 聊聊例化寄存器型的RTL编码设计
聊聊例化寄存器型的RTL编码设计
这篇文章来整体的聊一下个人理解的例化寄存器型的RTL编码风格。在脱离实验室氛围开始在公司写芯片设计代码的时候,就发现公司里代码规范里明确表明:
1.避免always @*语句;
2.避免always时序语句;
这让我幼小的心灵备受打击,不用always怎么怎么写RTL呢?当然了写着写着也就习惯了。避免always @*这个咱们已经理解用意了,主要是避免X态问题被掩盖。那么避免always时序语句是为什么?又应该如何实操呢? 要避免always时序语句其实也很简单,自然就是例化dff了呀,根据接口和特性可以划分归类一下有哪几种dff我们可能会用得到:
1.是否需要复位
2.是否需要使能
3.是否需要校验
暂时排除第三种校验情况稍后再聊,根据前两个分类我们会得到以下的dff模块:
1.moon_dffre
2.moon_dffr
3.moon_dffe
4.moon_dff
这个前缀就是做一下标志随便加就可以。dff例化的风格怎么取代always时序呢,以下面这段代码为例:
1.能够规避不合理的代码习惯。最典型的就是时序逻辑中的clk_gating问题。想要综合工具自动插入门控的话,那么always块中就尽量不要有else分支(或者else分支是非阻塞赋值给自身),如果else中对信号赋常值了那么门控就插不进去,影响整个芯片的功耗。那么如果自己来写always块粗心大意了的话就可能出问题,且这个事完全靠个人意识了(当然工具可以查gating比例)。如果采用例化dff的方式,寄存器的实现方式就是统一的,只要dff模块写的合理那么无论如何调用都不会出这个问题。
2.便于X态检查。如同之前文章中所述的,if-else会掩盖X态问题,而如果我们希望对X态进行检查那么就可以统一在dff模块内来完成。
3.便于集中操作。假如某天突然有一个需求,要求所有的寄存器都加入校验逻辑,那么如果是always块怎么处理比较快速呢?需要把所有寄存器的值送入一个模块,然后连出一根error线。dff模块呢可以在模块内加入逻辑,例化时把error接出来||在一起。还是那句话,这两种方式难说好坏,dff例化型编码倒是可以从底层保证所有例化的寄存器都加入了校验逻辑(引出的工作还是得自己来的)。
4.便于全局替换。还是刚刚那个例子,加入校验逻辑,只需要全局把moon_dffre替换为moon_dffre_chk就可以了。
5.逻辑和互联更加清晰,更接近于底层电路实现对工具友好。同时我的习惯是用xx_d、xx_q、xx_en来命名信号,那么在写逻辑时,代码中用到了xx_q我就会非常放心因为这意味着该信号的时序极好,写习惯了对于时序路径的把握也有所提升。
6.有利于降低复位比例,利于功耗控制。dff例化风格编码时,组合逻辑和时序逻辑是分开写的,在每一个时序逻辑处都面临一个模块选型的问题,这个时候就需要分析这个寄存器是不是需要复位,如果不需要就选用moon_dffe型好了。而always块写法组合逻辑和时序逻辑是在一处写,精力很容易投在if-else的逻辑上,复位很多时候就顺手写了,后面还得艰难的降复位比例。
7.便于脚本工具集中处理,对,说的就是auto_dff哈哈。 最后一点,dff例化风格的代码天然的会分成信号声明、组合逻辑、时序逻辑三个部分,因此你可以选择这样组织代码:
//寄存器1 ...声明... ...逻辑... ...例化... //寄存器2 ...声明... ...逻辑... ...例化... 也可以很轻易的把三个区域分开:
...声明所有信号... ... ...例化所有寄存器... ... ...完成所有逻辑... ... 那么这个收益是什么呢?这样编码形式和风格容易写出美感,毕竟好看才是编码第一要务! 好的,dff编码风格的收益部分就写完了,接下来进行实操部分,各种dff模块应该怎么写呢?从最典型的moon_dffre写起吧。dffre顾名思义就是有复位有使能,内部根据使能进行赋值:
odulemodule moon_dffre #( parameter WD = 1, parameter VE = {WD{1'b0}}) ( input clk, input rst_n, input [DW -1:0]d, input en, output reg[DW -1:0]q ); always @(posedge clk or negedge rst_n)begin if(!rst_n) q <= VE; else if(en) q <= d; end endmodule 两个参数分别是寄存器的位宽和复位值。那么如果在模块内加入关于X态的校验,可以增加如下的代码(示意):
