 netmap的源码分析
netmap的源码分析
netmap的出现,它既实现了一个高性能的网络I/O框架,代码量又不算大,非常适合学习和研究。
netmap简单介绍
首先要感谢netmap的作者,创造出了netmap并无私的分享了他的设计和代码。netmap的文档写得很不错,这里我简单说明一下为什么netmap可以达到高性能。
- 利用mmap,将网卡驱动的ring内存空间映射到用户空间。这样用户态可以直接访问到原始的数据包,避免了内核和用户态的两次拷贝;——前两天我还想写这么一个东西呢。
- 利用预先分配的固定大小的buff来保存数据包。这样减少了内核原有的动态分配;——对于网络设备来说,固定大小的内存池比buddy要有效的多。之前我跟Bean_lee也提过此事呵。
- 批量处理数据包。这样就减少了系统调用;
更具体的内容,大家直接去netmap的官方网站上看吧,写得很详细。虽然英文,大家还是耐着性子好好看看,收获良多。
netmap的源码分析
从上面netmap的简单介绍中可以看到,netmap不可避免的要修改网卡驱动。不过这个修改量很小。
驱动的修改
下面我以e1000.c为例来分析。由于netmap最早是在FreeBSD上实现的,为了在linux达到最小的修改,使用了大量的宏,这给代码的阅读带来了一些困难。
e1000_probe的修改 俺不是写驱动的。。。e1000_probe里面很多代码看不明白,但是不影响我们对netmap的分析。通过netmap的patch,知道是在e1000完成一系列硬件初始化以后,并注册成功,这时调用e1000_netmap_attach
@@ -1175,6 +1183,10 @@ static int __devinit e1000_probe(struct
if (err)
goto err_register;
+#ifdef DEV_NETMAP
+ e1000_netmap_attach(adapter);
+#endif /* DEV_NETMAP */
+
/* print bus type/speed/width info */
e_info(probe, "(PCI%s:%dMHz:%d-bit) %pMn",
((hw- >bus_type == e1000_bus_type_pcix) ? "-X" : ""),
下面是e1000_netmap_attach的代码
01.static void02.e1000_netmap_attach(struct SOFTC_T *adapter)03.{04.struct netmap_adapter na;05.bzero(&na, sizeof(na));06. 07.na.ifp = adapter- >netdev;08.na.separate_locks = 0;09.na.num_tx_desc = adapter- >tx_ring[0].count;10.na.num_rx_desc = adapter- >rx_ring[0].count;11.na.nm_register = e1000_netmap_reg;12.na.nm_txsync = e1000_netmap_txsync;13.na.nm_rxsync = e1000_netmap_rxsync;14.netmap_attach(&na, 1);15.}
SOFTC_T是一个宏定义,对于e1000,实际上是e1000_adapter,即e1000网卡驱动对应的private data。 下面是struct netmap_adapter的定义
/*
* This struct extends the 'struct adapter' (or
* equivalent) device descriptor. It contains all fields needed to
* support netmap operation.
*/
struct netmap_adapter {
/*
* On linux we do not have a good way to tell if an interface
* is netmap-capable. So we use the following trick:
* NA(ifp) points here, and the first entry (which hopefully
* always exists and is at least 32 bits) contains a magic
* value which we can use to detect that the interface is good.
*/
uint32_t magic;
uint32_t na_flags; /* future place for IFCAP_NETMAP */
int refcount; /* number of user-space descriptors using this
interface, which is equal to the number of
struct netmap_if objs in the mapped region. */
/*
* The selwakeup in the interrupt thread can use per-ring
* and/or global wait queues. We track how many clients
* of each type we have so we can optimize the drivers,
* and especially avoid huge contention on the locks.
*/
int na_single; /* threads attached to a single hw queue */
int na_multi; /* threads attached to multiple hw queues */
int separate_locks; /* set if the interface suports different
locks for rx, tx and core. */
u_int num_rx_rings; /* number of adapter receive rings */
u_int num_tx_rings; /* number of adapter transmit rings */
u_int num_tx_desc; /* number of descriptor in each queue */
u_int num_rx_desc;
/* tx_rings and rx_rings are private but allocated
* as a contiguous chunk of memory. Each array has
* N+1 entries, for the adapter queues and for the host queue.
*/
struct netmap_kring *tx_rings; /* array of TX rings. */
struct netmap_kring *rx_rings; /* array of RX rings. */
NM_SELINFO_T tx_si, rx_si; /* global wait queues */
/* copy of if_qflush and if_transmit pointers, to intercept
* packets from the network stack when netmap is active.
*/
int (*if_transmit)(struct ifnet *, struct mbuf *);
/* references to the ifnet and device routines, used by
* the generic netmap functions.
*/
struct ifnet *ifp; /* adapter is ifp- >if_softc */
NM_LOCK_T core_lock; /* used if no device lock available */
int (*nm_register)(struct ifnet *, int onoff);
void (*nm_lock)(struct ifnet *, int what, u_int ringid);
int (*nm_txsync)(struct ifnet *, u_int ring, int lock);
int (*nm_rxsync)(struct ifnet *, u_int ring, int lock);
int bdg_port;
#ifdef linux
struct net_device_ops nm_ndo;
int if_refcount; // XXX additions for bridge
#endif /* linux */
};
从struct netmap_adapter可以看出,netmap的注释是相当详细。所以后面,我不再列出netmap的结构体定义,大家可以自己查看,免得满篇全是代码。————这样的注释,有几个公司能够做到?
e1000_netmap_attach完成简单的初始化工作以后,调用netmap_attach执行真正的attach工作。前者是完成与具体驱动相关的attach工作或者说是准备工作,而后者则是真正的attach。
int
netmap_attach(struct netmap_adapter *na, int num_queues)
{
int n, size;
void *buf;
/* 这里ifnet又是一个宏,linux下ifnet实际上是net_device */
struct ifnet *ifp = na- >ifp;
if (ifp == NULL) {
D("ifp not set, giving up");
return EINVAL;
}
/* clear other fields ? */
na- >refcount = 0;
/* 初始化接收和发送ring */
if (na- >num_tx_rings == 0)
na- >num_tx_rings = num_queues;
na- >num_rx_rings = num_queues;
/* on each direction we have N+1 resources
* 0..n-1 are the hardware rings
* n is the ring attached to the stack.
*/
/*
这么详细的注释。。。还用得着我说吗?
