 TensorRT-LLM初探(一)运行llama
TensorRT-LLM初探(一)运行llama
前文
TensorRT-LLM正式出来有半个月了,一直没有时间玩,周末趁着有时间跑一下。
之前玩内测版的时候就需要cuda-12.x,正式出来仍是需要cuda-12.x,主要是因为tensorr-llm中依赖的CUBIN(二进制代码)是基于cuda12.x编译生成的,想要跑只能更新驱动。
因此,想要快速跑TensorRT-LLM,建议直接将nvidia-driver升级到535.xxx,利用docker跑即可,省去自己折腾环境, 至于想要自定义修改源码,也在docker中搞就可以 。
理论上替换原始代码中的该部分就可以使用别的cuda版本了(batch manager只是不开源,和cuda版本应该没关系,主要是FMA模块,另外TensorRT-llm依赖的TensorRT有cuda11.x版本,配合inflight_batcher_llm跑的triton-inference-server也和cuda12.x没有强制依赖关系):

tensorrt-llm中预先编译好的部分
说完环境要求,开始配环境吧!
搭建运行环境以及库
首先拉取镜像,宿主机显卡驱动需要高于等于535:
docker pull nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3
这个镜像是前几天刚出的,包含了运行TensorRT-LLM的所有环境(TensorRT、mpi、nvcc、nccl库等等),省去自己配环境的烦恼。
拉下来镜像后,启动镜像:
docker run -it -d --cap-add=SYS_PTRACE --cap-add=SYS_ADMIN --security-opt seccomp=unconfined --gpus=all --shm-size=16g --privileged --ulimit memlock=-1 --name=develop nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3 bash
接下来的操作全在这个容器里。
编译tensorrt-llm
首先获取git仓库,因为这个镜像中 只有运行需要的lib ,模型还是需要自行编译的(因为依赖的TensorRT,用过trt的都知道需要构建engine),所以首先编译tensorrRT-LLM:
# TensorRT-LLM uses git-lfs, which needs to be installed in advance.
apt-get update && apt-get -y install git git-lfs
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
git submodule update --init --recursive
git lfs install
git lfs pull
然后进入仓库进行编译:
python3 ./scripts/build_wheel.py --trt_root /usr/local/tensorrt
一般不会有环境问题,这个docekr中已经包含了所有需要的包,执行build_wheel的时候会按照脚本中的步骤pip install一些需要的包,然后运行cmake和make编译文件:
..
adding 'tensorrt_llm/tools/plugin_gen/templates/functional.py.tpl'
adding 'tensorrt_llm/tools/plugin_gen/templates/plugin.cpp.tpl'
adding 'tensorrt_llm/tools/plugin_gen/templates/plugin.h.tpl'
adding 'tensorrt_llm/tools/plugin_gen/templates/plugin_common.cpp'
adding 'tensorrt_llm/tools/plugin_gen/templates/plugin_common.h'
adding 'tensorrt_llm/tools/plugin_gen/templates/tritonPlugins.cpp.tpl'
adding 'tensorrt_llm-0.5.0.dist-info/LICENSE'
adding 'tensorrt_llm-0.5.0.dist-info/METADATA'
adding 'tensorrt_llm-0.5.0.dist-info/WHEEL'
adding 'tensorrt_llm-0.5.0.dist-info/top_level.txt'
adding 'tensorrt_llm-0.5.0.dist-info/zip-safe'
adding 'tensorrt_llm-0.5.0.dist-info/RECORD'
removing build/bdist.linux-x86_64/wheel
Successfully built tensorrt_llm-0.5.0-py3-none-any.whl
然后pip install tensorrt_llm-0.5.0-py3-none-any.whl即可。
运行
首先编译模型,因为最近没有下载新模型,还是拿旧的llama做例子。其实吧,其他llm也一样(chatglm、qwen等等),只要trt-llm支持,编译运行方法都一样的,在hugging face下载好要测试的模型即可。
这里我执行:
python /work/code/TensorRT-LLM/examples/llama/build.py
--model_dir /work/models/GPT/LLAMA/llama-7b-hf # 可以替换为你自己的llm模型
--dtype float16
--remove_input_padding
--use_gpt_attention_plugin float16
--enable_context_fmha
--use_gemm_plugin float16
--use_inflight_batching # 开启inflight batching
--output_dir /work/trtModel/llama/1-gpu
然后就是TensorRT的编译、构建engine的过程(因为使用了plugin,编译挺快的,这里我只用了一张A4000,所以没有设置world_size,默认为1),这里有很多细节,后续会聊。
编译好engine后,会生成/work/trtModel/llama/1-gpu,后续会用到。
执行以下命令:
cd tensorrtllm_backend
mkdir triton_model_repo
# 拷贝出来模板模型文件夹
cp -r all_models/inflight_batcher_llm/* triton_model_repo/
