 Linux的文件系统特点
Linux的文件系统特点
Linux的文件系统特点
- 文件系统要有严格的组织形式,使得文件能够以块为单位进行存储。
- 文件系统中也要有索引区,用来方便查找一个文件分成的多个块都存放在了什么位置。
- 如果文件系统中有的文件是热点文件,近期经常被读取和写入,文件系统应该有缓存层。
- 文件应该用文件夹的形式组织起来,方便管理和查询。
- Linux内核要在自己的内存里面维护一套数据结构,来保存哪些文件被哪些进程打开和使用。
总体来说,文件系统的主要功能梳理如下:
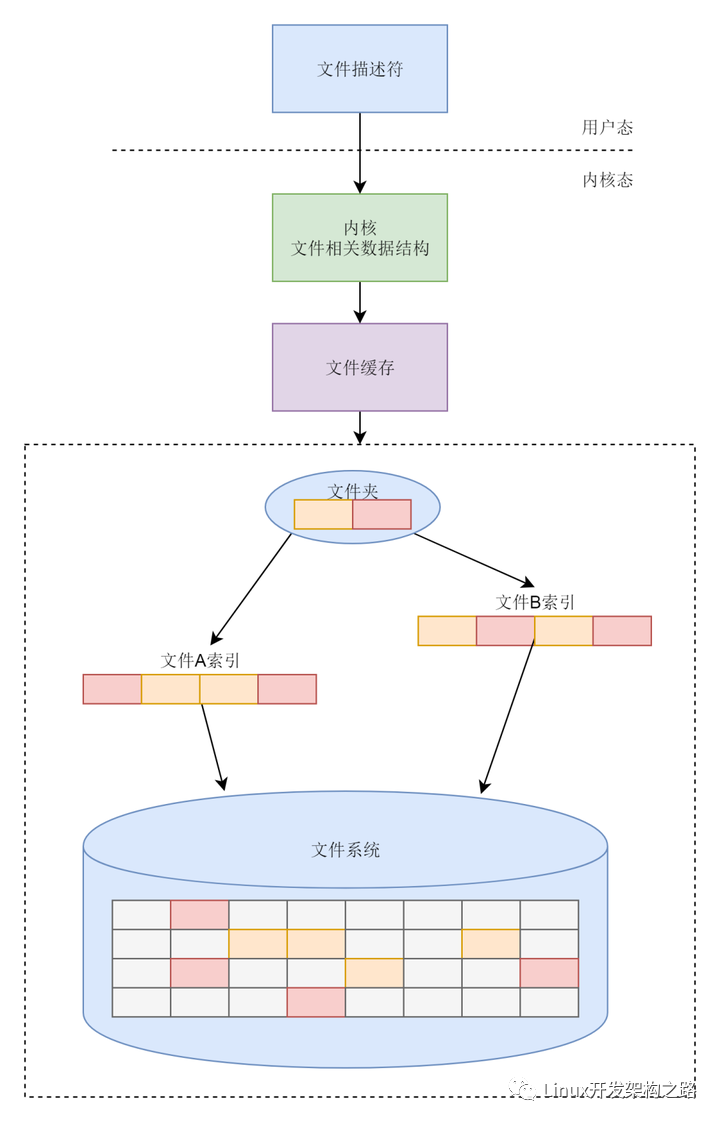
ext系列的文件系统的格式
inode与块的存储
硬盘分成相同大小的单元,我们称为块(Block)。一块的大小是扇区大小的整数倍,默认是4K。在格式化的时候,这个值是可以设定的。
一大块硬盘被分成了一个个小的块,用来存放文件的数据部分。这样一来,如果我们像存放一个文件,就不用给他分配一块连续的空间了。我们可以分散成一个个小块进行存放。这样就灵活得多,也比较容易添加、删除和插入数据。
inode就是文件索引的意思,我们每个文件都会对应一个inode;一个文件夹就是一个文件,也对应一个inode。
inode数据结构如下:
__le16 i_mode; /* File mode */
__le16 i_uid; /* Low 16 bits of Owner Uid */
__le32 i_size_lo; /* Size in bytes */
__le32 i_atime; /* Access time */
__le32 i_ctime; /* Inode Change time */
__le32 i_mtime; /* Modification time */
__le32 i_dtime; /* Deletion Time */
__le16 i_gid; /* Low 16 bits of Group Id */
__le16 i_links_count; /* Links count */
__le32 i_blocks_lo; /* Blocks count */
__le32 i_flags; /* File flags */
......
