 多任务微调框架MFTCoder详细技术解读
多任务微调框架MFTCoder详细技术解读
代码大模型(Code LLMs)已经成为一个专门的研究领域,通过使用代码相关数据对预训练模型进行微调来提升模型的编码能力。以往的微调方法通常针对特定的下游任务或场景进行定制,意味着每个任务需要单独进行微调,需要大量的训练资源,并且由于多个模型并存而难于维护和部署。此外,这些方法未能利用不同代码任务之间的内在联系。 为了克服这些限制,我们提出了一种多任务微调框架——MFTCoder,它可以实现在多个任务上同时并行地进行微调。通过结合多种损失函数,我们有效地解决了多任务学习中常见的任务间数据量不平衡、难易不一和收敛速度不一致等挑战。
大量实验结果显示,相较于单独对单个任务进行微调或者多任务混合为一后进行微调,我们的多任务微调方法表现更优。此外,MFTCoder具备高效训练特征,包括提供高效的数据Tokenization模式和支持PEFT微调,能有效提升微调训练速度并降低对资源的需求。 MFTCoder已适配支持了多个主流开源LLMs,如LLama-1/2、CodeLLama、Qwen、CodeGeeX2、StarCoder、Baichuan2、ChatGLM2/3、GPT-Neox等。
以CodeLLama为底座,使用MFTCoder微调得到的CODEFUSE-CODELLAMA-34B在HumaneEval测试中pass@1得分高达74.4%,超过了GPT-4的表现(67%,zero-shot, 2023年3月)。
对应的代码也已经开源到github: https://github.com/codefuse-ai/MFTCoder 本文旨在对MFTCoder论文做一个详细技术解读。

引言
ChatGPT和GPT-4的横空出世使得大模型(LLMs)研发井喷式爆发,这也同时进一步引燃了将大模型应用于代码生成与理解的研发热潮,这一分支被称为代码大模型(即Code LLMs)方向。通过在大量的代码数据(例如GitHub公开数据)和自然文本数据上进行预训练,代码大模型可以有效完成各种代码相关的任务,例如代码自动补全、基于描述生成代码、为代码添加注释、解释代码功能、生成单测用例、修复代码、翻译代码等。 尽管(代码)LLMs的预训练阶段旨在确保其对不同的下游任务具有泛化能力,但随后的微调阶段通常只针对特定任务或场景而进行。这种方法忽视了两个关键挑战。
首先,它涉及针对每个任务进行资源密集型的单独微调,这阻碍了在生产环境中的高效部署;其次,代码领域任务的相互关联性表明,与单独微调相比,联合微调可以提高性能。因此,进行多任务微调是至关重要的,可以同时处理所有任务,并利用相关任务的优势来增强其他任务的表现。 为了更好地阐明,假设我们有两个相关的任务:代码补全和代码摘要。代码补全是基于部分代码片段预测下一行代码,而代码摘要旨在生成给定代码片段的简洁易读的摘要。传统上,每个任务会分别进行微调,导致资源密集型的重复。然而,代码补全和代码摘要之间存在内在联系。
代码片段的补全依赖于对整体功能和目的的理解,而生成准确的摘要则需要理解结构、依赖关系和预期功能。通过采用多任务学习,可以训练一个单一模型来共同学习这两个任务,利用共享的知识和模式,从而提高两个任务的性能。模型理解代码元素之间的上下文依赖关系,有助于预测下一个代码片段并生成信息丰富的摘要。此外,多任务学习在个别任务性能之外还提供了额外的好处:任务之间的共享表示有助于减轻过拟合问题,促进更好的泛化,并增强模型处理特定任务的数据稀缺性的能力。如果代码补全具有比代码摘要更大的训练数据集,模型可以利用丰富的补全数据来提高摘要的性能,从而有效地解决数据稀缺性挑战。多任务学习甚至使模型能够处理未见过但相关的任务,即使没有特定的训练数据。
总体而言,多任务学习允许模型共同学习多个相关的任务,从共享的知识中受益,提高性能,增强泛化能力,并应对数据稀缺性。 尽管多任务学习很重要,但在自然语言处理领域,只有少数几项现有研究探索了这种方法(Raffel等,2023年;Aghajanyan等,2021年;Aribandi等,2022年)。这些研究将多任务数据合并用于大模型学习,而没有明确区分任务。更不幸的是,这些研究往往优先考虑样本量较大的任务,忽视了样本量较小的任务。此外,它们未能确保任务间的收敛速度相等,导致一些任务过度优化,而其他任务则欠优化。 本文聚焦于大模型多任务微调(MFT, Multitask Fine-Tuning),意在使样本数量存有差异的任务获得相等的关注并取得相近的优化。
虽然我们的方法不限于代码大模型领域,但本文我们重点关注代码大模型,这是考虑到代码领域的下游任务往往更具相关性,这也是MFTCoder命名的来源。我们强调,MFTCoder可以简单地扩展到任意一组相关的NLP任务。为了提高MFTCoder的效率,我们采用了包括LoRA(Hu等,2021年)和QLoRA(Dettmers等,2023年)在内的参数高效的微调技术。实验结果表明,使用MFT方法训练的多任务模型在性能上优于单独为每个任务进行微调或合并多个任务的数据进行微调而得到的模型。我们进一步适配并验证了MFTCoder对各种当前流行的预训练LLMs的有效性,例如Qwen、Baichuan2、Llama、Llama 2、StarCoder、CodeLLama、CodeGeex2等。值得一提的是,当以CodeLlama-34B-Python为基座模型,MFTCoder微调得到的CodeFuse-CodeLLama-34B模型在HmanEval评测集上取得了74.4%的pass@1得分,超过了GPT-4(67%,zero-shot, 2023年3月)的表现。 文章主要贡献总结如下:
