 使用RayDF方法突破3D形状重建方案
使用RayDF方法突破3D形状重建方案
1.摘要
传统的三维形状表示方法存在离散化和内存占用等问题,而基于深度学习的方法在恢复三维几何结构方面取得了显著的进展。然而,这些方法的离散形状表示受到空间分辨率和内存占用的限制。因此,本文提出了一种新的三维形状表示方法,即射线-表面距离场(RayDF),通过学习射线与表面之间的距离来表示三维形状。与现有的基于坐标和射线的方法相比,RayDF具有更高的效率和更准确的三维几何重建能力。同时,本文还引入了多视角一致性优化模块,以提高学习到的射线-表面距离场在不同视角下的一致性。通过在多个数据集上的实验证明,RayDF方法在三维形状重建的准确性和效率方面优于现有的方法。
2.研究思路
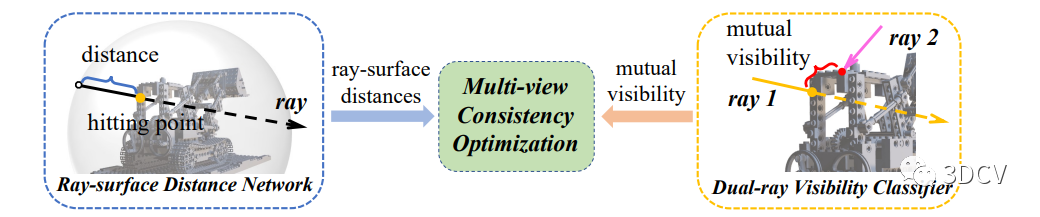
本研究的研究思路是通过神经网络来学习三维形状的表面距离,并保持多视角一致性。我们提出了一种称为RayDF的方法,它包括三个关键组件:
主要的射线-表面距离网络
辅助的双射线可见性分类器
多视角一致性优化模块
3.贡献
我们采用了直观的射线-表面距离场来表示三维形状,这种表示方法比现有的基于坐标的表示更高效。
我们设计了一种新的双射线可见性分类器,用于学习任意一对射线的空间关系,使学到的射线-表面距离场具有多视角几何一致性。
我们在多个数据集上展示了优越的三维形状重建准确性和效率,相比于现有的基于坐标和基于射线的基线方法,取得了显著更好的结果。
4.研究问题的解决方法
通过训练主要的射线-表面距离网络和辅助的双射线可见性分类器,并引入多视角一致性优化模块来训练这两个网络。具体而言,我们的训练模块包括两个阶段:
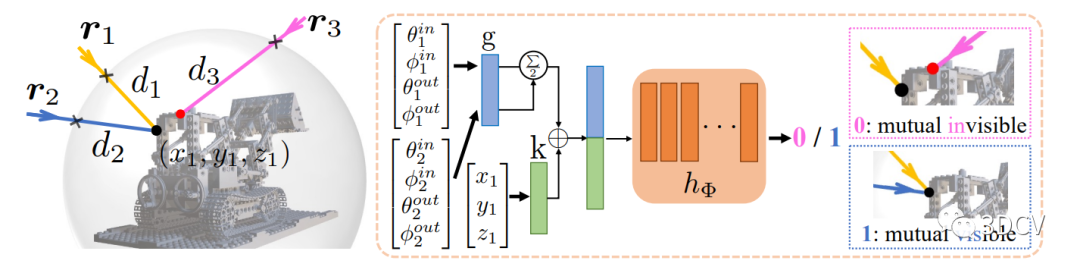
阶段1:训练双射线可见性分类器。关键是创建正确的数据对,将原始深度值转换为射线-表面距离值,并生成射线对和0/1标签。采用标准的交叉熵损失函数来优化双射线可见性分类器。
阶段2:训练射线-表面距离网络。将所有深度图像转换为射线-表面距离,为特定的3D场景生成训练射线-距离对。通过采样多视角射线并利用训练好的可见性分类器,优化射线-表面距离网络,使其不仅适应已见射线的距离,还能准确估计未见射线的距离,从而实现多视角一致性。
5.RayDF网络结构和训练过程
网络结构
RayDF模型包括主要的射线-表面距离网络、辅助的双射线可见性分类器和多视角一致性优化模块。
训练过程
第一阶段是训练双射线可见性分类器
首先,将所有原始深度值转换为射线-表面距离值。对于第k张图像中的第i条射线(像素),将其射线-表面点投影回剩余的(K-1)个扫描中,得到相应的(K-1)个距离值。设置10毫米作为接近阈值,确定投影的(K-1)条射线在(K-1)个图像中是否可见。总共生成K* H * W * (K-1)对射线,以及0/1标签。采用标准的交叉熵损失函数来优化双射线可见性分类器。推荐三维重建课程基于深度学习的三维重建MVSNet系列 [论文+源码+应用+科研]
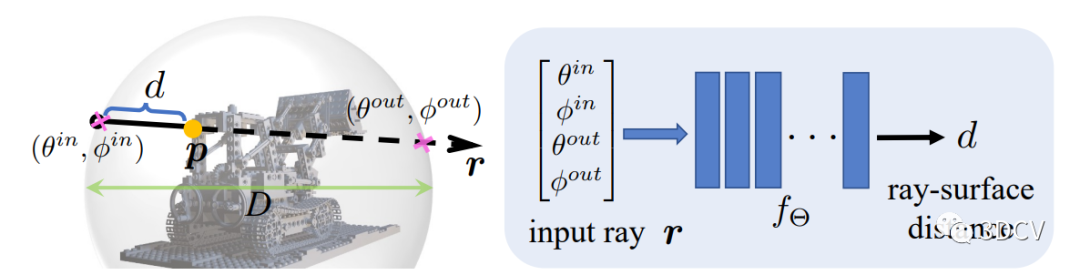
第二阶段是训练射线-表面距离网络
首先,将所有深度图像转换为射线-表面距离,为特定的3D场景生成K * H * W个训练射线-距离对。然后,对于特定的训练射线,称为主射线,我们在以表面点p为球心的球中均匀采样M条射线,称为多视角射线。
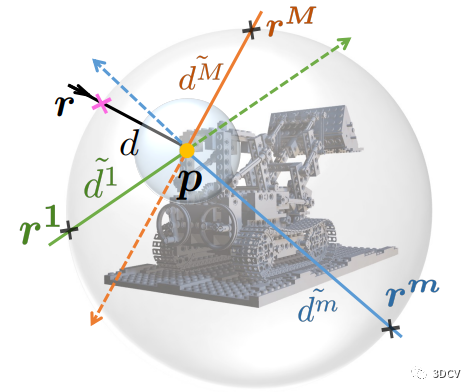
然后,计算表面点p与沿着每条多视角射线的边界球之间的距离,得到多视角距离。
接下来,建立M对射线并将它们输入到训练好的可见性分类器中,推断它们的可见性得分。
然后,将主射线和所有采样的M条多视角射线输入到射线-表面距离网络中,估计它们的表面距离。
最后,使用多视角一致性损失函数来(公式如下)优化射线-表面距离网络,使其不仅适应主射线的表面距离,还满足可见的多视角射线也具有准确的距离估计。
