 情感语音识别的研究方法与实践
情感语音识别的研究方法与实践

一、引言
情感语音识别是指通过计算机技术和人工智能算法自动识别和理解人类语音中的情感信息。为了提高情感语音识别的准确性,本文将探讨情感语音识别的研究方法与实践。
二、情感语音识别的研究方法
数据采集与预处理:首先需要采集包含情感变化的语音数据。通常采用专业的录音设备进行采集,并使用音频编辑软件进行预处理,如噪声消除、回声消除等。
特征提取:对预处理后的语音数据进行特征提取,提取出与情感相关的特征。常用的特征包括梅尔频率倒谱系数(MFCC)、线性预测系数(LPC)、倒谱系数(cepstral coefficients)等。
模型构建与训练:根据提取的特征构建情感语音识别模型,并使用已知标签的语音数据进行训练。常用的模型包括支持向量机(SVM)、朴素贝叶斯(Naive Bayes)、决策树(Decision Tree)等。
模型评估与优化:使用测试集对模型进行评估,通过调整模型参数和优化算法来提高模型的准确性。常用的评估指标包括准确率(accuracy)、召回率(recall)、F1得分等。
部署与测试:将优化后的模型部署到实际应用场景中进行测试,观察其在实际环境中的表现和性能。
三、情感语音识别的实践案例
使用MFCC特征和SVM模型进行情感分类:首先采集包含不同情感的语音数据,提取MFCC特征并使用SVM模型进行分类。通过调整SVM模型的参数,提高模型的准确性和泛化能力。
基于深度学习的多模态情感识别:使用卷积神经网络(CNN)或循环神经网络(RNN)等方法对语音信号进行自动编码和特征提取,结合面部表情、身体语言等多模态信息进行情感分类。这种方法能够更全面地分析用户的情感状态。
在线情感聊天机器人:通过使用情感语音识别技术,开发一个能够理解用户情感并作出相应回应的在线聊天机器人。该机器人可以通过分析用户的语音情感来提供个性化的建议和帮助。
审核编辑 黄宇
-
语音识别
+关注
关注
39文章
1820浏览量
116233
发布评论请先 登录
普强信息荣登2026语音识别技术公司TOP30榜单
语音识别芯片介绍,语音识别芯片工作原理解析
WTK6900系列离线语音识别芯片全面解析:从基础识别到鼾声哭声检测,一芯覆盖多场景

语音识别芯片的功能与优势有哪些

语音识别芯片有哪些(语音识别芯片AT680系列)
什么是离线语音识别芯片(离线语音识别芯片有哪些优点)
基于开源鸿蒙的语音识别及语音合成应用开发样例

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程

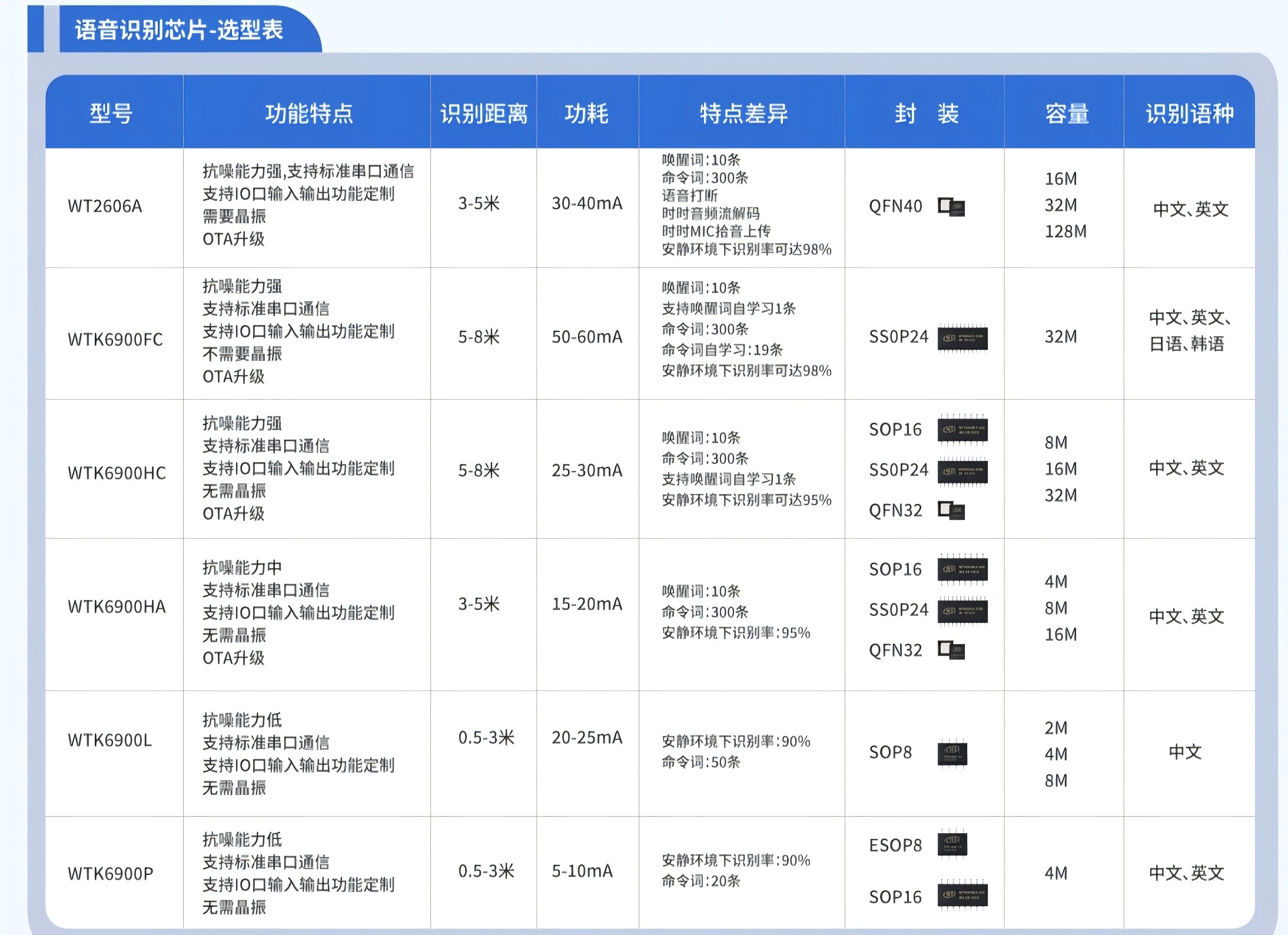
语音识别芯片选型有哪些技术参数要注意



评论