 非阻塞的的connect()函数如何编写
非阻塞的的connect()函数如何编写
由于网络编程涉及很多细节和技巧,一直想写篇文章来总结下这方面的心得与经验,希望对来者有一点帮助,那就善莫大焉了。
一、非阻塞的的connect()函数如何编写
我们知道用connect()函数默认是阻塞的,直到三次握手建立之后,或者实在连不上超时返回,期间程序执行流一直阻塞在那里。那么如何利用connect()函数编写非阻塞的连接代码呢?
无论在windows还是linux平台都可以采取以下思路来实现:
- 创建socket时,将socket设置成非阻塞模式;
- 接着调用connect()进行连接,如果connect()能立即连接成功,则返回0;如果此刻不能立即连接成功,则返回-1(windows上返回SOCKET_ERROR也等于-1),这个时候错误码是WSAEWOULDBLOCK(windows平台),或者是EINPROGRESS(linux平台),表明立即暂时不能完成。
- 接着调用select()函数在指定的时间内检测socket是否可写,如果可写表明connect()连接成功。
需要注意的是:linux平台上connect()暂时不能完成返回-1,错误码可能是EINPROGRESS,也可能是由于被信号给中断了,这个时候错误码是:EINTR。这种情况也要考虑到;而在windows平台上除了用select()函数去检测socket是否可写,也可以使用windows平台自带的函数WSAAsyncSelect或WSAEventSelect来检测。
下面是代码:
/**
*@param timeout 连接超时时间,单位为秒
*@return 连接成功返回true,反之返回false
**/
bool CSocket::Connect(int timeout)
{
//windows将socket设置成非阻塞的方式
unsigned long on = 1;
if (::ioctlsocket(m_hSocket, FIONBIO, &on) < 0)
return false;
//linux将socket设置成非阻塞的方式
//将新socket设置为non-blocking
/*
int oldflag = ::fcntl(newfd, F_GETFL, 0);
int newflag = oldflag | O_NONBLOCK;
if (::fcntl(m_hSocket, F_SETFL, newflag) == -1)
return false;
*/
struct sockaddr_in addrSrv = { 0 };
addrSrv.sin_family = AF_INET;
addrSrv.sin_addr = htonl(addr);
addrSrv.sin_port = htons((u_short)m_nPort);
int ret = ::connect(m_hSocket, (struct sockaddr*)&addrSrv, sizeof(addrSrv));
if (ret == 0)
return true;
//windows下检测WSAEWOULDBLOCK
if (ret < 0 && WSAGetLastError() != WSAEWOULDBLOCK)
return false;
//linux下需要检测EINPROGRESS和EINTR
/*
if (ret < 0 && (errno != EINPROGRESS || errno != EINTR))
return false;
*/
fd_set writeset;
FD_ZERO(&writeset);
FD_SET(m_hSocket, &writeset);
struct timeval tv;
tv.tv_sec = timeout;
//可以利用tv_usec做更小精度的超时设置
tv.tv_usec = 0;
if (::select(m_hSocket + 1, NULL, &writeset, NULL, &tv) != 1)
return false;
return true;
}
二、非阻塞socket下如何正确的收发数据
这里不讨论阻塞模式下,阻塞模式下send和recv函数如果tcp窗口太小或没有数据的话都是阻塞在send和recv调用处的。对于收数据,一般的流程是先用select(windows和linux平台皆可)、WSAAsyncSelect()或WSAEventSelect()(windows平台)、poll或epoll_wait(linux平台)检测socket有数据可读,然后进行收取。对于发数据,;linux平台下epoll模型存在水平模式和边缘模式两种情形,如果是边缘模式一定要一次性把socket上的数据收取干净才行,也就是一定要循环到recv函数出错,错误码是EWOULDBLOCK。而linux下的水平模式或者windows平台上可以根据业务一次性收取固定的字节数,或者收完为止。还有个区别上文也说过,就是windows下发数据的代码稍微有点不同的就是不需要检测错误码是EINTR,只需要检测是否是WSAEWOULDBLOCK。代码如下:
用于windows或linux水平模式下收取数据,这种情况下收取的数据可以小于指定大小,总之一次能收到多少是多少:
bool TcpSession::Recv()
{
//每次只收取256个字节
char buff[256];