# 将刚才生成好的`/work/trtModel/llama/1-gpu`移动到模板模型文件夹中
cp /work/trtModel/llama/1-gpu/* triton_model_repo/tensorrt_llm/1

设置好之后进入tensorrtllm_backend执行:
python3 scripts/launch_triton_server.py --world_size=1 --model_repo=triton_model_repo
顺利的话就会输出:
root@6aaab84e59c0:/work/code/tensorrtllm_backend# I1105 14:16:58.286836 2561098 pinned_memory_manager.cc:241] Pinned memory pool is created at '0x7ffb76000000' with size 268435456
I1105 14:16:58.286973 2561098 cuda_memory_manager.cc:107] CUDA memory pool is created on device 0 with size 67108864
I1105 14:16:58.288120 2561098 model_lifecycle.cc:461] loading: tensorrt_llm:1
I1105 14:16:58.288135 2561098 model_lifecycle.cc:461] loading: preprocessing:1
I1105 14:16:58.288142 2561098 model_lifecycle.cc:461] loading: postprocessing:1
[TensorRT-LLM][WARNING] max_tokens_in_paged_kv_cache is not specified, will use default value
[TensorRT-LLM][WARNING] batch_scheduler_policy parameter was not found or is invalid (must be max_utilization or guaranteed_no_evict)
[TensorRT-LLM][WARNING] kv_cache_free_gpu_mem_fraction is not specified, will use default value of 0.85 or max_tokens_in_paged_kv_cache
[TensorRT-LLM][WARNING] max_num_sequences is not specified, will be set to the TRT engine max_batch_size
[TensorRT-LLM][WARNING] enable_trt_overlap is not specified, will be set to true
[TensorRT-LLM][WARNING] [json.exception.type_error.302] type must be number, but is null
[TensorRT-LLM][WARNING] Optional value for parameter max_num_tokens will not be set.
[TensorRT-LLM][INFO] Initializing MPI with thread mode 1
I1105 14:16:58.392915 2561098 python_be.cc:2199] TRITONBACKEND_ModelInstanceInitialize: postprocessing_0_0 (CPU device 0)
I1105 14:16:58.392979 2561098 python_be.cc:2199] TRITONBACKEND_ModelInstanceInitialize: preprocessing_0_0 (CPU device 0)
[TensorRT-LLM][INFO] MPI size: 1, rank: 0
I1105 14:16:58.732165 2561098 model_lifecycle.cc:818] successfully loaded 'postprocessing'
I1105 14:16:59.383255 2561098 model_lifecycle.cc:818] successfully loaded 'preprocessing'
[TensorRT-LLM][INFO] TRTGptModel maxNumSequences: 16
[TensorRT-LLM][INFO] TRTGptModel maxBatchSize: 8
[TensorRT-LLM][INFO] TRTGptModel enableTrtOverlap: 1
[TensorRT-LLM][INFO] Loaded engine size: 12856 MiB
[TensorRT-LLM][INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 13144, GPU 13111 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Init cuDNN: CPU +2, GPU +10, now: CPU 13146, GPU 13121 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +12852, now: CPU 0, GPU 12852 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 13164, GPU 14363 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 13164, GPU 14371 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 12852 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 13198, GPU 14391 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Init cuDNN: CPU +0, GPU +10, now: CPU 13198, GPU 14401 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 12852 (MiB)
[TensorRT-LLM][INFO] Using 2878 tokens in paged KV cache.
