 后端有点卷?冲客户端去了!
后端有点卷?冲客户端去了!
大家好,我是小林。
互联网岗位里,可以说后端开发是最卷,投的人最多的,但是隔壁的客户端开发投的就很少,有后端同学会被客户端部门捞起来去面试,所以如果卷不过后端,又想进大厂的同学,可以尝试投客户端开发,面试相对没那么卷,薪资待遇跟后端也是一样的。
今天分享一位快手客户端一二三面的面经,同学的技术栈是C++后端,但是面试不会问后端内容了,主要就围绕Cpp+操作系统+网络协议+算法来问,相比后端所需要准备的内容就少了 mysql 、redis、消息队列等后端组件,但是计算基础的深度会问的比较深一点。
由其第三面,直接给两个场景代码题手写出来,还是有点难度。。
快手一面
拥塞控制介绍一下
在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大....
所以,TCP 不能忽略网络上发生的事,它被设计成一个无私的协议,当网络发送拥塞时,TCP 会自我牺牲,降低发送的数据量。
于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。
为了在「发送方」调节所要发送数据的量,定义了一个叫做「拥塞窗口」的概念。
拥塞控制主要是四个算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
慢启动
TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量,如果一上来就发大量的数据,这不是给网络添堵吗?
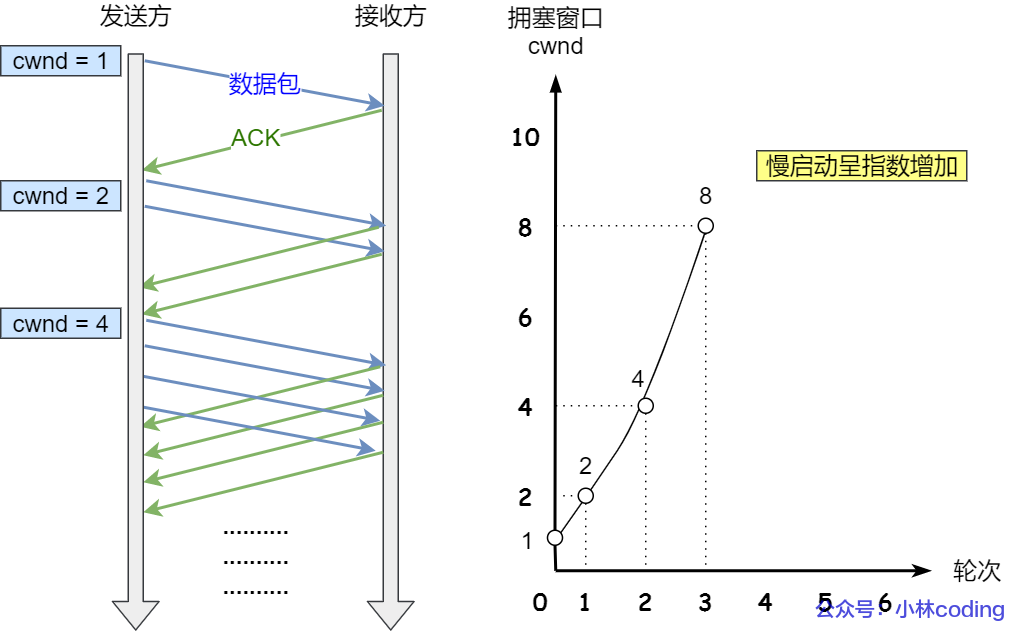
慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
这里假定拥塞窗口 cwnd 和发送窗口 swnd 相等,下面举个栗子:
-
连接建立完成后,一开始初始化
cwnd = 1,表示可以传一个MSS大小的数据。 - 当收到一个 ACK 确认应答后,cwnd 增加 1,于是一次能够发送 2 个
- 当收到 2 个的 ACK 确认应答后, cwnd 增加 2,于是就可以比之前多发2 个,所以这一次能够发送 4 个
- 当这 4 个的 ACK 确认到来的时候,每个确认 cwnd 增加 1, 4 个确认 cwnd 增加 4,于是就可以比之前多发 4 个,所以这一次能够发送 8 个。
慢启动算法的变化过程如下图:
 慢启动算法
慢启动算法
可以看出慢启动算法,发包的个数是指数性的增长。
那慢启动涨到什么时候是个头呢?