0到n-1的ring是用于转发的ring,而n是本机协议栈的队列
n+1为哨兵位置
*/
n = na- >num_rx_rings + na- >num_tx_rings + 2;
/* netmap_adapter与其ring统一申请内存 */
size = sizeof(*na) + n * sizeof(struct netmap_kring);
/*
这里的malloc,实际上为kmalloc。
这里还有一个小trick。M_DEVBUF,M_NOWAIT和M_ZERO都是FreeBSD的定义。那么在linux下怎么使用呢?
我开始以为其被定义为linux对应的flag,如GFP_ATOMIC和__GFP_ZERO,于是grep了M_NOWAIT,也没有找到任何的宏定义。
正在奇怪的时候,想到一种情况。让我们看看malloc的宏定义
/* use volatile to fix a probable compiler error on 2.6.25 */
#define malloc(_size, type, flags)
({ volatile int _v = _size; kmalloc(_v, GFP_ATOMIC | __GFP_ZERO); })
这里type和flags完全没有任何引用的地方。所以在linux下,上面的M_DEVBUG实际上直接被忽略掉了。
*/
buf = malloc(size, M_DEVBUF, M_NOWAIT | M_ZERO);
if (buf) {
/* Linux下重用了struct net_device- >ax25_ptr,用其保存buf的地址 */
WNA(ifp) = buf;
/* 初始化tx_rings和rx_rings,tx_rings和rx_rings之间用了一个额外的ring分隔,目前不知道这个ring是哨兵呢,还是本主机的ring */
na- >tx_rings = (void *)((char *)buf + sizeof(*na));
na- >rx_rings = na- >tx_rings + na- >num_tx_rings + 1;
/* 复制netmap_device并设置对应的标志位,用于表示其为netmap_device*/
bcopy(na, buf, sizeof(*na));
NETMAP_SET_CAPABLE(ifp);
na = buf;
/* Core lock initialized here. Others are initialized after
* netmap_if_new.
*/
mtx_init(&na- >core_lock, "netmap core lock", MTX_NETWORK_LOCK,
MTX_DEF);
if (na- >nm_lock == NULL) {
ND("using default locks for %s", ifp- >if_xname);
na- >nm_lock = netmap_lock_wrapper;
}
}
/* 这几行Linux才用的上的代码,是为linux网卡的驱动框架准备的。未来有用处 */
#ifdef linux
if (ifp- >netdev_ops) {
D("netdev_ops %p", ifp- >netdev_ops);
/* prepare a clone of the netdev ops */
na- >nm_ndo = *ifp- >netdev_ops;
}
na- >nm_ndo.ndo_start_xmit = linux_netmap_start;
#endif
D("%s for %s", buf ? "ok" : "failed", ifp- >if_xname);
return (buf ? 0 : ENOMEM);
}
完成了netmap_attach,e1000的probe函数e1000_probe即执行完毕。
前面e1000_probe的分析,按照Linux驱动框架,接下来就该e1000_open。netmap并没有对e1000_open进行任何修改,而是改动了e1000_configure,其会被e1000_open及e1000_up调用。
e1000_configure的修改
按照惯例,还是先看diff文件
@@ -393,6 +397,10 @@ static void e1000_configure(struct e1000
e1000_configure_tx(adapter);
e1000_setup_rctl(adapter);
e1000_configure_rx(adapter);
+#ifdef DEV_NETMAP
+ if (e1000_netmap_init_buffers(adapter))
+ return;
+#endif /* DEV_NETMAP */
/* call E1000_DESC_UNUSED which always leaves
* at least 1 descriptor unused to make sure
* next_to_use != next_to_clean */
从diff文件可以看出,netmap替代了原有的e1000申请ring buffer的代码。如果e1000_netmap_init_buffers成功返回,e1000_configure就直接退出了。
接下来进入e1000_netmap_init_buffers:
/*
* Make the tx and rx rings point to the netmap buffers.
*/
static int e1000_netmap_init_buffers(struct SOFTC_T *adapter)
{
struct e1000_hw *hw = &adapter- >hw;
struct ifnet *ifp = adapter- >netdev;
struct netmap_adapter* na = NA(ifp);
struct netmap_slot* slot;
struct e1000_tx_ring* txr = &adapter- >tx_ring[0];
unsigned int i, r, si;
uint64_t paddr;
/*
还记得前面的netmap_attach吗?
所谓的attach,即申请了netmap_adapter,并将net_device- >ax25_ptr保存了指针,并设置了NETMAP_SET_CAPABLE。
因此这里做一个sanity check,以免影响正常的网卡驱动
*/
if (!na || !(na- >ifp- >if_capenable & IFCAP_NETMAP))
return 0;
/* e1000_no_rx_alloc如其名,为一个不该调用的函数,只输出一行错误日志 */
adapter- >alloc_rx_buf = e1000_no_rx_alloc;
for (r = 0; r < na- >num_rx_rings; r++) {
struct e1000_rx_ring *rxr;
/* 初始化对应的netmap对应的ring */
slot = netmap_reset(na, NR_RX, r, 0);
if (!slot) {
D("strange, null netmap ring %d", r);
return 0;
}
/* 得到e1000对应的ring */
rxr = &adapter- >rx_ring[r];
for (i = 0; i < rxr- >count; i++) {
// XXX the skb check and cleanup can go away
struct e1000_buffer *bi = &rxr- >buffer_info[i];
/* 将当前的buff索引转换为netmap的buff索引 */
si = netmap_idx_n2k(&na- >rx_rings[r], i);
/* 获得netmap的buff的物理地址 */
PNMB(slot + si, &paddr);
if (bi- >skb)
D("rx buf %d was set", i);
bi- >skb = NULL;
// netmap_load_map(...)
/* 现在网卡的这个buffer已经指向了netmap申请的buff地址了 */
E1000_RX_DESC(*rxr, i)- >buffer_addr = htole64(paddr);
}
rxr- >next_to_use = 0;
/*
下面这几行代码没看明白怎么回事。
有明白的同学指点一下,多谢。
*/
/* preserve buffers already made available to clients */
i = rxr- >count - 1 - na- >rx_rings[0].nr_hwavail;
if (i < 0)
i += rxr- >count;
D("i now is %d", i);
wmb(); /* Force memory writes to complete */
writel(i, hw- >hw_addr + rxr- >rdt);
}
/*
初始化发送ring,与接收类似.
区别在于没有考虑发送多队列。难道是因为e1000只可能是接收多队列,发送只可能是一个队列?