//memset(buff, 0, sizeof(buff));
int nRecv = ::recv(clientfd_, buff, 256, 0);
if (nRecv == 0)
return false;
inputBuffer_.add(buff, (size_t)nRecv);
return true;
}
如果是linux epoll边缘模式(ET),则一定要一次性收完:
bool TcpSession::RecvEtMode()
{
//每次只收取256个字节
char buff[256];
while (true)
{
//memset(buff, 0, sizeof(buff));
int nRecv = ::recv(clientfd_, buff, 256, 0);
if (nRecv == -1)
{
if (errno == EWOULDBLOCK || errno == EINTR)
return true;
return false;
}
//对端关闭了socket
else if (nRecv == 0)
return false;
inputBuffer_.add(buff, (size_t)nRecv);
}
return true;
}
用于linux平台发送数据:
bool TcpSession::Send()
{
while (true)
{
int n = ::send(clientfd_, buffer_, buffer_.length(), 0);
if (n == -1)
{
//tcp窗口容量不够, 暂且发不出去,下次再发
if (errno == EWOULDBLOCK)
break;
//被信号中断,继续发送
else if (errno == EINTR)
continue;
return false;
}
//对端关闭了连接
else if (n == 0)
return false;
buffer_.erase(n);
//全部发送完毕
if (buffer_.length() == 0)
break;
}
return true;
}
另外,收发数据还有个技巧是设置超时时间,除了用setsocketopt函数设置send和recv的超时时间以外,还可以自定义整个收发数据过程中的超时时间,思路是开始收数据前记录下时间,收取完毕后记录下时间,如果这个时间差大于超时时间,则认为超时,代码分别是:
long tmSend = 3*1000L;
long tmRecv = 3*1000L;
setsockopt(m_hSocket, IPPROTO_TCP, TCP_NODELAY,(LPSTR)&noDelay, sizeof(long));
setsockopt(m_hSocket, SOL_SOCKET, SO_SNDTIMEO,(LPSTR)&tmSend, sizeof(long));
int httpclientsocket::RecvData(string& outbuf,int& pkglen)
{
if(m_fd == -1)
return -1;
pkglen = 0;
char buf[4096];
time_t tstart = time(NULL);
while(true)
{
int ret = ::recv(m_fd,buf,4096,0);
if(ret == 0)
{
Close();
return 0;//对方关闭socket了
}
else if(ret < 0)
{
if(errno == EAGAIN || errno ==EWOULDBLOCK || errno == EINTR)
{
if(time(NULL) - tstart > m_timeout)
{
Close();
return 0;
}
else
continue;
}
else
{
Close();
return ret;//接收出错
}
}
outbuf.append(buf,buf+ret);
pkglen = GetBufLen(outbuf.data(),outbuf.length());
if(pkglen <= 0)
{//接收的数据有问题
Close();
return pkglen;
}
else if(pkglen <= (int)outbuf.length())
break;//收够了
}
return pkglen;//返回该完整包的长度
}
三、如何获取当前socket对应的接收缓冲区中有多少数据可读
Windows上可以使用ioctlsocket()这个函数,代码如下:
ulong bytesToRecv;
if (ioctlsocket(clientsock, FIONREAD, &bytesToRecv) == 0)
{
//在这里,bytesToRecv的值即是当前接收缓冲区中数据字节数目
}
linux平台我没找到类似的方法。可以采用我上面说的通用方法《非阻塞socket下如何正确的收发数据》来做。当然有人说可以这么写(我在linux man手册ioctl函数栏目上并没有看到这个函数可以使用FIONREAD这样的标志,不同机器可能也有差异,具体可不可以得需要你根据你的linux系统去验证):
ulong bytesToRecv;
if (ioctl(clientsock, FIONREAD, &bytesToRecv) == 0)
{
//在这里,bytesToRecv的值即是当前接收缓冲区中数据字节数目
}
四、上层业务如何解析和使用收到的数据包?