I1105 14:17:17.299293 2561098 model_lifecycle.cc:818] successfully loaded 'tensorrt_llm'
I1105 14:17:17.303661 2561098 model_lifecycle.cc:461] loading: ensemble:1
I1105 14:17:17.305897 2561098 model_lifecycle.cc:818] successfully loaded 'ensemble'
I1105 14:17:17.306051 2561098 server.cc:592]
+------------------+------+
| Repository Agent | Path |
+------------------+------+
+------------------+------+
I1105 14:17:17.306401 2561098 server.cc:619]
+-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
| Backend | Path | Config |
+-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
| tensorrtllm | /opt/tritonserver/backends/tensorrtllm/libtriton_tensorrtllm.so | {"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-com |
| | | pute-capability":"6.000000","default-max-batch-size":"4"}} |
| python | /opt/tritonserver/backends/python/libtriton_python.so | {"cmdline":{"auto-complete-config":"false","backend-directory":"/opt/tritonserver/backends","min-com |
| | | pute-capability":"6.000000","shm-region-prefix-name":"prefix0_","default-max-batch-size":"4"}} |
+-------------+-----------------------------------------------------------------+------------------------------------------------------------------------------------------------------+
I1105 14:17:17.307053 2561098 server.cc:662]
+----------------+---------+--------+
| Model | Version | Status |
+----------------+---------+--------+
| ensemble | 1 | READY |
| postprocessing | 1 | READY |
| preprocessing | 1 | READY |
| tensorrt_llm | 1 | READY |
+----------------+---------+--------+
I1105 14:17:17.393318 2561098 metrics.cc:817] Collecting metrics for GPU 0: NVIDIA RTX A4000
I1105 14:17:17.393534 2561098 metrics.cc:710] Collecting CPU metrics
I1105 14:17:17.394550 2561098 tritonserver.cc:2458]
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+
| Option | Value |
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+
| server_id | triton |
| server_version | 2.39.0 |
| server_extensions | classification sequence model_repository model_repository(unload_dependents) schedule_policy model_configuration system_shared_memory cuda_shared_ |
| | memory binary_tensor_data parameters statistics trace logging |
| model_repository_path[0] | /work/triton_models/inflight_batcher_llm |
| model_control_mode | MODE_NONE |
| strict_model_config | 1 |
| rate_limit | OFF |
| pinned_memory_pool_byte_size | 268435456 |
| cuda_memory_pool_byte_size{0} | 67108864 |
| min_supported_compute_capability | 6.0 |
| strict_readiness | 1 |
| exit_timeout | 30 |
| cache_enabled | 0 |
+----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------+
I1105 14:17:17.423479 2561098 grpc_server.cc:2513] Started GRPCInferenceService at 0.0.0.0:8001
I1105 14:17:17.424418 2561098 http_server.cc:4497] Started HTTPService at 0.0.0.0:8000
这时也就启动了triton-inference-server,后端就是TensorRT-LLM。
可以看到LLAMA-7B-FP16精度版本,占用显存为:
+---------------------------------------------------------------------------------------+
Sun Nov 5 14:20:46 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.113.01 Driver Version: 535.113.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA RTX A4000 Off | 00000000:01:00.0 Off | Off |
| 41% 34C P8 16W / 140W | 15855MiB / 16376MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
客户端
然后我们请求一下吧,先走http接口:
# 执行
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "What is machine learning?", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
# 得到返回结果
{"model_name":"ensemble","model_version":"1","sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":" ⁇ What is machine learning? Machine learning is a subfield of computer science that focuses on the development of algorithms that can learn"}
triton目前不支持SSE方法,想stream可以使用grpc协议,官方也提供了grpc的方法,首先安装triton客户端:
pip install tritonclient[all]
然后执行:
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py --request-output-len 200 --tokenizer_dir /work/models/GPT/LLAMA/llama-7b-hf --tokenizer_type llama --streaming
请求后可以看到是一个token一个token返回的,也就是我们使用chatgpt3.5时,一个字一个字蹦的意思:
...
