 Python网络爬虫Selenium的简单使用
Python网络爬虫Selenium的简单使用
Python网络爬虫-Selenium
想要学习爬虫,如果比较详细的了解web开发的前端知识会更加容易上手,时间不够充裕,仅仅了解html的相关知识也是够用的。
准备工作:
使用它肯定先要安装它,对于Selenium的安装推荐使用pip,十分方便。因为我使用的是谷歌浏览器,使用前需要先配置相应的ChromeDriver,在此放出对应谷歌浏览器对应的80版本的ChromeDriver。地址 :点击下载提取码:sz2s
至于如何去安装配置,网络上有很多教程,在此不做赘述。
简要功能:
使用Selenium可以驱动浏览器执行特定操作,如点击,下拉等等,同时也能直接抓取网页源代码,即做到可见即可爬。
1.访问页面
通过下面这几行代码可以实现浏览器的驱动并获取网页源码,非常便捷。
from selenium import webdriver
browser = webdriver.Chrome() #声明浏览器对象
browser.get('https://www.baidu.com')
print(browser.page_source) #打印网页源码
browser.close() #关闭浏览器
2.查找节点
selenium可以驱动浏览器完成各种操作,但进行模拟点击,填写表单时,我们总要知道这些输入框,点击按钮在哪里,所以需要获取相对的节点。总共有其中寻找节点的方法,在此给出一个非常全面的学习查找节点的教程。
=单个节点=
下面以百度首页为例。通过查找源码,我们可以发现对应搜索文本框的class,name,id等属性名。
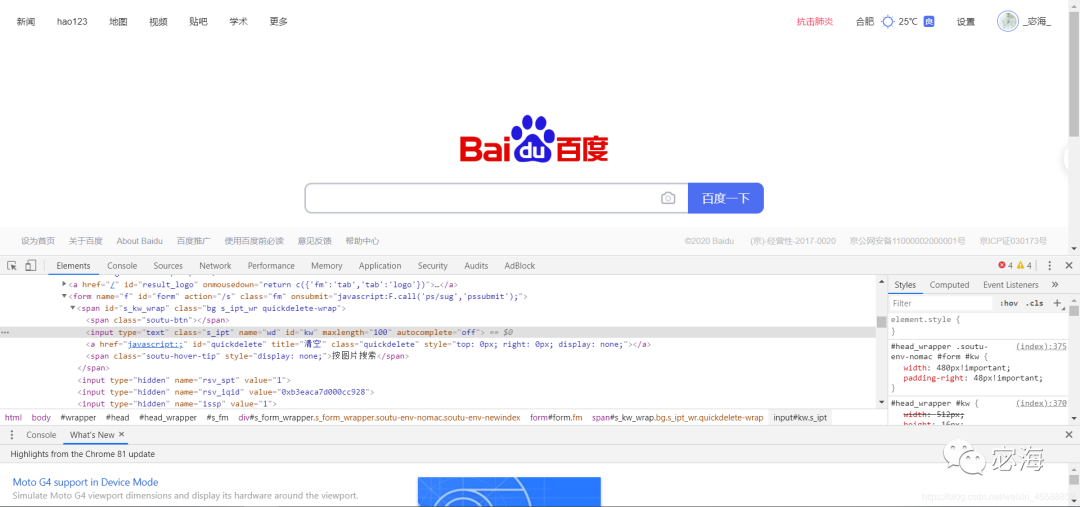
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw') #获取搜索框位置
input.send_keys('Python') #输入内容
运行代码得到如下内容,此时我们只是输入,并未进行其他操作。

=多个节点=
如果查找目标在网页中只有一个,使用find_element()方法就可了。如果有多个,举个例子,如查找多个满足条件的节点,通过html基本知识我们可以知道元素对应的id名是唯一的,像是其他的class等可以多次出现,其中对应的满足条件的倘若还用一开始的方法便只能得到第一个节点的内容,后面就不能得到,因此可以使用find_elements()。
3.节点交互
意思就是让浏览器模拟执行一些动作,常用的有:输入文字用send_keys(),清空文字用clear(),点击用click()。放个小实例。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
time.sleep(1) #等待时间设置为1秒,方便查看
input.clear() #清空搜索框
input.send_keys('LOL')
button = browser.find_element_by_id('su')
button.click() #模拟点击
4.获取节点信息
因为selenium的page_source属性可以直接获取网页源码,接着就可以直接使用解析库(如正则表达式,Beautiful Soup等)直接提取信息,不过Selenium已经直接提供了选择节点的方法了,返回的是WebElement类型,它也有相关的方法提取节点信息,如文本,属性等。这也是使用它进行一点简单的爬虫非常方便的原因,代码十分简洁。
=提取属性=
使用get_attribute()方法,但前提需要先选中节点,同样以百度首页为实例,打印出百度logo的属性。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('s_lg_img')
print(input)
print(input.get_attribute("class"))
'''打印结果
< selenium.webdriver.remote.webelement.WebElement (session="6013549f22f653cf081e0564da8315da", element="a924de49-358c-42e1-8c29-09bf0dd8d3c3") >
index-logo-src
'''
=获取文本值=
每个WebElement节点都有text属性,直接调用这个属性就可以获得节点内的内容,这相当于Beautiful Soup中的get_text()方法。这里打开百度首页,获取搜索按钮的百度一下文本。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('su')
print(input.text)
=获取id、位置、标签名和大小=
id属性获取节点id
location属性可以获取该节点在页面中的相对位置
tag_name属性获取标签名称
size属性获取节点大小,就是宽高
5.延时等待
当我们进行网络爬虫时,请求的东西或许不会第一时间出现,此时就会抛出时间异常,因此我们需要加上延时等待避免程序中断。这里面分为显式等待和隐式等待,具体详细教程参考链接: link.
6.异常处理
进行爬虫难免会遇到异常,如超时,节点未找到等错误,此时用try except语句捕获异常,可以避免程序因此中断。
关于Selenium其他的函数如对网页节点进行拖拽,切换标签页,前进与后退,选项卡管理以及对cookies相关的操作等不做详细说明,上面的知识足以进行简单的爬虫了,像是各大网页的文本值都可以很简单的抓取下来,可以做一点简单的数据分析。当然这仅对初学者是这样的,后期稍微深入会遇到需要这些函数的操作,对于小白这些就够了。
-
python
+关注
关注
55文章
4766浏览量
84361 -
异常中断
+关注
关注
0文章
9浏览量
1205
发布评论请先 登录
相关推荐
详细解读爬虫多开代理IP的用途,以及如何配置!
使用Python批量连接华为网络设备
用pycharm进行python爬虫的步骤
如何使用Python进行神经网络编程
常见的数据采集工具的介绍
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
python自带的idle怎么进入
python软件怎么运行代码
python最简单for循环例子
Python中使用selenium的准备工作






 工商网监
工商网监
评论