 【第20231110期嵌入式AI简报】OpenAI 如何再次让 AI 圈一夜未眠?
【第20231110期嵌入式AI简报】OpenAI 如何再次让 AI 圈一夜未眠?
嵌入式 AI
AI 简报 20231110期
1. 短短 45 分钟发布会,OpenAI 如何再次让 AI 圈一夜未眠
原文:https://www.geekpark.net/news/327126
对于 AI 行业从业者来说,刚刚可能是一夜未眠。
北京时间 11 月 7 日凌晨,美国人工智能公司 OpenAI 的开发者大会正式开启,创始人 Sam Altman 在台上和同事,只用 45 分钟时间,就「轰」出了团队最新的成果 GPT-4 Turbo,后者不仅更快、有更长的上下文、而且更好的控制。
同时,OpenAI 下调 API 的价格近 3 倍,降到了 1000 输入/美分,让在场开发者欢呼不已。
当然,更重要的是,OpenAI 推出了「GPTs」——让人们能用自然语言构建定制化 GPT,然后,你猜到了——可以把 GPT 上传到即将发布的「GPT Store」!
如果说 GPT-4 Turbo 是更好用的「iPhone」,GPT Store 则可能是让 OpenAI 成为「苹果」一样的巨头的重要一步。
当竞争对手们依然在「AI 炼丹」时,OpenAI 已经开始构建起一个看起来相当宏伟的生态了。
GPT-4 Turbo,更快,更省钱
发布会一开始,Sam Altman 就宣布了 GPT-4 的一次大升级,推出了 GPT-4 Turbo,同步在 ChatGPT 和 API 版本推出。
Sam Altman 表示团队一直在征求开发者的建议,对开发者关注的问题做了六大升级,分别是更长的上下文长度、更强的控制、模型的知识升级、多模态、模型微调定制和更高的速率限制。
其中前四条主要关于新模型的性能的提升,而后两点则主要针对企业开发者的痛点。在提升性能的同时,OpenAI 还宣布了 API 价格的下调,可谓「加量不加价」了。

六大升级中,第一,就是上下文长度。
OpenAI 原本提供的最长的上下文长度为 32k,而此次,GPT-4 Turbo 直接将上下文长度提升至 128k,一举超过了竞争对手 Anthropic 的 100k 上下文长度。
128k 的上下文大概是什么概念?大概约等于 300 页标准大小的书所涵盖的文字量。除了能够容纳更长上下文外,Sam 还表示,新模型还能够在更长的上下文中,保持更连贯和准确。
第二,是为开发者提供了几项更强的控制手段,以更好地进行 API 和函数调用。
首先,新模型提供了一个 JSON Mode,可以保证模型以特定 JSON 方式提供回答,调用 API 时也更加方便。
另外,新模型还允许同时调用多个函数,同时引入了 seed parameter,在需要的时候,可以确保模型能够返回固定输出。接下来几周,模型还将增加新功能,让开发者能看到 log probs。
第三,则是模型内部和外部知识库的升级。
ChatGPT 横空出世大概一年后,GPT 的知识库终于更新到了 2023 年 4 月。Sam Altman 承诺未来还将继续更新其知识库,不使其落伍。「对于 GPT 的知识停留在 2021 年,我们和你们一样,甚至比你们更恼火。」Sam Altman 表示。

除了内部知识库的升级,GPT-4 Turbo 也升级了外部知识库的更新方式,现在可以上传外部数据库或文件,来为 GPT-4 Turbo 提供外部知识库的支持。
第四,或许是最不让人意外的,多模态。
新模型支持了 OpenAI 的视觉模型 DALL·E 3,还支持了新的文本到语音模型——开发者可以从六种预设声音中选择所需的声音。

