 阿里云大面积宕机,淘宝、饿了么等多产品“崩了”,机房运行面临四大挑战
阿里云大面积宕机,淘宝、饿了么等多产品“崩了”,机房运行面临四大挑战
电子发烧友网报道(文/吴子鹏)11月12日下午,就在双十一大促的后一天,阿里云疑似发生大规模、大范围故障,导致包括淘宝、闲鱼、阿里云盘、钉钉在内的阿里系产品全线崩溃。一时间,“阿里云盘崩了”“淘宝又崩了”“钉钉崩了”和“闲鱼崩了”等多条相关词条进入微博热搜榜。
12日晚8点,阿里方面发布官方消息称,19:20左右,经工程师紧急处理,阿里旗下淘宝、钉钉、阿里云盘等APP已全面恢复。
根据群公告和官方信息,此次阿里云系统宕机的时间线为:
·17时44分起,阿里云产品控制台访问及API调用出现使用异常,阿里云工程师开始紧急介入排查;
·17时50分,阿里云已确认故障原因与某个底层服务组件有关,工程师紧急处理中;
·18时54分,经过阿里工程师处理,杭州、北京等地域控制台已恢复,其他地域控制台服务逐步恢复中;
·19时20分,阿里工程师通过分批重启组件服务,绝大部分地域控制台服务已恢复访问;
·19时43分,异常管控服务组件均已完成重启,除个别云产品(如消息队列MQ、消息服务MNS)仍需处理,其余云产品控制台及API服务已恢复;
·20时12分,北京、杭州等地域消息队列MQ已完成重启,其余地域逐步恢复中;
·21时11分,受影响云产品均已恢复,因故障影响部分云产品的数据(如监控、账单等)可能存在延迟推送情况,不影响业务运行。
此次宕机波及甚广
上面的词条可能有细心的网友已经发现,“淘宝又崩了”这个词条多了一个又字。近两年,几乎每年都有“淘宝崩了”进入微博热搜榜。
2021年10月20日晚间,由于双十一改成了“八点档”而不再是零点开售,所以很多人开始在此时蹲守,准备“褥羊毛”,或者趁着便宜买自己需要的东西。然而,预售刚开始就有网友反馈给客服发消息发不出去。原因就是服务器系统受不了如此巨大的访问量,崩溃了。随后,淘宝官方账号在当天20时43分的时候回复称,原来不熬夜的你们这么猛吗?
2022年7月12日晚间,“淘宝崩了”再次上热搜,据多名网友反映,他们在购买商品时突然遇到了卡顿的情况。针对这一次的情况,淘宝官方账号表示:平台正常。
当然,阿里云也不是第一次发生规模性故障了。2022年12月,阿里云香港地域发生长时间持续性故障,服务中断一度超过12小时,这是阿里云运营十多年来持续时间最长的一次大规模故障。2022年12月25日,阿里云在官方微信发布《关于阿里云香港Region可用区C服务中断事件的说明 》。其中提到,12月18日,由于香港Region可用区C机房冷却系统失效,包间温度逐渐升高,导致一机房包间温度达到临界值触发消防系统喷淋,电源柜和多列机柜进水,部分机器硬件损坏。整个处置过程超过10小时。
虽然这一次阿里云的故障处置没有香港那么久,不过从上面的时间线也能够看出,基本上也是花费了一个半小时才做到绝大部分地域的正常访问。并且,此次系统宕机的影响范围远超上一次阿里云香港地域故障。
阿里云公告显示,国内包括华北2 (北京)、华北6 (乌兰察布)、华南1(深圳)、中国香港、华东1(杭州)等节点受到影响;国际市场包括英国(伦敦)、韩国(首尔)、日本(东京)、阿联酋(迪拜)、美国 (弗吉尼亚)、菲律宾 (马尼拉)、新加坡等节点受到影响。
阿里云公告显示,受影响的主要产品包括OSS、OTS、SLS、MNS等产品,大部分产品如ECS、RDS、网络等运营正常。这些受影响的产品包括企业级分布式应用服务、云原生大数据计算服务MaxCompute、云存储网关、块存储、混合云备份服务、云原生内存数据库Tair、运维安全中心(堡垒机)、数据库备份、物联网平台、超级计算集群、弹性裸金属服务器、云服务器ECS、云呼叫中心、交通云控平台、客服工作台、视觉智能开放平台、运维事件中心和新零售智能助理等。
2022年12月,当阿里云香港地域节点发生故障时,有消息人士称,阿里云将此次故障定义为“p0级事故”。随后不久,时任阿里巴巴集团董事会主席兼CEO张勇发出全员邮件称,自己将兼任阿里云智能总裁,取代原总裁张建锋。
如今,最新的故障虽然时间没有那么长,但是波及面实在是太大了,不知道阿里云是否会继续自己的铁血管理风格。
机房运转的四大挑战
我们都知道,云计算是互联网的核心支撑技术之一。根据Gartner相关统计数据,2022年以IaaS、PaaS、SaaS 为代表的全球云计算市场规模为 4910亿美元,同比增长19%,虽然增速有所降低,不过市场需求依然强劲。这表明,虽然有经济下行和通胀的压力存在,云计算依然是未来的重要发展趋势和实现新科技的重要手段,预计全球云计算市场规模会在2026年突破万亿美元级别。
在市场份额方面,IDC的数据显示,在公有云IaaS市场,2022年全球前四名云厂商依次为亚马逊、微软、谷歌和阿里云,其中阿里云的市场份额为5.2%。当然,如果仅统计中国企业或MNC使用国内公有云资源的业务,阿里云是当之无愧的市场第一,2022年上半年的占比高达37.2%。
这些大的云计算企业基本每年都会规模性故障,比如2022年7月,因遭遇极端高温天气,甲骨文和谷歌在伦敦的数据中心也曾因冷却系统出现问题而发生运行故障,导致部分网站瘫痪。
综合而言,作为云计算的硬件底层,机房主要会遇到四大方面的挑战,分别来自环境、电力、硬件和软件。
机房会遇到的环境挑战非常多,首当其冲就是高温,上述甲骨文和谷歌的机房故障就是因为高温,一旦温度负荷超过降温系统的极限,宕机是不可避免的。除了高温之外,湿度过高、震动、灰尘和自然灾害等,都会对机房的运行造成很大的干扰。
机房的电力问题有时来自外部,有时则是内部。外部原因主要是供电系统突发故障,非预期性断电是最常见的故障;内部原因则主要是初期规划问题,有时候可能是对于服务器更新换代带来的用电增长估计不足,有时候可能是成本压力没有备用设备。
第三个挑战是硬件本身的问题,机房的主要硬件设备包括服务器、交换机、路由器、硬件网关、硬件防火墙、交/直流电源、冷却系统和监控系统。这是一套配合非常紧密的硬件系统,某一类设备故障和设备老化都有可能造成机架大面积瘫痪。
最后一个挑战则来自软件。在服务领域,软件负责整个系统的监管、调度,同时软件还能够提升服务器集群的性能、安全性和可扩展性,当然服务器上的软件本身也是一种服务。软件端造成冲击最常见的两种方式是数据访问量短时间剧增,以及软件升级和更新。
此次阿里云的故障来自产品控制台访问及API调用,实际上就是软件系统出了问题。对于这类问题,系统重启是最直接有效的方式,不过过程中需要对数据进行留存和保护。
小结
大数据时代一个重要的特征是越来越多的数据及相关服务汇集在科技巨头的设备上,一旦发生故障就会产生很大的波及范围,也就会引起广泛的关注。虽然大家都知道故障来自哪些方面,不过由于设备更新换代和系统升级的节奏太快,很多问题是很难具体化的,在爆发之前它们都是未知的。
-
阿里云
+关注
关注
3文章
944浏览量
42981
发布评论请先 登录
相关推荐
阿里云财报亮点:连续四季度增速上扬,利润猛增89%
无线终端ZWS云应用(四)-ZigBee网关&云智慧工厂行业应用

