 论AI的系统厂商vs系统厂商的AI
论AI的系统厂商vs系统厂商的AI
01
前 言
10月初Dell在Austin的一个event “Bring AI to Your Data”宣传上,科技媒体65请了Dell 的一个VP来讨论,在讨论中一向比较直接的Patrick就问了一个所有系统厂商的灵魂问题:“Dell 在AI的软件和算法上没有投入,在AI加速的芯片上也没有投入,你们在谈AI到底在谈啥?”。好在是VP比较机灵,先谈“Dell是个大公司,客户多,很多客户不知道AI是个啥,Dell可以提供H100的GPU服务器,然后就是AI肯定要存储的,因为大数据要靠AI,数据的保护和管理,bablbabl.。.“。说实在的,如果AI的数据真的很重要的话。Samsung和Seagate应该是世界上市值最高的AI公司了。关心股市的同学知道,在这个宇宙中并不是。
俺是正统的系统厂商出身,毕业实习的时候在华腾(就是那个天腾和华东计算机所合资)做系统集成,很巧的是在俺公司现址的楼下,一天被当年带的新毕业生认出来,当年的毕业生已经是华腾的CTO了,在华腾工作了24年,从系统集成公司进化成上万人外包的大公司了。其实,在X86兴起的200X年代,互联网还在融资,系统集成公司的日子还是不错的,企业客户都面临这个信息化这个话题,系统集成公司是软硬一体的,可以像Dell今天满足客户AI需求一样满足客户的信息化需求。
当互联网兴起之后,系统集成公司的日子基本上到头了,互联网只要硬件,人家有的是软件工程师。后面,随着SSD出现,高速网络出现, intel手下的系统公司基本上被台厂,后面被互联网的系统部全部踢出局了。当然,俺早早的跳出这个领域,向下做到了SSD部件厂商,以至于前一段一个哥们问我服务器还是啥搞头,俺可是在联想,Dell做了快10年的服务器的人,居然真的想不出来服务器还能有啥花头。
02
缘 起
回到正题, AI从2012年开始,基本上起起伏伏快10年了,在Nvidia面临游戏和加密货币的下滑的双重打击下,GPTx异军突起,让老黄放飞了自我。就像前面讲的一样,AI的投资基本上在AI的网络算法和AI加速器两个方向。