 了解连接池、线程池、内存池、异步请求池
了解连接池、线程池、内存池、异步请求池
池化技术
池化技术能够减少资源对象的创建次数,提⾼程序的响应性能,特别是在⾼并发下这种提⾼更加明显。使用池化技术缓存的资源对象有如下共同特点:
- 对象创建时间长;
- 对象创建需要大量资源;
- 对象创建后可被重复使用像常见的线程池、内存池、连接池、对象池都具有以上的共同特点。
连接池
什么是数据库连接池
定义:数据库连接池(Connection pooling)是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态地对池中的连接进行申请,使用,释放。
大白话:创建数据库连接是⼀个很耗时的操作,也容易对数据库造成安全隐患。所以,在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,还更加安全可靠。这里讲的数据库,不单只是指Mysql,也同样适用于Redis。
为什么使用数据库连接池
- 资源复用:由于数据库连接得到复用,避免了频繁的创建、释放连接引起的性能开销,在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
- 更快的系统响应速度:数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了从数据库连接初始化和释放过程的开销,从而缩减了系统整体响应时间。
- 统⼀的连接管理:避免数据库连接泄露,在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄露。
如果不使用连接池
- TCP建立连接的三次握手(客户端与MySQL服务器的连接基于TCP协议)
- MySQL认证的三次握手
- 真正的SQL执行
- MySQL的关闭
- TCP的四次握手关闭
可以看到,为了执行⼀条SQL,需要进行TCP三次握手,Mysql认证、Mysql关闭、TCP四次挥手等其他操作,执行SQL操作在所有的操作占比非常低。
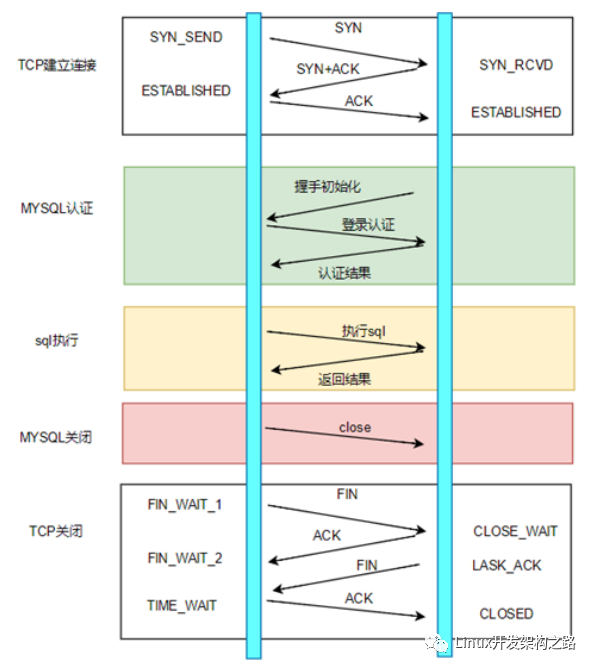
优点:实现简单
缺点:
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

使用连接池
第⼀次访问的时候,需要建立连接。但是之后的访问,均会复用之前创建的连接,直接执行SQL语句。
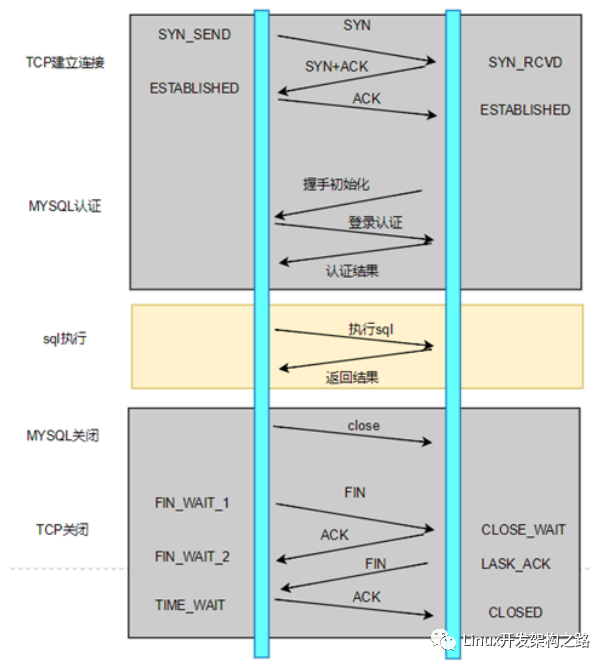
优点:
- 降低了网络开销
- 连接复用,有效减少连接数。
- 提升性能,避免频繁的新建连接。新建连接的开销比较大
- 没有TIME_WAIT状态的问题
缺点:
- 设计较为复杂
长连接和连接池的区别
- 长连接是⼀些驱动、驱动框架、ORM工具的特性,由驱动来保持连接句柄的打开,以便后续的数据库操作可以重用连接,从而减少数据库的连接开销。
- 而连接池是应用服务器的组件,它可以通过参数来配置连接数、连接检测、连接的生命周期等。
- 连接池内的连接,其实就是长连接。
数据库连接池运行机制
- 用户发送请求,把请求插入到消息队列
- 线程池中的线程竞争从消息队列拿出任务(涉及多线程竞争,加锁)
- 线程从连接池获取或创建可用连接(涉及多线程竞争,加锁)
- 利用连接对象和用户请求任务请求数据库数据
- 使用完毕之后,把连接返回给连接池 (涉及多线程竞争,加锁)
在系统关闭前,断开所有连接并释放连接占用的系统资源;
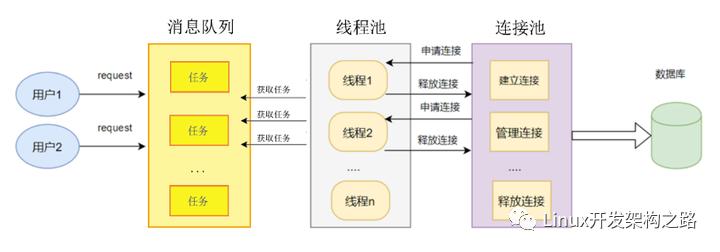
连接池和线程池的关系
连接池和线程池的区别:
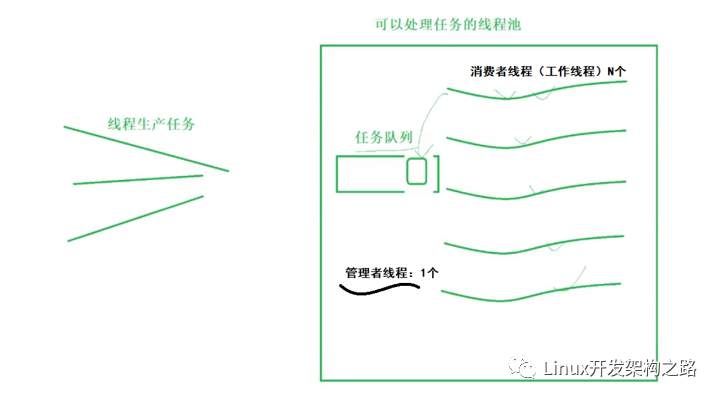
- 线程池:主动调用任务。当任务队列不为空的时候从队列取任务取执行。比如去银行办理业务,窗口柜员是线程,多个窗口组成了线程池,柜员从排号队列叫号执行。
- 连接池:被动被任务使用。当某任务需要操作数据库时,只要从连接池中取出⼀个连接对象,当任务使用完该连接对象后,将该连接对象放回到连接池中。如果连接池中没有连接对象可以用,那么该任务就必须等待。比如去银行用笔填单,笔是连接对象,我们要用笔的时候去取,用完了还回去
连接池和线程池设置数量的关系:
- ⼀般线程池线程数量和连接池连接对象数量⼀致;
- ⼀般线程执行任务完毕的时候归还连接对象;
线程池设计要点
使⽤连接池需要预先建立数据库连接
线程池设计思路:
- 连接到数据库,涉及到数据库ip、端口、用户名、密码、数据库名字等;a. 连接的操作,每个连接对象都是独立的连接通道,它们是独立的
b. 配置最小连接数和最大连接数 - 需要⼀个队列管理他的连接,比如使用list;
- 获取连接对象
- 归还连接对象
(同步方式)连接池的实现(伪代码)
//数据库连接类(一个对象对应一个Mysql/Redis连接)