__le32 i_block[EXT4_N_BLOCKS];/* Pointers to blocks */
__le32 i_generation; /* File version (for NFS) */
__le32 i_file_acl_lo; /* File ACL */
__le32 i_size_high;
......
};
inode里面有文件的读写权限i_mode,属于哪个用户i_uid,哪个组i_gid,大小是多少i_size_io,占用多少个块i_blocks_io,i_atime是access time,是最近一次访问文件的时间;i_ctime是change time,是最近一次更改inode的时间;i_mtime是modify time,是最近一次更改文件的时间等。
所有的文件都是保存在i_block里面。具体保存规则由EXT4_N_BLOCKS决定,EXT4_N_BLOCKS有如下的定义:
#define EXT4_IND_BLOCK EXT4_NDIR_BLOCKS
#define EXT4_DIND_BLOCK (EXT4_IND_BLOCK + 1)
#define EXT4_TIND_BLOCK (EXT4_DIND_BLOCK + 1)
#define EXT4_N_BLOCKS (EXT4_TIND_BLOCK + 1)
在ext2和ext3中,其中前12项直接保存了块的位置,也就是说,我们可以通过i_block[0-11],直接得到保存文件内容的块。
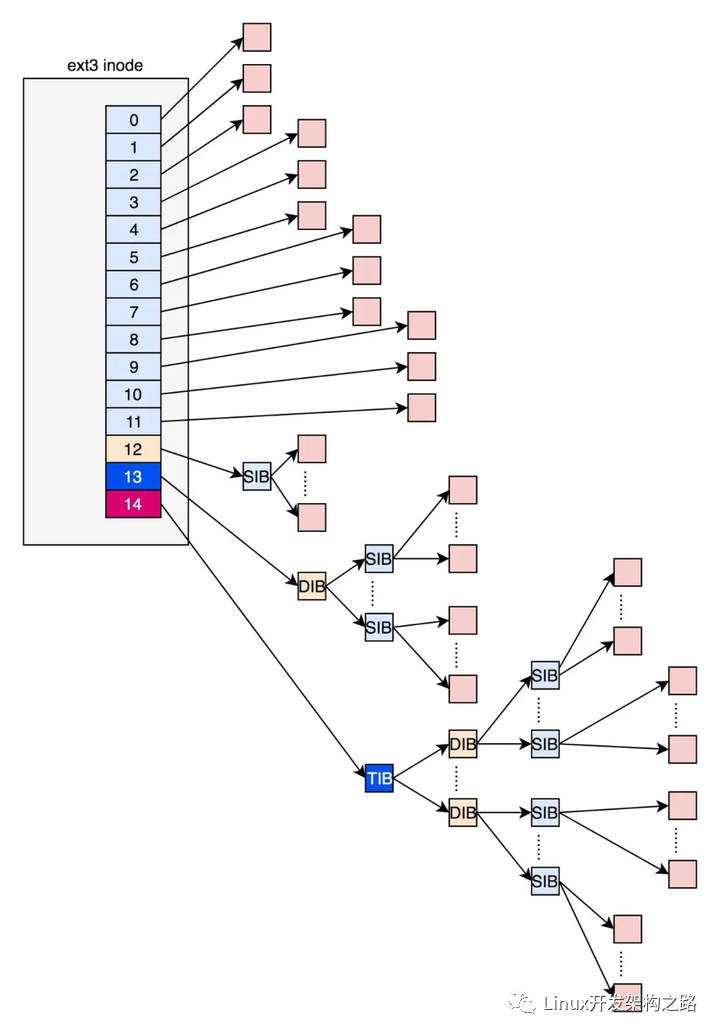
但是,如果一个文件比较大,12块放不下。当我们用到i_block[12]的时候,就不能直接放数据块的位置了,要不然i_block很快就会用完了。
那么可以让i_block[12]指向一个块,这个块里面不放数据块,而是放数据块的位置,这个块我们称为间接块。如果文件再大一些,i_block[13]会指向一个块,我们可以用二次间接块。二次间接块里面存放了间接块的位置,间接块里面存放了数据块的位置,数据块里面存放的是真正的数据。如果文件再大点,那么i_block[14]同理。
这里面有一个非常显著的问题,对于大文件来讲,我们要多次读取硬盘才能找到相应的块,这样访问速度就会比较慢。
为了解决这个问题,ext4做了一定的改变。它引入了一个新的概念,叫作Extents。比方说,一个文件大小为128M,如果使用4k大小的块进行存储,需要32k个块。如果按照ext2或者ext3那样散着放,数量太大了。但是Extents可以用于存放连续的块,也就是说,我们可以把128M放在一个Extents里面。这样的话,对大文件的读写性能提高了,文件碎片也减少了。
Exents是一个树状结构:
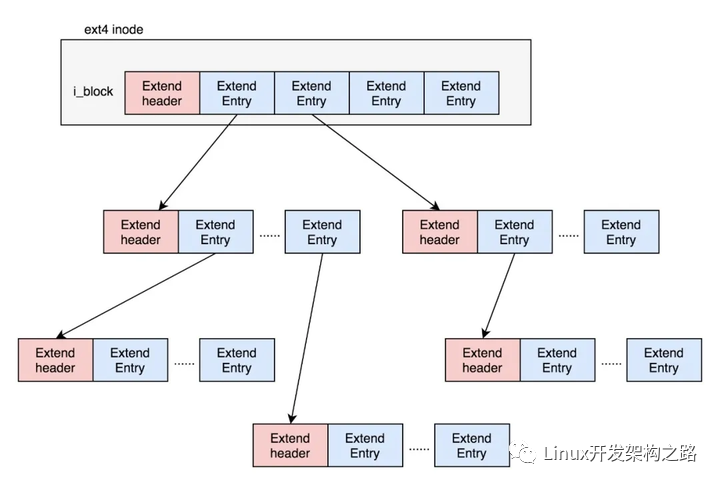
每个节点都有一个头,ext4_extent_header可以用来描述某个节点。
__le16 eh_magic; /* probably will support different formats */
__le16 eh_entries; /* number of valid entries */
__le16 eh_max; /* capacity of store in entries */
__le16 eh_depth; /* has tree real underlying blocks? */
__le32 eh_generation; /* generation of the tree */
};
eh_entries表示这个节点里面有多少项。这里的项分两种,如果是叶子节点,这一项会直接指向硬盘上的连续块的地址,我们称为数据节点ext4_extent;如果是分支节点,这一项会指向下一层的分支节点或者叶子节点,我们称为索引节点ext4_extent_idx。这两种类型的项的大小都是12个byte。
* This is the extent on-disk structure.
* It's used at the bottom of the tree.
*/
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};
/*
* This is index on-disk structure.
* It's used at all the levels except the bottom.