GPT-4 Turbo 现在可以以图生图了。同时,在图像问题上,目前 OpenAI 推出了防止滥用的安全系统。OpenAI 还表示,它将为所有客户提供牵涉到的版权问题的法律费用。
在语音系统中,OpenAI 表示,目前的语音模型远超市场上的同类,并宣布了开源语音识别模型 Whisper V3。
第五,模型微调与定制。
8 月,OpenAI 曾经发布过 GPT-3.5 Turbo 的微调服务。当时,有早期测试表明,经过微调的 GPT-3.5 Turbo 版本在某些任务中甚至可以超越 GPT-4,不过定价相对较高。
而此次,Sam 宣布 GPT-3.5 Turbo 16k 的版本目前也可以进行微调的定制了,且价格将比前一代更低。GPT-4 的微调定制也在申请中了。
同时,OpenAI 也开始接受单个企业的模型定制了。「包括修改模型训练过程的每一步,进行额外的特定领域的预训练,针对特定领域的后训练等等。」Sam 表示。同时他表示,OpenAI 没有办法做很多这样的模型定制,而且价格不会便宜。
第六,也是最后一点,是更高的速率限制。
GPT-4 用户,发布会后马上可以享受到每分钟的速率限制翻倍的体验。同时,如果不够满意,还可以进一步通过 API 账户,申请进一步提升速率限制。
六大升级以外,是 API 体系的全线降价。
此次新发布的 GPT-4 Turbo,输入方面比 GPT-4 降价 3 倍,而输出方面降价 2 倍,OpenAI 表示,总体使用上降价大概 2.75 倍。
新模型的价格是每千输入 token 1 美分,而每千输出 token 3 美分。降价的 API 迎来了现场开发者的欢呼。
Sam 还表示,在优先解决价格之后,下一个重点解决的问题将是速度问题,很快,开发者们就会发现 GPT-4 Turbo 将变快很多。
GPT Store 来了!
早在 5 月,OpenAI 就开放了插件系统,首批上线了 70 个大模型相关的应用,领域包括猜词、翻译、查找股票数据等等。
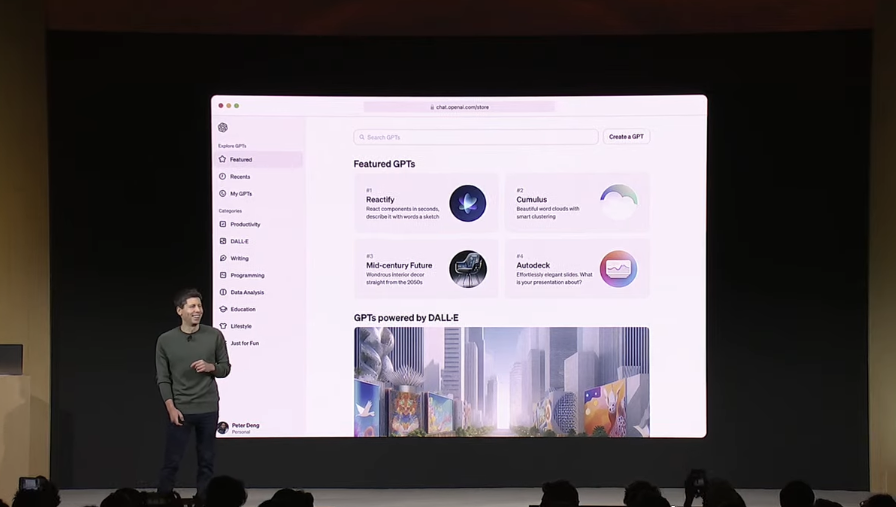
当时,该功能被寄予厚望,不少媒体将其类比于苹果的 App Store 时刻,认为它将改变大模型应用的生态。不过虽然后期插件不断增加,但插件系统却远远没有达到苹果应用商店的影响力。
而此次发布会上,OpenAI 则重新梳理了其应用商店的体系,并将其扩大到了一个全新的范畴——人人都能通过自然语言创建基于自己的知识库的 AI Agent,加入 OpenAI 的应用商店,并获得分成。
OpenAI 此次发布的应用,不再称为插件,而选择了一个相对比较奇怪的名字,GPT。而整体的应用商店,名字叫做 GPT Store,将在本月后期正式推出。
按照 Sam Altman 的说法,每一个 GPT 像是 ChatGPT 的一个为了特殊目的而做出的定制版本。
为了突出新的 GPT 应用,ChatGPT 整个页面将有小幅度的调整。左上角除了 ChatGPT,下面的应用,就是此次推出的 GPT 应用。
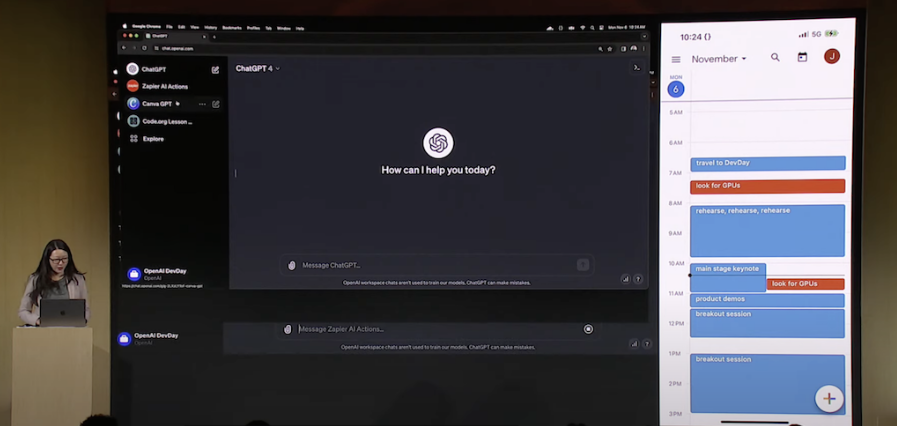
在演示中,可以看到,较为复杂的插件——比如曾经在 OpenAI 上线插件系统时第一批进入插件系统的 Zapier,仍然存在于目前的应用商店中,而且仍然可能是未来应用商店里很重要的一批应用。
演示中,OpenAI 的 Jessica Shay,就利用了 Zapier 链接了自己的日历和手机短信,通过与 Zapier 这个应用聊天的方式,直接安排了自己的日程,并通知了同事。
不过,Zapier 的功能虽然强大,这样的应用并不是此次发布的重点。据 Glassdoor 数据显示,Zapier 公司拥有 500-1000 名员工,而财富网站报道,Zapier 估值已达 50 亿美金。指望这样的应用来填充 OpenAI 的羽翼未丰的应用商店,使其成为一个丰富的生态显然不太现实。
因此,此次发布中,OpenAI 推出一个重磅发布:让不懂代码的人也能轻松定义一个 GPT。
Sam Altman 为此进行了现场展示。
「在 YC 工作过很多年,我总是遇到开发者向我咨询商业意见。」Sam Altman 讲到,「我一直想,如果有一天有个机器人能帮我回答这些问题就好了。」
接着,Sam Altman 打开了 GPT Builder,先打上一段对这个 GPT 的定义,类似于帮助初创公司的创始人思考他们的业务创意并获得建议,接着,在对话中,GPT Builder 自己生成了这个 GPT 的名字、图标,并通过与 Sam 对话的形式,询问 Sam 是否要对对生成的名字和图标等进行调整。
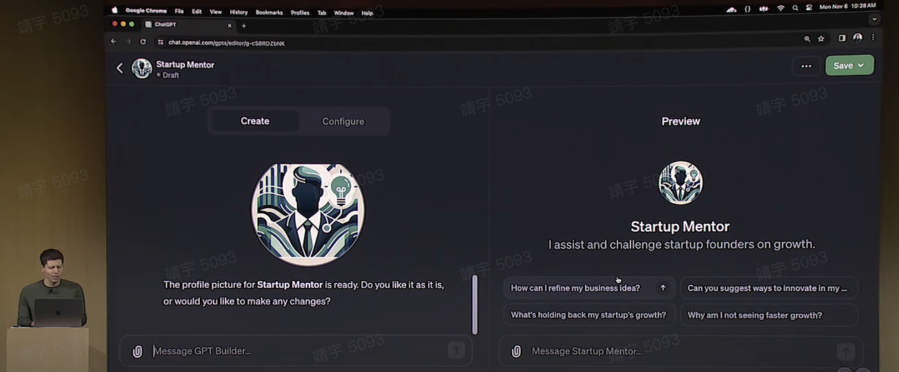
接下来,GPT Builder 主动向他询问这个应用该如何与用户交互,Sam 表示可以从我的过往演讲中选择合适且有建设性的回答,然后上传了一段自己过往的演讲。
即使加上讲解,整个应用也在三分钟内就完成了。访问这个 GPT 的人,会收到 GPT 自动生成的对话开头,可以与这个 GPT 对话咨询创业相关的内容,而得到的,将是一个类似于 Sam Altman 本人的回答。
Sam 表示,创建者还可以进一步为 GPT 增加 action(动作)。