class CDBConn {
int Init(); //初始化,连接数据库操作
MYSQL* m_mysql; // 对应一个连接
};
//连接池
class CDBPool {
int Init(); // 连接数据库,用于for循环创建CDBConn对象并且调用CDBConn->Init()
CDBConn* GetDBConn(const int timeout_ms = -1); // 获取连接资源(即从m_free_list拿出一个连接对象)
void RelDBConn(CDBConn* pConn); // 归还连接资源(即把连接对象放回m_free_list)
list m_free_list; // 空闲的连接
list m_used_list; // 记录已经被请求的连接
};
//用户请求的任务
struct job
{
void* (*callback_function)(void *arg); //线程回调函数
void *arg; //回调函数参数
struct job *next;
};
//线程池
struct threadpool{
//用户请求的任务插入到job list中
struct job *head; //指向job的头指针
struct job *tail; //指向job的尾指针
//工作线程
int thread_num; //线程池中开启线程的个数
pthread_t *pthreads; //线程池中所有线程的pthread_t
};
//工作线程执行的函数
void *threadpool_function(void *arg){
while(1){
//从消息队列中取任务
task = pop_task();
//从连接池取一个数据库连接对象
CDBConn *pDBConn = pDBPool->GetDBConn();
//请求数据库(同步方式,阻塞等待数据库消息返回)
query_db(pDBConn, task);
//把数据库连接对象放回连接池
pDBPool->RelDBConn(pDBConn);
}
}*>*>
连接池连接设置数量
连接数 = ((核心数 * 2) + 有效磁盘数)
按照这个公式,即是说你的服务器 CPU 是 4核 i7 的,那连接池连接数大小应该为 ((4*2)+1)=9
这里只是⼀个经验公式。还要和线程池数量以及具体业务结合在⼀起
线程池
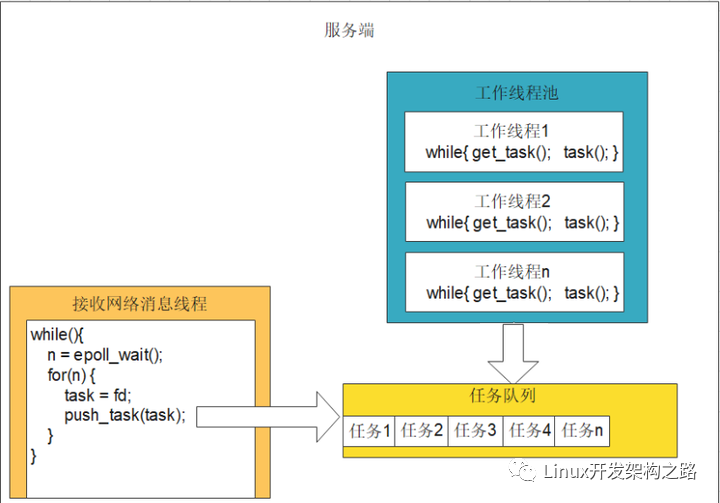
服务端epoll三种处理客户端信息方法模型:
int n = epoll_wait();
for(n){
#if //写法一 网络线程处理解析以及业务逻辑后直接发给客户端(单线程服务端)
recv(fd, buffer, length, 0);
parser();
send();
#elseif //写法二:网络线程把收到fd交给工作线程处理解析以及业务逻辑和发给客户端(多线程服务器)
//该模式有缺点:可能存在多个线程同时对一个fd进行操作!
//场景:同一个客户端短时间内发来多条请求,被分给了多个不同的线程处理,那么就出现多个线程同时对一个fd操作的情况。如果线程一个对fd写,另一个线程对fd进行close,就会引发错误
//因此需要特殊处理。处理方法:加入协程。每个协程处理一个IO。但是底层依然是依赖于epoll管理所有IO
task = fd;
push_tasks(task);
#else //写法三:网络线程解析完信息后,交给工作线程处理业务逻辑和发给客户端(多线程服务器)
recv(fd, buffer, length, 0);
push_task(buffer);
#endif
}
}
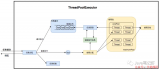
线程池图示
线程池代码演示
#include
#include
#include
#define LL_ADD(item, list) do {
item->prev = NULL;
item->next = list;
list = item;
} while(0)
#define LL_REMOVE(item, list) do {
if (item->prev != NULL) item->prev->next = item->next;
if (item->next != NULL) item->next->prev = item->prev;
if (list == item) list = item->next;
item->prev = item->next = NULL;
} while(0)
typedef struct NWORKER {
pthread_t thread;
int terminate;