*/
struct ext4_extent_idx {
__le32 ei_block; /* index covers logical blocks from 'block' */
__le32 ei_leaf_lo; /* pointer to the physical block of the next *
* level. leaf or next index could be there */
__le16 ei_leaf_hi; /* high 16 bits of physical block */
__u16 ei_unused;
};
如果文件不大,inode里面的i_block中,可以放得下一个ext4_extent_header和4项ext4_extent。所以这个时候,eh_depth为0,也即inode里面的就是叶子节点,树高度为0。
如果文件比较大,4个extent放不下,就要分裂成为一棵树,eh_depth>0的节点就是索引节点,其中根节点深度最大,在inode中。最底层eh_depth=0的是叶子节点。
除了根节点,其他的节点都保存在一个块4k里面,4k扣除ext4_extent_header的12个byte,剩下的能够放340项,每个extent最大能表示128MB的数据,340个extent会使你的表示的文件达到42.5GB。
inode位图和块位图
inode的位图大小为4k,每一位对应一个inode。如果是1,表示这个inode已经被用了;如果是0,则表示没被用。block的位图同理。
在Linux操作系统里面,想要创建一个新文件,会调用open函数,并且参数会有O_CREAT。这表示当文件找不到的时候,我们就需要创建一个。那么open函数的调用过程大致是:要打开一个文件,先要根据路径找到文件夹。如果发现文件夹下面没有这个文件,同时又设置了O_CREAT,就说明我们要在这个文件夹下面创建一个文件。
创建一个文件,那么就需要创建一个inode,那么就会从文件系统里面读取inode位图,然后找到下一个为0的inode,就是空闲的inode。对于block位图,在写入文件的时候,也会有这个过程。
文件系统的格式
数据块的位图是放在一个块里面的,共4k。每位表示一个数据块,共可以表示
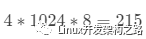
个数据块。如果每个数据块也是按默认的4K,最大可以表示空间为

个byte,也就是128M,那么显然是不够的。
这个时候就需要用到块组,数据结构为ext4_group_desc,这里面对于一个块组里的inode位图bg_inode_bitmap_lo、块位图bg_block_bitmap_lo、inode列表bg_inode_table_lo,都有相应的成员变量。
这样一个个块组,就基本构成了我们整个文件系统的结构。因为块组有多个,块组描述符也同样组成一个列表,我们把这些称为块组描述符表。
我们还需要有一个数据结构,对整个文件系统的情况进行描述,这个就是超级块ext4_super_block。里面有整个文件系统一共有多少inode,s_inodes_count;一共有多少块,s_blocks_count_lo,每个块组有多少inode,s_inodes_per_group,每个块组有多少块,s_blocks_per_group等。这些都是这类的全局信息。
最终,整个文件系统格式就是下面这个样子。
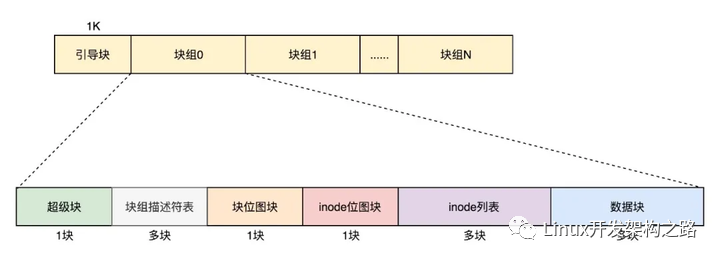
默认情况下,超级块和块组描述符表都有副本保存在每一个块组里面。防止这些数据丢失了,导致整个文件系统都打不开了。
由于如果每个块组里面都保存一份完整的块组描述符表,一方面很浪费空间;另一个方面,由于一个块组最大128M,而块组描述符表里面有多少项,这就限制了有多少个块组,128M * 块组的总数目是整个文件系统的大小,就被限制住了。
因此引入Meta Block Groups特性。
首先,块组描述符表不会保存所有块组的描述符了,而是将块组分成多个组,我们称为元块组(Meta Block Group)。每个元块组里面的块组描述符表仅仅包括自己的,一个元块组包含64个块组,这样一个元块组中的块组描述符表最多64项。
我们假设一共有256个块组,原来是一个整的块组描述符表,里面有256项,要备份就全备份,现在分成4个元块组,每个元块组里面的块组描述符表就只有64项了,这就小多了,而且四个元块组自己备份自己的。