创建一个这样的 GPT,本质上,用户能够定制的功能其实并不多:指令(预设的 prompt),外设的知识库和动作。但是,能把三者丝滑地结合起来,让一个不懂代码的人也能更简单地创建应用,确实是此次 Open AI 的创举。
GPT 发布后,应用可以选择私有,专属企业拥有和公开所有三种方式。而 Open AI 表示,将为受欢迎的应用提供利润分享。
很明显,OpenAI 在这里的发布,并没有希望普通用户能够通过自然语言创建出多么复杂的应用,其中的想象空间,更重要的在于个人和企业能够将自己的知识库上传到 OpenAI,一键构建专属应用。
比如作为一个拥有货运价格表的代理,可以将文件上传到 OpenAI 后,一键部署出自己的询价助理,这样简洁丝滑的应用部署,在之前还并不存在。而如果发布最终能够得到用户认可的话,类似的应用也将能够填充 OpenAI 的应用商店,使其成为各种信息的宝库。
零代码创建 AI Agent
如果你觉得上述的 0 代码的 GPT 很酷,此次 OpenAI 也推出了让开发者更容易使用 OpenAI API 的开发方式——Assistants API。
Sam Altman 表示,市面上基于 API 构建 agent 的体验很棒。比如,Shopify 的 Sidekick 可以让用户在平台上采取行动,Discord 的 Clyde 可以让管理员帮忙创建自定义人物,Snap 的 My AI 是一个自定义聊天机器人,可以添加到群聊中并提出建议。
但问题是,这些 agent 很难建立。有时需要几个月的时间,由数十名工程师组成的团队,处理很多事情才能使这种定制助手体验。这些事情包括状态管理(state management)、提示和上下文管理(prompt and context management)、扩展功能(extend capabilities)和检索(retrievel)。
在 OpenAI 开发者大会上,这些事情被 API 化——OpenAI 推出 Assistants API,让开发人员在他们的应用程序中构建「助手」。
使用 Assistants API,OpenAI 客户可以构建一个具有特定指令、利用外部知识并可以调用 OpenAI 生成式 AI 模型和工具来执行任务的「助手」。像这样的案例范围包含,从基于自然语言的数据分析应用程序到编码助手,甚至是人工智能驱动的假期规划器。
Assistants API 封装的能力包括:
持久的线程(persistent threads),人们不必弄清楚如何处理长的对话历史;
内置的检索(Retrieval),利用来自 OpenAI 模型外部的知识(例如公司员工提供的产品信息或文档)来增强开发人员创建的助手;提供新的 Stateful API 管理上下文;
内置的代码解释器(Code Interpreter),可在沙盒执行环境中编写和运行 Python 代码。这一功能于 3 月份针对 ChatGPT 推出,可以生成图形和图表并处理文件,让使用 Assistants API 创建的助手迭代运行代码来解决代码和数学问题;
改进的函数调用,使助手能够调用开发人员定义的编程函数并将响应合并到他们的消息中。
Assistants API 处于测试阶段,从今天开始可供所有开发人员使用。开发者可以前往 Assistants Playground 来尝试 Assistants API 测试版,而无需编写任何代码。
Assistants API 被 OpenAI 视为帮助开发者在其应用程序中构建「类 agent 体验」的第一步。有了 Assistants API,构建 agent 应用将变得更容易。OpenAI 表示,随着时间的推移,将会持续提高它们的能力。并且,未来计划允许客户提供自己的 copilot 工具,以补充其平台上的 Code Interpreter、检索组件和函数调用。
OpenAI 开发者大会上的产品升级,再次告诉人们,距离每个人都能有一个甚至多个专属私人助理、使用自然语言就能开发软件、还能像浏览应用一样,付费/免费购买流行的私人助理,这样的一个未来,正在加速向人们走来。
从 GPT-4 到 GPT-4 Turbo 和 GPT Store,OpenAI 只用了半年多一点的时间。而在 6 个月之内,全球的科技和 AI 行业,已经是天上人间。
当多模态、长文本输入、更便宜、个性化……这些旨在和 OpenAI 大模型错位竞争的特点,都被 OpenAI 抢先拿来自我革命;当 OpenAI 的产品在 B 端和 C 端都体现出强大的吸引力、并且还将利用 GPT Store 率先笼络住全球AI 开发者时,不知道全球的 AI 对手们的心情如何。
但 OpenAI 的技术进步是令人兴奋的,而团队所采用的商业策略,又有着超出一般创业公司的成熟——我们目睹着一个行业的潮起,也可能正在见证一个巨头的诞生。
2. 联发科翻身,同蓝厂联合研发「全大核」体系,vivo X100稳了
原文:https://mp.weixin.qq.com/s/RI1FYzmh7hcFnB5Dor5Eng
11月6号,联发科的旗舰芯片天玑 9300 正式亮相,一举完成了连续超车:性能超过高通和苹果,站上了本世代移动芯片的顶端。