[29953]
[29941]
[511]
[450]
[315]
[4664]
[457]
[310]
output_ids = [[0, 19298, 297, 6641, 29899, 23027, 3444, 29892, 1105, 7598, 16370, 408, 263, 14547, 297, 3681, 1434, 8401, 304, 4517, 297, 29871, 29896, 29947, 29946, 29955, 29889, 940, 3796, 472, 278, 23933, 5977, 322, 278, 7021, 16923, 297, 29258, 265, 1434, 8718, 670, 1914, 27144, 297, 29871, 29896, 29947, 29945, 29896, 29889, 940, 471, 263, 29323, 261, 310, 278, 671, 310, 21837, 7984, 292, 322, 471, 278, 937, 304, 671, 263, 10489, 380, 994, 29889, 940, 471, 884, 263, 410, 29880, 928, 9227, 322, 670, 8277, 5134, 450, 315, 4664, 457, 310, 3444, 313, 29896, 29947, 29945, 29896, 511, 450, 315, 4664, 457, 310, 12730, 313, 29896, 29947, 29945, 29946, 511, 450, 315, 4664, 457, 310, 13616, 313, 29896, 29947, 29945, 29945, 511, 450, 315, 4664, 457, 310, 9556, 313, 29896, 29947, 29945, 29955, 511, 450, 315, 4664, 457, 310, 17362, 313, 29896, 29947, 29945, 29947, 511, 450, 315, 4664, 457, 310, 12710, 313, 29896, 29947, 29945, 29929, 511, 450, 315, 4664, 457, 310, 14198, 653, 313, 29896, 29947, 29953, 29900, 511, 450, 315, 4664, 457, 310, 28806, 313, 29896, 29947, 29953, 29896, 511, 450, 315, 4664, 457, 310, 27440, 313, 29896, 29947, 29953, 29906, 511, 450, 315, 4664, 457, 310, 24506, 313, 29896, 29947, 29953, 29941, 511, 450, 315, 4664, 457, 310]]
Input: Born in north-east France, Soyer trained as a
Output: chef in Paris before moving to London in 1 847. He worked at the Reform Club and the Royal Hotel in Brighton before opening his own restaurant in 1 851 . He was a pioneer of the use of steam cooking and was the first to use a gas stove. He was also a prolific writer and his books included The Cuisine of France (1 851 ), The Cuisine of Italy (1 854), The