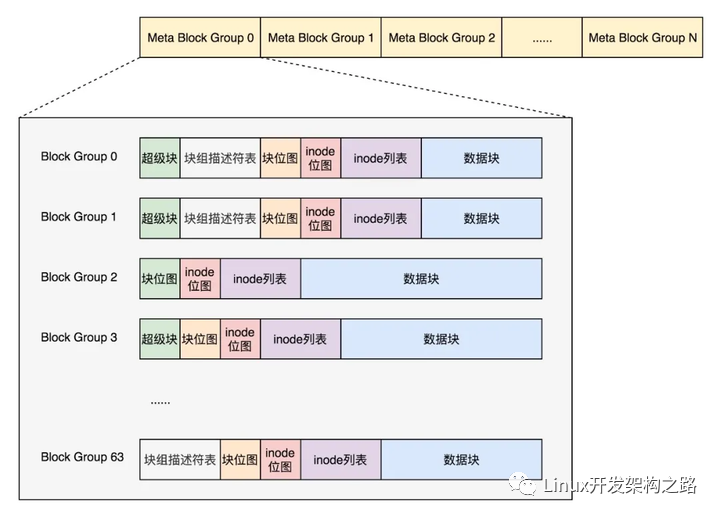
根据图中,每一个元块组包含64个块组,块组描述符表也是64项,备份三份,在元块组的第一个,第二个和最后一个块组的开始处。
如果开启了sparse_super特性,超级块和块组描述符表的副本只会保存在块组索引为0、3、5、7的整数幂里。所以上图的超级块只在索引为0、3、5、7等的整数幂里。
目录的存储格式
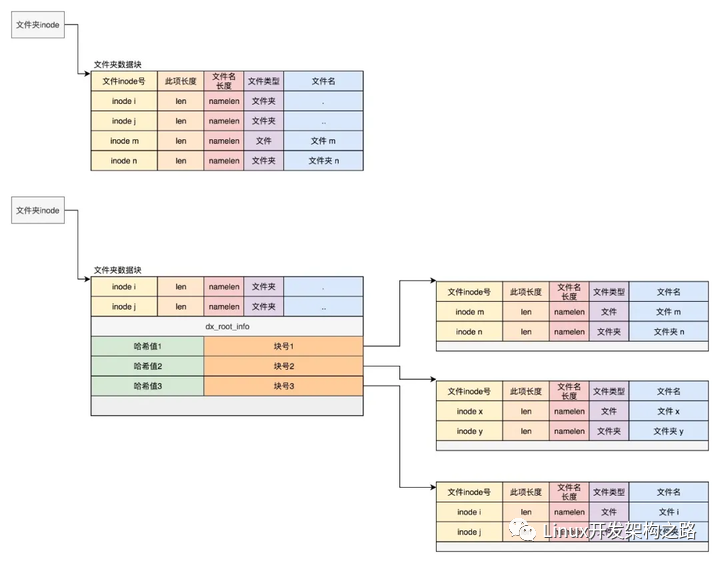
其实目录本身也是个文件,也有inode。inode里面也是指向一些块。和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。这些信息我们称为ext4_dir_entry。
在目录文件的块中,最简单的保存格式是列表,每一项都会保存这个目录的下一级的文件的文件名和对应的inode,通过这个inode,就能找到真正的文件。第一项是“.”,表示当前目录,第二项是“…”,表示上一级目录,接下来就是一项一项的文件名和inode。
如果在inode中设置EXT4_INDEX_FL标志,那么就表示根据索引查找文件。索引项会维护一个文件名的哈希值和数据块的一个映射关系。
如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。然后打开这个块,如果里面不再是索引,而是索引树的叶子节点的话,那里面还是ext4_dir_entry的列表,我们只要一项一项找文件名就行。通过索引树,我们可以将一个目录下面的N多的文件分散到很多的块里面,可以很快地进行查找。
Linux中的文件缓存
ext4文件系统层
对于ext4文件系统来讲,内核定义了一个ext4_file_operations。
......
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......
}
ext4_file_read_iter会调用generic_file_read_iter,ext4_file_write_iter会调用__generic_file_write_iter。
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
struct address_space *mapping = file->f_mapping;
......
retval = mapping->a_ops->direct_IO(iocb, iter);
}
......
retval = generic_file_buffered_read(iocb, iter, retval);
}
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
......
if (iocb->ki_flags & IOCB_DIRECT) {
......
written = generic_file_direct_write(iocb, from);
......
} else {
......
written = generic_perform_write(file, from, iocb->ki_pos);
......
}
}
generic_file_read_iter和__generic_file_write_iter有相似的逻辑,就是要区分是否用缓存。因此,根据是否使用内存做缓存,我们可以把文件的I/O操作分为两种类型。
第一种类型是缓存I/O。大多数文件系统的默认I/O操作都是缓存I/O。对于读操作来讲,操作系统会先检查,内核的缓冲区有没有需要的数据。如果已经缓存了,那就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。对于写操作来讲,操作系统会先将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说,写操作就已经完成。至于什么时候再写到磁盘中由操作系统决定,除非显式地调用了sync同步命令。
第二种类型是直接IO,就是应用程序直接访问磁盘数据,而不经过内核缓冲区,从而减少了在内核缓存和用户程序之间数据复制。
如果在写的逻辑__generic_file_write_iter里面,发现设置了IOCB_DIRECT,则调用generic_file_direct_write,里面同样会调用address_space的direct_IO的函数,将数据直接写入硬盘。