为啥这次LLM只是火了AI算法,但是一票AI加速器公司反而悄无声息?原因也很简单,就像在Meta做AI Infra的Dr. Kim Hazelwood讲的一样,在AI的框架世界中,高效的框架是打不过好用的框架的,因为对算法工程来讲,2小时和12小时没有区别,反正下班前提交了,只要明天上班的时候能出来就行。
因此,在AI框架的竞争中,Pytorch战胜了TensorFlow【1】。
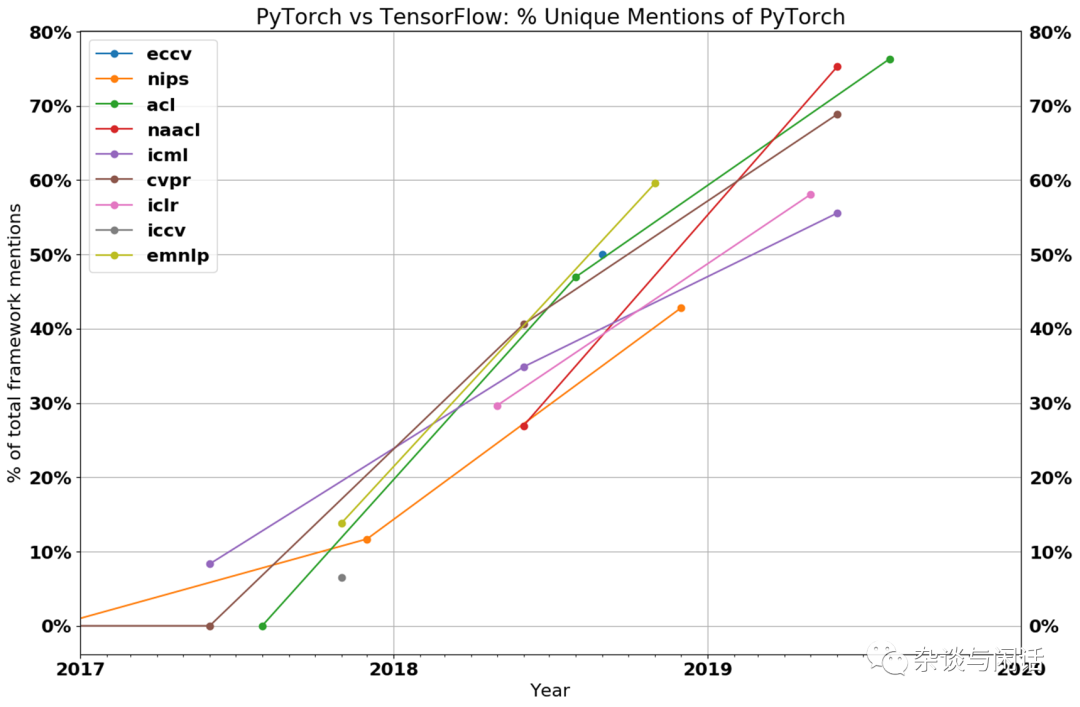
对了,Pytorch就是Meta的,前面的计算机科学家Kim的评论(2020)圆满了。而Pytorch的特点就是好用,有2000+ 算子,这个对于AI加速器来讲就是灭顶之灾。之前那些学Google TPU做脉动整列的,做Tensor/Vector加速的startup基本上被强大的CUDA打趴下了。
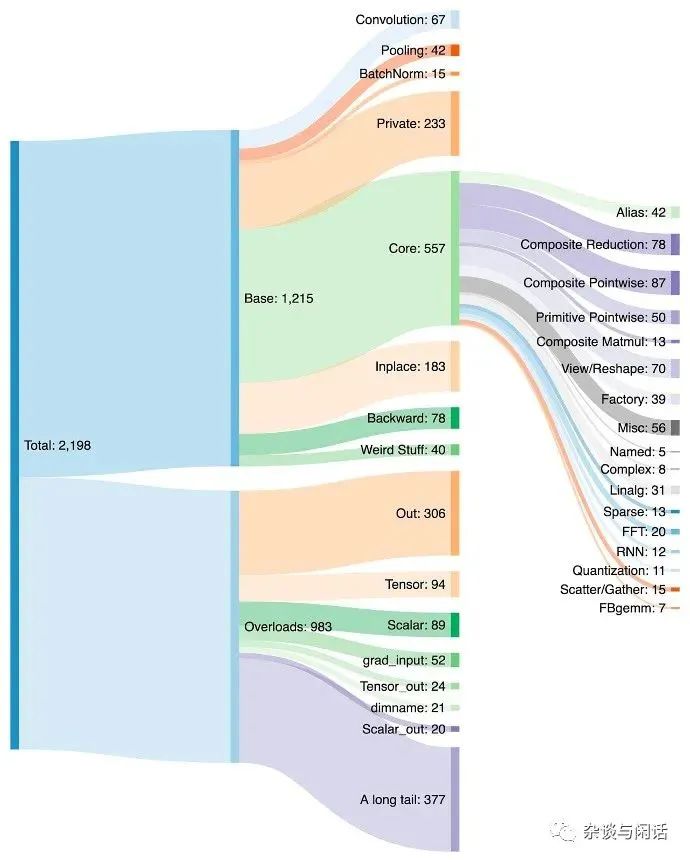