struct NWORKQUEUE *workqueue;
struct NWORKER *prev;
struct NWORKER *next;
} nWorker;
typedef struct NJOB {
void (*job_function)(struct NJOB *job);
void *user_data;
struct NJOB *prev;
struct NJOB *next;
} nJob;
typedef struct NWORKQUEUE {
struct NWORKER *workers;
struct NJOB *waiting_jobs;
pthread_mutex_t jobs_mtx;
pthread_cond_t jobs_cond;
} nWorkQueue;
typedef nWorkQueue nThreadPool;
static void *ntyWorkerThread(void *ptr) {
nWorker *worker = (nWorker*)ptr;
while (1) {
pthread_mutex_lock(&worker->workqueue->jobs_mtx);
while (worker->workqueue->waiting_jobs == NULL) {
if (worker->terminate) break;
pthread_cond_wait(&worker->workqueue->jobs_cond, &worker->workqueue->jobs_mtx);
}
if (worker->terminate) {
pthread_mutex_unlock(&worker->workqueue->jobs_mtx);
break;
}
nJob *job = worker->workqueue->waiting_jobs;
if (job != NULL) {
LL_REMOVE(job, worker->workqueue->waiting_jobs);
}
pthread_mutex_unlock(&worker->workqueue->jobs_mtx);
if (job == NULL) continue;
job->job_function(job);
}
free(worker);
pthread_exit(NULL);
}
int ntyThreadPoolCreate(nThreadPool *workqueue, int numWorkers) {
if (numWorkers < 1) numWorkers = 1;
memset(workqueue, 0, sizeof(nThreadPool));
pthread_cond_t blank_cond = PTHREAD_COND_INITIALIZER;
memcpy(&workqueue->jobs_cond, &blank_cond, sizeof(workqueue->jobs_cond));
pthread_mutex_t blank_mutex = PTHREAD_MUTEX_INITIALIZER;
memcpy(&workqueue->jobs_mtx, &blank_mutex, sizeof(workqueue->jobs_mtx));
int i = 0;
for (i = 0;i < numWorkers;i ++) {
nWorker *worker = (nWorker*)malloc(sizeof(nWorker));
if (worker == NULL) {
perror("malloc");
return 1;
}
memset(worker, 0, sizeof(nWorker));
worker->workqueue = workqueue;
int ret = pthread_create(&worker->thread, NULL, ntyWorkerThread, (void *)worker);
if (ret) {
perror("pthread_create");
free(worker);
return 1;
}
LL_ADD(worker, worker->workqueue->workers);
}
return 0;
}
void ntyThreadPoolShutdown(nThreadPool *workqueue) {
nWorker *worker = NULL;
for (worker = workqueue->workers;worker != NULL;worker = worker->next) {
worker->terminate = 1;
}
pthread_mutex_lock(&workqueue->jobs_mtx);
workqueue->workers = NULL;