Cuisine of Spain (1 855), The Cuisine of Germany (1 857), The Cuisine of Austria (1 858), The Cuisine of Russia (1 859), The Cuisine of Hungary (1 860), The Cuisine of Switzerland (1 861 ), The Cuisine of Norway (1 862), The Cuisine of Sweden (1863), The Cuisine of
因为开了inflight batching,其实可以同时多个请求打过来,修改request_id不要一样就可以:
# user 1
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py --request-output-len 200 --tokenizer_dir /work/models/GPT/LLAMA/llama-7b-hf --tokenizer_type llama --streaming --request_id 1
# user 2
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py --request-output-len 200 --tokenizer_dir /work/models/GPT/LLAMA/llama-7b-hf --tokenizer_type llama --streaming --request_id 2
至此就快速过完整个TensorRT-LLM的运行流程。
使用建议
非常建议使用docker,人生苦短。
在我们实际使用中,vllm在batch较大的场景并不慢,利用率也能打满。TensorRT-LLM和vllm的速度在某些模型上快某些模型上慢,各有优劣。

TensorRT-LLM的特点就是借助TensorRT,TensorRT后续更新越快,支持特性越牛逼,TensorRT-LLM也就越牛逼。灵活性上,我感觉vllm和TensorRT-LLM不分上下,加上大模型的结构其实都差不多,甚至TensorRT-LLM都没有上onnx-parser,在后续更新模型上,python快速搭建模型效率也都差不了多少。
-
python
+关注
关注
56文章
4800浏览量
84821 -
GPU芯片
+关注
关注
1文章
303浏览量
5857 -
HTTP接口
+关注
关注
0文章
21浏览量
1815 -
ChatGPT
+关注
关注
29文章
1564浏览量
7823
发布评论请先 登录
相关推荐
【算能RADXA微服务器试用体验】+ GPT语音与视觉交互:1,LLM部署
Meta推出Llama 2 免费开放商业和研究机构使用
现已公开发布!欢迎使用 NVIDIA TensorRT-LLM 优化大语言模型推理

浅析tensorrt-llm搭建运行环境以及库
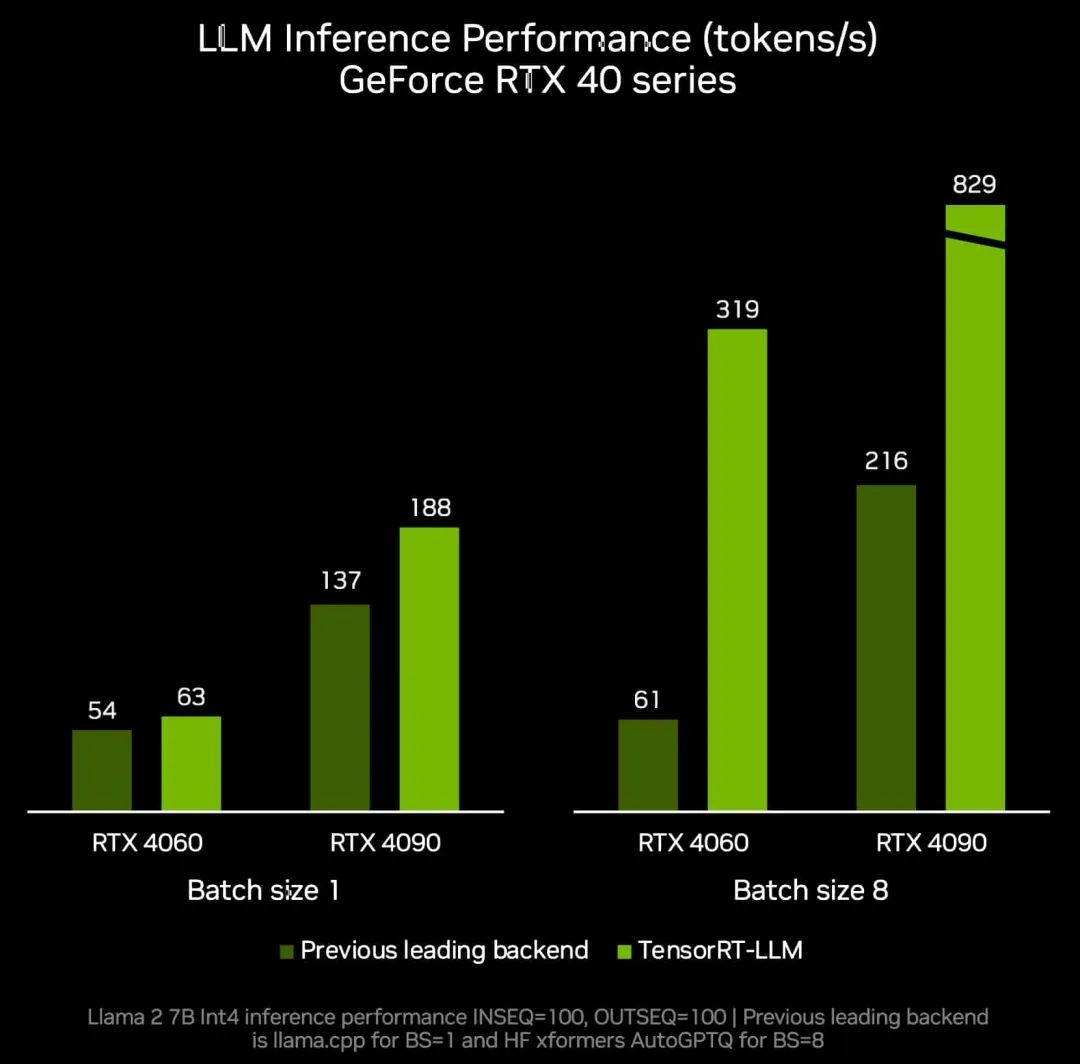
点亮未来:TensorRT-LLM 更新加速 AI 推理性能,支持在 RTX 驱动的 Windows PC 上运行新模型
LLaMA 2是什么?LLaMA 2背后的研究工作
NVIDIA加速微软最新的Phi-3 Mini开源语言模型
高通支持Meta Llama 3在骁龙终端上运行
Meta发布基于Code Llama的LLM编译器
魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
TensorRT-LLM低精度推理优化

使用NVIDIA TensorRT提升Llama 3.2性能
NVIDIA TensorRT-LLM Roadmap现已在GitHub上公开发布

解锁NVIDIA TensorRT-LLM的卓越性能
在NVIDIA TensorRT-LLM中启用ReDrafter的一些变化






 工商网监
工商网监
评论