这个问题不影响后面的代码阅读。咱们可以暂时将其假设为e1000只有一个发送队列
*/
/* now initialize the tx ring(s) */
slot = netmap_reset(na, NR_TX, 0, 0);
for (i = 0; i < na- >num_tx_desc; i++) {
si = netmap_idx_n2k(&na- >tx_rings[0], i);
PNMB(slot + si, &paddr);
// netmap_load_map(...)
E1000_TX_DESC(*txr, i)- >buffer_addr = htole64(paddr);
}
return 1;
}
e1000cleanrx_irq的修改
@@ -3952,6 +3973,11 @@ static bool e1000_clean_rx_irq(struct e1
bool cleaned = false;
unsigned int total_rx_bytes=0, total_rx_packets=0;
+#ifdef DEV_NETMAP
+ ND("calling netmap_rx_irq");
+ if (netmap_rx_irq(netdev, 0, work_done))
+ return 1; /* seems to be ignored */
+#endif /* DEV_NETMAP */
i = rx_ring- >next_to_clean;
rx_desc = E1000_RX_DESC(*rx_ring, i);
buffer_info = &rx_ring- >buffer_info[i];
进入netmap_rx_irq, int netmaprxirq(struct ifnet *ifp, int q, int *workdone) { struct netmapadapter *na; struct netmap_kring *r; NMSELINFOT *main_wq;
if (!(ifp- >if_capenable & IFCAP_NETMAP))
return 0;
na = NA(ifp);
/*
尽管函数名为rx,但实际上这个函数服务于rx和tx两种情况,用work_done做区分。
*/
if (work_done) { /* RX path */
r = na- >rx_rings + q;
r- >nr_kflags |= NKR_PENDINTR;
main_wq = (na- >num_rx_rings > 1) ? &na- >rx_si : NULL;
} else { /* tx path */
r = na- >tx_rings + q;
main_wq = (na- >num_tx_rings > 1) ? &na- >tx_si : NULL;
work_done = &q; /* dummy */
}
/*
na- >separate_locks只在ixgbe和bridge中会被设置为1。
根据下面的代码,这个separate_locks表示多队列时,是每个队列使用一个锁。——这样可以提高性能
其余的代码基本相同。都是唤醒等待数据的进程。
*/
if (na- >separate_locks) {
mtx_lock(&r- >q_lock);
selwakeuppri(&r- >si, PI_NET);
mtx_unlock(&r- >q_lock);
if (main_wq) {
mtx_lock(&na- >core_lock);
selwakeuppri(main_wq, PI_NET);
mtx_unlock(&na- >core_lock);
}
} else {
mtx_lock(&na- >core_lock);
selwakeuppri(&r- >si, PI_NET);
if (main_wq)
selwakeuppri(main_wq, PI_NET);
mtx_unlock(&na- >core_lock);
}
*work_done = 1; /* do not fire napi again */
return 1;
}
发送部分的修改与接收类似,就不重复了。
开始进入netmap的核心代码。一切从init开始。。。
netmap_init
Linux环境下,netmap使用动态模块加载,由linuxnetmapinit调用netmap_init。
static int
netmap_init(void)
{
int error;
/*
申请netmap的各个内存池,包括netmap_if,netmap_ring,netmap_buf以及内存池的管理结构
*/
error = netmap_memory_init();
if (error != 0) {
printf("netmap: unable to initialize the memory allocator.n");
return (error);
}
printf("netmap: loaded module with %d Mbytesn",
(int)(nm_mem- >nm_totalsize > > 20));
/*
在Linux上,调用的实际上是misc_register。make_dev为一共宏定义。
创建一个名为netmap的misc设备,作为userspace和kernel的接口
*/
netmap_dev = make_dev(&netmap_cdevsw, 0, UID_ROOT, GID_WHEEL, 0660,
"netmap");
#ifdef NM_BRIDGE
{
int i;
for (i = 0; i < NM_BRIDGES; i++)
mtx_init(&nm_bridges[i].bdg_lock, "bdg lock", "bdg_lock", MTX_DEF);
}
#endif
return (error);
}
netmapmemoryinit
netmap目前有两套内存分配管理代码,一个是netmapmem1.c,另一个是netmapmem2.c。默认使用的是后者。
static int
netmap_memory_init(void)
{
struct netmap_obj_pool *p;
/* 先申请netmap内存管理结构 */
nm_mem = malloc(sizeof(struct netmap_mem_d), M_NETMAP,
M_WAITOK | M_ZERO);
if (nm_mem == NULL)
goto clean;
/* netmap_if的内存池 */
p = netmap_new_obj_allocator("netmap_if",
NETMAP_IF_MAX_NUM, NETMAP_IF_MAX_SIZE);
if (p == NULL)
goto clean;
nm_mem- >nm_if_pool = p;
/* netmap_ring的内存池 */
p = netmap_new_obj_allocator("netmap_ring",
NETMAP_RING_MAX_NUM, NETMAP_RING_MAX_SIZE);
if (p == NULL)
goto clean;
nm_mem- >nm_ring_pool = p;
/* netmap_buf的内存池 */
p = netmap_new_obj_allocator("netmap_buf",
NETMAP_BUF_MAX_NUM, NETMAP_BUF_SIZE);
if (p == NULL)
goto clean;
/* 对于netmap_buf,为了以后的使用方便,将其中的一些信息保存到其它明确的全局变量中 */
netmap_total_buffers = p- >objtotal;
netmap_buffer_lut = p- >lut;
nm_mem- >nm_buf_pool = p;
netmap_buffer_base = p- >lut[0].vaddr;
mtx_init(&nm_mem- >nm_mtx, "netmap memory allocator lock", NULL,
MTX_DEF);
nm_mem- >nm_totalsize =
nm_mem- >nm_if_pool- >_memtotal +
nm_mem- >nm_ring_pool- >_memtotal +
nm_mem- >nm_buf_pool- >_memtotal;
D("Have %d KB for interfaces, %d KB for rings and %d MB for buffers",
nm_mem- >nm_if_pool- >_memtotal > > 10,
nm_mem- >nm_ring_pool- >_memtotal > > 10,
nm_mem- >nm_buf_pool- >_memtotal > > 20);
return 0;
clean:
if (nm_mem) {
netmap_destroy_obj_allocator(nm_mem- >nm_ring_pool);
netmap_destroy_obj_allocator(nm_mem- >nm_if_pool);
free(nm_mem, M_NETMAP);
}
return ENOMEM;
}
netmapnewobj_allocator
进入内存池的申请函数——这是netmap中比较长的函数了。
static struct netmap_obj_pool *
netmap_new_obj_allocator(const char *name, u_int objtotal, u_int objsize)
{
struct netmap_obj_pool *p;
int i, n;
u_int clustsize; /* the cluster size, multiple of page size */
u_int clustentries; /* how many objects per entry */
#define MAX_CLUSTSIZE (1< < 17)
#define LINE_ROUND 64
/* 这个检查应该是netmap不允许申请过于大的结构的内存池 */
if (objsize >= MAX_CLUSTSIZE) {
/* we could do it but there is no point */
D("unsupported allocation for %d bytes", objsize);
return NULL;
}
/*
让obj的size取整到64字节。为啥呢?