workqueue->waiting_jobs = NULL;
pthread_cond_broadcast(&workqueue->jobs_cond);
pthread_mutex_unlock(&workqueue->jobs_mtx);
}
void ntyThreadPoolQueue(nThreadPool *workqueue, nJob *job) {
pthread_mutex_lock(&workqueue->jobs_mtx);
LL_ADD(job, workqueue->waiting_jobs);
pthread_cond_signal(&workqueue->jobs_cond);
pthread_mutex_unlock(&workqueue->jobs_mtx);
}
/************************** debug thread pool **************************/
//sdk --> software develop kit
// 提供SDK给其他开发者使用
#if 1
#define KING_MAX_THREAD 80
#define KING_COUNTER_SIZE 1000
void king_counter(nJob *job) {
int index = *(int*)job->user_data;
printf("index : %d, selfid : %lun", index, pthread_self());
free(job->user_data);
free(job);
}
int main(int argc, char *argv[]) {
nThreadPool pool;
ntyThreadPoolCreate(&pool, KING_MAX_THREAD);
int i = 0;
for (i = 0;i < KING_COUNTER_SIZE;i ++) {
nJob *job = (nJob*)malloc(sizeof(nJob));
if (job == NULL) {
perror("malloc");
exit(1);
}
job->job_function = king_counter;
job->user_data = malloc(sizeof(int));
*(int*)job->user_data = i;
ntyThreadPoolQueue(&pool, job);
}
getchar();
printf("n");
}
#endif
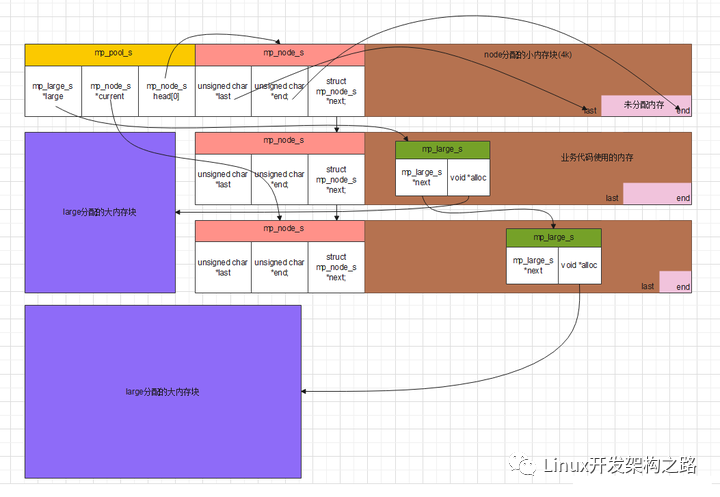
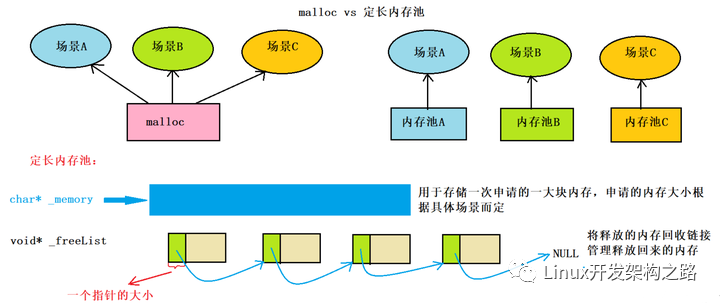
内存池
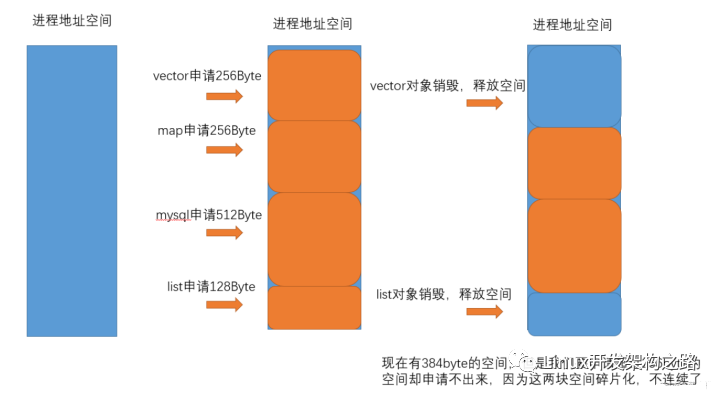
为什么要用内存池:
- 在需要堆内存管理一些数据的时候直接malloc,容易造成内存碎片
- 在需要堆内存管理一些数据的时候直接malloc,容易忘记free,造成内存泄漏,利于内存管理
策略
- 小块内存(<4k):先分配一个整块,在整块里每次用一小块内存
- 大块内存(>4k):直接分配
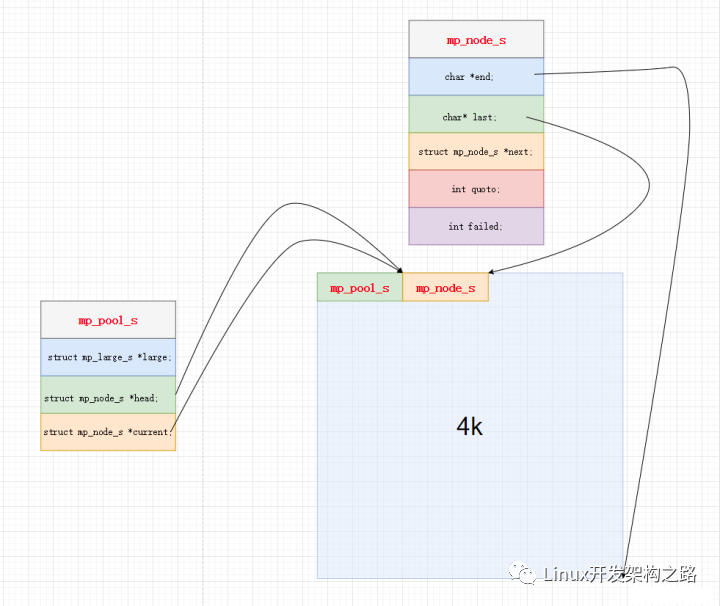
图示
代码示例
#include
#include
#include
#include
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align(n, alignment) (((n)+(alignment-1)) & ~(alignment-1))
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
struct mp_large_s {
struct mp_large_s *next; //下个内存结点
void *alloc; //分配的内存的头位置
};
struct mp_node_s {
unsigned char *last; //内存结点末尾位置
unsigned char *end; //内存结点已分配内存的末尾位置
struct mp_node_s *next; //下一个内存结点
size_t failed; //尝试利用此结点剩余空间失败次数
};
struct mp_pool_s {
//该内存池组织了大块内存和小块内存 二者分配方式不一样
size_t max; //MP_PAGE_SIZE
struct mp_large_s *large; //大块内存
struct mp_node_s *current; //小块内存 当前位置
struct mp_node_s head[0]; //小块内存 头节点位置
};