`ifdef ASSERT_ON property chk_en_xz(); @(posedge clk) disable iff(~rst_n) ~$isunknown(en); endproperty property chk_d_xz(); @(posedge clk) disable iff(~rst_n) en |-> ~$isunknown(d); endproperty assert_chk_en_xz: assert property(chk_en_xz()) else $assertoff(0, assert_chk_en_xz); assert_chk_d_xz: assert property(chk_d_xz()) else $assertoff(0, assert_chk_d_xz); `endif 这样一来,X态检查的问题就融在底层模块中了。顺着这个思路,另外几种dff的编码也很简单,moon_dffe:
module moon_dffe #( parameter WD = 1) ( input clk, input [DW -1:0]d, input en, output reg[DW -1:0]q ); always @(posedge clk)begin if(en) q <= d; end `ifdef ASSERT_ON property chk_en_xz(); @(posedge clk) disable iff(~rst_n) ~$isunknown(en); endproperty property chk_d_xz(); @(posedge clk) disable iff(~rst_n) en |-> ~$isunknown(d); endproperty assert_chk_en_xz: assert property(chk_en_xz()) else $assertoff(0, assert_chk_en_xz); assert_chk_d_xz: assert property(chk_d_xz()) else $assertoff(0, assert_chk_d_xz); `endif endmodule moon_dffr没有使能其实就没有必要检查什么X态的事了:
module moon_dffr #( parameter WD = 1, parameter VE = {WD{1'b0}}) ( input clk, input rst_n, input [DW -1:0]d, output reg[DW -1:0]q ); always @(posedge clk or negedge rst_n)begin q <= d; end endmodule 最最古朴的自然还是moon_dff:
module moon_dffr #( parameter WD = 1, parameter VE = {WD{1'b0}}) ( input clk, input rst_n, input [DW -1:0]d, output reg[DW -1:0]q ); always @(posedge clk)begin q <= d; end endmodule 基础版本的寄存器这四种就完全够用了。那么如果有需求在寄存器中加入校验,比如说加入奇偶校验,又该如何编码呢?这就需要一个单独的寄存器,当数据写入时同步写入校验位,之后每拍检查是否发生数据篡改:
编辑:黄飞
-
寄存器
+关注
关注
31文章
5336浏览量
120244 -
芯片设计
+关注
关注
15文章
1017浏览量
54880 -
RTL
+关注
关注
1文章
385浏览量
59763 -
代码
+关注
关注
30文章
4780浏览量
68535 -
时序逻辑
+关注
关注
0文章
39浏览量
9159
原文标题:IC设计笔记 | 论RTL中always语法的消失术
文章出处:【微信号:IC修真院,微信公众号:IC修真院】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
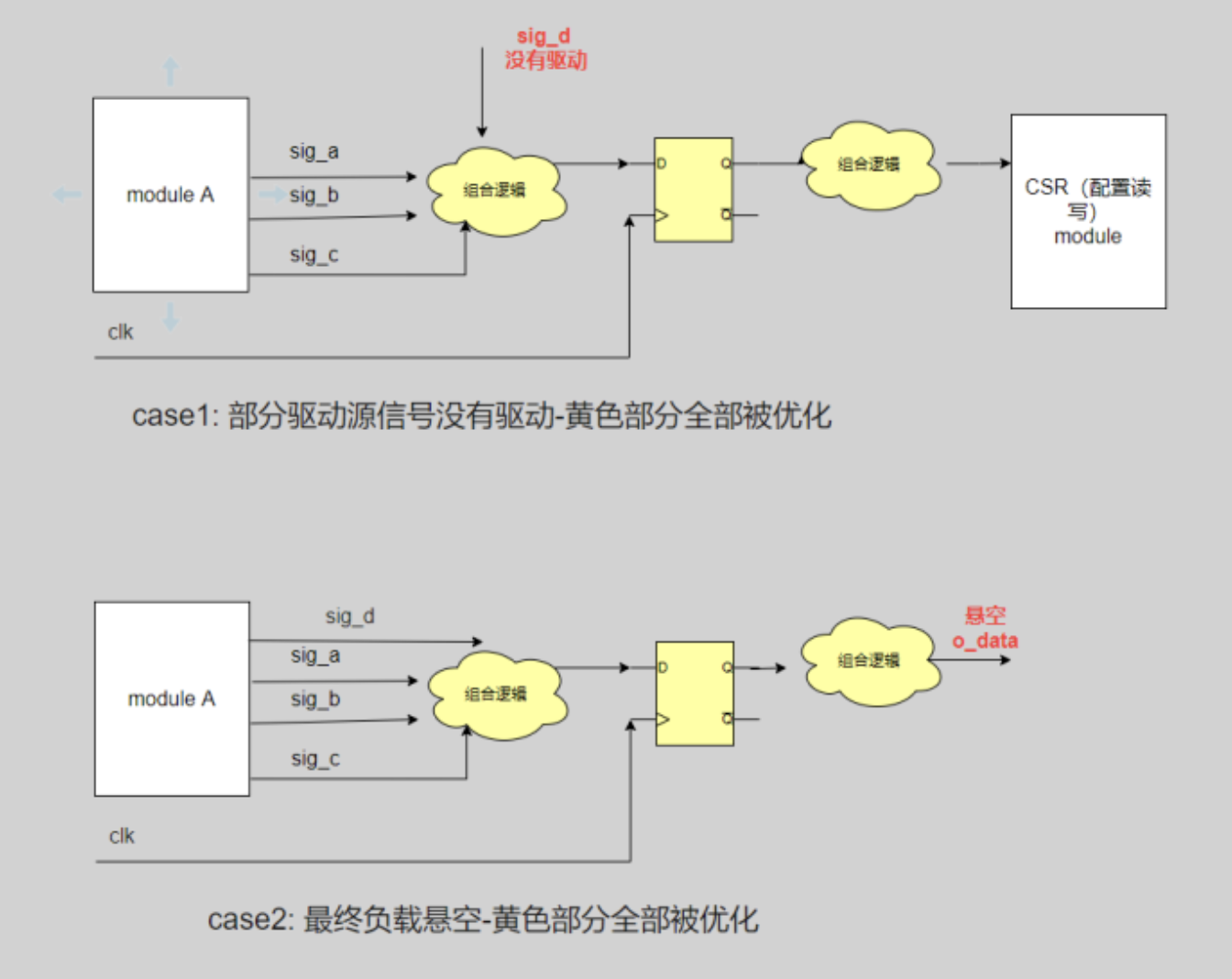
聊聊寄存器被优化的2种情况
有偿求助:RTL8365MB/RTL8363SB 寄存器问题
五个广泛使用的特殊寄存器
寄存器是什么 掌握使用寄存器做设计需要注意的事项





 工商网监
工商网监
评论