因为CPU的cache line大小一般是64字节。所以object的size如果和cache line对齐,可以获得更好的性能。
关于cache line对性能的影响,可以看一下我以前写得一篇博文《多核编程:选择合适的结构体大小,提高多核并发性能》
*/
/* make sure objsize is a multiple of LINE_ROUND */
i = (objsize & (LINE_ROUND - 1));
if (i) {
D("XXX aligning object by %d bytes", LINE_ROUND - i);
objsize += LINE_ROUND - i;
}
/*
* Compute number of objects using a brute-force approach:
* given a max cluster size,
* we try to fill it with objects keeping track of the
* wasted space to the next page boundary.
*/
/*
这里有一个概念:cluster。
暂时没有找到相关的文档介绍这里的cluster的概念。
这里,我只能凭借下面的代码来说一下我的理解:
cluster是一组内存池分配对象object的集合。为什么要有这么一个集合呢?
众所周知,Linux的内存管理是基于页的。而object的大小或小于一个页,或大于一个页。如果基于object本身进行内存分配,会造成内存的浪费。
所以这里引入了cluster的概念,它占用一个或多个连续页。这些页的内存大小或为object大小的整数倍,或者是浪费空间最小。
下面的方法是一个比较激进的计算cluster的方法,它尽可能的追求上面的目标直到cluster的占用的大小超出设定的最大值——MAX_CLUSTSIZE。
*/
for (clustentries = 0, i = 1;; i++) {
u_int delta, used = i * objsize;
/* 不能一味的增长cluster,最大占用空间为MAX_CLUSTSIZE */
if (used > MAX_CLUSTSIZE)
break;
/* 最后页面占用的空间 */
delta = used % PAGE_SIZE;
if (delta == 0) { // exact solution
clustentries = i;
break;
}
/* 这次利用页面空间的效率比上次的高,所以更新当前的clustentries,即cluster的个数*/
if (delta > ( (clustentries*objsize) % PAGE_SIZE) )
clustentries = i;
}
// D("XXX --- ouch, delta %d (bad for buffers)", delta);
/* compute clustsize and round to the next page */
/* 得到cluster的大小,并将其与PAGE SIZE对齐 */
clustsize = clustentries * objsize;
i = (clustsize & (PAGE_SIZE - 1));
if (i)
clustsize += PAGE_SIZE - i;
D("objsize %d clustsize %d objects %d",
objsize, clustsize, clustentries);
/* 申请内存池管理结构的内存 */
p = malloc(sizeof(struct netmap_obj_pool), M_NETMAP,
M_WAITOK | M_ZERO);
if (p == NULL) {
D("Unable to create '%s' allocator", name);
return NULL;
}
/*
* Allocate and initialize the lookup table.
*
* The number of clusters is n = ceil(objtotal/clustentries)
* objtotal' = n * clustentries
*/
/* 初始化内存池管理结构 */
strncpy(p- >name, name, sizeof(p- >name));
p- >clustentries = clustentries;
p- >_clustsize = clustsize;
/* 根据要设定的内存池object的数量,来调整cluster的个数 */
n = (objtotal + clustentries - 1) / clustentries;
p- >_numclusters = n;
/* 这是真正的内存池中的object的数量,通常是比传入的参数objtotal要多 */
p- >objtotal = n * clustentries;
/* 为什么0和1是reserved,暂时不明。搁置争议,留给后面解决吧。:) */
p- >objfree = p- >objtotal - 2; /* obj 0 and 1 are reserved */
p- >_objsize = objsize;
p- >_memtotal = p- >_numclusters * p- >_clustsize;
/* 物理地址与虚拟地址对应的查询表 */
p- >lut = malloc(sizeof(struct lut_entry) * p- >objtotal,
M_NETMAP, M_WAITOK | M_ZERO);
if (p- >lut == NULL) {
D("Unable to create lookup table for '%s' allocator", name);
goto clean;
}
/* Allocate the bitmap */
/* 申请内存池位图,用于表示那个object被分配了 */
n = (p- >objtotal + 31) / 32;
p- >bitmap = malloc(sizeof(uint32_t) * n, M_NETMAP, M_WAITOK | M_ZERO);
if (p- >bitmap == NULL) {
D("Unable to create bitmap (%d entries) for allocator '%s'", n,
name);
goto clean;
}
/*
* Allocate clusters, init pointers and bitmap
*/
for (i = 0; i < p- >objtotal;) {
int lim = i + clustentries;
char *clust;
clust = contigmalloc(clustsize, M_NETMAP, M_WAITOK | M_ZERO,
0, -1UL, PAGE_SIZE, 0);
if (clust == NULL) {
/*
* If we get here, there is a severe memory shortage,
* so halve the allocated memory to reclaim some.