struct mp_pool_s *mp_create_pool(size_t size);
void mp_destory_pool(struct mp_pool_s *pool);
void *mp_alloc(struct mp_pool_s *pool, size_t size);
void *mp_nalloc(struct mp_pool_s *pool, size_t size);
void *mp_calloc(struct mp_pool_s *pool, size_t size);
void mp_free(struct mp_pool_s *pool, void *p);
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret) {
return NULL;
}
p->max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p->current = p->head;
p->large = NULL;
p->head->last = (unsigned char *)p + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s);
p->head->end = p->head->last + size;
p->head->failed = 0;
return p;
}
void mp_destory_pool(struct mp_pool_s *pool) {
struct mp_node_s *h, *n;
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
h = pool->head->next;
while (h) {
n = h->next;
free(h);
h = n;
}
free(pool);
}
void mp_reset_pool(struct mp_pool_s *pool) {
struct mp_node_s *h;
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (l->alloc) {
free(l->alloc);
}
}
pool->large = NULL;
for (h = pool->head; h; h = h->next) {
h->last = (unsigned char *)h + sizeof(struct mp_node_s);
}
}
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *h = pool->head;
size_t psize = (size_t)(h->end - (unsigned char *)h);
int ret = posix_memalign((void **)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
struct mp_node_s *p, *new_node, *current;
new_node = (struct mp_node_s*)m;
new_node->end = m + psize;
new_node->next = NULL;
new_node->failed = 0;
m += sizeof(struct mp_node_s);
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node->last = m + size;
current = pool->current;
for (p = current; p->next; p = p->next) {
if (p->failed++ > 4) {
current = p->next;
}
}
p->next = new_node;
pool->current = current ? current : new_node;
return m;
}
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void *p = malloc(size);
if (p == NULL) return NULL;
size_t n = 0;
struct mp_large_s *large;
for (large = pool->large; large; large = large->next) {
if (large->alloc == NULL) {
large->alloc = p;
return p;
}
if (n ++ > 3) break;
}
// 把 mp_large_s 结构体 放到 小块内存的结点里