这个话题实际上是继上一个话题讨论的。这个问题也可以回答常用的面试题:如何解决数据的丢包、粘包、包不完整的问题。首先,因为tcp协议是可靠的,所以不存在丢包问题,也不存在包顺序错乱问题(udp会存在这个问题,这个时候需要自己使用序号之类的机制保证了,这里只讨论tcp)。一般的做法是先收取一个固定大小的包头信息,接着根据包头里面指定的包体大小来收取包体大小(这里“收取”既可以从socket上收取,也可以在已经收取的数据缓冲区里面拿取)。举个例子:
#pragma pack(push, 1)
struct msg
{
int32_t cmd; //协议号
int32_t seq; //包序列号(同一个请求包和应答包的序列号相同)
int32_t packagesize; //包体大小
int32_t reserved1; //保留字段,在应答包中内容保持不变
int32_t reserved2; //保留字段,在应答包中内容保持不变
};
/**
* 心跳包协议
**/
struct msg_heartbeat_req
{
msg header;
};
struct msg_heartbeat_resp
{
msg header;
};
/**
* 登录协议
**/
struct msg_login_req
{
msg header;
char user[32];
char password[32];
int32_t clienttype; //客户端类型
};
struct msg_login_resp
{
msg header;
int32_t status;
char user[32];
int32_t userid;
};
#pragma pack(pop)
看上面几个协议,拿登录请求来说,每次可以先收取一个包头的大小,即sizeof(msg),然后根据msg.packagesize的大小再收取包体的大小sizeof(msg_login_req) - sizeof(msg),这样就能保证一个包完整了,如果包头或包体大小不够,则说明数据不完整,继续等待更多的数据的到来。
因为tcp协议是流协议,对方发送10个字节给你,你可能先收到5个字节,再收到5个字节;或者先收到2个字节,再收到8个字节;或者先收到1个字节,再收到9个字节;或者先收到1个字节,再收到7个字节,再收到2个字节。总之,你可能以这10个字节的任意组合方式收取到。所以,一般在正式的项目中的做法是,先检测socket上是否有数据,有的话就收一下(至于收完不收完,上文已经说了区别),收好之后,在收到的字节中先检测够不够一个包头大小,不够下次收数据后再检测;如果够的话,再看看够不够包头中指定的包体大小,不够下次再处理;如果够的话,则取出一个包的大小,解包并交给上层业务逻辑。注意,这个时候还要继续检测是否够下一个包头和包体,如此循环下去,直到不够一个包头或者包体大小。这种情况很常见,尤其对于那些对端连续发数据包的情况下。
五、nagle算法
nagle算法的是操作系统网络通信层的一种发送数据包机制,如果开启,则一次放入网卡缓冲区中的数据(利用send或write等)较小时,可能不会立即发出去,只要当多次send或者write之后,网卡缓冲区中的数据足够多时,才会一次性被协议栈发送出去,操作系统利用这个算法减少网络通信次数,提高网络利用率。对于实时性要求比较高的应用来说,可以禁用nagle算法。这样send或write的小数据包会立刻发出去。系统默认是开启的,禁用方法如下:
long noDelay = 1;
setsockopt(m_hSocket, IPPROTO_TCP, TCP_NODELAY,(LPSTR)&noDelay, sizeof(long));
noDelay为1禁用nagle算法,为0启用nagle算法。
六、select函数的第一个参数问题
select函数的原型是:
int select(
_In_ int nfds,
_Inout_ fd_set *readfds,
_Inout_ fd_set *writefds,
_Inout_ fd_set *exceptfds,
_In_ const struct timeval *timeout
);
使用示例:
fd_set writeset;
FD_ZERO(&writeset);
FD_SET(m_hSocket, &writeset);
struct timeval tv;
tv.tv_sec = 3;