提出了MFTCoder,将多任务学习应用于代码大模型微调,重点解决了先前多任务微调方法中常见的数据不平衡和收敛速度不一致问题。
大量实验表明,MFT方法在性能上优于单独微调和多任务混合合并微调方法。基于CodeLlama-34B-Python底座,MFTCoder微调得到的模型CodeFuse-CodeLLama-34B在HumanEval评测集上取得了74.4%的pass@1得分,超过了GPT-4(67%,零样本),并开源了该模型和一个高质量指令数据集。
我们在多个流行LLMs上适配并验证了MFTCoder的表现,包括Qwen、Baichuan2、Llama、Llama 2、StarCoder、CodeLLama、CodeFuse和CodeGeex2等,证明了其与不同底座模型的兼容性和可扩展性。
方法
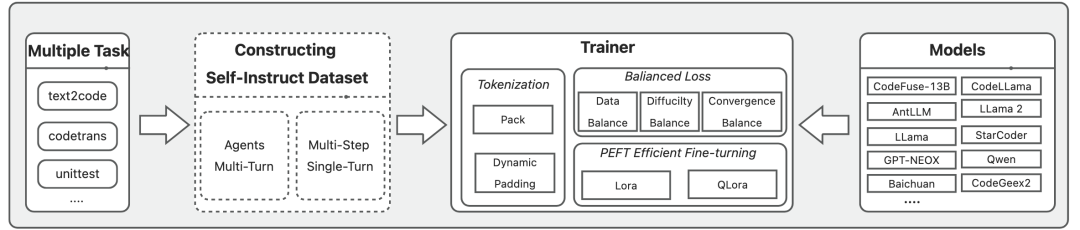
图1:MFT架构图 01
框架
MFTCoder的总体框架如图 1所示,包括多任务支持、多模型适配、高质量数据集构建、高效数据使用方式、高效训练方式及多任务均衡设计。
(多任务)MFTCoder旨在无缝地适配LLMs到不同的场景,并在特定的场景中最大化它们的性能。在将MFTCoder应用于新场景时,首要步骤便是将场景分解为对应于目标能力的较小任务。例如,在代码LLMs领域,增强模型的代码能力的总体目标可以进一步拆解为更细粒度的任务,如代码补全,文本到代码生成,单元测试用例生成,代码修复,代码调试,甚至跨语言翻译。我们广泛的实践经验表明,MFTCoder可以有效处理从单个任务到数十甚至数百个任务的多任务规模。
(数据集构建与高效训练)拆分完后,下一步便是为每个任务收集和整理微调数据集,然而,某些任务的数据收集可能会存在挑战。为了克服这一问题,MFTCoder利用了Self-Instruct(Wang等,2022年)和Agents技术来生成指令数据集。多任务微调往往意味着一次微调会使用较大量的训练数据,为了确保高效的训练过程,MFTCoder采用了两种高效的数据Tokenization模式,并支持PEFT(Parameter-Efficient Fine-Tuning)技术来提高训练效率。
(任务均衡设计)针对多任务学习领域普遍存在的任务间数据量不均衡、难易不一及收敛速度不一致的挑战,MFTCoder引入或调整不同的损失函数以实现任务平衡。
(多模型适配)鉴于不同的大型模型具有不同的优势和能力,为支持按需选择适合的模型底座进行微调以实现最佳性能,MFTCoder已适配了若干主流的开源LLMs,包括LLama,LLama 2,CodeLLama,Qwen,Baichuan 1/2,ChatGLM 2,CodeGeeX 2,GPT-NEOX,CodeFuse-13B,StarCoder,AntLLM等。同时也在持续更新和适配新的模型。
02
指令数据集构建
对于数据收集具有挑战性的任务,我们采用Self-Instruct技术为MFTCoder中的下游代码相关任务生成微调数据。这涉及向GPT-3.5或GPT-4提供定制的提示,明确描述我们的指令生成需求,从而生成指令数据。此外,我们从PHI-1/1.5工作(Gunasekar等,2023年)中受到启发,进一步将Self-Instruct技术应用于为下游代码相关任务生成高质量的代码练习数据集。 在具体实现方面,我们有两个选择。
一种是借助Agents(例如Camel(Li等,2023c年))的自主多轮对话方法,另一种是通过直接调用ChatGPT API实现的单轮对话方法。在多轮对话方法中,我们使用Camel启动两个Agents,每个Agent被赋予特定的角色和任务目标,驱动它们之间相互对话以生成与给定主题相符的指令数据。例如,在生成Python练习数据时,我们将两个Agents分别指定为“教师”(模拟ChatGPT的用户角色)和“学生”(模拟ChatGPT的助理角色)角色,其中,教师的责任是向学生提供生成练习题的指令,而学生的任务则是提供相应指令的解决方案。
这个迭代过程会持续进行而生成多个练习问题,直到满足任务要求或达到ChatGPT的最大输入长度。值得一提的是,为了适应ChatGPT的输入长度限制,我们不能直接使用较宽泛的题目作为任务主题。例如,当创建用于评估学生Python语言掌握程度的练习题时,我们需要将主题分解为较小而具体的Python知识点(例如二叉搜索树),并为每个知识点单独启动Camel会话。
具体的示例如下图2(摘自论文附录Ahttps://arxiv.org/pdf/2311.02303.pdf)。