据介绍,天玑 9300 的 CPU、GPU 性能均超过了竞品,另外能耗还有所降低,又率先实现了 70 亿大语言模型在手机端侧的落地。
与此同时,搭载顶级芯片的新手机也将开卖。在发布会上,vivo 第一时间宣布即将发布的年度旗舰机 vivo X100 系列将首发搭载天玑 9300,新机型与芯片进行了深度的定制化,发布会下周就开。
「我们认为在移动端,CPU 的使用方式将从低速持续转变为快速集中的方式,」联发科活动中,vivo 高级副总裁施玉坚表示:「在 vivo 与联发科共同探索下,新的全大核架构可以快速完成任务,快速休眠,大幅降低功耗,做到冷静低耗。」

看起来,连续两年国内份额排名第一的蓝厂,也对这块芯片信心满满。
只用大核,性能超出预期
在手机 SoC 领域,今年安卓阵营正在全面超越苹果,作为重要一极的天玑也是玩出了狠活。
昨天正式发布的天玑 9300 在性能和功耗比上均实现了领先。这颗芯片的 CPU 部分使用了 4 颗 Cortex-X4 超大核与 4 颗 Cortex-A720 大核的设计,其中超大核频率是 3.25GHz,大核 A720 的频率是 2.0GHz。据联发科介绍,「全大核」的设计从理念上领先于竞品。相比上代,天玑 9300 峰值性能提升 40%,同性能的功耗则减少了 33%。
联发科表示,全大核设计加上乱序执行(out-of-order)机制,在工作过程中可以快速处理任务,让芯片在更长的时间内处于待机状态,既提升了速度也降低了功耗。这种做法将会成为未来旗舰手机芯片的趋势。
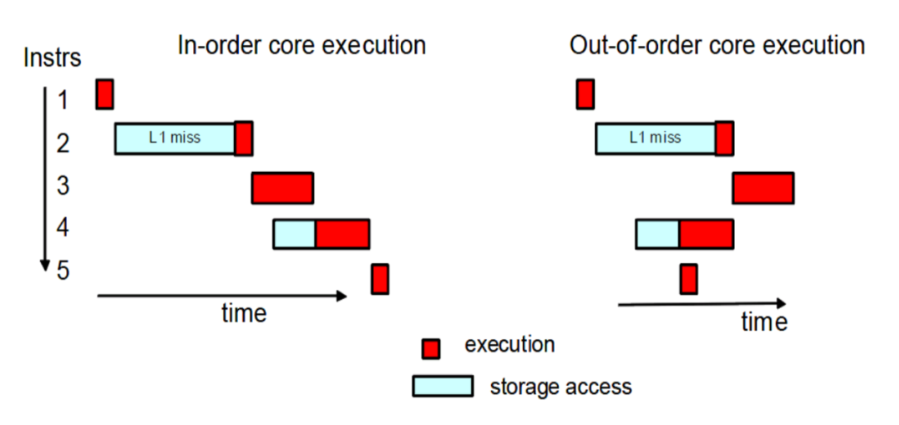
而在游戏等重负载任务关注的图形处理能力上,与上代相比,天玑 9300 的峰值性能提升了 46%,相同性能下功耗可节省 40%。该芯片搭载的 GPU Immortalis-G720 引入了延迟顶点着色(DVS)技术,这是一种可以减少内存访问和带宽使用的方法,可以大幅节省功耗和提高帧率。
在 AI 性能方面,天玑 9300 的新一代 APU 内置了硬件级的生成式 AI 引擎,首次实现行业最高的 70 亿 AI 大语言模型以及 10 亿 AI 视觉大模型在手机上的落地,可带来端侧的 AI 画图、大模型推理等能力。
如果看跑分的话,天玑 9300 处于目前安卓处理器性能第一的位置。在 Geekbench 上,X100 的分数与骁龙竞品非常接近,多核分数更高一些。
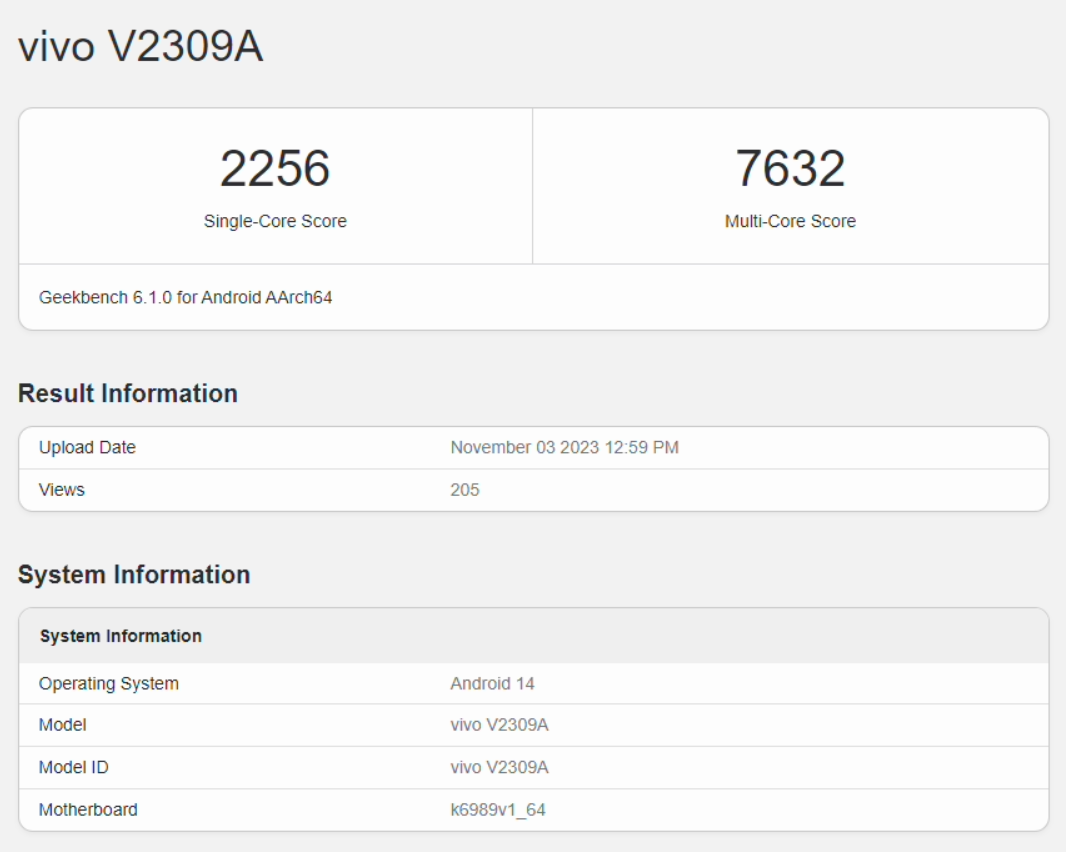
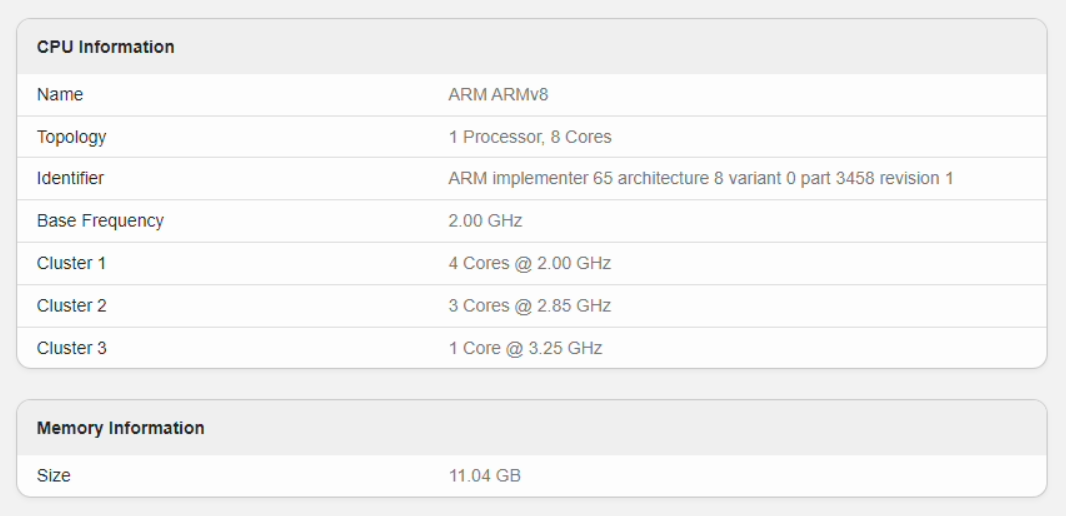
除此以外,不论是 CPU 多核性能还是 GPU 性能,天玑 9300 都超过了苹果 A17 Pro 芯片。很多媒体第一时间发布的评测中,都给出了「超出预期」的评价。
总而言之,天玑 9300 可以在日常使用、游戏和拍摄众多场景上以更快的速度、实现更好的效果,同时功耗还不会更高。这让人不得不感叹:安卓的性能真的变天了?

有趣的是,不论是在此前的技术展示,还是昨天的发布会上,联发科均表示基于天玑 9300 芯片,vivo 与其进行了深度合作与联调。至此,有关即将发售的 vivo X100 系列,我们已知的消息有:它将引入天玑 9300、vivo 6nm 自研影像芯片 V3、LPDDR5T 运存、UFS 4.0 闪存、全系使用潜望长焦镜头、1.5K 曲面屏,还有蓝海电池等配置。

强大的芯片,再加上全方位的升级。下星期才发布的 X100 系列,可以说已经剧透了大部分配置。
联动 V3 芯片,首次实现 4K 视频拍摄 + 编辑
当然,不论还有哪些未透露的黑科技,vivo 新旗舰机的目标都非常明确:要确立高端影像旗舰的标杆。
最近几年,X 系列已经通过独立芯片把拍照能力卷成了蓝厂的招牌。在 vivo X100 系列上,vivo 还要更进一步,即将搭载的是新一代自研影像芯片 V3。
这款芯片在今年 7 月首次被公布,它采用 6nm 制程工艺打造,能效比相比上代提升了 30%,通过与手机 SoC 高速联通,V3 的影像处理耗时相较上代缩短了 20%。

V3 芯片的出现,让移动影像领域此前一些「不可能」成为可能。比如配合蔡司镜头和 T* 镀膜防眩光技术,让手机可以直接拍摄太阳,同时解决色差和眩光问题,获得漂亮的成片。
从技术层面上看,V3 能够实现此前传统算法难以达到的「4K 电影级视频拍摄」和「拍后编辑」能力。其中 4K 电影人像视频可以实现类似电影效果的实时背景虚化、HDR、降噪等功能,对于画面主体也可以实现自动焦点检测和切换,同时可以对皮肤和色彩进行「电影级」优化处理。
4K 级拍后编辑则可以让用户先拍摄,然后在相册中无损调整画面中的虚化和焦点位置,实现更好的切焦运镜效果。
以上这些都是安卓平台上,首次有手机能够实现的功能。
X100 的影像能力,与芯片的联合调教是分不开的。在 vivo 与联发科针对天玑 9300 和 V3 芯片的联动,设计了全新的多并发 AI 感知 ISP 架构和第二代 FIT 互联系统,可以降低功耗,并显著提升算法效果。此外,两块芯片能够灵活切换算法部署方式,做到独立芯片和 SoC 的无缝衔接。
可以说,V3 加上天玑 9300,两颗芯片能够跑出更多马力,在各种场景下都可以满足复杂人机交互的需求。