带缓存的写入操作
我们先来看带缓存写入的函数generic_perform_write。
struct iov_iter *i, loff_t pos)
{
struct address_space *mapping = file->f_mapping;
const struct address_space_operations *a_ops = mapping->a_ops;
do {
struct page *page;
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
pos += copied;
written += copied;
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
}
循环中主要做了这几件事:
- 对于每一页,先调用address_space的write_begin做一些准备;
- 调用iov_iter_copy_from_user_atomic,将写入的内容从用户态拷贝到内核态的页中;
- 调用address_space的write_end完成写操作;
- 调用balance_dirty_pages_ratelimited,看脏页是否太多,需要写回硬盘。所谓脏页,就是写入到缓存,但是还没有写入到硬盘的页面。
对于第一步,调用的是ext4_write_begin来说,主要做两件事:
第一做日志相关的工作。
ext4是一种日志文件系统,是为了防止突然断电的时候的数据丢失,引入了日志(Journal)模式。日志文件系统比非日志文件系统多了一个Journal区域。文件在ext4中分两部分存储,一部分是文件的元数据,另一部分是数据。元数据和数据的操作日志Journal也是分开管理的。你可以在挂载ext4的时候,选择Journal模式。这种模式在将数据写入文件系统前,必须等待元数据和数据的日志已经落盘才能发挥作用。这样性能比较差,但是最安全。
另一种模式是order模式。这个模式不记录数据的日志,只记录元数据的日志,但是在写元数据的日志前,必须先确保数据已经落盘。这个折中,是默认模式。
还有一种模式是writeback,不记录数据的日志,仅记录元数据的日志,并且不保证数据比元数据先落盘。这个性能最好,但是最不安全。
第二调用 grab_cache_page_write_begin来,得到应该写入的缓存页。
pgoff_t index, unsigned flags)
{
struct page *page;
int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT;
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}
在内核中,缓存以页为单位放在内存里面,每一个打开的文件都有一个struct file结构,每个struct file结构都有一个struct address_space用于关联文件和内存,就是在这个结构里面,有一棵树,用于保存所有与这个文件相关的的缓存页。
对于第二步,调用 iov_iter_copy_from_user_atomic。先将分配好的页面调用kmap_atomic映射到内核里面的一个虚拟地址,然后将用户态的数据拷贝到内核态的页面的虚拟地址中,调用kunmap_atomic把内核里面的映射删除。
struct iov_iter *i, unsigned long offset, size_t bytes)
{
char *kaddr = kmap_atomic(page), *p = kaddr + offset;
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
kunmap_atomic(kaddr);
return bytes;
}
第三步中,调用ext4_write_end完成写入。这里面会调用ext4_journal_stop完成日志的写入,会调用block_write_end->__block_commit_write->mark_buffer_dirty,将修改过的缓存标记为脏页。可以看出,其实所谓的完成写入,并没有真正写入硬盘,仅仅是写入缓存后,标记为脏页。
第四步,调用 balance_dirty_pages_ratelimited,是回写脏页。