tv.tv_usec = 100;
select(m_hSocket + 1, NULL, &writeset, NULL, &tv)
无论linux还是windows,这个函数都源于Berkeley 套接字。其中readfds、writefds和exceptfds都是一个含有socket描述符句柄数组的结构体。在linux下,第一个参数必须设置成这三个参数中,所有socket描述符句柄中的最大值加1;windows虽然不使用这个参数,却为了保持与Berkeley 套接字兼容,保留了这个参数,所以windows平台上这个参数可以填写任意值。
七、关于bind函数的绑定地址
使用bind函数时,我们需要绑定一个地址。示例如下:
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = inet_addr(ip_.c_str());
servaddr.sin_port = htons(port_);
bind(listenfd_, (sockaddr *)&servaddr, sizeof(servaddr));
这里的ip地址,我们一般写0.0.0.0(即windows上的宏INADDR_ANY),或者127.0.0.1。这二者还是有什么区别?如果是前者,那么bind会绑定该机器上的任意网卡地址(特别是存在多个网卡地址的情况下),如果是后者,只会绑定本地回环地址127.0.0.1。这样,使用前者绑定,可以使用connect去连接任意一个本地的网卡地址,而后者只能连接127.0.0.1。举个例子:
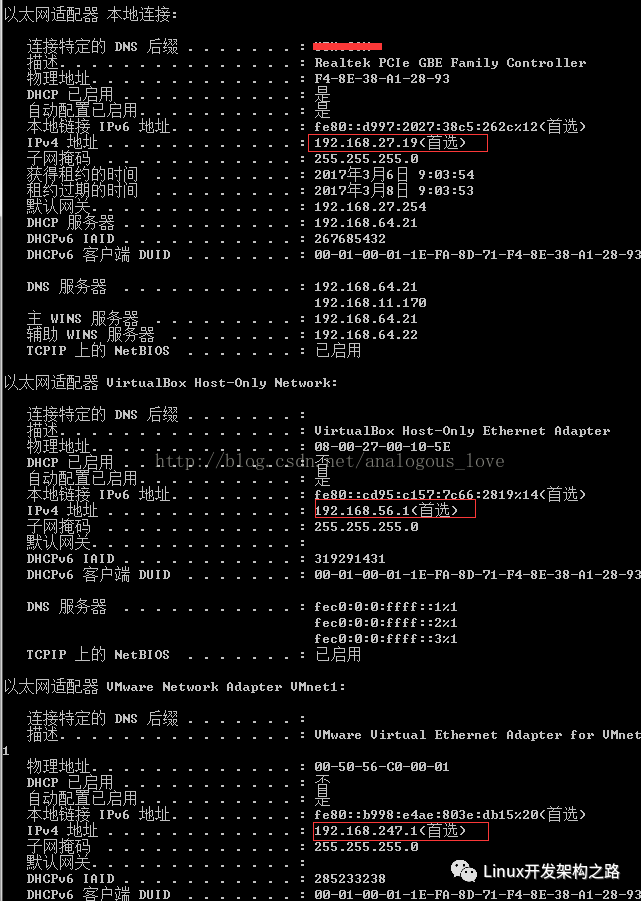
上文中,机器有三个网卡地址,如果使用bind到0.0.0.0上的话,则可以使用192.168.27.19或 192.168.56.1或 192.168.247.1任意地址去connect,如果bind到127.0.0.1,则只能使用127.0.0.1这个地址去connect。
八、关于SO_REUSEADDR和SO_REUSEPORT
使用方法如下:
int on = 1;
setsockopt(listenfd_, SOL_SOCKET, SO_REUSEADDR, (char *)&on, sizeof(on));
setsockopt(listenfd_, SOL_SOCKET, SO_REUSEPORT, (char *)&on, sizeof(on));
这两个socket选项,一般服务器程序用的特别多,主要是为了解决一个socket被系统回收以后,在一个最大存活期(MSL,大约2分钟)内,该socket绑定的地址和端口号不能被重复利用的情况。tcp断开连接时,需要进行四次挥手,为了保证最后一步处于time_wait状态的socket能收到ACK应答,操作系统将socket的生命周期延长至一个MSL。但是这对于服务器程序来说,尤其是重启的情况下,由于重启之后,该地址和端口号不能立刻被使用,导致bind函数调用失败。所以开发者要不变更地址和端口号,要不等待几分钟。这其中任意一个选择都无法承受的。所以可以设置这个选项来避免这个问题。
但是windows上和linux上实现稍有差别,windows上是一个socket回收后,在MSL期间内,其使用的地址和端口号组合其他进程不可以使用,但本进程可以继续重复利用;而linux实现是所有进程在MSL期间内都不能使用,包括本进程。
九、心跳包机制
为了维持一个tcp连接的正常,通常一个连接长时间没有数据来往会被系统的防火墙关闭。这个时候,如果再想通过这个连接发送数据就会出错,所以需要通过心跳机制来维持。虽然tcp协议栈有自己的keepalive机制,但是,我们应该更多的通过应用层心跳包来维持连接存活。那么多长时间发一次心跳包合适呢?在我的过往项目经验中,真是众说纷纭啊,也因此被坑了不少次。后来,我找到了一种比较科学的时间间隔:
先假设每隔30秒给对端发送一个心跳数据包,这样需要开启一个定时器,定时器是每过30秒发送一个心跳数据包。
除了心跳包外,与对端也会有正常的数据来往(非心跳包数据包),那么记下这些数据的send和recv时刻。也就是说,如果最近的30秒内,发送过或者收到过非心跳包外的数据包,那么30秒后就不要发心跳包数据。也就是说,心跳包发送一定是在两端没有数据来往后的30秒才需要发送。这样不仅可以减轻服务器的压力,同时也减少了网络通信流量,尤其对于流量昂贵的移动设备。