图2: 通过Camel Agents生成代码练习题系统及用户提示设置示例
多轮对话方案提供了较高的自动化能力,但由于需要维护两个Agents,并且每个代理都需要对ChatGPT API进行多轮会话调用,因此成本较高。为了缓解这一问题,我们提出了一种更经济高效的单轮对话生成方法,其整体过程如图3所示。我们首先创建一个初始种子集,种子集由数百个Python基础知识点组成。然后将这些种子与准备好的固定Prompt模板组合,生成一组模式化的任务Prompt。
为了解决固定模板导致的多样性减少问题,并确保准确的提示描述,我们利用Camel的任务Prompt细化功能来获取精确且多样的任务Prompt。每个任务Prompt用于生成与相应种子相关的一组指令(例如与二叉搜索树相关的练习问题)。使用ChatGPT,我们生成相应的指令解决方案。最后,我们将指令及其相应的解决方案组装和去重,以获得一个练习数据集。我们已经开源了使用这种方法构建的Python Code Exercises数据集: https://huggingface
.co/datasets/codefuse-ai/CodeExercise-Python-27k
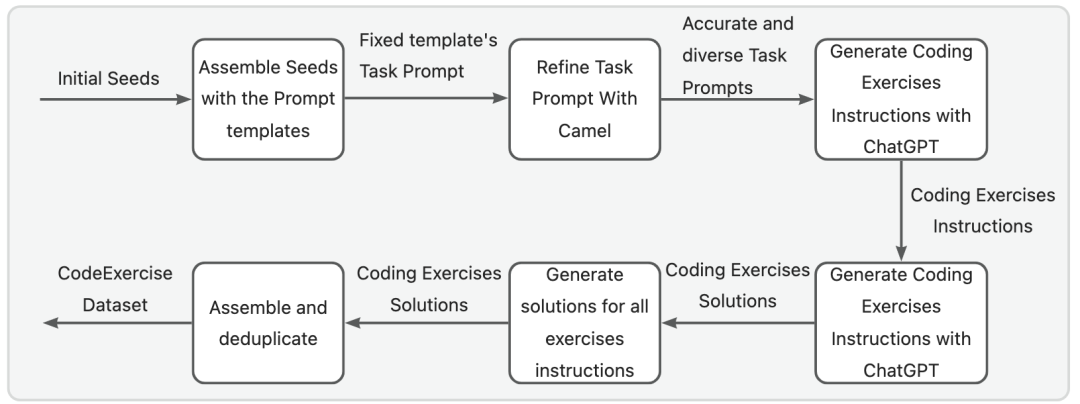
图3: Code Exercises指令数据集单轮生成方案流程 03
高效Tokenization模式
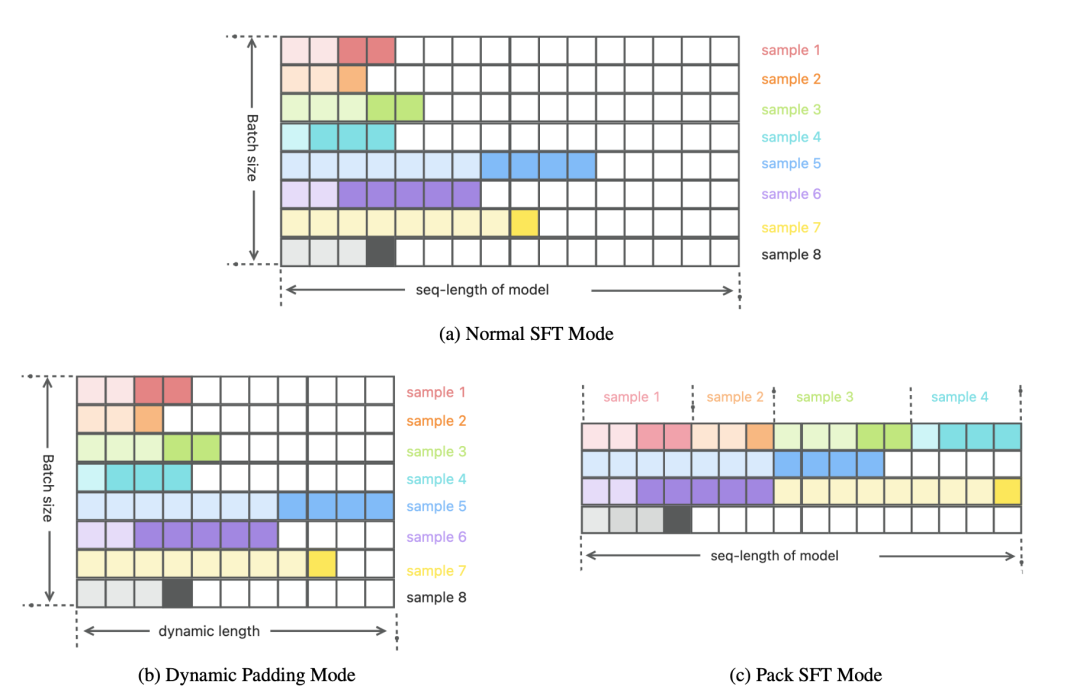
图4: 三种Tokenization模式在一个Batch中的数据存在形式对比示意图
在LLMs的预训练和微调过程中,分词(Tokenization)是一个关键步骤,在这个步骤中输入和输出文本被分割成较小的单元以供后续使用。Tokenization与训练过程使用的损失函数一起定义了训练过程中数据的使用方式,因此在模型的有效性和训练效率上起着关键作用。在典型的SFT (Supervised Fine-Tuning) Tokenization方案中,同一batch中的样本被统一对齐到模型的最大输入长度(seq-length),对于长度不足的则使用额外的填充Tokens进行填充,如图 4(a)所示。然而,在实践中,我们发现这种方法会导致产生大量的填充Tokens。例如,当使用CodeFuse-13B(Di等,2023年)的Tokenizer处理35个下游任务数据时,填充Tokens的平均比例为92.22%(seq-length为4096)。
这意味着有大量的Tokens仅用于对齐,而对训练过程没有任何价值,这导致训练效率降低,且浪费用于存储离线Tokenization结果的存储空间。为了解决这个问题,我们采用了两种Tokenization模式,即动态填充(Dynamic Padding)模式和打包(Pack)模式,并对其进行了优化。 在动态填充模式中,每个GPU的micro batch窗口大小由其中的最大样本长度确定。较短的样本会使用额外的填充Tokens进行填充,以对齐到该大小,如图 4(b)所示。
尽管填充Tokens不会影响模型的训练效果,但它们会增加训练过程中的计算开销,从而影响训练速度,而动态填充模式有效地减少了填充Tokens的使用比例,从而加快了训练速度。根据我们的经验,与传统的SFT Tokenization模式相比,这种方法可以实现大约两倍的速度提升(实际的增幅取决于数据集)。需要注意的是,该模式仅适用于在线Tokenization场景。 与动态填充模式通过减少了micro batch窗口大小来提高效率的角度不同,打包模式是从最大化模型允许的最大输入窗口长度(seq-length)的利用率角度出发,这种模式与Llama 2的SFT Tokenization模式(Touvron等,2023b年)相似。
在打包模式中,多个微调样本按顺序打包到一个长度为seq-length的窗口中,两个相邻样本通过一个EOS Token分隔,如图 4(c)所示。在图中,图 4(a)的样本1-4被组合并依次放置在一个窗口中。如果一个样本无法完全放入当前窗口,它将被放置在下一个窗口,并用填充Tokens填充剩余的空间,例如,图 4(c)中,样本5被放置在第二个窗口中,并使用填充Tokens填充尾部空间,而样本6则放置在第三个窗口中。与动态填充模式相比,打包模式进一步降低了的填充Tokens比例,从而可进一步提高训练速度。我们的实践经验表明,在前面提到的35个任务中,该方法将填充Tokens的平均比例降低到不到10%,从而在保持训练效果的同时大幅提升了训练速度。需要强调的是,MFTCoder支持在线和离线的打包Tokenization场景,不仅服务于SFT阶段,还适用于预训练阶段。 04
PEFT高效微调
目前流行的开源LLMs通常包含数十亿乃至上百亿个参数,而多任务学习场景又通常涉及大量的任务,这意味着会有大量的微调样本参与训练。如果我们选择使用大量数据对这些大模型进行全量微调,将会面临两个挑战:首先,需要大量的存储和计算资源;其次,在训练过程中可能面临灾难性遗忘的风险。为了解决这些问题,MFTCoder采用了PEFT(Parameter-efficient fine-tuning)技术(Houlsby等,2019年),使得能够在短时间内以最小的资源需求实现高效的微调。