但是,如果是这样的话,就没有本文的标题了,在硅谷走老黄的路的公司基本都没有了,只有中国还在和A股互动炒作GPU的概念,而真正可以对标老黄的公司都不是走GPU的路线。反而是两家做可编程DataFlow的公司成为了热点,而且都是AI的系统公司。
03
Sambanova
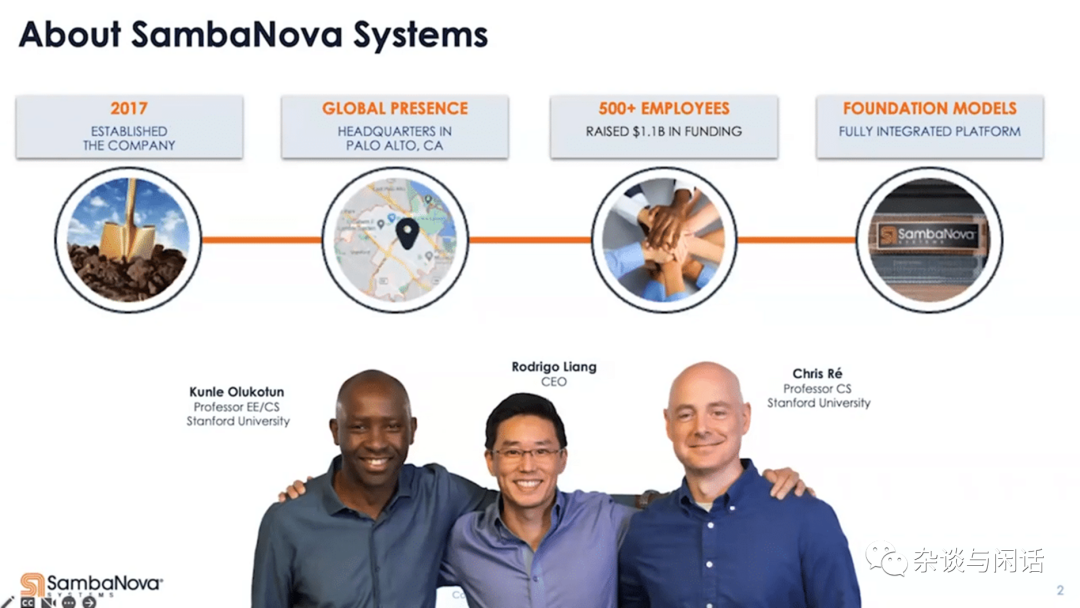
Kunle Olukotun的名号是“Father of The Mutil-Core Processor”,之前的公司是Afara Websystem,做最早的多核系统。

从这一页,看不懂Niagara的同学可以劝退了。看懂的童鞋可以点赞了。这么老的古董,现在散落在不同的公司的Sun可以缅怀一分钟。
另一个大佬是Chris,主要是做软件的,公司被Apple收购。

做多核CPU和做大数据管理的在一起,故事很直接。ML Application就是Software 2.0呀。