当然,心跳包不仅可以用来维持连接正常,也可以携带一些数据,比如定期得到某些数据的最新值,这个时候,上面的方案可能就不太合适了,还是需要每隔30秒发送一次。具体采取哪种,可以根据实际的项目需求来决定。
另外,需要补充一点的时,心跳包一般由客户端发给服务器端,也就是说客户端检测自己是否保持与服务器连接,而不是服务器主动发给客户端。用程序的术语来讲就是调用connect函数的一方发送心跳包,调用listen的一方接收心跳包。
拓展一下,这种思路也可以用于保持与数据库的连接。比如在30秒内没有执行数据库操作后,定期执行一条sql,用以保持连接不断开,比如一条简单的sql:select 1 from user;
十、重连机制
在我早些年的软件开发生涯中,我用connect函数连接一个对端,如果连接不上,那么我会再次重试,如果还是连接不上,会接着重试。如此一直反复下去,虽然这种重连动作放在一个专门的线程里面(对于客户端软件,千万不要放在UI线程里面,不然你的界面将会卡死)。但是如果对端始终连不上,比如因为网络断开。这种尝试其实是毫无意义的,不如不做。其实最合理的重连方式应该是结合下面的两种方案:
- 如果connect连接不上,那么n秒后再重试,如果还是连接不上2n秒之后再重试,以此类推,4n,8n,16n......
但是上述方案,也存在问题,就是如果当重试间隔时间变的很长,网络突然畅通了,这个时候,需要很长时间才能连接服务器,这个时候,就应该采取方法2。
- 在网络状态发生变化时,尝试重连。比如一款通讯软件,由于网络故障现在处于掉线状态,突然网络恢复了,这个时候就应该尝试重连。windows下检测网络状态发生变化的API是IsNetworkAlive。示例代码如下:
BOOL IUIsNetworkAlive()
{
DWORD dwFlags; //上网方式
BOOL bAlive = TRUE; //是否在线
bAlive = ::IsNetworkAlive(&dwFlags);
return bAlive;
}
十一、关于错误码EINTR
这个错误码是linux平台下的。对于很多linux网络函数,如connect、send、recv、epoll_wait等,当这些函数出错时,一定要检测错误是不是EINTR,因为如果是这种错误,其实只是被信号中断了,函数调用并没用出错,这个时候要么重试,如send、recv、epoll_wait,要么利用其他方式检测完成情况,如利用select检测connect是否成功。千万不要草草认定这些调用失败,而做出错误逻辑判断。
十二、尽量减少系统调用
对于高性能的服务器程序来说,尽量减少系统调用也是一个值得优化的地方。每一次系统调用就意味着一次从用户空间到内核空间的切换。例如,在libevent网络库,在主循环里面,对于时间的获取是一次获取后就立刻缓存下来,以后如果需要这个时间,就取缓存的。但是有人说,在x86机器上gettimeofday不是系统调用,所以libevent没必要这么做。有没有必要,我们借鉴一下这个减少系统调用的思想而已。
十三、忽略linux信号SIGPIPE
SIGPIPE这个信号针对linux平台的,什么情况下会产生这个信号呢?在 TCP 通信双方中,为了描述方便,以下将通信双方用 A 和 B 代替。当 A “关闭”连接时,若 B 继续给 A 发数据,根据 TCP 协议的规定,B 会收到 A 的一个 RST 报文响应,如 B 继续再往这个服务器发送数据,系统会产生一个 SIGPIPE 信号给该 B 进程,告诉该进程这个连接已经断开了,不要再写了。系统对 SIGPIPE 信号的默认处理行为是让 B 进程退出。
所以应该捕获或者忽略掉这个信号,忽略该信号的代码如下:
signal(SIGPIPE, SIG_IGN);
-
WINDOWS
+关注
关注
3文章
3541浏览量
88623 -
函数
+关注
关注
3文章
4327浏览量
62571 -
网络编程
+关注
关注
0文章
71浏览量
10074 -
非阻塞
+关注
关注
0文章
13浏览量
2170
发布评论请先 登录
相关推荐
Verilog语言中阻塞和非阻塞赋值的不同
Verilog阻塞和非阻塞原理分析
linux串口通信阻塞与非阻塞问题。
verilog中阻塞赋值和非阻塞赋值
简述阻塞赋值和非阻塞赋值的可综合性
简述Verilog HDL中阻塞语句和非阻塞语句的区别








 工商网监
工商网监
评论