*/
D("Unable to create cluster at %d for '%s' allocator",
i, name);
lim = i / 2;
for (; i >= lim; i--) {
p- >bitmap[ (i >>5) ] &= ~( 1 < < (i & 31) );
if (i % clustentries == 0 && p- >lut[i].vaddr)
contigfree(p- >lut[i].vaddr,
p- >_clustsize, M_NETMAP);
}
p- >objtotal = i;
p- >objfree = p- >objtotal - 2;
p- >_numclusters = i / clustentries;
p- >_memtotal = p- >_numclusters * p- >_clustsize;
break;
}
/* 初始化位图即虚拟地址和物理地址插叙表 */
for (; i < lim; i++, clust += objsize) {
/*
1. bitmap是32位,所以i > > 5;
2. 为什么(i&31),也是这个原因;—— 这就是代码的健壮性。
*/
p- >bitmap[ (i >>5) ] |= ( 1 < < (i & 31) );
p- >lut[i].vaddr = clust;
p- >lut[i].paddr = vtophys(clust);
}
}
/* 与前面一样,保留第0位和第1位。再次搁置争议。。。 */
p- >bitmap[0] = ~3; /* objs 0 and 1 is always busy */
D("Pre-allocated %d clusters (%d/%dKB) for '%s'",
p- >_numclusters, p- >_clustsize > > 10,
p- >_memtotal > > 10, name);
return p;
clean:
netmap_destroy_obj_allocator(p);
return NULL;
}
netmapnewobj_allocator的分析结束。关于netmap的内存管理,依然按照事件的主线分析,而不是集中将一部分搞定。
接下来就要从netmap的使用,自上而下的学习分析一下netmap的代码了。
netmap的应用示例
netmap的网站上给出了一个简单的例子——说简单,其实也涵盖了netmap的框架的调用。
struct netmap_if *nifp;
struct nmreq req;
int i, len;
char *buf;
fd = open("/dev/netmap", 0);
strcpy(req.nr_name, "ix0"); // register the interface
ioctl(fd, NIOCREG, &req); // offset of the structure
mem = mmap(NULL, req.nr_memsize, PROT_READ|PROT_WRITE, 0, fd, 0);
nifp = NETMAP_IF(mem, req.nr_offset);
for (;;) {
struct pollfd x[1];
struct netmap_ring *ring = NETMAP_RX_RING(nifp, 0);
x[0].fd = fd;
x[0].events = POLLIN;
poll(x, 1, 1000);
for ( ; ring- >avail > 0 ; ring- >avail--) {
i = ring- >cur;
buf = NETMAP_BUF(ring, i);
use_data(buf, ring- >slot[i].len);
ring- >cur = NETMAP_NEXT(ring, i);
}
}
咱们还是一路走来,走到哪看到哪。
open操作
这个其实跟netmap没有多大关系。记得前文中的netmap注册了一个misc设备netmap_cdevsw吗?
static struct file_operations netmap_fops = {
.mmap = linux_netmap_mmap,
LIN_IOCTL_NAME = linux_netmap_ioctl,
.poll = linux_netmap_poll,
.release = netmap_release,
};
static struct miscdevice netmap_cdevsw = { /* same name as FreeBSD */
MISC_DYNAMIC_MINOR,
"netmap",
&netmap_fops,
};
netmapcdevsw为对应的设备结构体定义,netmapfops为对应的操作函数。这里面没有自定义的open函数,那么应该就使用linux内核默认的open——这个是我的推测,暂时不去查看linux代码了。
NIOCREG ioctl操作
ioctl就是内核的一个垃圾桶啊,什么都往里装,什么都能做。
netmap的ioctl
long
linux_netmap_ioctl(struct file *file, u_int cmd, u_long data /* arg */)
{
int ret;
struct nmreq nmr;
bzero(&nmr, sizeof(nmr));
/*
从上面的例子和这里可以看出,struct nmreq就是netmap内核与用户空间的消息结构体。
两者的互动就靠它了。
*/
if (data && copy_from_user(&nmr, (void *)data, sizeof(nmr) ) != 0)
return -EFAULT;
ret = netmap_ioctl(NULL, cmd, (caddr_t)&nmr, 0, (void *)file);
if (data && copy_to_user((void*)data, &nmr, sizeof(nmr) ) != 0)
return -EFAULT;
return -ret;
}
进入netmap_ioctl,真正的netmap的ioctl处理函数
static int
netmap_ioctl(struct cdev *dev, u_long cmd, caddr_t data,
int fflag, struct thread *td)
{
struct netmap_priv_d *priv = NULL;
struct ifnet *ifp;
struct nmreq *nmr = (struct nmreq *) data;
struct netmap_adapter *na;
int error;
u_int i, lim;
struct netmap_if *nifp;
/*
为了去除warning警告——没用的参数。
void应用的一个小技巧
*/
(void)dev; /* UNUSED */
(void)fflag; /* UNUSED */
/* Linux下这两个红都是空的 */
CURVNET_SET(TD_TO_VNET(td));
/*
devfs_get_cdevpriv在linux下是一个宏定义。
得到struct file- >private_data;
当private_data不为NULL时,返回0;为null时,返回ENOENT。
所以对于linux,后面的条件判断永远为假
*/
error = devfs_get_cdevpriv((void **)&priv);
if (error != ENOENT && error != 0) {
CURVNET_RESTORE();
return (error);
}
error = 0; /* Could be ENOENT */
/*
又可见到高手代码健壮性的体现。
对于运行在kernel中的代码,一定要稳定!强制保证nmr- >nr_name字符串长度的合法性
*/
nmr- >nr_name[sizeof(nmr- >nr_name) - 1] = '�'; /* truncate name */
。。。。。。 。。。。。。
为了流程的清楚,对于netmap_ioctl的分析就到这里。依然按照之前的使用的流程走。
写到这里我发现netmap网站给的实例应该是老古董了。按照netmap当前的代码,上面的例子根本无法使用。不过木已成舟,大家凑合意会理解这个例子吧,还好流程没有太大的变化。
既然示例代码不可信了,那么就按照ioctl支持的命令顺序,来分析netmap吧。
NIOCGINFO
用于返回netmap的基本信息
case NIOCGINFO: /* return capabilities etc */
/* memsize is always valid */
/*
如果是我写,我可能先去做后面的版本检查
netmap这样选择,应该是因为这些信息与版本无关。
*/
nmr- >nr_memsize = nm_mem- >nm_totalsize;
nmr- >nr_offset = 0;
nmr- >nr_rx_rings = nmr- >nr_tx_rings = 0;
nmr- >nr_rx_slots = nmr- >nr_tx_slots = 0;
if (nmr- >nr_version != NETMAP_API) {
D("API mismatch got %d have %d",
nmr- >nr_version, NETMAP_API);
nmr- >nr_version = NETMAP_API;
error = EINVAL;
break;
}
if (nmr- >nr_name[0] == '�') /* just get memory info */
break;
/*
Linux下调用dev_get_by_name通过网卡名得到网卡struct net_device。
并且通过NETMAP_CAPABLE来检查netmap是否attach了这个net_device——忘记NETMAP_CAPABLE和attach的同学请自行查看前面几篇文章。
*/
error = get_ifp(nmr- >nr_name, &ifp); /* get a refcount */
if (error)
break;
/* 得到attach到网卡结构的netmap结构体 */
na = NA(ifp); /* retrieve netmap_adapter */
/* 得到ring的个数,以及每个ring有多少slot */
nmr- >nr_rx_rings = na- >num_rx_rings;
nmr- >nr_tx_rings = na- >num_tx_rings;
nmr- >nr_rx_slots = na- >num_rx_desc;
nmr- >nr_tx_slots = na- >num_tx_desc;
nm_if_rele(ifp); /* return the refcount */
break;
NIOCREGIF
将特定的网卡设置为netmap模式
case NIOCREGIF:
if (nmr- >nr_version != NETMAP_API) {
nmr- >nr_version = NETMAP_API;
error = EINVAL;
break;
}
if (priv != NULL) { /* thread already registered */
/* 重新设置对哪个ring感兴趣,这个函数,留到后面说 */
error = netmap_set_ringid(priv, nmr- >nr_ringid);
break;
}
/* 下面几行拿到netmap_device结构的代码,和NIOCGINFO case没什么区别 */
/* find the interface and a reference */
error = get_ifp(nmr- >nr_name, &ifp); /* keep reference */
if (error)
break;
na = NA(ifp); /* retrieve netmap adapter */
/*
* Allocate the private per-thread structure.