2019年回来的芯片很大很大,比GPU还大,725mm2。4个DDR4 controller支持1.5T。64Lane PCIe Gen4.0 做单机8卡互联。(不错,我们是I/O控)。

这张图说明了,2019年已经tapeout的片子,现在刚刚热起来。编译器的能力,特别是可编程的并行能力,需要时间呀。
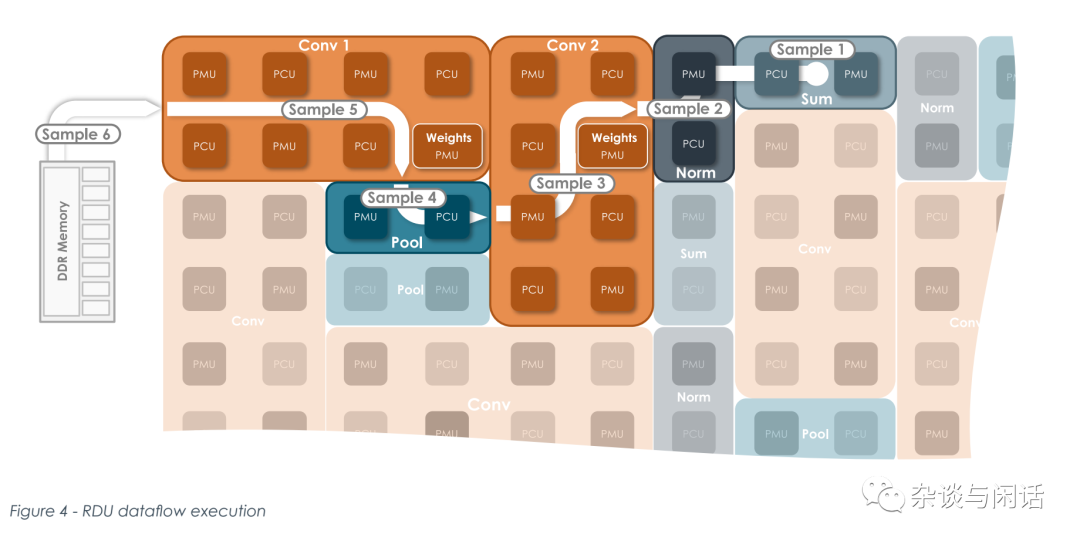
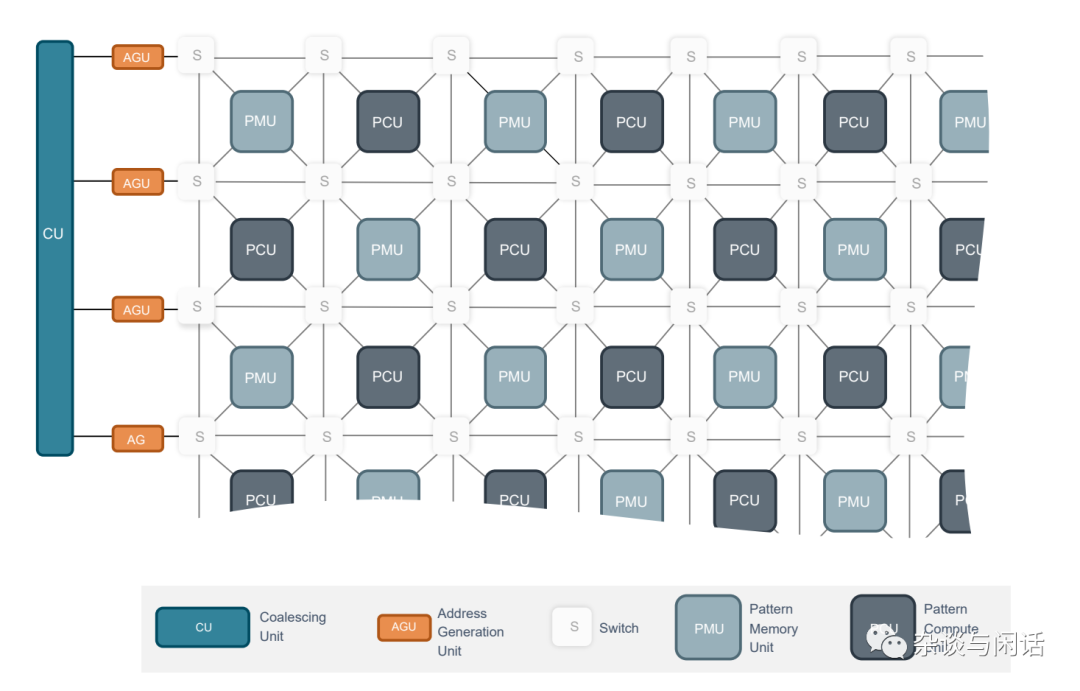
芯片上的主要部分,和大部分AI加速器类似,计算单元,SRAM做weight/gradient的保存, AGU和SU做数据路由,CU就是控制了。
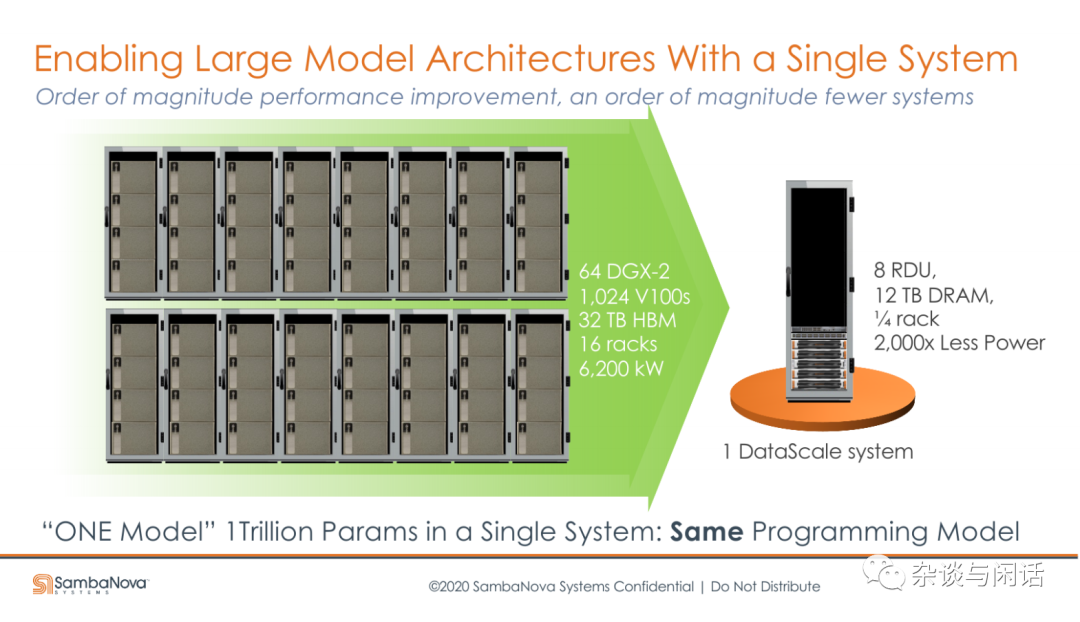
单机8卡,和老黄对标。

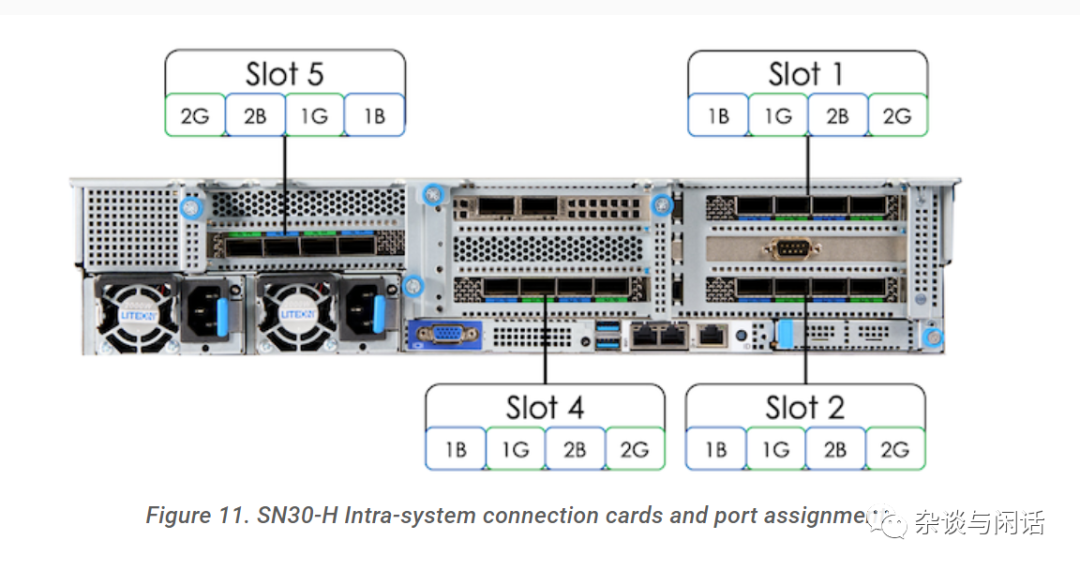
产品文档很全面,有自己的编译器和开发环境。硬件也是用AMD的PCIe的标准服务器带8个加速器。其中的HCI就是自己互联的方案,基于PCIe Gen4,从接口的形态看应该是4口一组的PCIe HBA类似。