有一个叫慢启动门限 ssthresh (slow start threshold)状态变量。
-
当
cwnd<ssthresh时,使用慢启动算法。 -
当
cwnd>=ssthresh时,就会使用「拥塞避免算法」。
拥塞避免
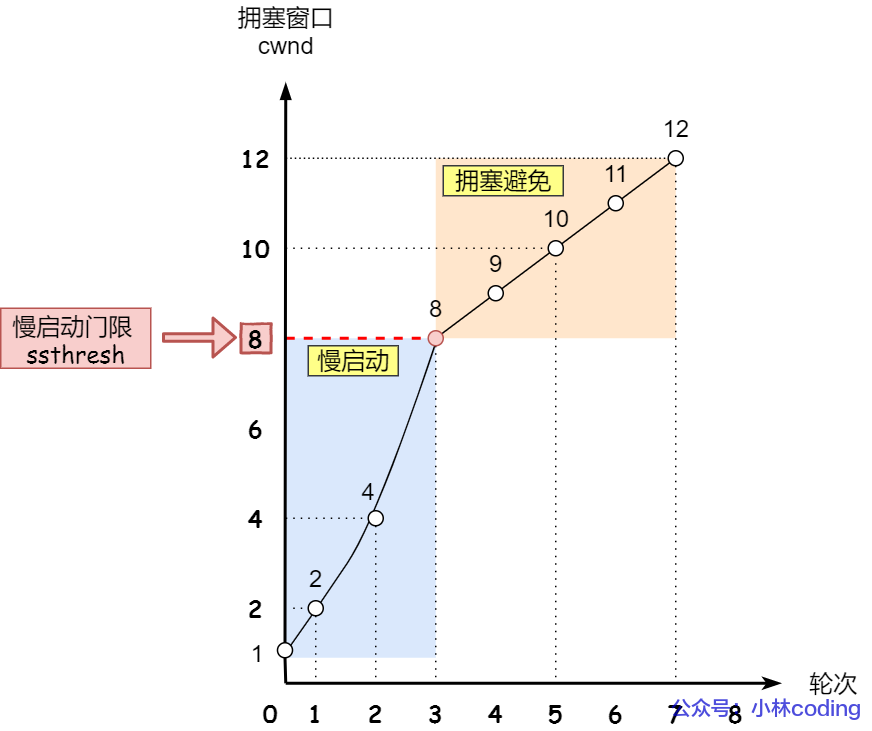
当拥塞窗口 cwnd 「超过」慢启动门限 ssthresh 就会进入拥塞避免算法。
一般来说 ssthresh 的大小是 65535 字节。
那么进入拥塞避免算法后,它的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。
接上前面的慢启动的栗子,现假定 ssthresh 为 8:
-
当 8 个 ACK 应答确认到来时,每个确认增加 1/8,8 个 ACK 确认 cwnd 一共增加 1,于是这一次能够发送 9 个
MSS大小的数据,变成了线性增长。
拥塞避免算法的变化过程如下图:
 拥塞避免
拥塞避免
所以,我们可以发现,拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。
就这么一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。
当触发了重传机制,也就进入了「拥塞发生算法」。
拥塞发生
当网络出现拥塞,也就是会发生数据包重传,重传机制主要有两种:
- 超时重传
- 快速重传
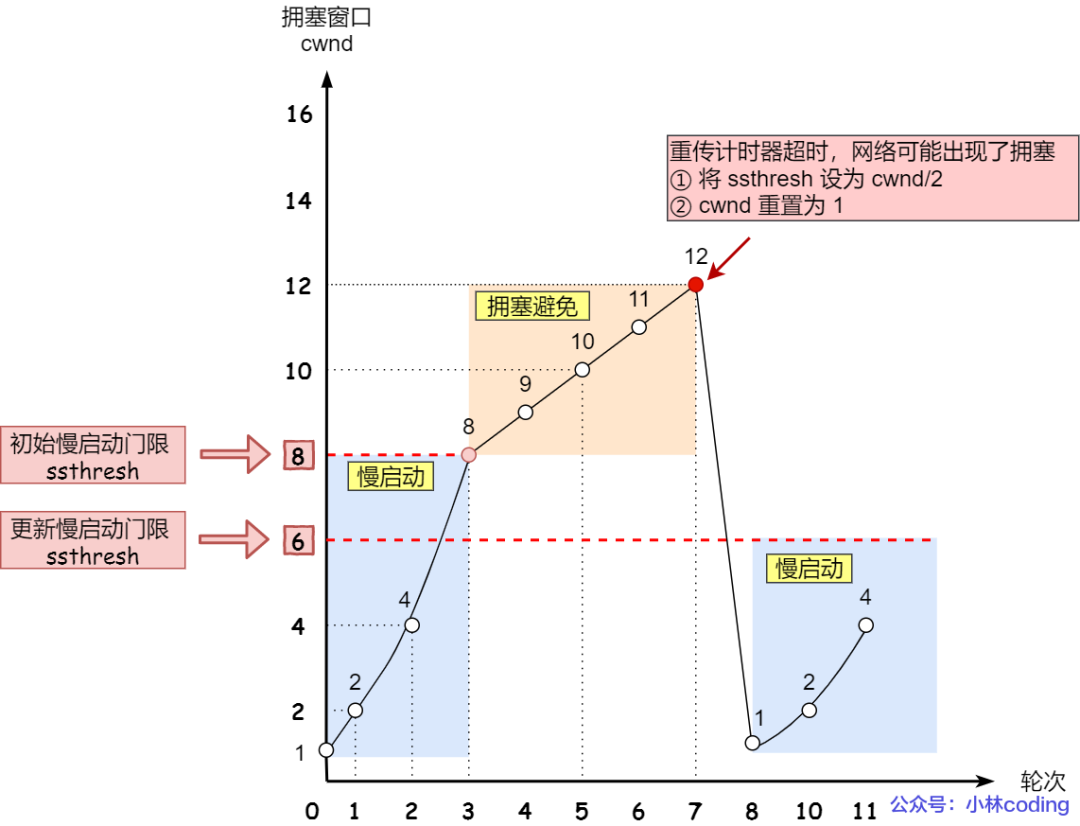
当发生了「超时重传」,则就会使用拥塞发生算法。
这个时候,ssthresh 和 cwnd 的值会发生变化:
-
ssthresh设为cwnd/2, -
cwnd重置为1(是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)
拥塞发生算法的变化如下图:
 拥塞发送 —— 超时重传
拥塞发送 —— 超时重传
接着,就重新开始慢启动,慢启动是会突然减少数据流的。这真是一旦「超时重传」,马上回到解放前。但是这种方式太激进了,反应也很强烈,会造成网络卡顿。
还有更好的方式,前面我们讲过「快速重传算法」。当接收方发现丢了一个中间包的时候,发送三次前一个包的 ACK,于是发送端就会快速地重传,不必等待超时再重传。
TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
-
cwnd = cwnd/2,也就是设置为原来的一半; -
ssthresh = cwnd; - 进入快速恢复算法
快速恢复
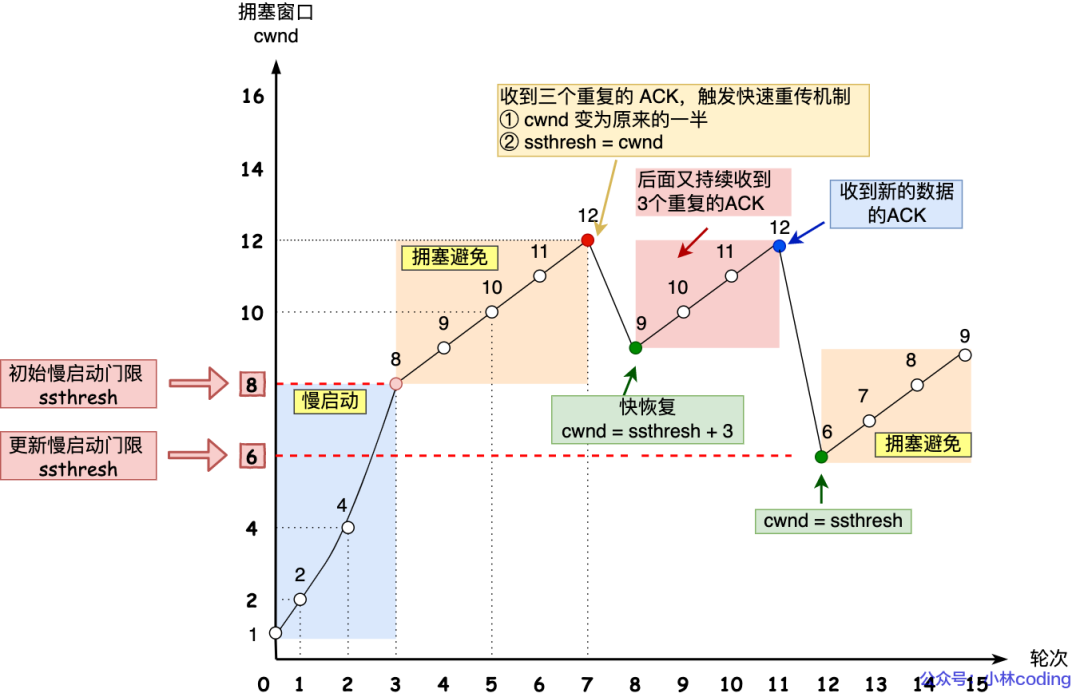
快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈。
正如前面所说,进入快速恢复之前,cwnd 和 ssthresh 已被更新了:
-
cwnd = cwnd/2,也就是设置为原来的一半; -
ssthresh = cwnd;
然后,进入快速恢复算法如下:
-
拥塞窗口
cwnd = ssthresh + 3( 3 的意思是确认有 3 个数据包被收到了); - 重传丢失的数据包;
- 如果再收到重复的 ACK,那么 cwnd 增加 1;
- 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
快速恢复算法的变化过程如下图:
 快速重传和快速恢复
快速重传和快速恢复
也就是没有像「超时重传」一夜回到解放前,而是还在比较高的值,后续呈线性增长。
http/ https 的区别?
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- 两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
Https四次加密过程?
基于 RSA 算法的 TLS 握手过程比较容易理解,所以这里先用这个给大家展示 TLS 握手过程,如下图:
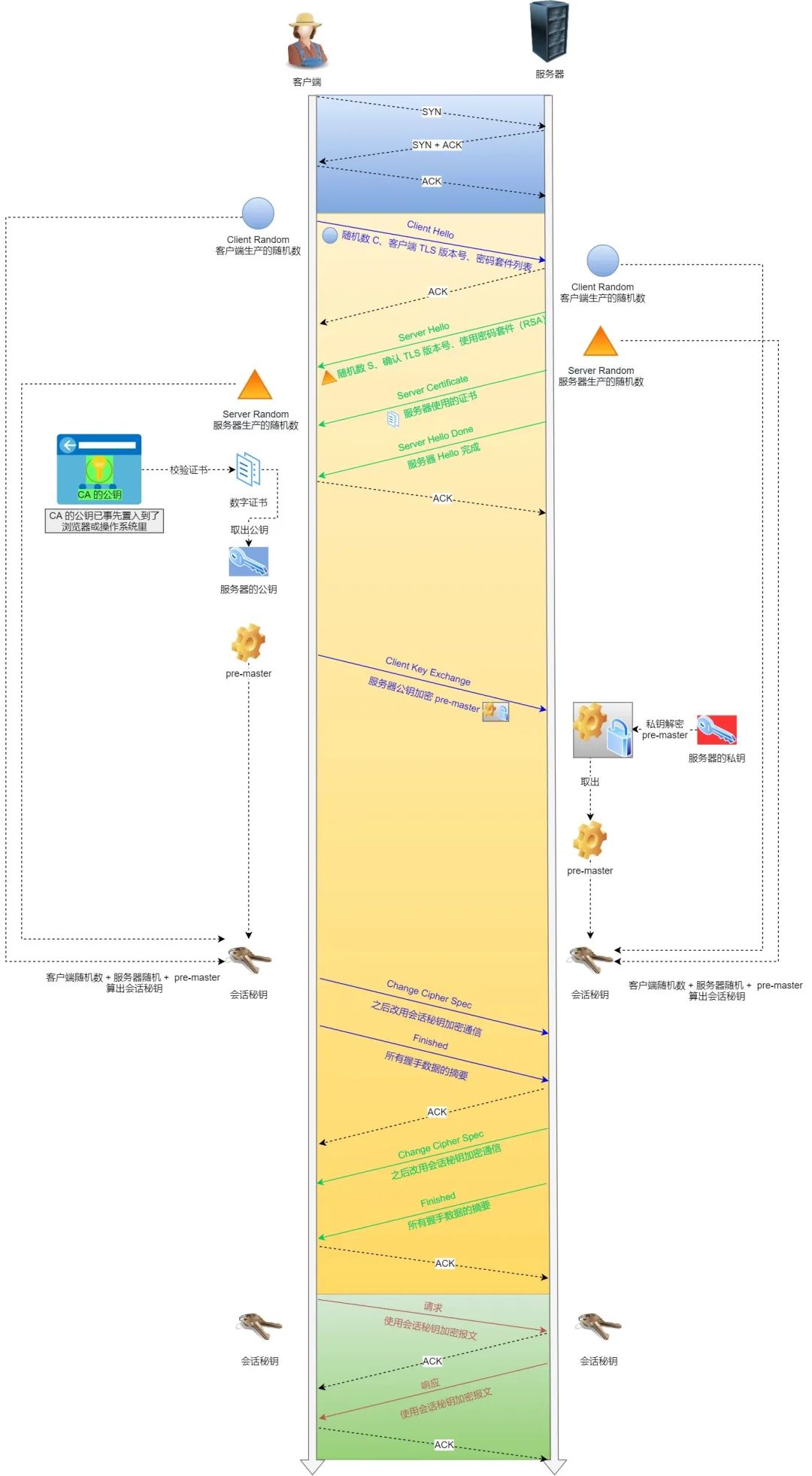 HTTPS 连接建立过程
HTTPS 连接建立过程TLS 协议建立的详细流程:
1. ClientHello
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
(1)客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
(2)客户端生产的随机数(Client Random),后面用于生成「会话秘钥」条件之一。
(3)客户端支持的密码套件列表,如 RSA 加密算法。
2. SeverHello
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
(1)确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信。
(2)服务器生产的随机数(Server Random),也是后面用于生产「会话秘钥」条件之一。
(3)确认的密码套件列表,如 RSA 加密算法。
(4)服务器的数字证书。
3.客户端回应
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
(1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
(2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
4. 服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
get和post的区别?