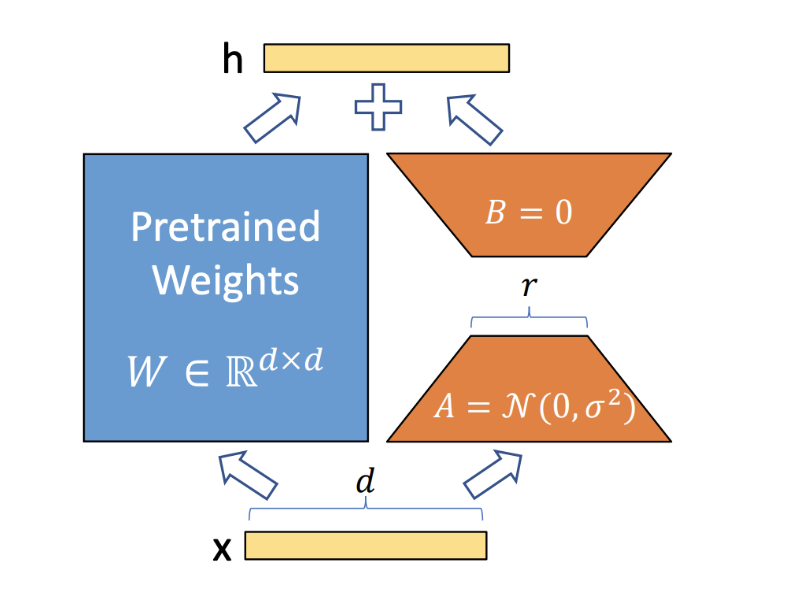
图5: Lora核心思想示意
具体来说,MFTCoder支持两种PEFT方法:Lora(Large-scale Language Model Low-Rank Adaptation)(Hu等,2021年)和QLora(Quantized Large-scale Language Model Low-Rank Adaptation)(Dettmers等,2023年)。 Lora的基本概念非常简单,如图 5所示。它会给原始模型添加一个旁路分支,在训练过程中,原始训练模型的参数W ∈ R(形状为d x d)保持不变,只有旁路分支中的降维矩阵A ∈ R(形状为d × r)和升维矩阵B ∈ R(形状为r x d)的参数是可训练的。
训练完成后,矩阵乘积BA将被加到原始模型参数W中,从而得到新训练的模型。由于r相对于d的规模显著缩小,可训练参数的数量因而大大减少。在Lora的基础上,QLora采用了一种称为NF4的新的高精度量化技术,并引入了双重量化来将预训练模型量化为4位(bits)。此外,它还引入了一组可学习的低秩适配器权重,通过优化量化权重的梯度,对这些权重进行微调。结果,QLoRA可以使用更少的GPU资源对较大的模型进行微调。例如,MFTCoder可以在单张Nvidia A100卡(80GB显存)上对70B模型进行微调。
05
多任务均衡损失函数
作为一个多任务学习框架,MFTCoder面临着任务间数据量不平衡、难易不一和收敛速度不同的重大挑战。为了解决这些挑战,MFTCoder采用了一组专门设计的损失函数,以缓解这些不平衡问题。 首先,为了解决数据量不平衡的问题,MFTCoder会确保在单个epoch内所有任务的每一个样本都被使用且只使用一次。为了避免模型偏向具有较多数据的任务,我们在损失计算过程中引入了权重分配策略。
具体而言,我们支持两种权重计算方案:一种基于任务样本数量,另一种基于纳入loss计算的的有效Tokens数量。前者更直接,但在处理样本数量与有效Tokens数量具有极端差异的任务(例如"是"或"否"回答的二元分类任务或单项选择考试任务)时可能表现不佳。而另一方面,基于纳入loss计算的有效Tokens数量的权重分配方案可以缓解这个问题。带权重的损失函数具体如公式 (1)所示。在公式1中,N代表任务的总数,M_i表示第i个任务的样本数量,T_ij表示第i个任务的第j个样本中的有效Token(即参与loss计算的Token)的数量,t_ijk表示第i个任务的第j个样本的第k个有效Token。
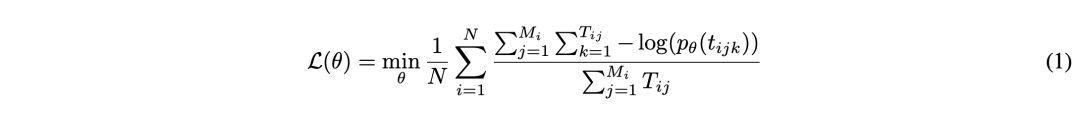
为了解决任务难易不一的问题,我们借鉴了Focal Loss的思想,并将其纳入到MFTCoder中。我们实现了两个不同层次的Focal Loss函数,以适应不同的细粒度。一个在样本级别操作,如公式 (2)所示,另一个在任务级别操作,如公式 (3)所示。
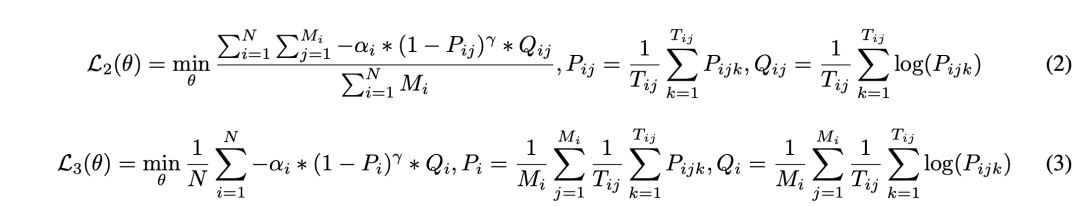
为了解决收敛速度不一致的问题,我们借鉴了FAMO(Fast Adaptation via Meta-Optimization)方法(Liu等,2023年)的思想,并创新地将其应用于计算validation loss。首先,我们假设每个任务(以索引i表示)都有自己的原始损失函数Li(θ)。在第t次迭代中,我们根据对应任务的validation loss的梯度来更新每个任务的权重,目标是最大化收敛速度最慢的任务的权重w_i,如公式 (4)所示。其中,g_t表示所有任务加权验证损失的梯度,ci(α, g_t)表示第i个任务验证损失的斜率(梯度),θ_t表示第t次迭代中网络的参数,α是学习率,ε是一个小常数,用于防止除以零。此外,我们希望对如何实现收敛平衡进行进一步解释。为了确保任务以相似的速度收敛,我们引入了一种动态平衡机制。
在每次迭代中,我们根据任务的验证损失梯度更新任务特定的权重。该方法旨在给予收敛速度较慢的任务更多的关注,使其对整体优化过程产生更大的影响。通过动态调整任务权重,我们创造了一个平衡收敛的情景,所有任务以类似的速度向其最优解进展。这种机制有效地解决了不同收敛速度的问题,增强了MFTCoder框架的整体稳定性和性能。
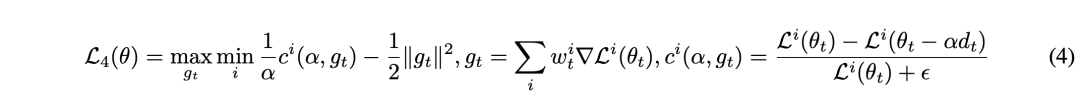
通过结合这些不同的损失函数,MFTCoder可有效地解决各种多任务场景的不同需求,并缓解现有大规模多任务学习研究中常遇到的任务数据不平衡、难易不一和收敛速度不一致等挑战。MFTCoder作为一个灵活框架为这些问题提供了有效的解决方案,为开发更高效、更准确的多任务模型提供了支持。
实验
在本节中,我们将使用MFTCoder进行多组实验用于验证MFT方法的有效性和优越性。具体而言,我们的目标是回答以下三个研究问题:
RQ1:通过使用MFT方法对多个任务进行微调得到的MFT模型是否优于单独对每个任务进行微调而得到的SFT-S(单一任务)模型?