* balance_dirty_pages_ratelimited - balance dirty memory state
* @mapping: address_space which was dirtied
*
* Processes which are dirtying memory should call in here once for each page
* which was newly dirtied. The function will periodically check the system's
* dirty state and will initiate writeback if needed.
*/
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
struct inode *inode = mapping->host;
struct backing_dev_info *bdi = inode_to_bdi(inode);
struct bdi_writeback *wb = NULL;
int ratelimit;
......
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
......
}
在 balance_dirty_pages_ratelimited里面,发现脏页的数目超过了规定的数目,就调用balance_dirty_pages->wb_start_background_writeback,启动一个背后线程开始回写。
另外还有几种场景也会触发回写:
- 用户主动调用sync,将缓存刷到硬盘上去,最终会调用wakeup_flusher_threads,同步脏页;
- 当内存十分紧张,以至于无法分配页面的时候,会调用free_more_memory,最终会调用wakeup_flusher_threads,释放脏页;
- 脏页已经更新了较长时间,时间上超过了设定时间,需要及时回写,保持内存和磁盘上数据一致性。
带缓存的读操作
看带缓存的读,对应的是函数 generic_file_buffered_read。
struct iov_iter *iter, ssize_t written)
{
struct file *filp = iocb->ki_filp;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT)
goto would_block;
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
/*
* Ok, we have the page, and it's up-to-date, so
* now we can copy it to user space...
*/
ret = copy_page_to_iter(page, offset, nr, iter);
}
}
在generic_file_buffered_read函数中,我们需要先找到page cache里面是否有缓存页。如果没有找到,不但读取这一页,还要进行预读,这需要在page_cache_sync_readahead函数中实现。预读完了以后,再试一把查找缓存页。
如果第一次找缓存页就找到了,我们还是要判断,是不是应该继续预读;如果需要,就调用 page_cache_async_readahead发起一个异步预读。
最后,copy_page_to_iter会将内容从内核缓存页拷贝到用户内存空间。
-
硬盘
+关注
关注
3文章
1308浏览量
57286 -
Linux
+关注
关注
87文章
11296浏览量
209362 -
文件系统
+关注
关注
0文章
284浏览量
19904 -
数据结构
+关注
关注
3文章
573浏览量
40124 -
进程
+关注
关注
0文章
203浏览量
13960
发布评论请先 登录
相关推荐

Linux文件系统课程
玩转Linux,先把文件系统搞懂

文件系统是什么?浅谈EXT文件系统历史

Linux 内核/sys 文件系统介绍
可以了解的Linux 文件系统结构
Linux最新UBI文件系统介绍
linux文件系统中的虚拟文件系统设计详解
Linux文件系统解析
Linux文件系统的特点及缓存知识

适用于Linux的最佳通用文件系统 Linux文件系统的安装






 工商网监
工商网监
评论