large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_memalign(struct mp_pool_s *pool, size_t size, size_t alignment) {
void *p;
int ret = posix_memalign(&p, alignment, size);
if (ret) {
return NULL;
}
struct mp_large_s *large = mp_alloc(pool, sizeof(struct mp_large_s));
if (large == NULL) {
free(p);
return NULL;
}
large->alloc = p;
large->next = pool->large;
pool->large = large;
return p;
}
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = mp_align_ptr(p->last, MP_ALIGNMENT);
if ((size_t)(p->end - m) >= size) {
p->last = m + size;
return m;
}
p = p->next;
} while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_nalloc(struct mp_pool_s *pool, size_t size) {
unsigned char *m;
struct mp_node_s *p;
if (size <= pool->max) {
p = pool->current;
do {
m = p->last;
if ((size_t)(p->end - m) >= size) {
p->last = m+size;
return m;
}
p = p->next;
} while (p);
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
memset(p, 0, size);
}
return p;
}
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *l;
for (l = pool->large; l; l = l->next) {
if (p == l->alloc) {
free(l->alloc);
l->alloc = NULL;
return ;
}
}
}
int main(int argc, char *argv[]) {
int size = 1 << 12;
struct mp_pool_s *p = mp_create_pool(size);
int i = 0;
for (i = 0;i < 10;i ++) {
void *mp = mp_alloc(p, 512);
// mp_free(mp);
}
//printf("mp_create_pool: %ldn", p->max);
printf("mp_align(123, 32): %d, mp_align(17, 32): %dn", mp_align(24, 32), mp_align(17, 32));
//printf("mp_align_ptr(p->current, 32): %lx, p->current: %lx, mp_align(p->large, 32): %lx, p->large: %lxn", mp_align_ptr(p->current, 32), p->current, mp_align_ptr(p->large, 32), p->large);
int j = 0;
for (i = 0;i < 5;i ++) {
char *pp = mp_calloc(p, 32);
for (j = 0;j < 32;j ++) {
if (pp[j]) {
printf("calloc wrongn");
}
printf("calloc successn");
}
}
//printf("mp_reset_pooln");
for (i = 0;i < 5;i ++) {
void *l = mp_alloc(p, 8192);
mp_free(p, l);
}
mp_reset_pool(p);
//printf("mp_destory_pooln");
for (i = 0;i < 58;i ++) {
mp_alloc(p, 256);
}
mp_destory_pool(p);
return 0;
}
异步请求池
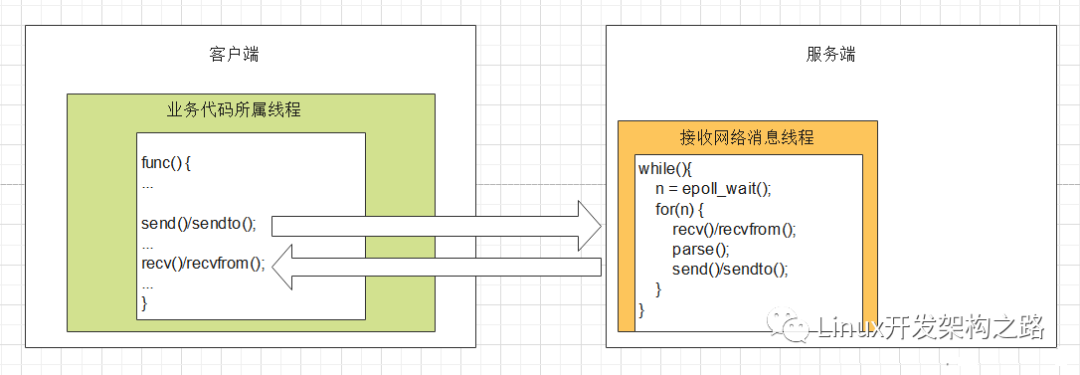
同步请求要点:
请求方作为客户端请求后(send/sendto),立即调用(recv/recvfrom)阻塞等待结果返回。
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);
if (sockfd < 0) {
perror("create socket failedn");
exit(-1);
}
printf("url:%sn", domain);
struct sockaddr_in dest;
bzero(&dest, sizeof(dest));
dest.sin_family = AF_INET;
dest.sin_port = htons(53);
dest.sin_addr.s_addr = inet_addr(DNS_SVR);
int ret = connect(sockfd, (struct sockaddr*)&dest, sizeof(dest));
printf("connect :%dn", ret);
struct dns_header header = {0};
dns_create_header(&header);
struct dns_question question = {0};
dns_create_question(&question, domain);
char request[1024] = {0};
int req_len = dns_build_request(&header, &question, request);
int slen = sendto(sockfd, request, req_len, 0, (struct sockaddr*)&dest, sizeof(struct sockaddr));
char buffer[1024] = {0};
struct sockaddr_in addr;
size_t addr_len = sizeof(struct sockaddr_in);
int n = recvfrom(sockfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&addr, (socklen_t*)&addr_len);
printf("recvfrom n : %dn", n);
struct dns_item *domains = NULL;
dns_parse_response(buffer, &domains);
return 0;
}
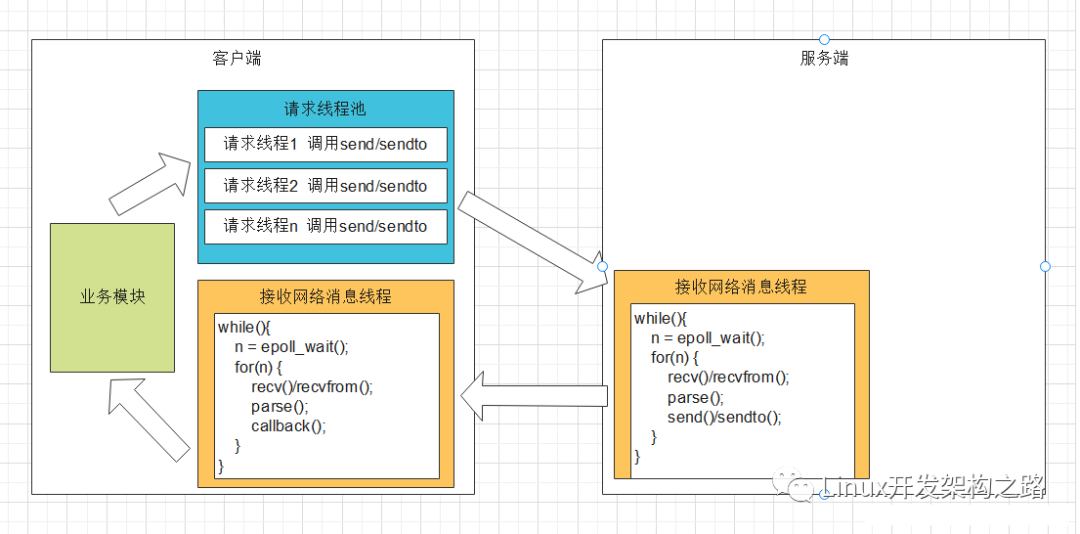
异步请求要点:
- 请求方作为客户端请求后(send/sendto),把fd交给epoll管理,不等待结果返回(recv/recvfrom)。
- epoll_wait在一个线程死循环中,当epoll收到消息,在进行处理(recv/recvfrom)。
struct async_context {
int epfd;
pthread_t threadid;
};
struct ep_arg {
int sockfd;
async_result_cb cb;
};
#define ASYNC_EVENTS 128
void *dns_async_callback(void *arg) {
struct async_context* ctx = (struct async_context*)arg;
while (1) {
struct epoll_event events[ASYNC_EVENTS] = {0};
int nready = epoll_wait(ctx->epfd, events, ASYNC_EVENTS, -1);
if (nready < 0) {
continue;
}
int i = 0;
for (i = 0;i < nready;i ++) {
struct ep_arg *ptr = events[i].data.ptr;
int sockfd = ptr->sockfd;
char buffer[1024] = {0};
struct sockaddr_in addr;
size_t addr_len = sizeof(struct sockaddr_in);
int n = recvfrom(sockfd, buffer, sizeof(buffer), 0, (struct sockaddr*)&addr, (socklen_t*)&addr_len);
//协议解析
//这里是DNS协议解析、也可以换成Mysql、Redis协议解析等。
printf("recvfrom n : %dn", n);
struct dns_item *domains = NULL;
int count = dns_parse_response(buffer, &domains);
