 7种server的服务器处理结构模型
7种server的服务器处理结构模型
两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor和 Proactor,同步 I/O 模型通常用于实现Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件
Reactor可以理解为:来了事件是由操作系统通知应用程序,让应用程序来处理。又因为【内核中的数据准备阶段和数据就绪并由内核态切换到用户态】这两个过程对应用层来说是需要主动调用read来等待的,所以Reactor一般都是用同步IO实现。
Proactor可以理解为:来了事件是由操作系统处理好了之后再通知应用程序。又因为【内核中会由异步线程把数据准备好并且处理好了之后,直接通过信号中断告诉应用层】,对于应用程序来说,得到的是已经完成读写的事件,这个过程不需要等待。因此Proactor一般都是用异步IO实现的。
Linux基本上逐步实现了POSIX兼容,但并没有参加正式的POSIX认证。由于Linux下的异步IO不完善,aio_read,aio_write系列函数是由POSIX定义的异步操作接口,不是真正操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅支持本地文件的aio异步操作,网络编程中的socket是不支持的。所以本文没有讲述异步IO实现Proactor模式,取而代之的是同步IO模拟实现Proactor模式。
①同步IO实现reactor模式:主线程只负责监听lfd,accept成功之后把新创建的cfd交给子线程。子线程再通过IO多路复用去监听cfd的读写数据,并且处理客户端业务。(主线程把已被触发但是还未完成的事件分发给子线程)
·································································································
②同步IO模拟proactor模式:是主线程accpet监听lfd,并且lfd读事件触发时,建立连接并创建cfd,并且通过epoll_ctl把cfd注册到内核的监听树中,等到该socket的读事件就绪时,主线程进行读操作,把读到的内容交给子线程去进行业务处理,然后子线程处理完业务之后把该socketfd又注册为写时间就绪,并且把数据交回给主线程,由主线程写回给客户端。
(主线程模拟真实Proactor模式中的异步线程,把已完成的事件分发给子线程)
下面的并发模型中,常用的是:
1️⃣模型四(同步IO模拟proactor模式)
2️⃣模型五线程池版本 (同步IO实现reactor模式)
在客户端数量非常多的时候适合用模型五,但是在客户端数量不多的时候使用模型四可能会效率更好,因为模型四的线程数量更少,减少CPU切换线程的频率。
为什么要用同步IO模拟proactor模式呢?
理论上 Proactor 比 Reactor 效率要高一些,异步 I/O 能够充分利用 DMA 特性,让 I/O 操作与计算重叠,但要实现真正的异步 I/O,操作系统需要做大量的工作。目前 Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下的 AIO 并不完善,因此在 Linux 下实现高并发网络编程时都是以 Reactor 模式为主。所以即使 Boost.Asio 号称实现了 Proactor 模型,其实它在 Windows 下采用 IOCP,而在 Linux 下是用 Reactor 模式(采用 epoll)模拟出来的异步模型
服务器开发常见的并发模型
只要是做服务器开发,那么常见的模型是通用的,C/C++/go等等都是通用的,因为这是一种设计思想。
其中模型四和模型五是实际开发中主流的,而模型六过于理想化目前的硬件无法实现。
模型一:单线程accept(无IO复用)
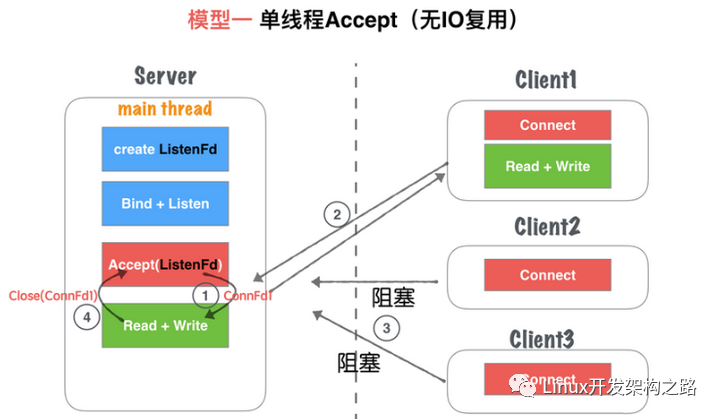
模型分析:
- ①主线程执行阻塞accept,每次客户端connect请求连接过来,主线程中的accept响应并建立连接
- ②创建连接成功之后,得到新的套接字文件描述符cfd(用于与客户端通信),然后在主线程串行处理套接字读写,并处理业务。
- ③在②的处理业务时,如果有新的客户端发送请求连接,会被阻塞,服务器无响应,直到当前的cfd全部业务处理完毕,重新回到accept阻塞监听状态时,才会从请求队列中选取第一个lfd进行连接。
优缺点:
优点:
- socket编程流程清晰且简单,适合学习使用,了解socket基本编程流程。
缺点:
- 该模型并非并发模型,是串行的服务器,同一时刻,监听并响应最大的网络请求量为1。即并发量为1。
- 仅适合学习基本socket编程,不适合任何服务器Server构建。
模型二:单线程accept + 多线程读写业务(无IO复用)