* XXX perhaps we can use a blocking malloc ?
*/
priv = malloc(sizeof(struct netmap_priv_d), M_DEVBUF,
M_NOWAIT | M_ZERO);
if (priv == NULL) {
error = ENOMEM;
nm_if_rele(ifp); /* return the refcount */
break;
}
/* 这里循环等待net_device可用 */
for (i = 10; i > 0; i--) {
na- >nm_lock(ifp, NETMAP_REG_LOCK, 0);
if (!NETMAP_DELETING(na))
break;
na- >nm_lock(ifp, NETMAP_REG_UNLOCK, 0);
tsleep(na, 0, "NIOCREGIF", hz/10);
}
if (i == 0) {
D("too many NIOCREGIF attempts, give up");
error = EINVAL;
free(priv, M_DEVBUF);
nm_if_rele(ifp); /* return the refcount */
break;
}
/* 保存设备net_device指针*/
priv- >np_ifp = ifp; /* store the reference */
/* 设置感兴趣的ring,即准备哪些ring来与用户态交互 */
error = netmap_set_ringid(priv, nmr- >nr_ringid);
if (error)
goto error;
/*
每一个netmap的描述符,对应每一个网卡,都有一个struct netmap_if, 即priv- >np_nifp.
*/
priv- >np_nifp = nifp = netmap_if_new(nmr- >nr_name, na);
if (nifp == NULL) { /* allocation failed */
error = ENOMEM;
} else if (ifp- >if_capenable & IFCAP_NETMAP) {
/* was already set */
/* 网卡对应的netmap_device的扩展已经设置过了 */
} else {
/* Otherwise set the card in netmap mode
* and make it use the shared buffers.
*/
/* 这时,这块网卡真正要进入netmap模式,开始初始化一些成员变量 */
for (i = 0 ; i < na- >num_tx_rings + 1; i++)
mtx_init(&na- >tx_rings[i].q_lock, "nm_txq_lock", MTX_NETWORK_LOCK, MTX_DEF);
for (i = 0 ; i < na- >num_rx_rings + 1; i++) {
mtx_init(&na- >rx_rings[i].q_lock, "nm_rxq_lock", MTX_NETWORK_LOCK, MTX_DEF);
}
/*
设置网卡为netmap mode为打开模式
对于e1000驱动来说,nm_register即e1000_netmap_reg
*/
error = na- >nm_register(ifp, 1); /* mode on */
if (error)
netmap_dtor_locked(priv);
}
if (error) { /* reg. failed, release priv and ref */
error:
na- >nm_lock(ifp, NETMAP_REG_UNLOCK, 0);
nm_if_rele(ifp); /* return the refcount */
bzero(priv, sizeof(*priv));
free(priv, M_DEVBUF);
break;
}
na- >nm_lock(ifp, NETMAP_REG_UNLOCK, 0);
/* Linux平台,将priv保存到file- >private_data*/
error = devfs_set_cdevpriv(priv, netmap_dtor);
if (error != 0) {
/* could not assign the private storage for the
* thread, call the destructor explicitly.
*/
netmap_dtor(priv);
break;
}
/* return the offset of the netmap_if object */
nmr- >nr_rx_rings = na- >num_rx_rings;
nmr- >nr_tx_rings = na- >num_tx_rings;
nmr- >nr_rx_slots = na- >num_rx_desc;
nmr- >nr_tx_slots = na- >num_tx_desc;
nmr- >nr_memsize = nm_mem- >nm_totalsize;
/*
得到nifp在内存池中的偏移。
因为netmap的基础就是利用内核与用户空间的内存共享。但是众所周知,内核和用户空间的地址范围是不用的。
这样同样的物理内存,在内核态和用户态地址肯定不同。所以必须利用偏移来对应相同的内存。
*/
nmr- >nr_offset = netmap_if_offset(nifp);
break;
netmap_ioctl
分析完了NIOCGINFO和NIOCREGIF两个,剩下的比较简单了。接下来是netmap_ioctl调用的函数
NIOCUNREGIF
case NIOCUNREGIF:
if (priv == NULL) {
/* 没有priv肯定是不对的,肯定是没有调用过NIOCREGIF */
error = ENXIO;
break;
}
/* the interface is unregistered inside the
destructor of the private data. */
/* 释放priv内存*/
devfs_clear_cdevpriv();
break;
NIOCTXSYNC和NIOCRXSYNC
这两个使用相同的代码。
case NIOCTXSYNC:
case NIOCRXSYNC:
/* 检查priv,确保之前调用了NIOCREGIF */
if (priv == NULL) {
error = ENXIO;
break;
}
/*
记得之前分析NIOCREGIF时,priv- >np_ifp保存了net_device指针,所有现在可以直接获得这个指针。
要不要担心net_device指针的有效性呢?不用,因为NIOCREGIF时,在得到net_device时,已经增加了计数
*/
ifp = priv- >np_ifp; /* we have a reference */
na = NA(ifp); /* retrieve netmap adapter */
/*
np_qfirst表示需要检查的第一个ring
当其值为NETMAP_SW_RING是一个特殊的值,表示处理host的ring
*/
if (priv- >np_qfirst == NETMAP_SW_RING) { /* host rings */
/*
对于host ring处理,这个地方的代码有点奇怪。
当cmd是NIOCTXSYNC,是将数据包传给host;
当cmd是NIOCRXSYNC,是将数据包从host发送出去;
感觉好像写反了。我给作者发了邮件,不知道能不能得到回复。
反正从语义上,我是觉得有问题。
现在已经得到了作者的回复——再次感叹外国人的友好。这里的方向,是以netmap的角度去看。
所以,当cmd是txsync时,是netmap把包送出去,那么自然是交给host。反之亦然。
*/
if (cmd == NIOCTXSYNC)
netmap_sync_to_host(na);
else
netmap_sync_from_host(na, NULL, NULL);
break;
}
/* find the last ring to scan */
/*
得到需要检查的最后一个ring,如果是NETMAP_HW_RING,那么就是最大ring数值
关于np_qfirst和np_qlast,等看到netmap_set_ringid时,大家就明白了
*/
lim = priv- >np_qlast;
if (lim == NETMAP_HW_RING)
lim = (cmd == NIOCTXSYNC) ?