RQ2:MFT模型是否优于将多个任务组合并作为一个任务进行微调而得到的SFT-Mixed(混合任务)模型?
RQ3:在对未见任务的泛化能力上,MFT模型是否优于SFT-Mixed模型?
接下来,我们将首先介绍实验设置。然后,我们将展示和深入探讨实验结果。最后,我们将总结并回答本节中提出的研究问题。 01
实验设置
为了回答这三个研究问题,我们选择了5个与代码相关的下游任务,并准备了相应的微调数据,如表 1所示。表1展示了每个任务的目标能力(第III列)和样本数量(第IV列)。例如,CODECOMPLETION-TASK旨在提高模型的代码补全能力,包括192,547个微调样本。CODETRANS-TASK旨在增强模型的代码翻译能力,包含307,585个微调样本。因此,我们共训练了7个模型(第I列),包括为每个下游任务单独训练的SFT-S-*模型、5个任务数据混合为一的SFT-MIXED模型,以及使用MFT方法训练的MFT-5TASKS模型。
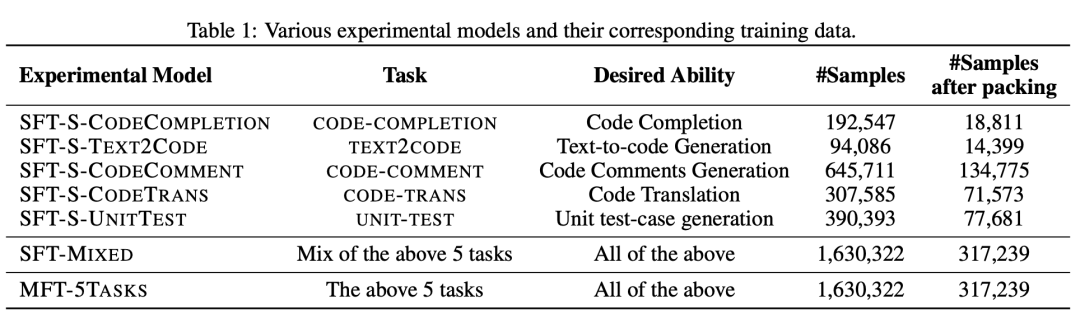
在实验中,除训练数据外,所有模型的配置都相同。所有模型的底座模型都是CodeLlama-13B-Python(Rozière等,2023年)。每个模型使用16张A100 GPU(80GB显存),micro batch大小为8,全局batch大小为128进行训练。使用Adam优化器(Kingma和Ba,2017年),初始学习率为2e-4,最小学习率为1e-5。我们使用MFTCoder的QLora-INT4模式进行微调,微调参数比例均为2.52%,且可训练参数的位置和初始值也是相同的。
所有模型都采用数据均衡损失函数(即公式 (1))并使用打包Tokenization模式。值得注意的是,当只有一个任务时,这个损失函数与标准GPT模型预训练中使用的传统损失函数一致。为了使得每个模型尽可能收敛完全,我们会在模型连续两个Epoch的validation loss均高于它们前面紧邻的一个Epoch的validation loss时终止模型训练,并选择倒数第三个Epoch对应的模型检查点作为评测对象。 02
评测集
在本文中,我们使用了公开可得且具有代表性的代码评测集进行比较评估,包括:
HumanEval(Chen等,2021年)是一个广泛使用的Python代码补全评估数据集,由OpenAI的研究人员精心设计。
HumanEval-X(Zheng等,2023年)是通过翻译方式将HumanEval扩展成多种编程语言,实现了多语言代码补全评估。
DS-1000(Lai等,2022年)侧重于评估模型使用Python代码进行数据科学分析的能力,涵盖了Numpy、Pandas、TensorFlow、Pytorch、Scipy、Sklearn和Matplotlib等重要库。
MBPP(Austin等,2021年)包含1000个Python编程问题,通过众包方式构建,主要评估模型对基础Python的掌握能力。在本研究中,我们从MBPP中选择了ID为11-510的500个问题来评估模型基于文本描述生成代码的能力。
CodeFuseEval(https://github.com/codefuse-ai/codefuse-evaluation),在HumanEval和HumanEval-X的基础上,进一步扩展评测范围,新增中文代码补全(docstring为中文)、代码翻译和单测用例生成能力评估,对应的子集分别称为CodeFuseEval-CN、CodeFuseEval-CodeTrans和CodeFuseEval-UnitTest。
在以上评测集上,我们均采用“pass@1”作为本文中的评估指标。
实验结果