从 vivo 此前一些活动中公布的信息可知,即将发布的 vivo X100 系列将会在影像方面迎来重大升级,该系列新机将会在新一代处理器的加持下,配备 vivo 自研 V3 影像芯片,搭载全新的大底主摄以及「Vario-Apo-Sonnar」长焦镜头,以及全新的蔡司 T * 镀膜技术。两块芯片与新一代光学元器件的配合,将为用户带来出众的全焦段影像体验。
我们知道,国内外的手机大厂多年以来都在不断发力移动摄影,但 vivo 这样从镜片开始,深入芯片再到 AI 算法全面加码的,可谓独树一帜。
「蓝晶芯片技术栈」上线,以后更得看蓝厂
近四年来,vivo X 系列旗舰手机的稳定表现让人们已经逐渐形成了「天玑调教看蓝厂」的印象。自从 vivo X80 系列开启与天玑平台首次合作以来,X 系列的名头变得越来越响,天玑芯片也在朝着最强处理器的目标一步步迈进。
可以说,这几年蓝厂的步子走的又快又稳,而且还准。
vivo 的创新理念是回归本原思考。在芯片方面,其致力于面向高频使用场景进行创新,高强度不设限地自研影像芯片,在 SoC 上则选择与芯片厂商展开深度合作。
vivo 与联发科是战略级技术合作伙伴,它们之间的合作可以从四年前成立联合实验室说起。如今,联合实验室的研究范围已经覆盖了 AI、功耗、性能、游戏、现实、通信、存储 8 大赛道,以及很多面向全行业的先进技术。
这种长期的合作已经带来了肉眼可见的成果:在 vivo X80 系列中,vivo 与天玑平台首次进行了自研芯片的调通。双方共投入 300 人,经过 350 天研发周期大幅革新了软件通路架构,将 V1+ 芯片与天玑 9000 调通,使 vivo X80 系列成为了「表现最好的天玑 9000 旗舰」。
通过双芯技术和对软硬件架构的优化,X80 系列在影像方面带来了微光手机「夜视仪」、实时黑光夜视 2.0 和极夜视频,游戏方面也实现了超分辨率、独显超清、双芯超帧以及低功耗等特性。
在去年底发布的 vivo X90 系列上,vivo 在天玑 9200 旗舰平台的研发阶段早期介入,通过与联发科长达 20 个月的密切合作,带来了 MCQ 多循环队列、MAGT 自适应画质、芯片护眼、APU 框架融合与 AI 机场模式等五大联合研发技术。在游戏上提出了 vivo 专属游戏调校、OriginOS 3 流畅智算中枢和旗舰影像体验三大联合调校。
vivo 与联发科的合作,是基于用户需求从芯片设计层面上开始的改进,真正深入了芯片底层,充分发挥了天玑芯片的潜力。随着近年来在芯片技术的沉淀,vivo 已初步具备了面向行业需求定义芯片的能力。
X100 上的天玑 9300,已是 vivo 与联发科在旗舰手机 SoC 上的第三代合作。这一次,vivo 的「造芯能力」上升到了新的高度 —— 昨天,vivo 还介绍了「蓝晶芯片技术栈」。

在 vivo X100 系列产品上,大家将看到 vivo 在 SoC 芯片上的优化能力,从芯片核心赛道的联合调优,到深入底层 ARM 指令集调用架构突破 GPU 带宽瓶颈,vivo 正在以芯片设计者、引领者、实践者的身份,拓宽技术发展的边界。
没错,vivo 现在一定程度上已是引领者了,比如在天玑 9300 的全大核设计上。
据介绍,早在三年前,vivo 就与联发科开始共同探索全大核架构设计的构想。随着制程发展进入瓶颈期,大小核的功耗差距会变得不再明显,想让芯片更加省电,我们要更看重调度能力。因此,确定关键性进程后,快速处理完任务再休息的方式,不仅能让芯片处理任务的速度更快,还能让大核比小核更省能耗。或许在明年,其他芯片厂商就会陆续跟进这种思路。
而对于我们来说,算力充分释放,可以期待的体验自然就好了起来。在社交网络上,有着天玑 9300、V3 芯片和蓝晶芯片技术栈加持的 X100 系列,已经被冠上了「机圈灭霸」的名号。
11 月 13 日,vivo 今年的旗舰机型 X100 系列将正式在北京水立方发布。这款新机,我们还有哪些期待?
3. 重磅!百度知识增强大语言模型关键技术荣获“2023世界互联网大会领先科技奖”
原文:https://mp.weixin.qq.com/s/9TqP7yrxL8UbGQvvtabJ0Q
11月8日,2023年世界互联网大会乌镇峰会正式开幕,今年是乌镇峰会举办的第十年,本次峰会的主题为“建设包容、普惠、有韧性的数字世界——携手构建网络空间命运共同体”。百度知识增强大语言模型关键技术荣获“世界互联网大会领先科技奖”,百度首席技术官、深度学习技术及应用国家工程研究中心主任王海峰现场发布了文心大模型的关键技术成果。