na- >num_tx_rings : na- >num_rx_rings;
/* 从第一个开始遍历每个ring */
for (i = priv- >np_qfirst; i < lim; i++) {
if (cmd == NIOCTXSYNC) {
struct netmap_kring *kring = &na- >tx_rings[i];
if (netmap_verbose & NM_VERB_TXSYNC)
D("pre txsync ring %d cur %d hwcur %d",
i, kring- >ring- >cur,
kring- >nr_hwcur);
/* 执行发送工作,留到后面分析 */
na- >nm_txsync(ifp, i, 1 /* do lock */);
if (netmap_verbose & NM_VERB_TXSYNC)
D("post txsync ring %d cur %d hwcur %d",
i, kring- >ring- >cur,
kring- >nr_hwcur);
} else {
/* 执行接收工作,留到后面分析*/
na- >nm_rxsync(ifp, i, 1 /* do lock */);
/*
在linux平台上,实际上是调用了do_gettimeofday,不知道为什么接收需要的这个时间
看看以后是不是可以知道原因。
*/
microtime(&na- >rx_rings[i].ring- >ts);
}
}
到此,netmap_ioctl分析学习完毕。
netmap_set_ringid
static int
netmap_set_ringid(struct netmap_priv_d *priv, u_int ringid)
{
struct ifnet *ifp = priv- >np_ifp;
struct netmap_adapter *na = NA(ifp);
/*
从下面三个宏,可以得知ringid是一个“复用”的结构。低24位用于表示id值,高位作为标志。
#define NETMAP_HW_RING 0x4000 /* low bits indicate one hw ring */
#define NETMAP_SW_RING 0x2000 /* process the sw ring */
#define NETMAP_NO_TX_POLL 0x1000 /* no automatic txsync on poll */
#define NETMAP_RING_MASK 0xfff /* the ring number */
*/
u_int i = ringid & NETMAP_RING_MASK;
/*
根据注释,在初始化阶段,np_qfirst和np_qlast相等,不需要锁保护。
关于这点我没想明白。如果两个线程同时进入怎么办?
*/
/* initially (np_qfirst == np_qlast) we don't want to lock */
int need_lock = (priv- >np_qfirst != priv- >np_qlast);
int lim = na- >num_rx_rings;
/* 上限取发送和接收队列数量的最大值 */
if (na- >num_tx_rings > lim)
lim = na- >num_tx_rings;
/* 当处理HW ring时,要对id进行有效性判断 */
if ( (ringid & NETMAP_HW_RING) && i >= lim) {
D("invalid ring id %d", i);
return (EINVAL);
}
if (need_lock)
na- >nm_lock(ifp, NETMAP_CORE_LOCK, 0);
priv- >np_ringid = ringid;
/*
根据三种标志,设置正确的np_qfirst和qlast。从这里也可以看出,只有在初始化时,np_qfirst才可能等于np_qlast。
*/
if (ringid & NETMAP_SW_RING) {
priv- >np_qfirst = NETMAP_SW_RING;
priv- >np_qlast = 0;
} else if (ringid & NETMAP_HW_RING) {
priv- >np_qfirst = i;
priv- >np_qlast = i + 1;
} else {
priv- >np_qfirst = 0;
priv- >np_qlast = NETMAP_HW_RING ;
}
/* 是否在执行接收数据包的poll时,发送数据包 */
priv- >np_txpoll = (ringid & NETMAP_NO_TX_POLL) ? 0 : 1;
if (need_lock)
na- >nm_lock(ifp, NETMAP_CORE_UNLOCK, 0);
if (ringid & NETMAP_SW_RING)
D("ringid %s set to SW RING", ifp- >if_xname);
else if (ringid & NETMAP_HW_RING)
D("ringid %s set to HW RING %d", ifp- >if_xname,
priv- >np_qfirst);
else
D("ringid %s set to all %d HW RINGS", ifp- >if_xname, lim);
return 0;
}
netmap_ioctl分析完了,根据netmap的示例,下面该分析netmap的mmap的实现了。
定位netmap的mmap
前文提到过netmap会创建一个设备
static struct miscdevice netmap_cdevsw = { /* same name as FreeBSD */
MISC_DYNAMIC_MINOR,
"netmap",
&netmap_fops,
};
netmap_fops定义了netmap设备支持的操作
static struct file_operations netmap_fops = {
.mmap = linux_netmap_mmap,
LIN_IOCTL_NAME = linux_netmap_ioctl,
.poll = linux_netmap_poll,
.release = netmap_release,
};
OK,现在我们找到了mmap的入口,linuxnetmapmmap。
linux_netmap_mmap分析
现在直接进入linux_netmap_mmap的代码
static int
linux_netmap_mmap(struct file *f, struct vm_area_struct *vma)
{
int lut_skip, i, j;
int user_skip = 0;
struct lut_entry *l_entry;
const struct netmap_obj_pool *p[] = {
nm_mem- >nm_if_pool,
nm_mem- >nm_ring_pool,
nm_mem- >nm_buf_pool };
/*
* vma- >vm_start: start of mapping user address space
* vma- >vm_end: end of the mapping user address space
*/
/*
这里又是一个编程技巧,使用(void)f既不会产生任何真正的代码,又可以消除变量f没有使用的warning。
为什么f不使用,还会出现在参数列表中呢?没办法啊,只是Linux框架决定的。linux_netmap_mmap只是一个注册回调,自然要遵从linux的框架了。
*/
(void)f; /* UNUSED */
// XXX security checks
for (i = 0; i < 3; i++) { /* loop through obj_pools */
/*
* In each pool memory is allocated in clusters
* of size _clustsize , each containing clustentries
* entries. For each object k we already store the
* vtophys malling in lut[k] so we use that, scanning
* the lut[] array in steps of clustentries,
* and we map each cluster (not individual pages,
* it would be overkill).