- 根据 RFC 规范,GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。
- 根据 RFC 规范,POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中,body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。
进程线程 有什么区别?
-
资源占用:每个进程都有独立的地址空间、文件描述符和其他系统资源,进程之间的资源是相互独立的,而线程共享所属进程的地址空间和资源,包括文件描述符、信号处理等。
-
调度和切换:进程是系统进行调度和分配资源的基本单位,进程之间的切换开销相对较大。而线程是在进程内部执行的,线程的切换开销相对较小。
-
通信和同步:进程之间通信的方式包括管道、消息队列、共享内存等,进程间通信相对复杂。线程之间共享进程的内存空间,直接读写共享数据即可实现通信和同步。
线程有哪些资源,栈中保存什么?
线程在操作系统中有一些特定的资源,包括:
-
线程控制块(Thread Control Block,TCB):用于保存线程的状态信息,如程序计数器(Program Counter,PC)、寄存器值、线程 ID、线程优先级等。
-
栈(Stack):每个线程都有自己的栈空间,用于保存函数调用的局部变量、函数的返回地址以及其他临时数据。栈是线程私有的,不同线程之间的栈是相互独立的。
-
寄存器(Registers):线程在执行过程中会使用到寄存器,包括通用寄存器(如EAX、EBX等)、程序计数器(PC)等。寄存器保存了线程当前的执行状态。
-
共享资源:线程可以共享所属进程的资源,如打开的文件、信号处理器等。这些资源可以在线程之间共享和访问。
栈中,主要保存了以下内容:
-
函数调用的局部变量:当一个函数被调用时,其局部变量会被保存在栈中。这些局部变量在函数执行结束后会被销毁。
-
函数的返回地址:当一个函数执行完毕后,需要返回到调用该函数的地址。返回地址会被保存在栈中,以便函数执行完毕后能够正确返回。
-
函数调用过程中的临时数据:在函数执行过程中,可能会需要保存一些临时数据,如函数的参数、中间计算结果等,这些数据会保存在栈中。
函数调用的时候压栈怎么样的
函数调用时,会进行以下压栈操作:
-
保存返回地址:在函数调用前,调用指令会将下一条指令的地址(即函数调用后需要继续执行的地址)压入栈中,以便函数执行完毕后能够正确返回到调用点。
-
保存调用者的栈帧指针:在函数调用前,调用指令会将当前栈帧指针(即调用者的栈指针)压入栈中,以便函数执行完毕后能够恢复到调用者的执行状态。
-
传递参数:函数调用时,会将参数值依次压入栈中,这些参数值在函数内部可以通过栈来访问。
-
分配局部变量空间:函数调用时,会为局部变量分配空间,这些局部变量会被保存在栈中。栈指针会相应地移动以适应新的局部变量空间。
静态链接库和动态链接库有什么区别?