接下来,我们将展示7个训练模型的评估结果。对于每个单一任务SFT-S-*模型,我们重点测试它们的特定目标能力,例如,对于只用代码补全数据集训练的SFT-S-CODECOMPLETION模型,我们只测试其在代码补全上的表现。另一方面,对于SFT-MIXED模型和MFT-5TASKS模型,我们将评估它们在每个任务上的表现,并将其与相应的SFT-S-*模型进行比较。具体而言,我们评估了7个模型在代码补全、Text2Code、代码注释生成、代码翻译和单测用例生成等能力维度上的表现。 代码补全 对于代码补全任务,我们使用了HumanEval和HumanEval-X评估数据集来评估模型的性能,采用pass@1作为评估指标。我们评估了3个模型:SFT-S-CODECOMPLETION、SFT-MIXED和MFT-5TASKS。
这些模型在HumanEval数据集上的表现总结如表 2所示(第III列)。结果表明,使用MFT方法训练的MFT-5TASKS模型优于其他两个模型。相比于使用混合任务数据进行微调的SFT-MIXED模型,其性能提高了2.44%。值得注意的是,SFT-MIXED模型的性能不如SFT-S-CODECOMPLETION模型,后者是针对代码补全任务进行单独训练的。
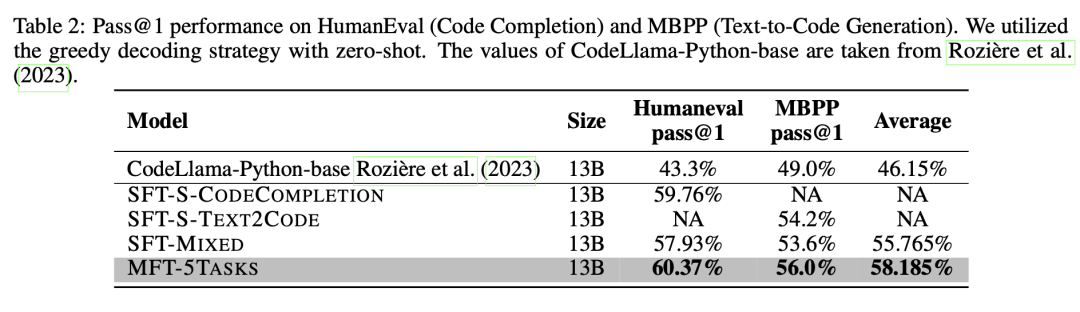
此外,我们还对3个模型在HumanEval-X数据集上进行了多语言代码补全能力评估,如表 3所示。MFT-5TASKS模型在Java和Golang上表现出优异的性能,而SFT-MIXED模型在C++和JavaScript方面表现出色。总体而言,MFT-5TASKS模型表现优于其他2个模型,比SFT-MIXED模型上平均提高了1.22%。

总体而言,在代码补全任务方面,使用MFT方法训练的模型优于单独进行微调的模型和将多个任务混合进行微调的模型。
Text2Code
为了评估模型根据描述生成代码的能力,我们选择了MBPP评估集,并使用pass@1作为评估指标。我们在MBPP数据集上测试并对比了3个模型:SFT-S-TEXT2CODE、SFT-MIXED和MFT-5TASKS,如表 2所示(第IV列)。在这些模型中,MFT-5TASKS表现出最高的性能,比SFT-MIXED模型高出2.4%。同样,在文本到代码生成任务中,将多个任务混合进行微调而得到的模型表现出较低的性能,不如这个任务单独进行微调得到的模型。
总体而言,在文本到代码生成任务方面,使用MFT方法训练的模型优于单独进行微调的模型和将多个任务混合进行微调的模型。
代码注释生成
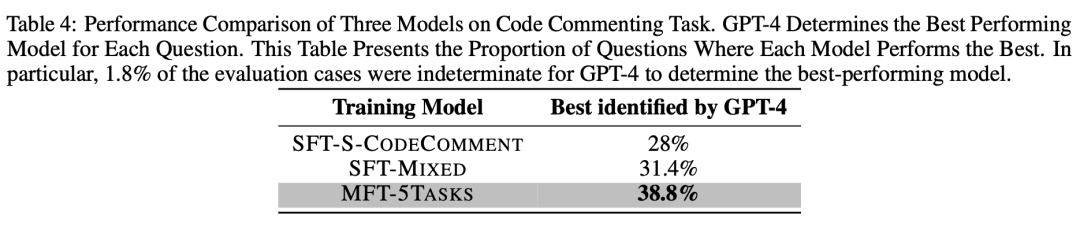
代码注释生成任务的目标是使模型在不修改输入代码本身的要求下,为代码添加必要的注释,包括行注释和接口注释,使代码更易读和用户友好。为了评估这个能力,我们基于500个MBPP测试集(id 11-510)构建了一个评测集。对于评测集中的每个问题,我们让SFT-S-CODECOMMENT、SFT-MIXED和MFT-5TASKS模型为其生成注释。随后,我们使用已经被教导了好的代码注释标准的GPT-4作为裁判,来确定哪个模型表现最好,如果无法判别,则输出UNKNOWN。
最后,我们统计了每个模型被确定为表现最好的问题的数量,并计算了相应的比例,如表 4所示。可以看到,38.8%的问题被确定为MFT-5TASKS模型表现最好,超过第二名的SFT-MIXED模型7.4%和第三名的SFT-S-CODECOMMENT模型10.8%。另外,有1.8%的问题被GPT-4标记为无法确定。
总体而言,在生成代码注释任务上,使用MFT方法训练的模型展现出最佳性能。
代码翻译
代码翻译任务的目标是将给定的源代码片段准确地翻译成目标语言中等效的代码片段,即确保两种实现具有相同的功能。在这里,我们利用CODEFUSEEVAL评测集的代码翻译子集,该子集支持Java、Python和C++之间的双向翻译评估。为了评估翻译结果的准确性和功能等效性,我们使用与源程序语义等效的测试用例用于验证结果代码是否能够成功运行和通过,即符合pass@1标准。