6.创新点
主要体现在以下几个方面:
提出了一种新的神经网络模型,称为RayDF,用于学习三维场景的表面距离。与传统的基于点云或体素的方法不同,RayDF利用射线与表面的交点来表示场景的几何形状,从而更准确地捕捉细节和形状变化。
引入了多视角一致性约束,通过训练网络来学习不同视角下的一致性信息。这种约束可以提高模型在新视角下的泛化能力,使其能够更好地处理未见过的场景。
提出了双射线可见性分类器,用于判断射线是否与表面相交。这个分类器可以帮助网络学习更准确的表面距离,并提高模型在测试阶段的性能。
在实验中,本研究在多个真实世界的三维数据集上进行了评估,并与其他基线方法进行了比较。
7.实验方法
本研究采用了两组实验方法进行评估。第一组实验方法是基于多视角深度图像的三维形状表示。在这组实验中,我们使用了多视角深度图像作为输入,通过训练模型来学习三维场景的形状表示。我们与其他基线方法进行了比较,包括OF、DeepSDF、NDF、NeuS、DS-NeRF、LFN和PRIF。通过对六个ScanNet数据集场景的评估,我们发现我们的方法在ADE指标上表现明显优于其他方法,展示了我们方法在显式表面恢复方面的明显优势。第二组实验方法是基于多视角RGB图像和深度图像的三维形状和外观表示。在这组实验中,我们使用了多视角RGB图像和深度图像作为输入,通过训练模型来学习三维场景的形状和外观表示。我们与NeuS、DS-NeRF、LFN和PRIF等基线方法进行了比较。通过对DM-SR数据集的评估,我们发现我们的方法在ADE指标上再次超越了所有基线方法,展示了我们方法在形状恢复方面的优势。同时,我们的方法在PSNR、SSIM和LPIPS等指标上也取得了可比较的性能。
8.结论
本文的研究旨在提出一种称为RayDF的方法,用于准确地表示三维形状。该方法基于射线-表面距离场的概念,通过训练一个主要的射线-表面距离网络和一个辅助的双射线可见性分类器,以及一个多视角一致性优化模块来实现。主要网络直接将射线作为输入,并推断射线起点与其在表面上的击中点之间的距离。辅助网络则以一对射线作为输入,并预测它们的相互可见性。通过训练辅助网络,可以有效地利用学到的双射线可见性来训练主网络,从而使学到的射线-表面距离在任何已见或未见的视角下保持多视角一致性。研究结果表明,相比于现有的基于坐标的表示方法,RayDF方法在效率上具有优势,而相比于现有的基于射线的方法,RayDF方法在学习准确的三维几何形状方面表现出色。在多个数据集上的实验证明了RayDF方法在三维形状重建的准确性和效率方面的优越性。
编辑:黄飞
-
神经网络
+关注
关注
42文章
4789浏览量
101597 -
分类器
+关注
关注
0文章
152浏览量
13283 -
网络结构
+关注
关注
0文章
48浏览量
11318 -
数据集
+关注
关注
4文章
1212浏览量
24990 -
深度图像
+关注
关注
0文章
19浏览量
3539
原文标题:香港理工大学最新提出精确3D重建的突破性方法
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
3d全息风扇灯条|3D全息风扇方案|3d全息风扇PCBA
PYNQ框架下如何快速完成3D数据重建
在Altium Designer创建不寻常的3D形状
使用结构光的3D扫描介绍
光学3D表面轮廓仪可以测金属吗?
创想三维:3D扫描仪在3D打印机上的运用

音圈模组3D打印助力肌腱和韧带重建
大规模3D重建的Power Bundle Adjustment
英伟达提出了同时对未知物体进行6D追踪和3D重建的方法

基于未知物体进行6D追踪和3D重建的方法

基于3D形状重建网络的机器人抓取规划方法
使用Python从2D图像进行3D重建过程详解

三维扫描与3D打印在法医头骨重建中的突破性应用





 工商网监
工商网监
评论