//执行回调函数
ptr->cb(domains, count);
// close sockfd
close (sockfd);
free(ptr);
epoll_ctl(ctx->epfd, EPOLL_CTL_DEL, sockfd, NULL);
}
}
}
struct async_context* dns_async_client_init(void) {
int epfd = epoll_create(1);
if (epfd < 0) return NULL;
struct async_context* ctx = calloc(1, sizeof(struct async_context));
if (ctx == NULL) return NULL;
ctx->epfd = epfd;
int ret = pthread_create(&ctx->threadid, NULL, dns_async_callback, ctx);
if (ret) {
close(epfd);
free(ctx);
return NULL;
}
return ctx;
}
int dns_async_client_destroy(struct async_context* ctx) {
close(ctx->epfd);
pthread_cancel(ctx->threadid);
}
int dns_async_client_commit(struct async_context *ctx, async_result_cb cb) {
int sockfd = socket(AF_INET, SOCK_DGRAM, 0);
if (sockfd < 0) {
perror("create socket failedn");
exit(-1);
}
printf("url:%sn", domain);
struct sockaddr_in dest;
bzero(&dest, sizeof(dest));
dest.sin_family = AF_INET;
dest.sin_port = htons(53);
dest.sin_addr.s_addr = inet_addr(DNS_SVR);
int ret = connect(sockfd, (struct sockaddr*)&dest, sizeof(dest));
printf("connect :%dn", ret);
struct dns_header header = {0};
dns_create_header(&header);
struct dns_question question = {0};
dns_create_question(&question, domain);
char request[1024] = {0};
int req_len = dns_build_request(&header, &question, request);
int slen = sendto(sockfd, request, req_len, 0, (struct sockaddr*)&dest, sizeof(struct sockaddr));
struct ep_arg *ptr = calloc(1, sizeof(struct ep_arg));
if (ptr == NULL) return -1;
ptr->sockfd = sockfd;
ptr->cb = cb;
//
struct epoll_event ev;
ev.data.ptr = ptr;
ev.events = EPOLLIN; //可读
epoll_ctl(ctx->epfd, EPOLL_CTL_ADD, sockfd, &ev);
return 0;
}
执行顺序:
- 调用dns_async_client_init创建epoll和处理epoll_wait对应的线程。
- 调用dns_async_client_commit提交请求(send/sendto),并且把对应fd交给epoll管理
- 在dns_async_callback线程中,死循环中epoll_wait检测到EPOLLIN可读事件,然后调用(recv/recvfrom)和callback函数处理请求返回的response事件。
-
服务器
+关注
关注
12文章
9160浏览量
85420 -
数据库
+关注
关注
7文章
3799浏览量
64389 -
程序
+关注
关注
117文章
3787浏览量
81043 -
Redis
+关注
关注
0文章
375浏览量
10875
发布评论请先 登录
相关推荐



高并发内存池项目实现
池化技术的应用实践
线程池的运转流程图 池化技术实践案例解析





 工商网监
工商网监
评论