HCI组网方式基本上就是full mesh,4个计算节点互联和头节点互联。 节点之间的连接还有用RoCEv2的Ethernet以及junper的交换机。只是HCI没有用PCIe switch,看cable做pointer to pointer的互联,可能和NVLinkv1一样,没有做NVSwitch。
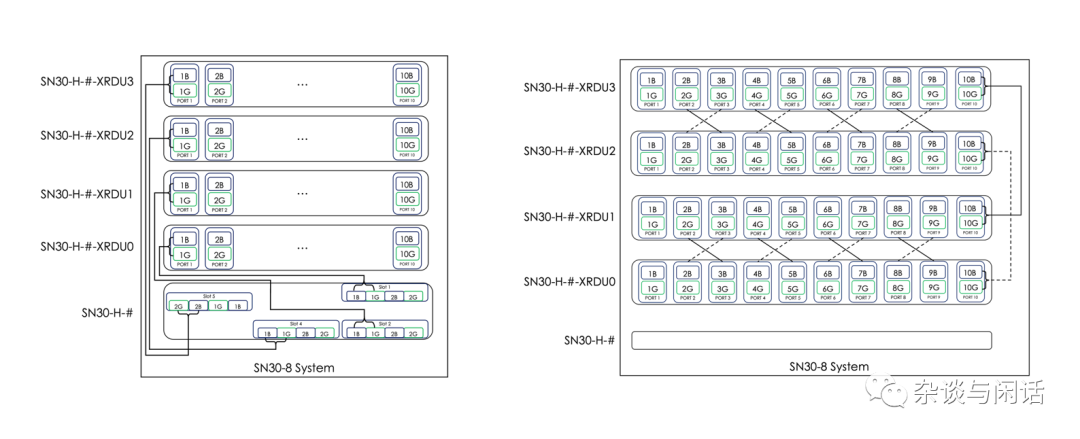
作为AI的系统厂商来讲,Sambanova还是很不错的,除了一些美国的国家实验室以外,还有一些做金融和文本处理的公司。而且关键是2代的芯片也回来了,支持HBM, 支持5T的LLMs【2】。

04
Cerebras
说到这家,必须讲它的出处 SeaMicro. 对,下图就是8个server在一个5X11英寸的PCB上。它是ARM进军数据中心的先烈,被AMD收购了,被Lisa SU杀死了。这种类型的板子,我当年在DCS的时候也搞过类似的低功耗MicroServer。