*/
/*
上面的注释说的很明白。
每个pool里的object都是由_clustsize组成的,每一个都包含clustertries个基础内存块。 一个pool公有_numclusters个基础内存块。
所以,在进行内存映射的时候,user_skip表示已经映射的内存大小,vma- >start+user_skip也就是当前未映射内存的起始地址,lut_skip表示当前待映射的物理内存池的块索引
*/
for (lut_skip = 0, j = 0; j < p[i]- >_numclusters; j++) {
l_entry = &p[i]- >lut[lut_skip];
if (remap_pfn_range(vma, vma- >vm_start + user_skip,
l_entry- >paddr > > PAGE_SHIFT, p[i]- >_clustsize,
vma- >vm_page_prot))
return -EAGAIN; // XXX check return value
lut_skip += p[i]- >clustentries;
user_skip += p[i]- >_clustsize;
}
}
/*
循环执行完毕后,netmap在内核中的3个对象池已经完全映射到用户空间
真正执行映射的函数是remap_pfn_range,这是内核函数,用于将内核空间映射到用户空间
这个函数超出了本文的主题范围了,我们只需要知道它是做什么的就行了。
*/
return 0;
}
用户态得到对应网卡的netmap结构
在将netmap内核态的内存映射到用户空间以后,netmap的示例通过offset来得到对应网卡的netmap结构。
fd = open("/dev/netmap", 0);
strcpy(req.nr_name, "ix0"); // register the interface
ioctl(fd, NIOCREG, &req); // offset of the structure
mem = mmap(NULL, req.nr_memsize, PROT_READ|PROT_WRITE, 0, fd, 0);
nifp = NETMAP_IF(mem, req.nr_offset);
在此例中,使用ioctl,得到req.nroffset是ix0网卡的netmap结构的偏移——准确的说是netmap管理网卡结构内存池的偏移。mmap后,mem是netmap内存的映射,而网卡结构内存是内存中的第一项,那么mem同样可以视为netmap管理网卡结构的内存池的起始地址。因此,利用前面的req.nroffset,就得到了ix0的netmap结构,即struct netmap_if。
走读netmap的示例中工作代码
按照netmap示例,马上就要进入netmap真正工作的代码了。
for (;;) {
struct pollfd x[1];
/*
根据netmap的代码,NETMAP_RXRING的定义如下
#define NETMAP_RXRING(nifp, index)
((struct netmap_ring *)((char *)(nifp) +
(nifp)- >ring_ofs[index + (nifp)- >ni_tx_rings + 1] ) )
得到该网卡的接收ring buffer。
吐个槽,为什么英文接收Receive要缩写为RX呢。。。我在别的地方也见过。
*/
struct netmap_ring *ring = NETMAP_RX_RING(nifp, 0);
x[0].fd = fd;
x[0].events = POLLIN;
/* 超时1秒等接收事件发生 */
poll(x, 1, 1000);
/* 收到ring- >avail个包 */
for ( ; ring- >avail > 0 ; ring- >avail--) {
/* 得到当前包索引 */
i = ring- >cur;
/* 得到对应的数据包 */
buf = NETMAP_BUF(ring, i);
/* 用户态处理该数据包 */
use_data(buf, ring- >slot[i].len);
/* 移到下一个待处理数据包 */
ring- >cur = NETMAP_NEXT(ring, i);
}
}
-
网络设备
+关注
关注
0文章
308浏览量
29613 -
源码
+关注
关注
8文章
633浏览量
29146 -
数据包
+关注
关注
0文章
253浏览量
24366
发布评论请先 登录
相关推荐
Linux内核源码之我见——内核源码的分析方法
鸿蒙源码分析系列(总目录) | 给HarmonyOS源码逐行加上中文注释
互斥量源码分析测试
nucleus plus源码分析下载


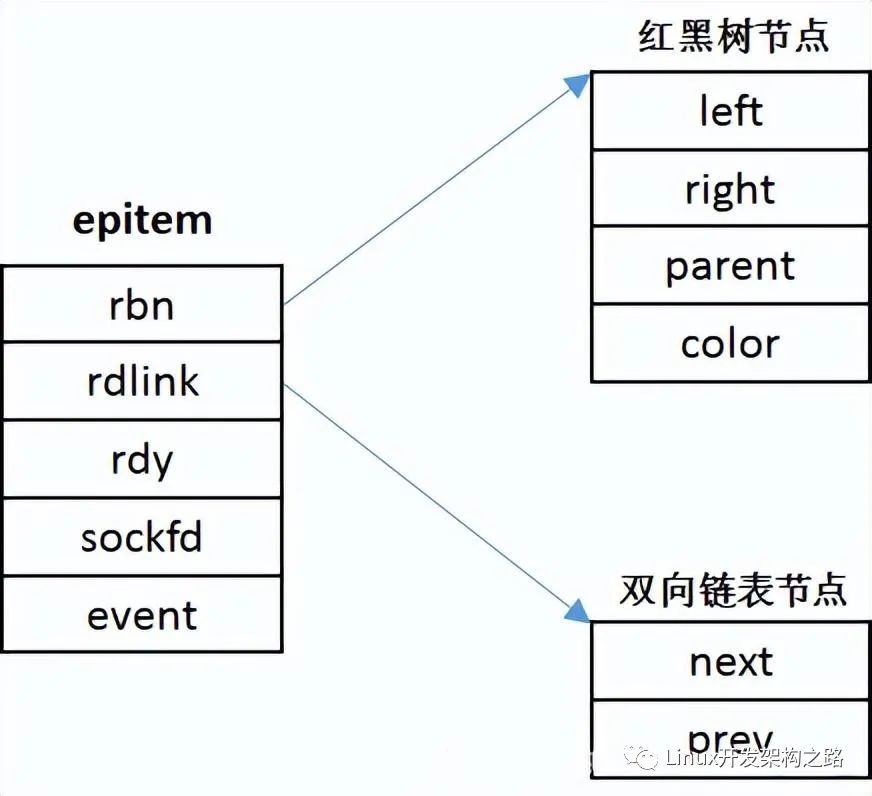
epoll源码分析





 工商网监
工商网监
评论