模型分析:
- ①主线程执行accept阻塞监听,每当有客户端connect连接请求过来,主线程中的accept响应并且与客户端建立连接
- ②创建连接成功后得到新的cfd,然后再thread_create一个新的线程用来处理客户端的读写业务,并且主线程马上回到accept阻塞监听继续等待新客户端的连接请求
- ③这个新的线程通过套接字cfd与客户端进行通信读写
- ④服务器在②处理业务中,如果有新客户端发送申请连接过来,主线程accept依然会响应并且简历连接,重复②过程。
优缺点:
优点:
- 基于模型一作了改进,支持了并发
- 使用灵活,一个client对应一个thread单独处理,server处理业务的内聚程度高(一个好的内聚模块应当恰好做一件事)。客户端无论如何写,服务端都会有一个线程做资源响应。
缺点:
- 随着客户端的数量增多,需要开辟的线程也增加,客户端与服务端线程数量是1:1正比关系。因此对于高并发场景,线程数量收到硬件的瓶颈制约。线程过多也会增加CPU的切换成本,降低CPU的利用率。
- 对于长连接,客户端一旦没有业务读写操作,只要客户端不关闭,服务端的对应线程就必须要保持连接(心跳包、健康监测等机制),占用连接资源和线程的开销
- 仅适合客户端数量不大,并且是可控的场景来使用
- 仅适合学习基本的socket编程,不适合做并发服务器
模型三:单线程多路IO复用

模型分析:
- ①主线程main thread 创建 lfd之后,采用多路IO复用机制(如select和epoll)进行IO状态阻塞监听。有client1客户端 connect 请求, IO复用机制检测到lfd触发事件读写,则进行accept建立连接,并将新生成的cfd1加入到监听IO集合中。
- ②client1 再次进行正常读写业务请求,主线程的多路IO复用机制阻塞返回,主线程与client1进行读写通信业务。等到读写业务结束后,会再次返回多路IO复用的地方进行阻塞监听。
- ③如果client1正在进行读写业务时,server依然在主线程执行流程中继续执行,此时如果有新的客户端申请连接请求,server将没有办法及时响应(因为是单线程,server正在读写),将会把这些还没来得及响应的请求加入阻塞队列中。
- ④等到server处理完一个客户端连接的读写操作时,继续回到多路IO复用机制处阻塞,其他的连接如果再发送连接请求过来的话,会继续重复②③流程。
优缺点:
优点:
- 单线程/单进程解决了可以同时监听多个客户端读写状态的模型,不需要1:1与客户端的线程数量关系。而是1:n;
- 多路IO复用阻塞,不需要一直轮询,所以不会浪费CPU资源,CPU利用效率较高。
缺点:
- 因为是单线程/单线程,虽然可以监听多个客户端的读写状态,但是在同一时间内,只能处理一个客户端的读写操作,实际上读写的业务并发为1;
- 多客户端访问服务器,但是业务为串行执行,大量请求会有排队延迟现象。如图中⑤所示,当client3占据主线程流程时, client1和client2流程会卡在IO复用,等待下次监听触发事件。
是否满足实际开发?
可以!该模型编写代码较简单,虽然有延迟现象,但是毕竟多路IO复用机制阻塞,不会占用CPU资源,如果并发请求量比较小,客户端数量可数,允许信息有一点点延迟,可以使用该模型。
比如Redis就是采用该模型设计的,因为Redis业务处理主要是在内存中完成的,操作速度很快,性能瓶颈不在CPU上。
模型四:单线程多路IO复用 + 多线程业务工作池