世界互联网领先科技成果是由世界互联网大会组织发布的,面向全球广泛征集前沿科技申报成果,通过评审评出具有国际代表性的年度领先科技成果。世界互联网领先科技成果发布活动自2016年起连续举办,旨在引领科技前沿创新,倡导技术交流合作,对世界互联网科技发展发挥了积极影响。今年,这一活动全面升级为世界互联网大会领先科技奖,并首次分为关键技术、基础研究、工程研发三类,面向全球表彰年度领先互联网科技成果。
本次大会共计征集到来自中国、美国、俄罗斯、英国、德国等国家的领先科技成果246项,涵盖人工智能、大数据、5G、车联网等领域,经过40名海内外专家评审,百度知识增强大语言模型关键技术成为唯一获奖的大模型技术,这也是继百度大脑、小度助手(DuerOS)、Apollo、飞桨之后,百度在世界互联网大会乌镇峰会第五次获此荣誉。
王海峰发布知识增强大语言模型领先科技成果时表示,“人工智能正在引领新一轮科技革命和产业变革,大语言模型让人们看到了通用人工智能的曙光。知识增强大语言模型关键技术,突破知识内化和外用技术,具备知识增强、检索增强和对话增强的独有技术优势,并通过模型与框架联合优化,突破了训练规模,提高了训练效率,提升了模型效果。”
百度在今年3月16日发布新一代知识增强大语言模型文心一言,目前其基础模型已迭代到文心大模型4.0版本。文心大模型和飞桨深度学习平台联合优化,快速迭代升级,训练效率提升到3月发布时的 3.6 倍,推理提升 50 多倍。
公开资料显示,百度知识增强大语言模型相关技术曾获国家技术发明二等奖、中国专利金奖、吴文俊人工智能科技进步特等奖、中国电子学会科技进步一等奖等。技术成果应用于智能搜索、通用对话等,并成功实践“集约化生产,平台化应用”的产业模式,与合作伙伴联合研制10余个行业大模型,助力产业智能化升级。
据了解,8月31日文心一言面向全社会开放至今,用户规模已经达到7000万,场景4300个。
4. 马斯克旗下 AI 公司推出 PromptIDE 工具
原文:https://www.oschina.net/news/265374
马斯克旗下 AI 公司 xAI 宣布推出 PromptIDE 工具,需要使用 X 账户登录。
https://x.ai/prompt-ide/
PromptIDE 是一个用于提示工程和可解释性研究的集成开发环境。它通过 SDK 加速提示工程,该 SDK 允许实现复杂的提示技术和丰富的分析功能,从而实现网络输出可视化。
IDE 的核心是一个 Python 代码编辑器,它可以与新的 SDK 结合实现复杂的提示。在 IDE 中执行提示时,用户会看到一些有用的分析和建议,例如精确标记化等等。
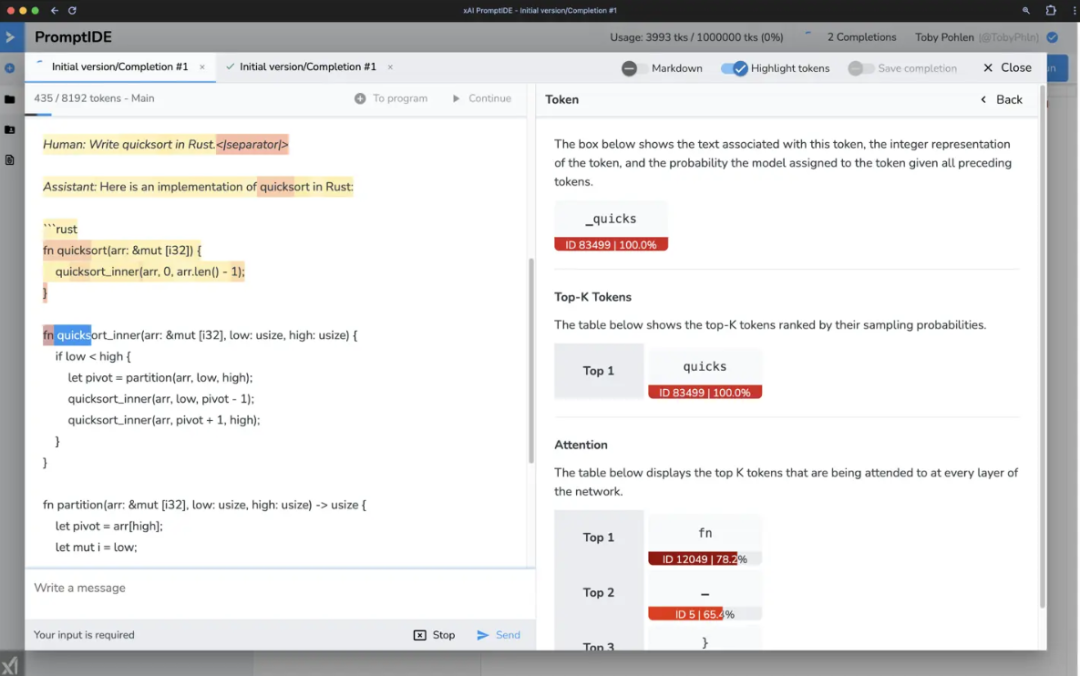
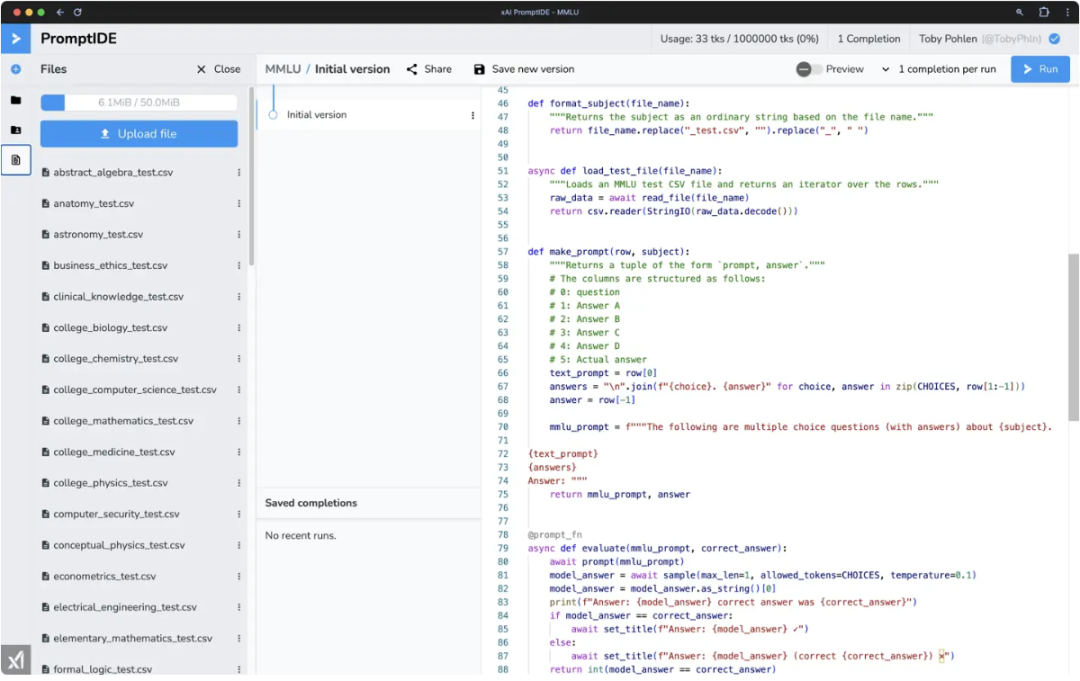
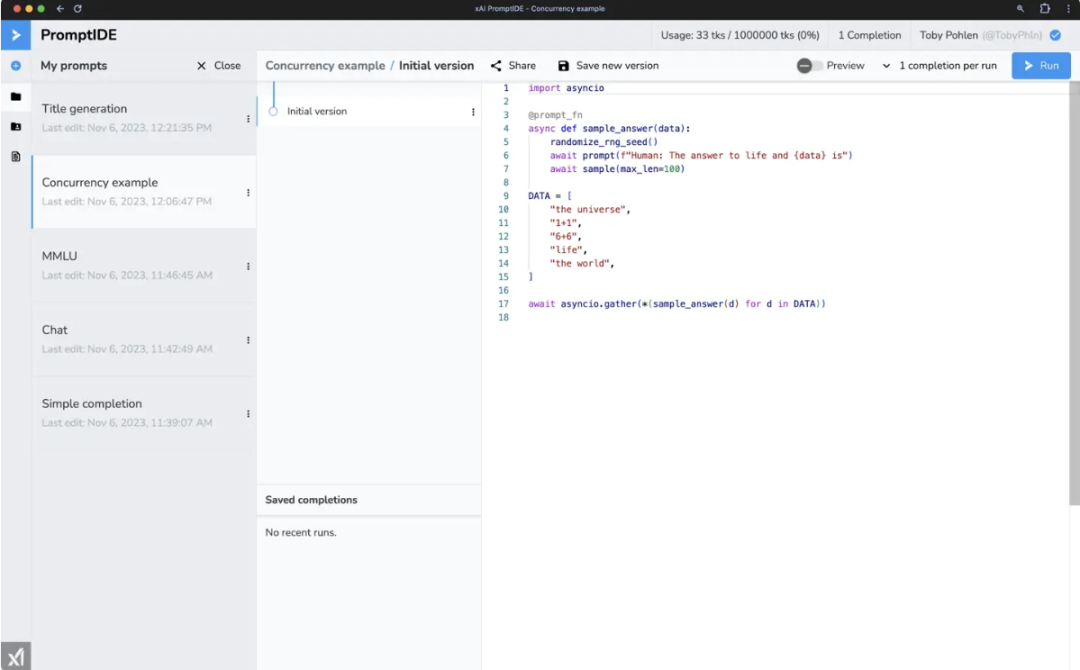
xAI 官方表示,他们开发 PromptIDE 是为了向社区的工程师和研究人员透明地提供 Grok-1 的透明访问权限。该 IDE 旨在赋予用户权力,帮助他们快速探索大型语言模型(LLMs)的魅力。
5. 阿里巴巴即将开源国内规模最大的 AI 大模型,720 亿参数
原文:https://www.ithome.com/0/731/189.htm
IT之家 11 月 9 日消息,阿里巴巴集团 CEO 吴泳铭今日在 2023 年世界互联网大会乌镇峰会上透露,阿里巴巴即将开源 720 亿参数大模型,这将是国内参数规模最大的开源大模型。
IT之家查询获悉,阿里巴巴目前已经开源通义千问 140 亿参数模型 Qwen-14B 和 70 亿参数模型 Qwen-7B,而 720 亿确实是目前国内开源大模型的参数新高。
吴泳铭昨日还在 2023 年世界互联网大会乌镇峰会上表示,AI 时代,阿里巴巴要成为一家服务全社会 AI 创新的、开放的科技平台企业。
“回望这 20 年,我们打造了覆盖交易、物流、支付、生产等环节的数字商业基础服务,为电商行业发展提供了有力支撑。而随着 AI 成为中国数字经济创新突破的关键,阿里巴巴要做一家开放的科技平台企业,为千行百业的 AI 创新和转型提供基础设施。”吴泳铭说。