- 链接方式:静态链接库在编译链接时会被完整地复制到可执行文件中,成为可执行文件的一部分;而动态链接库在编译链接时只会在可执行文件中包含对库的引用,实际的库文件在运行时由操作系统动态加载。
- 文件大小:静态链接库会使得可执行文件的大小增加,因为库的代码被完整地复制到可执行文件中;而动态链接库不会增加可执行文件的大小,因为库的代码在运行时才会被加载。
- 内存占用:静态链接库在运行时会被完整地加载到内存中,占用固定的内存空间;而动态链接库在运行时才会被加载,可以在多个进程之间共享,减少内存占用。
- 可扩展性:动态链接库的可扩展性更好,可以在不修改可执行文件的情况下替换或添加新的库文件,而静态链接库需要重新编译链接。
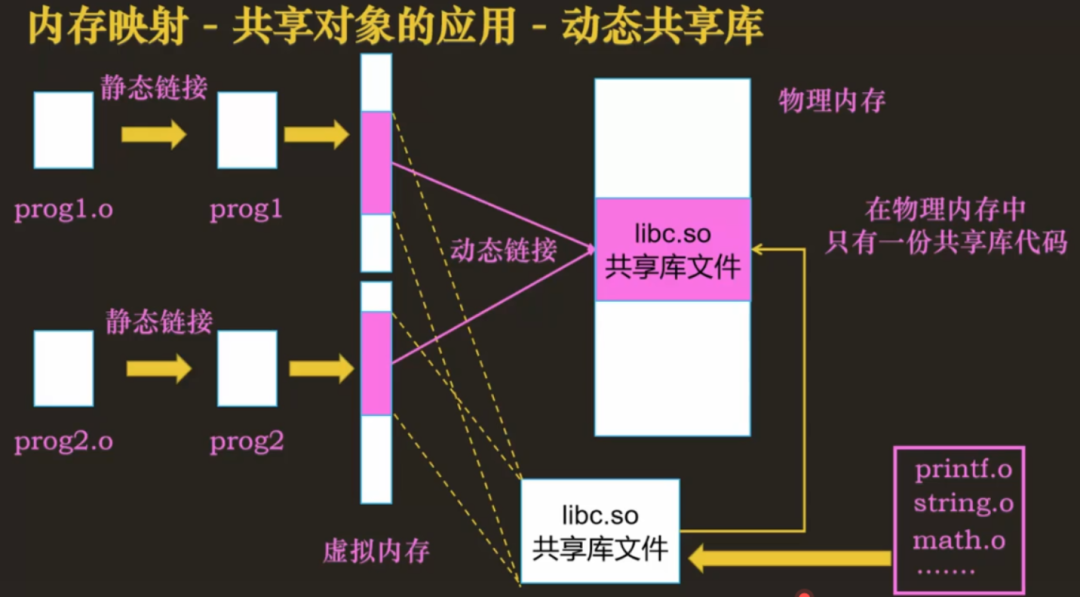
动态链接库怎么装载到内存的?
通过用mmap把该库直接映射到各个进程的地址空间中,尽管每个进程都认为自己地址空间中加载了该库,但实际上该库在内存中只有一份,mmap就这样很神奇和动态链接库联动起来了。
 img
img虚拟内存介绍一下
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
中断是什么
在操作系统中,中断是指由硬件或软件触发的一种事件,它会暂时中止当前正在执行的程序,并转而执行与中断相关的处理程序。中断可以是内部的,如除法错误或越界访问,也可以是外部的,如硬件设备的输入/输出请求或时钟中断。