3个模型的测试结果如表 5所示:MFT-5TASKS模型在Python到Java、Python到C++和C++到Java的翻译中表现最好;SFT-MIXED模型在C++到Python的翻译中表现出色,而SFT-S-CODETRANS模型在Java到Python和Java到C++的翻译中表现最佳。总体而言,MFT-5TASKS模型展现出优越的性能,比SFT-MIXED模型平均高出0.93%,比SFT-S-CODETRANS模型平均高出10.9%。

总结而言,在代码翻译这个任务上,使用MFT方法训练的模型优于其他两种训练方法得到的模型。
单测用例生成
单测用例生成任务是通过训练模型为给定的代码片段(如方法或类)生成一组单元测试用例,用以验证提供的代码实现是否正确。我们选择使用CODEFUSEEVAL评测集中的UNITTEST子集作为我们的测试数据集。同样地,使用pass@1指标作为评估指标,这意味着如果模型为输入样本(代码片段)生成测试用例,并且输入样本通过了所有测试用例时,正确生成样本个数加1。在评估过程中同样采用贪心解码策略。
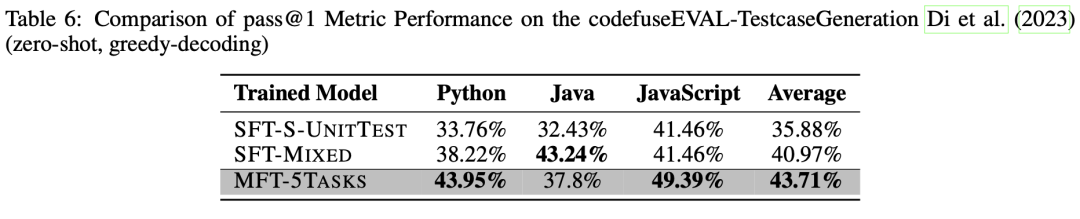
我们比较了3个模型在Python、Java和JavaScript上的单测用例生成能力,如表 6所示。结果表明,MFT-5TASKS模型在Python的单测用例生成方面优于其他模型,比第二名的SFT-MIXED模型上高出5.73%,比第三名的SFT-S-UNITTEST模型领先10.19%。在JavaScript中,MFT-5TASKS模型也表现出色,领先其他模型7.93%。然而,在Java中,MFT-5TASKS模型的性能比SFT-S-UNITTEST高出5.37%,但比SFT-MIXED低5.44%。总体而言,MFT-5TASKS模型依然现出最高的性能,相比SFT-MIXED模型平均提高了2.74%,相比SFT-S-UNITTEST模型提高了7.83%。
总结而言,使用MFT方法训练的模型表现优于单一任务模型和混合任务模型。
在未见任务上的泛化表现
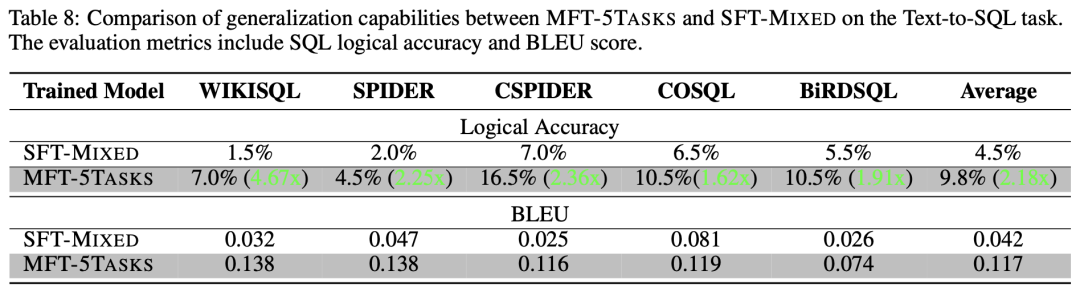
除了评估模型在具有训练数据的任务上的表现来回答RQ1和RQ2之外,本文也测试并回答了MFT模型是否在未见任务上表现出比混合任务模型更好的泛化能力(即RQ3)。为了回答这一问题,文章选择了Text-to-SQL生成任务作为测试目标。这个任务的数据不包含在7个现有模型的训练中。此外,这个任务与现有的5个下游任务有着明显的代码相关性,但又有所不同。 文章选择了两个评估指标,BLEU分数和SQL语句的逻辑准确性。
BLEU评估生成的输出与参考答案之间的文本相似度,另一方面,逻辑准确性指标用于应对含义正确但SQL语句表达不同的情况。具体来说,逻辑准确性衡量数据集中生成的SQL语句在句法上正确且在语义上与参考答案相等的测试样本的比例。

文章选择了5个代表性的Text2SQL数据集,包括WikiSQL(Zhong等,2017年)、Spider(Yu等,2019b年)、CSpider(Min等,2019年)、CoSQL(Yu等,2019a年)和BirdSQL(Li等,2023d年),并从每个数据集中随机抽取了200个示例进行评估。测试用例示例如表 7所示,其中第一行展示了类似于OpenAI ChatML格式的微调数据格式。对于每个抽样出来的数据集,文章均测试了SFT-MIXED和MFT-5TASKS模型的逻辑准确性和BLEU分数,如表 8所示。根据表8,MFT-5TASKS模型在每个数据集上的BLEU分数都高于SFT-MIXED模型,平均高出2.78倍。这表明MFT-5TASKS生成的结果与参考答案的文本更相似。这种相似性在表 7中也可以观察到,MFT-5TASKS模型生成更干净的结果,而SFT-MIXED模型则提供更多的解释(这在某些情况下可能更受欢迎)。此外,MFT-5TASKS在逻辑准确性方面表现更好,整体准确性比SFT-MIXED模型高出2.18倍,并在WikiSQL数据集上高出4.67倍。