6. 联想首推大模型解决方案及服务 加速推动企业级应用落地
原文:http://finance.people.com.cn/n1/2023/1110/c1004-40115499.html
11月9日,在乌镇举办的2023世界互联网大会算力网络协同创新分论坛上,联想集团副总裁、中国区方案服务业务总经理戴炜以“算力时代一切皆服务”为主题进行演讲,并首次对外推出联想企业大模型服务。旨在以智算服务为基础,通过AI平台部署进行推理加速、分布式训练&微调,帮助实现私有化大模型部署,全面赋能企业的业务系统,帮助客户实现 AI转型。
戴炜表示,“随着人工智能技术的快速发展,算力网络未来的发展方向将专注于实现大模型及人工智能在行业和企业中的实际落地和体现其业务价值。”
此次,联想首次对外推出了企业专属的私有化大模型解决方案及服务。该服务是联想基于智能算力和AI大模型技术的全新方案服务,可以有效解决企业自建大模型进程中对算力扩展、数据安全以及部署与运维等诸多个性化需求。
戴炜表示,企业大模型服务的优势在于可以帮助企业构建私有化的一体化大模型平台,一站式交付,安全可控,基于领域知识的高效微调,打造专属企业大脑。
而联想推出的企业专属的私有化大模型解决方案及服务,依托于一站式端到端的解决方案与陪伴式服务,让更多的企业也能快速享有大模型的能力同时,不必考虑具体的部署细节,能够把更多精力放在自身业务发展中。真正帮专注于探索大模型应用的企业更加经济地、高效地实现大模型应用的落地。
作为一场引领数字技术创新趋势的全球行业盛会,本次2023世界互联网大会吸引了中国ICT领域的诸多头部企业,包括以云网业务为核心的三大运营商,拥有全栈智能布局(包括AI内嵌的智能终端、AI导向的基础设施、AI原生的方案服务)的联想集团以及一家基础设施和智能终端提供商。
据IDC的最新数据显示,在IDC2022自然年对中国IT服务市场(非运营商)的排名中,联想方案服务业务夺得市场第二,正式迈入中国IT服务市场的头部核心梯队。联想正凭借AI原生的方案与服务,持续赋能中国企业智能化转型,以实赋实,最终与合作伙伴一起加速推动实现中国数实融合新图景。
算力五年复合增长率达52.3%,企业抢滩大模型建设
从ChatGPT横空出世,到国内外厂商纷纷入局大模型“百舸争流”,仅用了一年时间。
关于各类生成式人工智能大模型的讨论,已经从互联网、科技领域的局内人,蔓延至全社会的各行各业。由大模型引发的创新浪潮,正在不断“涌现”。
最新数据显示,目前我国有至少130家公司研究大模型产品,其中通用大模型有78家。如今,科大讯飞的“星火”、腾讯的“混元”、百度的“文心一言”、百川智能等国产大模型开始陆续出实验室,面向公众进行开放测试。
伴随大模型应用的不断推出,国内对于智能算力的需求也将持续扩大。据IDC数据显示,中国智能算力规模将持续高速增长,未来五年复合增长率达52.3%。
对于大众而言,可以对话、写诗、作画,甚至是写文章、编代码的AI大模型应用开始变得更加亲切和具体。但对于业内人士而言,大模型已经成为当前人工智能、乃至新一轮科技革命与产业变革的核心驱动力,成为各大国争相抢占的科技制高点。
历经数十年的发展,人工智能正在逐步从感知智能向认知智能转化。掌握AI大模型工具,就是掌握了未来的生产力。
中国工程院院士、中国互联网协会咨询委员会主任邬贺铨指出,“多数行业的大企业没有自行开发大模型的能力,而互联网大企业和科研机构的大模型不了解行业,因此难以直接应用到行业中。为解决以上困境,现在的一种趋势是,互联网企业和科研企业开发大模型与行业合作,加上行业和企业自身数据,再在原有基础大模型上针对应用场景进行调优、量化、场景迁移等,帮助模型适应行业需要,变成一种小模型。”
企业正在转变思路,从大模型的消费者变成共同的创造者,深入探索产业价值。联想大模型服务的推出可以帮助正在探索大模型应用的企业抢占私有化大模型建设的先机,不断深耕自身所在领域的专精数据与经验积累,构建自身竞争力、形成智能、高效、可自行迭代的企业大脑。
联想推出大模型服务,助力企业抢跑下一轮智能化变革
自建企业大模型已经大势所趋,但在实践过程中仍存在算力扩展、数据安全以及部署与运维的诸多难题。因此,B端企业客户需要一个懂行业know—how、能帮助解决业务问题、真正赋能产业升级的大模型解决方案及服务商。
为帮助正在探索大模型应用的企业解决上述后顾之忧,联想首次推出的企业专属的私有化大模型解决方案及服务,通过强大的智能算力平台、工具和服务为企业智能化转型提供了坚实保障,更好地实现大模型在企业的落地。
在智能算力服务方面,不论是需要从0—1自建大模型的集团企业,还是选择一个经过预训练的大模型作为基础并进行指令微调以满足特定需求的中小企业,这些企业都需要能构造一个可扩展、能持续演进的算力发展架构。因此,联想为客户建设了以 AI计算虚拟化、GPU集群调度、异构计算等能力为核心的智算中心,可以满足客户对算力的个性化需求。
不仅如此,联想还提供全方位的联想智算中心解决方案和服务产品,包括了三大类解决方案:联想大脑嵌入的解决方案、联想混合云解决方案、联想绿色低碳智算中心基础设施;两大类服务,端到端全周期联想智算中心服务;按需订阅、灵活付费的联想臻算服务2.0。
在数据安全保障方面,为打造适合自己的专属大模型,企业需要使用私有数据(企业的高价值数据资产)作为知识来源和训练数据,对大模型进行再训练和精调,因此无论在计算、存储中都要保障数据资产的安全。联想通过私有化的一体化大模型平台保障了数据的安全可控,为客户部署AI平台,帮助客户实现推理加速、分布式训练&微调,任务编排等 AI基础能力。