中断的作用是提供一种机制来处理和响应各种事件,例如处理硬件设备的输入/输出请求、处理异常情况、进行时钟调度等。当发生中断时,操作系统会根据中断类型确定要执行的中断处理程序,并在处理完中断后恢复原来的程序执行。
中断处理程序可以执行一系列操作,如保存当前进程的上下文、处理中断事件、与设备进行通信、调度其他进程等。通过使用中断,操作系统可以实现多任务处理、实时响应外部事件、提高系统的可靠性和稳定性。
操作系统的锁,自己实现一个读写锁
读者只会读取数据,不会修改数据,而写者即可以读也可以修改数据。
读者-写者的问题描述:
- 「读-读」允许:同一时刻,允许多个读者同时读
- 「读-写」互斥:没有写者时读者才能读,没有读者时写者才能写
- 「写-写」互斥:没有其他写者时,写者才能写
接下来,提出几个解决方案来分析分析。
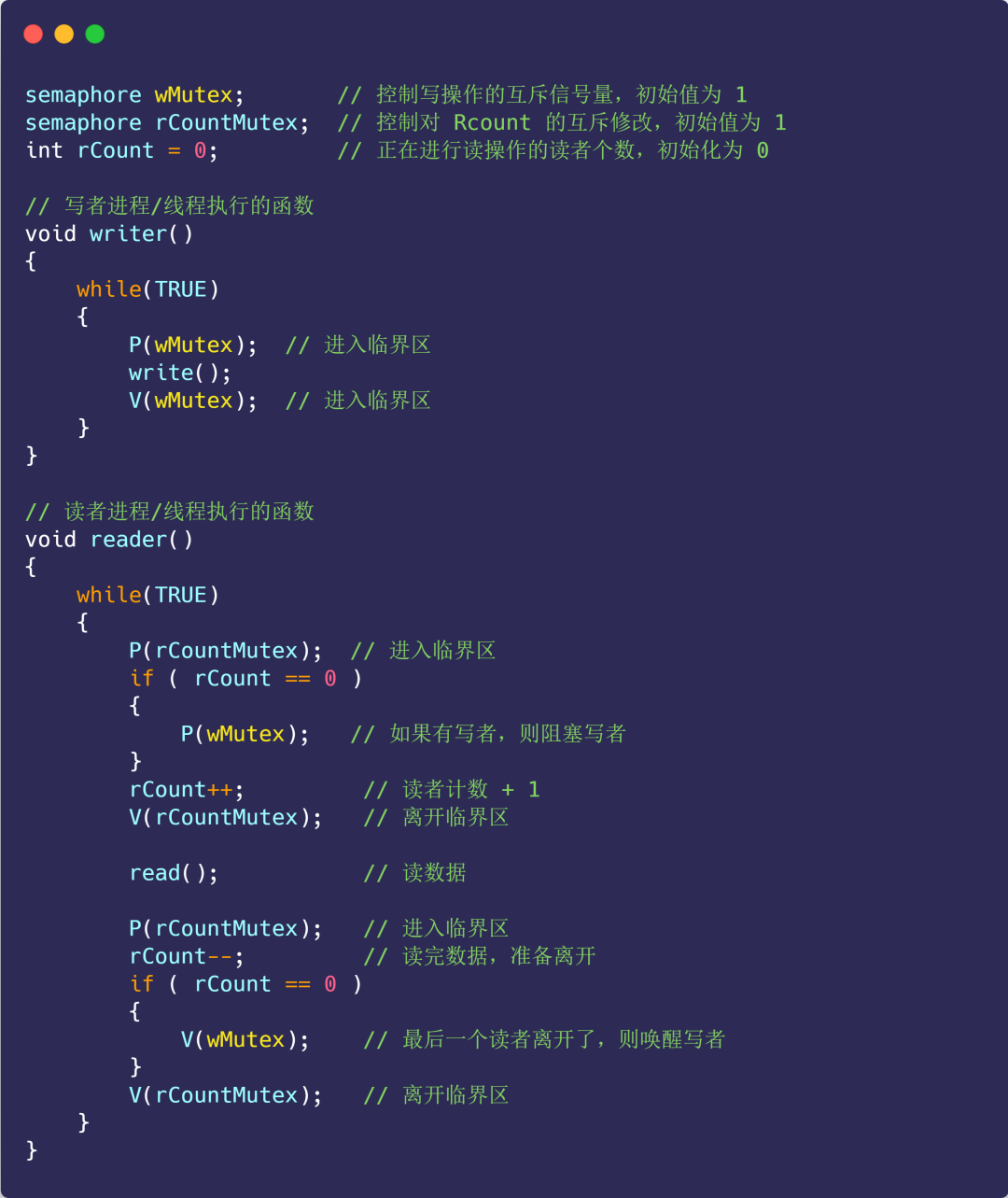
方案一
使用信号量的方式来尝试解决:
-
信号量
wMutex:控制写操作的互斥信号量,初始值为 1 ; -
读者计数
rCount:正在进行读操作的读者个数,初始化为 0; -
信号量
rCountMutex:控制对 rCount 读者计数器的互斥修改,初始值为 1;
接下来看看代码的实现:
 img
img上面的这种实现,是读者优先的策略,因为只要有读者正在读的状态,后来的读者都可以直接进入,如果读者持续不断进入,则写者会处于饥饿状态。
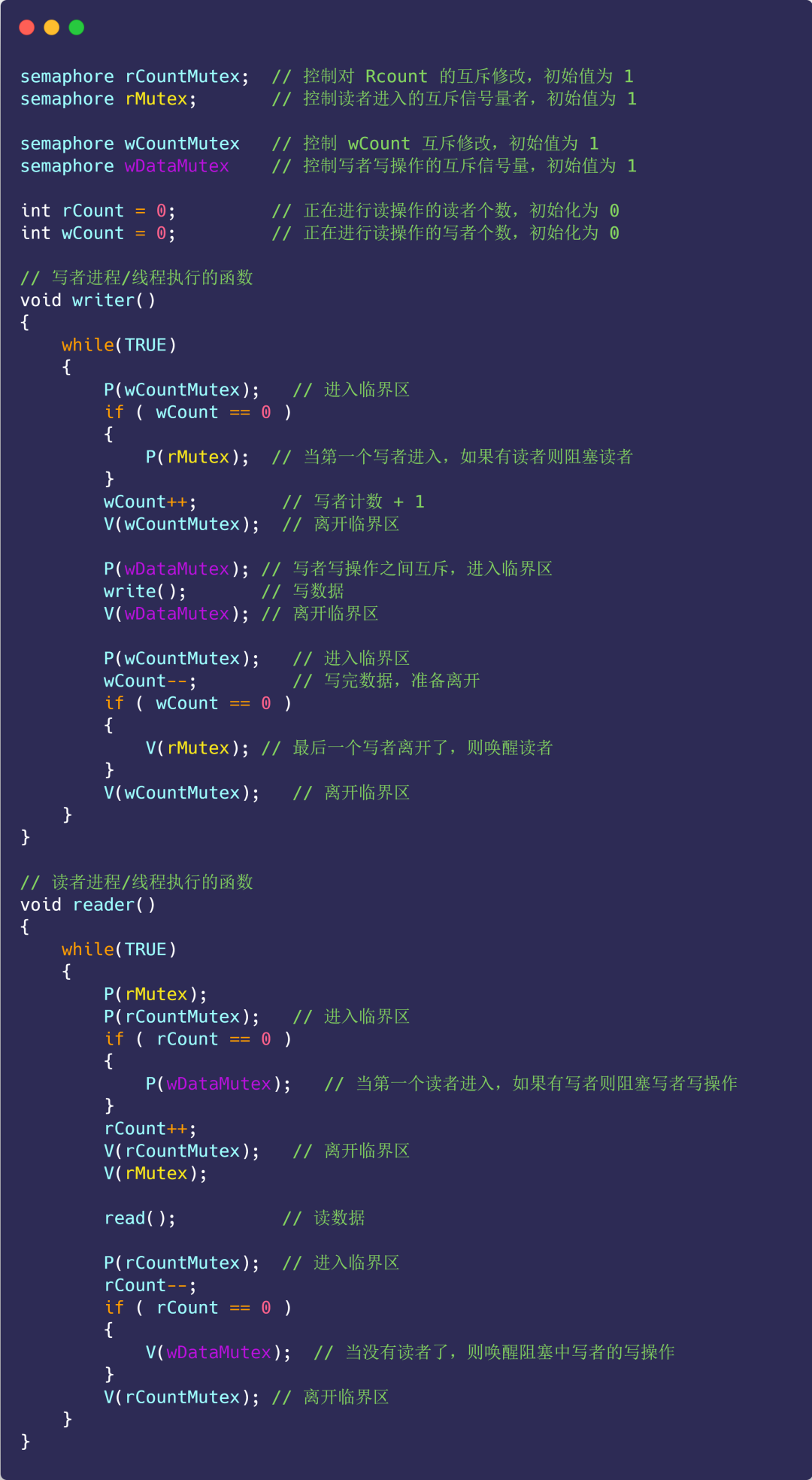
方案二
那既然有读者优先策略,自然也有写者优先策略:
- 只要有写者准备要写入,写者应尽快执行写操作,后来的读者就必须阻塞;
- 如果有写者持续不断写入,则读者就处于饥饿;
在方案一的基础上新增如下变量:
-
信号量
rMutex:控制读者进入的互斥信号量,初始值为 1; -
信号量
wDataMutex:控制写者写操作的互斥信号量,初始值为 1; -
写者计数
wCount:记录写者数量,初始值为 0; -
信号量
wCountMutex:控制 wCount 互斥修改,初始值为 1;
具体实现如下代码:
 img
img
注意,这里 rMutex 的作用,开始有多个读者读数据,它们全部进入读者队列,此时来了一个写者,执行了 P(rMutex) 之后,后续的读者由于阻塞在 rMutex 上,都不能再进入读者队列,而写者到来,则可以全部进入写者队列,因此保证了写者优先。
同时,第一个写者执行了 P(rMutex) 之后,也不能马上开始写,必须等到所有进入读者队列的读者都执行完读操作,通过 V(wDataMutex) 唤醒写者的写操作。
方案三
既然读者优先策略和写者优先策略都会造成饥饿的现象,那么我们就来实现一下公平策略。
公平策略:
- 优先级相同;
- 写者、读者互斥访问;
- 只能一个写者访问临界区;
- 可以有多个读者同时访问临界资源;
具体代码实现:
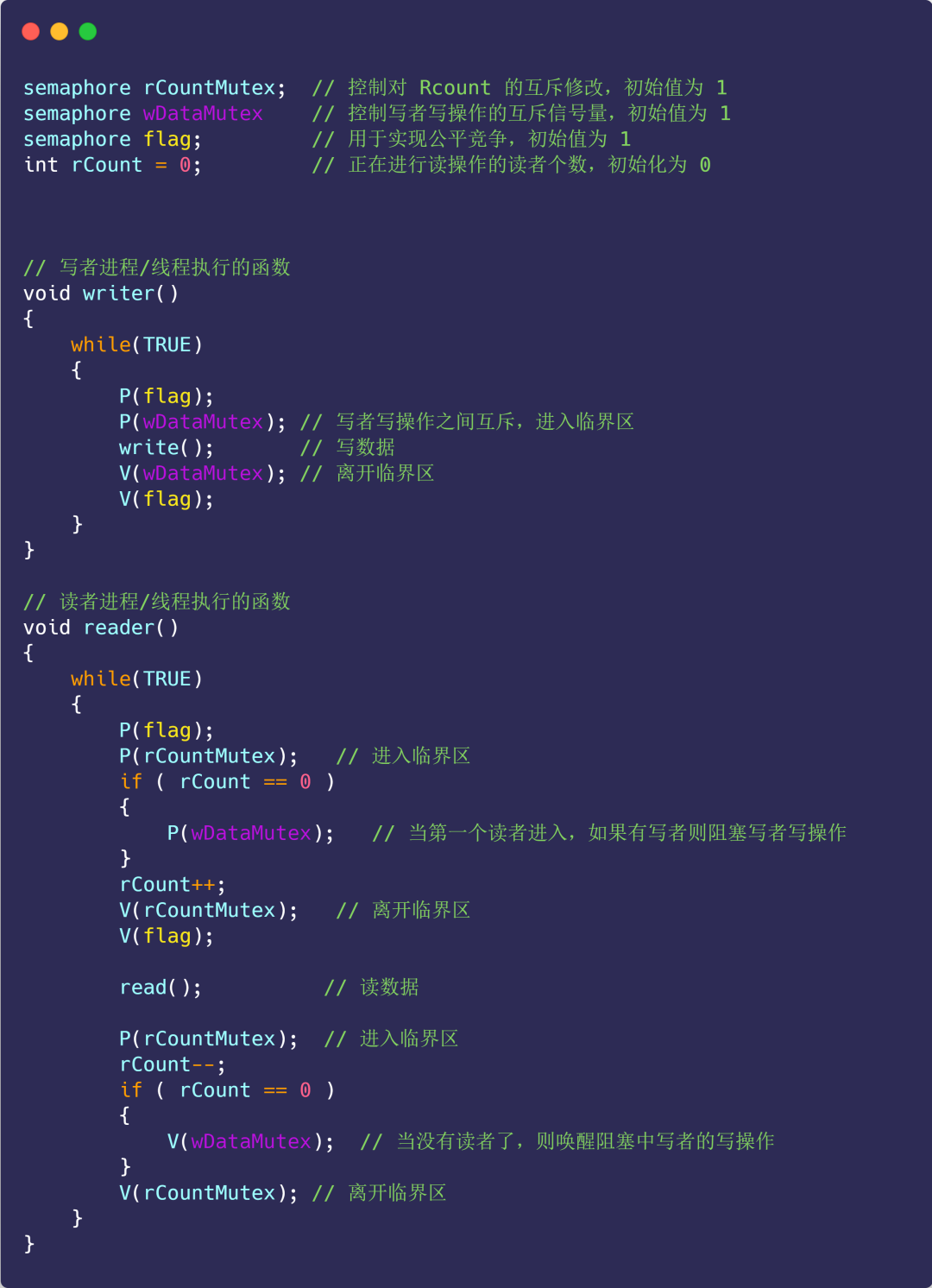 img
img
看完代码不知你是否有这样的疑问,为什么加了一个信号量 flag,就实现了公平竞争?
