那就查找下一个数组元素的free list,直到找到一个非空的free list。如果还是失败,则直接mmap 获取内存。
当一段连续的pages 被返回给了pageheap,则会根据当前pages 是否能够形成一个连续的pages区域,然后串联这一些pages 并根据page数量 添加到对应的free list中。
3.2 大页场景分配器设计
针对hugepage 的分配器设计 是希望其能够有效持有 hugepage 大小的内存块,需要的时候能够快速分配,不需要的时候也能在合理的内存占用情况下释放给操作系统。
hugepage 在x86 系统上一般是2M 及 以上的大小,tcmalloc 的back-end 拥有三个不同的cache 来管理大页内存的分配:
- filler cache。能够持有hugepage ,并提供一些大页内存的申请需求。类似于legacy pageheap,通过一些free lists 管理pages 那样管理huge page,主要用于处理小于hugepage 大小的内存申请。
- region cache。用于大于hugepage 大小的内存申请,这个cache 允许分配多个连续的hugepage。
- hugepage cache。和region cache的功能有点重复,也是用于分配大于hugepage 的内存申请。
-
内存
+关注
关注
8文章
3040浏览量
74168 -
操作系统
+关注
关注
37文章
6859浏览量
123491 -
编译
+关注
关注
0文章
660浏览量
32925 -
malloc
+关注
关注
0文章
53浏览量
73
发布评论请先 登录
相关推荐
STM32软件架构设计的意义
对嵌入式系统中的架构设计的理解
系统架构设计的详细讲解
SWE.2的软件架构设计
SYS.3的系统架构设计
桌面操作系统的架构设计和原理细节

架构与微架构设计
SWE.2软件架构设计
如何使用tcmalloc来替换glibc的malloc






 工商网监
工商网监
评论