在部署与运维方面,一方面AI大模型带来的大算力、大存储需求更加复杂,且需要进行持续迭代;另一方面,新建大模型要与原有IT系统融合、互通,加快数据流通,这也进一步增加了IT部署与运维的难度。
对此,联想将以服务的方式为客户提供方案交付,并且整个服务过程将在联想智能服务平台 AI force上进行统一管理,实现一站式交付,并且安全可控,客户也可以通过 AI force平台进行企业助手(智能体)部署服务、企业知识库部署服务、业务系统插件化服务以及企业模型微调及部署服务,更加安全、便捷的实现自身智能化管理。
在产业数字化的国家战略下,将人工智能与产业结合,打造更多落地应用,赋能千行百业的企业,跟随产业一同发展,“大模型+产业”则是一项更符合中国本土市场实际情况的发展战略。企业应该做好重构产品和服务的准备,包括基础设施层面,也包括思维方式、组织方式层面。戴炜表示,“联想全栈式解决方案与陪伴式服务将帮助正在探索大模型应用的企业更加经济地、高效地实现大模型应用的落地,抢跑下一轮智能化变革。”
联想全栈智能布局,加速推动AI走深向实
据IDC报告显示,随着生成式AI应用的爆发,各行业对智算的需求首次超过通用算力,智能算力已成为算力发展的主要方向。
在为技术进步欢欣雀跃的同时,联想也开始了更深层次的探求,即打造全景式的人工智能,“从口袋到云端”的计算能力,将公共大模型和个人大模型,以及企业级大模型相结合。
业内人士普遍认为,未来终端将嵌入超级算力,在端上完成用户个性化模型的训练和推理任务。智能终端作为人工智能触达终端用户的终极载体,成为了联想打造全景式的人工智能的重要方向。
联想早在6年前就已前瞻性地预见到了智能革命的大势所趋,启动了3S战略。而今,依托“端边云网智”新IT架构,联想已经打造了包含AI内嵌的智能终端、AI导向的基础设施和AI原生的方案服务的全栈智能布局。联想也成功转变为全栈智能的产品,方案和服务的提供商。
在刚结束的联想创新科技大会上,联想对外公布了首款AIPC产品,该设备搭载了联想的大模型压缩技术,从而具备运行个人大模型的能力,能够基于本地运行不涉及云端操作,由此保证了个人隐私和数据安全。
在对智能终端不断探索的同时,联想也将AI导向的算力基础设施推向了新的高度。联想今年推出了两款AI服务器——联想问天WA7780 G3 AI大模型训练服务器和联想问天WA5480 G3 AI训推一体服务器。作为全新的AI导向的算力基础设施,其不仅性能领先,还全面覆盖云端、边缘算力场景,同时满足AI大模型和传统模型的训练、推理需求。
值得一提的是,作为陪伴中国信息化、数字化发展历程的高新制造企业,联想已扎根实体长达39年。依托新IT架构,联想“内生外化”打磨出了具有中台化&云原生、AI智能和ESG三大特征的IT引擎——擎天,并构建出诸多数字化最佳实践。可以帮助客户打造专属的企业大模型,全面赋能企业的业务系统。以实赋实,帮助客户实现 AI转型。
在生成式人工智能蓬勃发展的背后,算力尤其是AI算力已经成为驱动大模型进化的核心引擎。联想积极响应国家“东数西算”战略,目前已在宁夏等西部地区布局绿色数据中心资源,并与多方联手打造多个行业标杆项目。
如今,联想在甘肃参与打造了西北地区最大的智算和超算平台—紫金云。据了解,紫金云算力平台不仅承担着西部与东部的协同枢纽功能,还面对西北地区计算和存储资源需求,在端边云网间输送先进算力。
未来,AI的落地、普及与安全,不仅仅是智能设备的课题,更关乎全产品组合与全方位、全景式的能力布局。
戴炜表示,“在 AI大模型浪潮下,在新的智能算力需求下,联想致力于成为“新IT”全栈解决方案提供商,为客户提供 AI内嵌的智能终端,AI导向的基础设施,以及 AI原生的方案服务,为政府、教育、制造、金融等行业客户提供 AI大模型赋能的“端边云网智”全栈解决方案,加速客户的智能化转型。”
-
RT-Thread
+关注
关注
31文章
1288浏览量
40115
原文标题:【第20231110期嵌入式AI简报】OpenAI 如何再次让 AI 圈一夜未眠?
文章出处:【微信号:RTThread,微信公众号:RTThread物联网操作系统】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD分析嵌入式边缘AI的发展
开启全新AI时代 智能嵌入式系统快速发展——“第六届国产嵌入式操作系统技术与产业发展论坛”圆满结束
恩智浦加速嵌入式AI创新应用开发
AI普及给嵌入式设计人员带来新挑战

嵌入式软件开发与AI整合

EVASH Ultra EEPROM:助力ChatGPT等AI应用的嵌入式存储解决方案
openEuler 24.03 LTS Meetup:聚焦AI、嵌入式与分布式创新
AI引爆边缘计算变革,塑造嵌入式产业新未来AI引爆边缘计算变革,塑造嵌入式产业新未来——2024研华嵌入式

苹果市值一夜大涨495亿美元 苹果搭上OpenAI的AI快车?
AI与开源力推嵌入式系统创新升级
英伟达市值一夜蒸发6116亿元
AMD Versal SoC刷新边缘AI性能,单芯片方案驱动嵌入式系统

AMD Versal SoC全新升级边缘AI性能,单芯片方案驱动嵌入式系统

嵌入式人工智能的就业方向有哪些?
新火种AI|扎克伯格力压盖茨!Meta一夜狂涨万亿,全凭AI逆天改命?





 工商网监
工商网监
评论