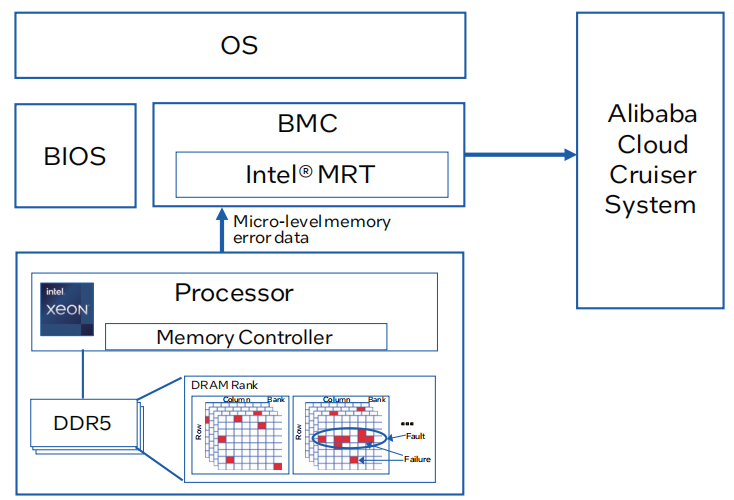
英特尔和阿里云开发DDR5内存故障预测和预防解决方案
破解大面积场景清洁难题,普渡推出AI智能扫地机器人PUDU MT1
阿里云设备的物模型数据里面始终没有值是为什么?
ESP32S3连接阿里云物联网平台LinkSDK报错怎么解决?
日本旭化成氮化铝基板技术突破:迈向更大面积与实用化

洲明科技携COB尖端产品、隧道照明等创新成果亮相“3号馆L310”






 工商网监
工商网监
评论