对比方案一的读者优先策略,可以发现,读者优先中只要后续有读者到达,读者就可以进入读者队列, 而写者必须等待,直到没有读者到达。
没有读者到达会导致读者队列为空,即 rCount==0,此时写者才可以进入临界区执行写操作。
而这里 flag 的作用就是阻止读者的这种特殊权限(特殊权限是只要读者到达,就可以进入读者队列)。
比如:开始来了一些读者读数据,它们全部进入读者队列,此时来了一个写者,执行 P(falg) 操作,使得后续到来的读者都阻塞在 flag 上,不能进入读者队列,这会使得读者队列逐渐为空,即 rCount 减为 0。
这个写者也不能立马开始写(因为此时读者队列不为空),会阻塞在信号量 wDataMutex 上,读者队列中的读者全部读取结束后,最后一个读者进程执行 V(wDataMutex),唤醒刚才的写者,写者则继续开始进行写操作。
算法题
- 二叉树层序遍历 构建一个二叉树测试
快手二面
指针和引用值传递的概念
- 值传递是指将参数的值复制一份,传递给函数或方法进行操作。在值传递中,函数或方法对参数进行修改不会影响到原始的变量值。
- 指针引用是指将参数的内存地址传递给函数或方法,使得函数或方法可以直接访问和修改原始变量的值。在指针引用中,函数或方法对参数的修改会直接反映在原始变量上。
int double string强制转化为什么会精度丢失?
-
整数到浮点数:整数类型是精确表示的,而浮点数类型则是近似表示的,具有固定的有效位数。当将整数转换为浮点数时,可能会导致精度丢失,因为浮点数无法精确地表示整数的所有位数。
-
浮点数到整数:浮点数类型具有小数部分和指数部分,而整数类型只能表示整数值。当将浮点数转换为整数时,小数部分将被丢弃,可能导致精度丢失。
-
字符串到数值类型:字符串表示的是文本形式的数据,而数值类型表示的是数值形式的数据。当将字符串转换为数值类型时,如果字符串无法解析为有效的数值,或者字符串表示的数值超出了目标类型的范围,就会导致精度丢失或产生错误的结果。
void*是什么?
void*是一种通用的指针类型,被称为"无类型指针"。它可以用来表示指向任何类型的指针,因为void*指针没有指定特定的数据类型。
由于void*是无类型的,它不能直接进行解引用操作,也不能进行指针运算。在使用void*指针时,需要将其转换为具体的指针类型才能进行操作。
void*指针常用于需要在不同类型之间进行通用操作的情况,例如在函数中传递任意类型的指针参数或在动态内存分配中使用。
malloc的参数列表 void*怎么转化为int*的?
可以使用类型转换将void*指针转化为int*指针。以下是将void*指针转化为int*指针的示例代码:
void*voidPtr=malloc(sizeof(int));//分配内存并返回void*指针
int*intPtr=(int*)voidPtr;//将void*指针转化为int*指针
//现在可以通过intPtr指针访问int类型的数据
*intPtr=42;
在上述示例中,使用malloc函数分配了存储一个int类型数据所需的内存,并返回了一个void*指针。然后,通过将void*指针转换为int*指针,将其赋值给intPtr变量。现在,可以通过intPtr指针访问和操作int类型的数据。
算法题
- 从一个数组中找出满足比左侧都要大比右侧都要小的数
快手三面
-
n个线程按照顺序打印编号
-
设计一个贪吃蛇小游戏,蛇的数据结构和蛇体更新和碰撞检测
三面一个八股没问,直接来两个场景代码题,比较注重实操,太难啦。
-
C++
+关注
关注
22文章
2114浏览量
73833 -
数据包
+关注
关注
0文章
267浏览量
24482 -
后端
+关注
关注
0文章
31浏览量
2291
原文标题:后端有点卷?冲客户端去了!
文章出处:【微信号:小林coding,微信公众号:小林coding】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
IR915作为OpenVPN服务器实现客户端子网互联的过程
STM32+以太网ENC28J60作为客户端
如何解决lwip的netconn客户端发送问题
UDP、TCP客户端、TCP服务器同时运行时出错该怎么办?
stm32f107vc lwip tcp客户端
实时性计算能力带宽内存客户端需要计算什么
通讯猫MQTT服务器在线客户端的问题

ROS是如何设计的 ROS客户端库
后端太卷?冲测开去了!






 工商网监
工商网监
评论