 NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化
NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化
通过 Merlin 大幅提升大规模深度多目标精排模型训练性能
本案例中,NVIDIA 团队与陌陌推荐系统团队深度合作,共同使用 NVIDIA GPU 和 Merlin 软件解决方案替代其原有解决方案。
通过使用 Merlin TensorFlow Plugin (即 Sparse Operation Kit,SOK) 和 HierarchicalKV(HKV),相较于原方案在相同规模模型和 GPU 下,显著提高了陌陌大规模深度多目标精排模型的训练性能。在不影响模型效果的前提下,模型整体吞吐提升了 5 倍以上,再结合通信和 IO 等进一步优化后,极限情况下可以提升 12 倍吞吐。
客户简介
挚文集团于 2011 年成立,2014 年 12 月 11 日在美国纳斯达克交易所挂牌上市(NASDAQ: MOMO),拥有陌陌、探探等多款手机应用,以及电影制作发行、节目制作等多元业务。陌陌是挚文集团于 2011 年 8 月推出的一款基于地理位置的移动视频社交应用,是中国领先的开放式社交平台之一。
训练速度面临挑战,
需有效提升算法迭代
陌陌的原始解决方案本质是基于 PS-Worker 的 CPU + GPU 混合训练方案,可支持大规模稀疏参数的训练。然而,随着用户规模的增加和业务的发展,对于推荐算法的准确度也有了更高的要求。这导致模型的复杂性和训练样本量显著增加,对单次模型训练速度和新模型算法探索效率都有更大的挑战。尽管原方案在功能上支持了大规模稀疏参数的训练,但在性能上难以满足业务日益增长的需求。因此,陌陌亟需对训练速度进行优化,加快算法迭代,以提高业务效果。
SOK 和 HKV
为推荐系统提升性能与灵活性
NVIDIA Merlin HugeCTR 是 NVIDIA 推出的可以高效利用 GPU 来进行推荐系统训练的解决方案,为了使它能直接被其他 DL 用户,比如 TensorFlow 所直接使用,NVIDIA 开发了 Merlin TensorFlow Plugin (以下简称 SOK),将 HugeCTR 中的高级特性封装为 TensorFlow 可直接调用的形式,从而帮助用户在 TensorFlow 中直接使用 HugeCTR 中的高级特性来加速他们的推荐系统。
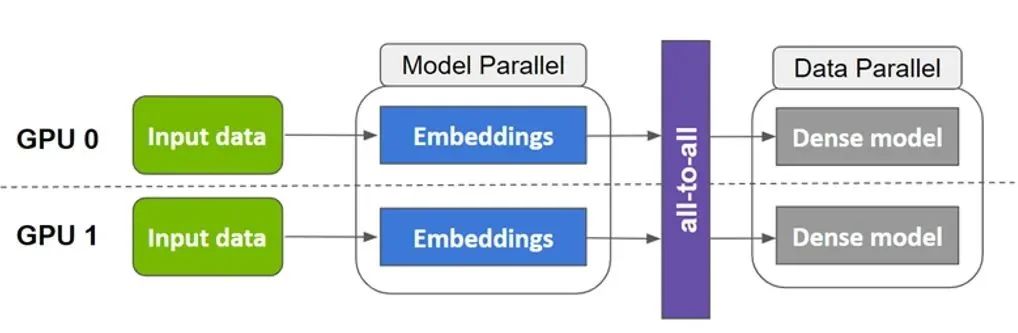
图 1. Merlin TensorFlow Plugin(SOK)模型并行示意图
Merlin TensorFlow Plugin 以数据并行的方式接收输入数据,将稀疏参数以模型并行的方式分布在多个 GPU 上,将稠密参数以数据并行的方式分布在多个 GPU 上,内部实现“数据并行-模型并行-数据并行”的转换流程。整个使用方式上尽可能的与原有 TensorFlow 算子对齐,减少对用户已有的代码的修改,以更方便、快捷地在多个 GPU 上进行扩展。此外,SOK 针对 embedding vector 的拷贝和 combiner 进行了高度优化和内核融合,使整个 lookup 的前后向过程拥有更好的性能。
Merlin HierarchicalKV (以下简称HKV)是 Merlin 下的针对于推荐系统训练设计的 KV 加速库。为兼容大模型训练支持了层次化动态 Embedding 存储(CPU+GPU),灵活的 eviction(淘汰) 机制和丰富的 API。目前已经集成入 SOK, 协同加速推荐系统 Embedding 的相关计算。
在应用了 SOK 和 HKV 后,相同规模模型和 GPU 下,陌陌精排模型的训练性能相比于原方案,整体吞吐提升了 5 倍以上。除此之外,陌陌推荐团队在当前 SOK + HKV 的架构基础上,基于业务场景特点,进一步优化整体性能,包括梯度合并,减少梯度计算的通信开销;并行特征数据读取与转换,以及特征数据预取到 GPU 等操作提速特征 IO;使用 XLA 进行编译优化,融合 kernel 以减少 kernel launch 时间;设置 GPU 亲和等操作,使得整体性能提升达到 12 倍。
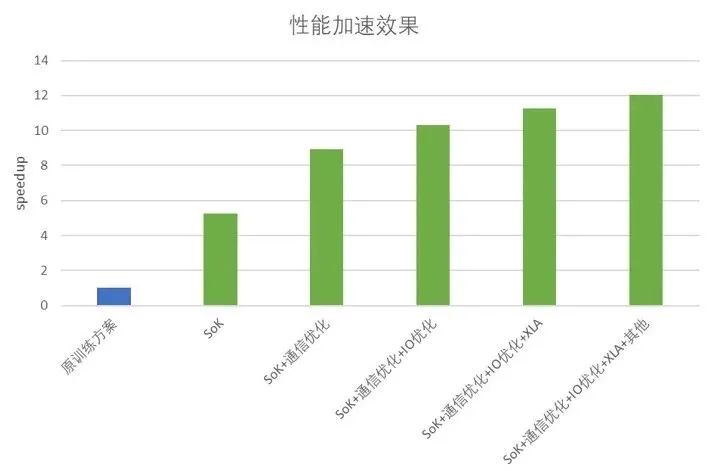
图 2. 性能加速效果
在陌陌的实际应用中,动态 Embedding 的特性大大简化了推荐系统中连续训练需人工控制显存中 embedding tab 大小的问题。而 SOK 与 HKV 为陌陌提供了完整的功能和性能支持。
除此之外,我们跟陌陌的合作过程中,也结合产品部署中的需求进一步对产品进行了性能优化和功能迭代,比如:
SOK 针对 embedding vector 的拷贝和 combiner 进行了高度优化和 kernel 融合,使整个 lookup 的前后向过程拥有更好的性能。
在陌陌 GPU 高水位线的实际业务中,基于陌陌的测试和反馈,SOK 通过优化了性能和功能的平衡点,使得其在保证性能的基础上,稳定性也大大提升。
另外,在陌陌的实际应用中,面临着模型实时训练的挑战,即需要减少对计算资源的占用,因此我们引入了 HKV,它支持了层次化动态嵌入存储(包括 CPU 和 GPU),并提供了灵活的 eviction 机制以及丰富的 API。这种引入在降低资源占用的同时,也提高了系统的灵活性。
陌陌的实际业务场景和 GPU 使用方式对于 SOK 的开发和迭代提供了非常宝贵的经验,同时陌陌的大量测试反馈也帮助 SOK 提升了应对复杂场景的能力,使得 SOK 的 feature 更加稳定和贴近客户。
持续合作:
优化推荐模型性能,降低训练成本
双方团队通过 SOK 和 HKV 对原方案进行深度优化后,成功帮助陌陌提升了 12 倍的训练效率,极大的降低了模型训练的成本和新模型算法尝试的成本。目前,整体方案已上线,全面支持陌陌推荐系统模型训练。
近期,NVIDIA 团队还与陌陌进行了基于 Transformer 的推荐模型性能优化。NVIDIA JOC 团队和 Merlin 团队基于客户的模型做了一系列性能分析,将 XLA+AMP+半精度 allreduce 应用到该模型上后,端到端性能实现了 50% 的加速。在此基础上,团队们进一步对性能热点 multi-head-attention 部分进行优化,正在将 Flash-Attention 以 tf-plugin 形式进行集成,预计此项优化集成后,整体加速比可达到 3 倍,同时整体的优化方案使得显存使用量下降约 70%,可以显著地缓解显存紧张的问题。
未来,陌陌与 NVIDIA 将继续在推荐系统训练和推理等方面持续合作,持续推进 GPU 和 AI 软件加速计算在陌陌的全面落地,期待能够为陌陌的业务及场景应用带来更大的价值。
了解更多本案例中相关的 NVIDIA 产品信息,敬请查阅:
-
NVIDIA Merlin:
https://developer.nvidia.cn/merlin
-
Merlin TensorFlow Plugin (SOK) :
https://github.com/NVIDIA-Merlin/HugeCTR/tree/main/sparse_operation_kit
-
Merlin HierarchicalKV (HKV):
https://github.com/NVIDIA-Merlin/HierarchicalKV
GTC 2024 将于 2024 年 3 月 18 至 21 日在美国加州圣何塞会议中心举行,线上大会也将同期开放。点击“阅读原文”或扫描下方海报二维码,立即注册 GTC 大会。
原文标题:NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化
文章出处:【微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
-
英伟达
+关注
关注
22文章
3872浏览量
92442
原文标题:NVIDIA Merlin 助力陌陌推荐业务实现高性能训练优化
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
鸿蒙原生页面高性能解决方案上线OpenHarmony社区 助力打造高性能原生应用
怎么做电子元器件的销售啊,不知道如何去地推陌拜,有没有师哥能帮我解答一下,跪谢~
全新NVIDIA NIM微服务实现突破性进展
NVIDIA AI助力实现更好的癌症检测
2024CHINTERGEO武汉测绘展,帆陌科技携创新无人机保险产品、技术首亮相

什么是协议分析仪和训练器
NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案

NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据

SOK在手机行业的应用案例
如何训练和优化神经网络
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
降本增效:NVIDIA路径优化引擎创下多项世界纪录!
基于NVIDIA Megatron Core的MOE LLM实现和训练优化

NVIDIA 发布全新交换机,全面优化万亿参数级 GPU 计算和 AI 基础设施






 工商网监
工商网监
评论