模型分析:
前两步跟模型三一致
- ①主线程main thread 创建 lfd之后,采用多路IO复用机制(如select和epoll)进行IO状态阻塞监听。有client1客户端 connect 请求, IO复用机制检测到lfd触发事件读写,则进行accept建立连接,并将新生成的cfd1加入到监听IO集合中。
- ②当cfd1有可读消息,触发读事件,并且进行读写消息。
- ③主线程按照固定的协议读取消息,并且交给worker pool工作线程池,工作线程池在server启动之前就已经开启固定数量的线程,里面的线程只处理消息业务,不进行套接字读写操作。
- ④工作池处理完业务,触发cfd1写事件,将要回发客户端的数据消息通过主线程写回给客户端
优缺点:
优点:
- 相比于模型三而言,设计了一个worker pool业务线程池,将业务处理部分从主线程抽离出来,为主线程分担了业务处理的工作,减少了因为单线程的串行执行业务机制,多客户端对server的大量请求造成排队延迟的时间。就是说主线程读完数据之后马上就丢给了线程池去处理,然后马上回到多路IO复用的阻塞监听状态。缩短了其他客户端的等待连接时间。
- 由于是单线程,实际上读写的业务并发还是为1,但是业务流程的并发数为worker pool线程池里的线程数量,加快了业务处理并行效率。
缺点:
- 读写依然是主线程单独处理,最高的读写并行通道依然是1,导致当前服务器的并发性能依然没有提升,只是响应任务的速度快了。每个客户端的排队时间短了,但因为还是只有一个通道进行读写操作,因此总体的完成度跟模型3是差不多的。
- 虽然多个worker线程池处理业务,但是最后返回给客户端依旧也需要排队。因为出口还是只有read+write 这1个通道。因此业务是可以并行了,但是总体的效率是不变的。
- 模型三是客户端向server发起请求时需要排队,模型四是业务处理完之后回写客户端需要排队。
是否满足实际开发?
可以!模型三跟模型四的总体并发效率差不多,因为还是一个线程进行读写。但是对于客户端的体验来说,会觉得响应速度变快,减少了在服务器的排队时间。如果客户端数量不多,并且各个客户端的逻辑业务有并行需求的话适合用该模型。
模型五:单线程多路IO复用 + 多线程多路IO复用(线程池)实际中最常用

模型分析:
- ①server在启动监听之前,需要创建固定数量N的线程,作为thread pool线程池。
- ②主线程创建lfd之后,采用多路IO复用机制(如select、epoll)进行IO状态阻塞监听。有client1客户端 connect请求,IO复用机制检测到lfd触发读事件,则进行accept建立连接,并且将新创建的cfd1分发给thread pool线程池中的某个线程监听。
- ③thread pool中的每个thread都启动多路IO复用机制,用来监听主线程建立成功并且分发下来的socket套接字(cfd)。
- ④如图,thread1监听cfd1、cfd2,thread2监听cfd3,thread3监听cfd4。线程池里的每一个线程相当于它们所监听的客户端所对应的服务端。当对应的cfd有读写事件时,对应的线程池里的thread会处理相应的读写业务。
优缺点:
优点:
- 将主线程的单流程读写,分散到线程池完成,这样增加了同一时刻的读写并行通道,并行通道数量等于线程池的thread数量N;
- server同时监听cfd套接字数量几乎成倍增大,之前的全部监控数量取决于主线程的多路IO复用机制的最大限制(select默认1024,epoll默认与内存有关,约3~6w不等)。所以该模型的理论单点server最高的响应并发数量为N*(3 ~ 6w)。(N为线程池thread的数量,建议与cpu核心数一致)
- 如果良好的线程池数量和CPU核心数适配,那么可以尝试CPU核心与thread绑定,从而降低cpu的切换频率,提高了每个thread处理业务的效率。
缺点:
- 虽然监听的并发数量提升,但是最高读写并行通道依然为N,而且多个身处被同一个thread所监听的客户端也会出现延迟读写现象。实际上线程池里每个thread对应客户端的部分,相当于模型三。
是否满足实际开发?
可以!当前主流的线程池框架就是模型五,其中有Netty 和 Memcache 。
模型六:(多进程版)单线程多路IO复用 + 多进程多路IO复用(进程池)