Cerebras的核心人物都是SeaMicro的背景。

关于Cerebas,正好之前有材料,这里就快速总结了。

通过RoCEv2的RDMA进行系统扩展。weight的存储和计算节点通过ethernet互联。
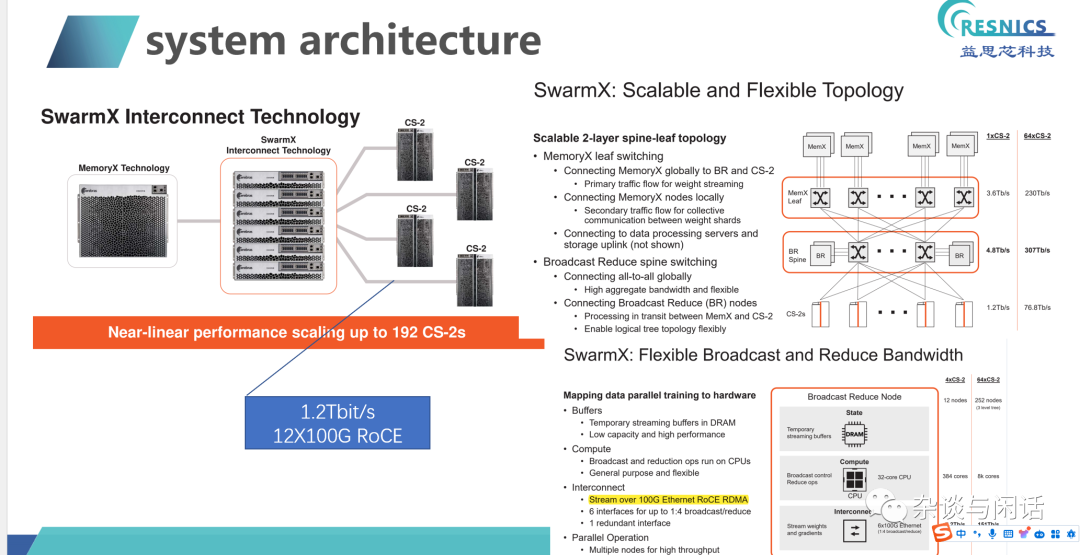
对于Weight节点独立,很好地解决了GPU因为内存不够出现的data 并行的问题,在大模型时代成了杀手锏。通过On-Chip Memory和MemoryX的流水线处理,很好地解决了之前GPU training中参数服务器的问题。

计算单元的设计还是软硬结合,编译器做调度编排,整个片子上网络没有中心的控制。
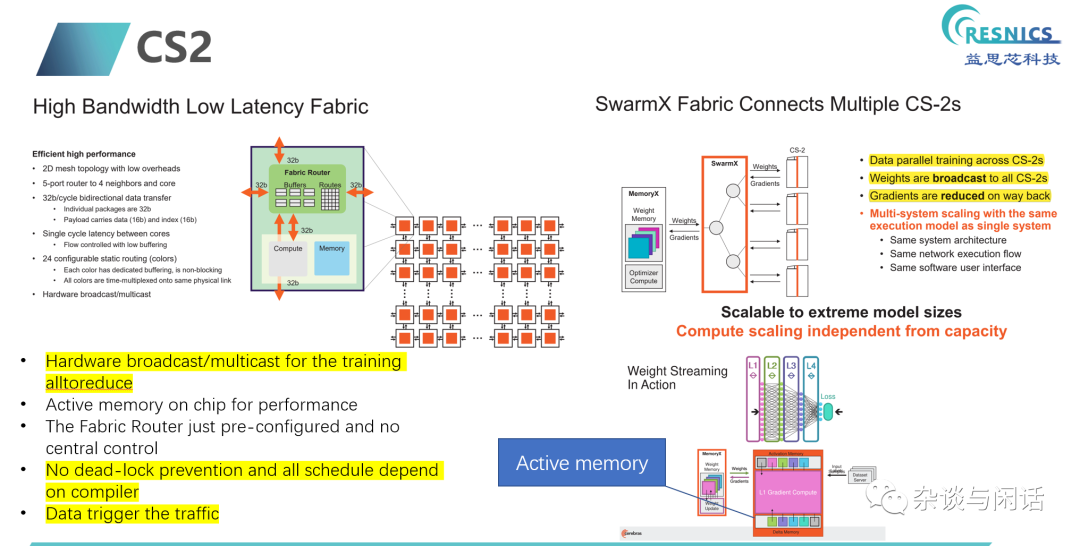
最后,在LLMs时代,Pytorch的胜利逻辑会继续。
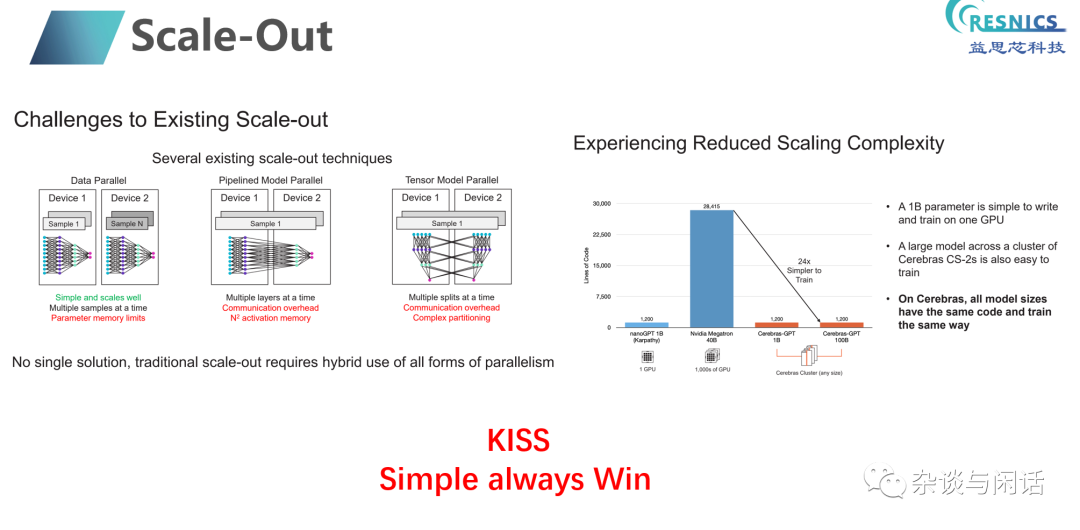
相对于Sambanova, 因为Cerebras的步子更大,不仅在国家实验室有落地,更加在LLMs时代找到了方向。