模型分析:
与线程池版没有太大的差异。需要在服务器启动之前先创建一些守护进程在后台运行。
存在的不同之处:
- ①进程间资源不共享,而线程是共享资源的。进程和线程的内存布局不同导致主进程不再进行accept操作,而是将accept过程分散到每一个子进程中
- ②进程的资源独立,所以主进程如果accept成功cfd,其他的进程是没有办法共享资源的,因此需要各子进程自行accpet创建连接
- ③主进程只是监听listenFd状态,一旦触发读事件或者有新连接请求,通过IPC进程间通信(signal、mmap、fifo等方式)让所有的子进程们进行竞争,抢到lfd读事件资源的子进程会进行accpet操作,监听他们自己所创建出来的套接字cfd。(自己创建的cfd,由自己监听cfd的读写事件)
优缺点:
与线程池版本没有太大差异
优点:
- 由于进程间的资源独立,尽管是父子进程,也是读时共享,写时复制。因此多进程模型安全稳定性较强,各自进程互不干扰。Nginx就是使用进程池的框架实现的。不过方案与标准的多 Reactor 多进程有些差异。具体差异表现在主进程中仅仅用来初始化 socket,并没有创建 mainReactor 来 accept 连接,而是由子进程的 Reactor 来 accept 连接,通过锁来控制一次只有一个子进程进行 accept(防止出现惊群现象),子进程 accept 新连接后就放到自己的 Reactor 进行处理,不会再分配给其他子进程。
缺点:
- 多进程内存资源空间占用得稍微大一些
模型七:单线程多路I/O复用+多线程多路I/O复用+多线程

模型分析:
- ①server在启动监听之前,开辟固定数量N个线程,创建thread pool线程池。
- ②主线程创建lfd之后,采用多路IO复用机制进行IO状态的阻塞监听。当有client1客户端connect请求,多路IO复用机制检测到lfd触发读事件,则会进行accept建立连接,并把accept后新创建的cfd1分发给thread pool中的某个线程进行监听。
- ③线程池中的每个thread都启动多路IO复用机制,用来监听主线程分发下来的socket套接字cfd。一旦某个被监听的cfd被触发了读写事件,该线程池里的thread会立即开辟他的一个子线程与cfd进行读写业务操作。
- ④当某个读写线程完成当前读写业务时,如果当前套接字没有被关闭,那么该线程会将当前的cfd套接字重新加回线程池的监听线程中,同时自身销毁。
优缺点:
优点:
- 在模型五的基础上,除了能够保证同时响应的最高并发数,又能解决了读写并行通道被局限的问题。
- 同一时刻的读写并行通道达到最大极限,一个客户端可以对应一个单独线程处理读写业务。读写并行通道与客户端的数量是1 :1关系。
缺点:
- 该模型过于理想化,因为要求cpu的核心数足够大
- 如果硬件cpu数量可数(目前的硬件情况就是cpu可数),那么该模型将造成大量的cpu切换成本。为了保证读写并行通道与客户端可以一对一服务,那么server需要开辟的线程数量就要与客户端一致,那么线程池中多路IO复用的监听线程池绑定CPU数量将会变得毫无意义。(因为使用多路IO复用机制,就是为了达到1个线程可以监听多个client。如果现在的线程数量已经跟客户端数量一致了,那多路IO复用就没意义了)
- 如果每个临时的读写线程都能够绑定一个单独的CPU,那么此模型将会是最优模型。但是目前的CPU数量无法与客户端的数量达到一个量级,还差得远。
八 、总结
- 上面整理了7种server的服务器处理结构模型,对于应付高并发和高CPU利用率的模型,目前采用最多的是模型五,其中Nginx就是类似模型五进程版的改版。
- 并发模型并且设计得越复杂越好,也不是线程开辟越多越好。真实设计开发中需要考虑硬件的利用和CPU切换成本的开销。模型六的设计极为复杂,线程较多,但以当今的硬件能力无法实现,反倒导致该模型性能级差。所以对于不同的业务场景要选择适合的模型构建,并不是说固定要使用哪一个,要根据实际灵活变动。
-
服务器
+关注
关注
12文章
9421浏览量
86482 -
Server
+关注
关注
0文章
93浏览量
24222 -
模型
+关注
关注
1文章
3413浏览量
49472 -
应用程序
+关注
关注
38文章
3305浏览量
58195
发布评论请先 登录
相关推荐
无纹波控制系统仿真结构模型
基于SI协议的IP电话服务器的设计
ZOPC Server服务器软件使用说明
如何用Foxmail Server搭建邮件服务器
IPTV的系统结构模型

NVIDIA Triton 系列文章(9):为服务器添加模型
嵌入式7种架构模式分析

服务器Server和客户端Client的区别
服务器Server和客户端Client有哪些区别呢?





 工商网监
工商网监
评论