05
尾 声
在过去2016年AI的创业风潮起来之后,GPU的颠覆者到现在还没有出现,的确让人比较遗憾。后面的路会怎么走,我还是比较认可Andrej Karpathy的判断, Transformers可能会走上模型的统一。
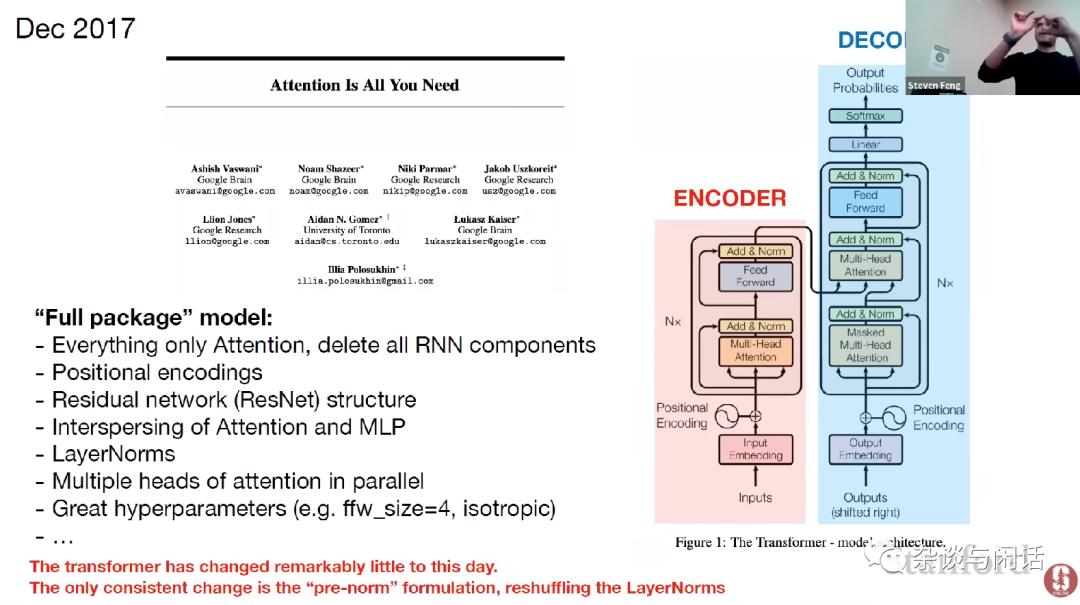
模型+数据+算力=ML Application, Chris指出的方向也许是AI创业公司盈利的方向???
回到正题,也许下一波就是AI公司成为AI系统厂商,或者系统厂商收购AI公司成为AI系统厂商的时代了。

-
互联网
+关注
关注
54文章
11153浏览量
103271 -
AI
+关注
关注
87文章
30830浏览量
268984 -
pytorch
+关注
关注
2文章
808浏览量
13219
原文标题:论AI的系统厂商 vs.系统厂商的AI
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论