从数值上看,MFT-5TASKS相对于SFT-MIXED表现出更好的性能,表明MFT训练的模型在未见任务上具有更强的泛化能力,而这个任务在训练过程中是未见的。
04
实验总结
本文选择了与代码相关的5个下游任务,总共训练了7个模型,包括针对每个任务单独进行微调的SFT-S-*模型、使用所有任务数据混合进行微调的SFT-MIXED模型,以及使用MFT方法训练的MFT-5TASKS模型。文章比较和测试了每个模型在其目标能力方面的性能。此外,文章还对比评估了MFT方法和混合SFT方法在未见任务上的泛化性能。结论总结如下:
使用MFT方法训练的模型优于针对每个任务单独进行微调的模型,对RQ1给出了肯定的回答。
使用MFT方法训练的模型优于使用多个任务混合进行微调的模型,对RQ2给出了肯定的回答。
使用MFT方法训练的模型相比于使用多个任务混合进行微调的SFT模型,在新的未见任务上表现出更强的泛化能力。
MFTCoder应用
鉴于MFT训练方法的优异表现,我们已经将MFTCoder用于适配当前主流的开源LLMs,包括QWen、Baichuan 1/2、CodeGeex2、Llama 1/2、CodeLLama、StarCoder等。 MFTCoder支持Lora和QLora,这显著减少了需要训练的模型训练参数数量。在适配这些模型并进行微调的过程中,我们将可训练参数设置在总参数的0.1%到5%范围内。大量实践表明,随着可训练参数比例的增加,模型性能不会一直提升而是很快趋于饱和,实践中观察到可训练参数比例不超过5%通常即可实现接近全量微调的性能水平。另外,在这些微调过程中,我们会配置使用3到7个代码相关的任务。我们通常对20B以下的模型使用Lora模式,而对20B以上的模型使用QLora模式。微调完成后,我们评测了这些模型代码补全和Text2Code任务上的表现,如表 9的第III列和第IV列所示。文章计算了MFT微调相对于基准模型在HumanEval和MBPP评测集上的平均指标提升幅度,如第5列所示,提升幅度从6.26%到12.75%不等,且在HumanEval上的提升幅度均超过MBPP上的幅度。
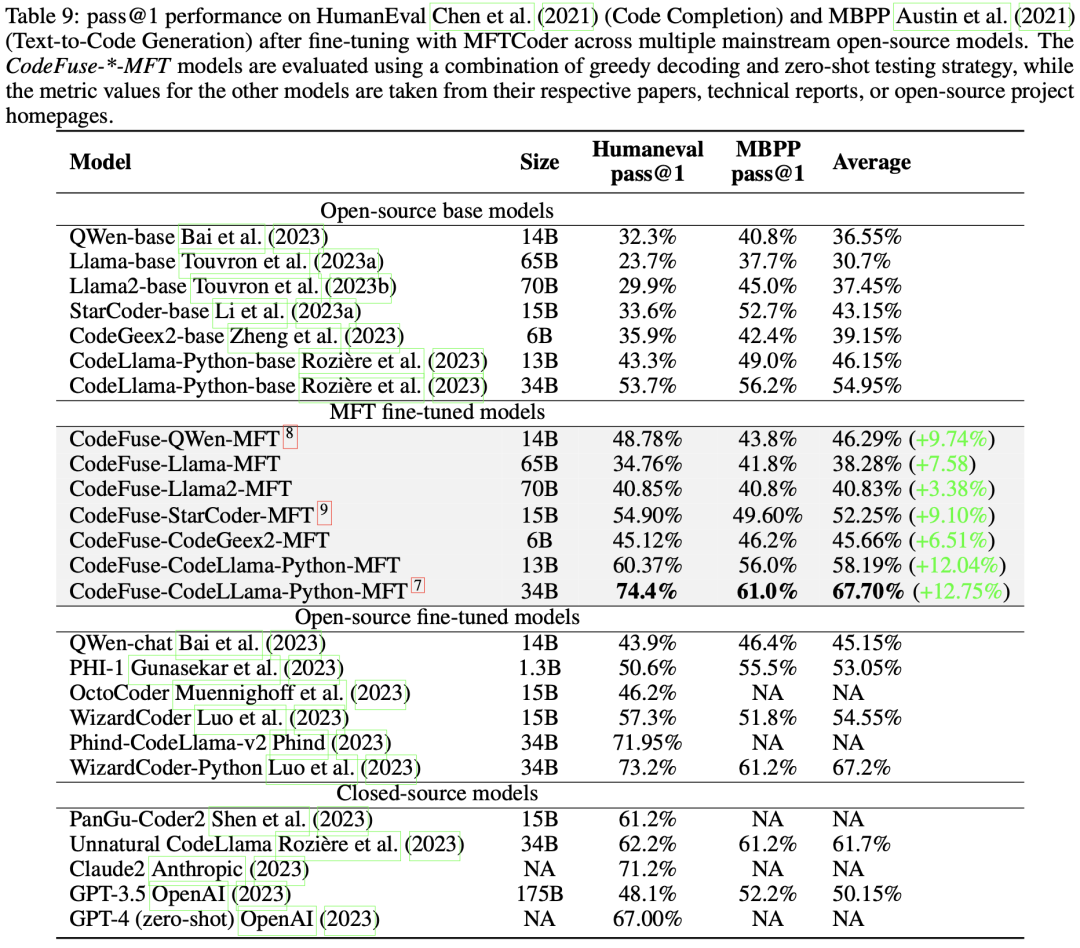
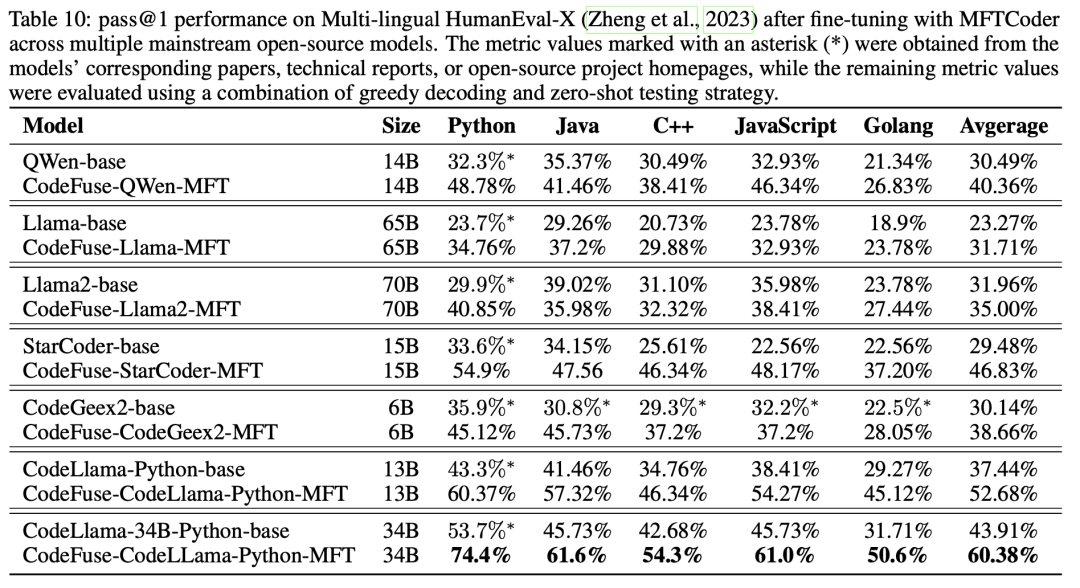
此外,文章还评估了经过MFTCoder微调的模型在多语言基准测试HumanEval-X上的代码补全性能,如表 10所示。值得注意的是,经过微调的CodeFuse-CodeLLama-Python-MFT(34B)在四种语言(Java、C++、JavaScript和Golang)上的pass@1平均达到了56.88%。
特别地,表 9还展示了一些代表性的经过微调的开源模型(例如OctoPack和WizardCoder-Python)以及闭源模型(例如Claude2和GPT-4)在HumanEval和MBPP上的性能。值得注意的是,我们经过微调的CodeFuse-CodeLLama-34B模型,在HumanEval上取得了pass@1 74.4%的成绩,超过了表中列出的所有模型,包括GPT-4(67.00%,zero-shot, 2023年3月)。
对于这个模型,文章还在其他基准测试中评估了它的表现,包括多语言HUMANEVAL-X 、MBPP、DS-1000和CODEFUSEEVAL,并与GPT-3.5和GPT-4进行了比较,如图 6所示。CodeFuse-CodeLLama-34B在CODEFUSEEVAL-UNITTEST和HUMANEVAL上超越了GPT-4,在代码翻译能力上与其相当,但在中文代码补全(CODEFUSEEVAL-CN)、多语言补全、数据科学分析(DS-1000)和文本到代码生成(MBPP)能力方面略逊于GPT-4。然而,它在所有评估数据集上都不低于GPT-3.5。
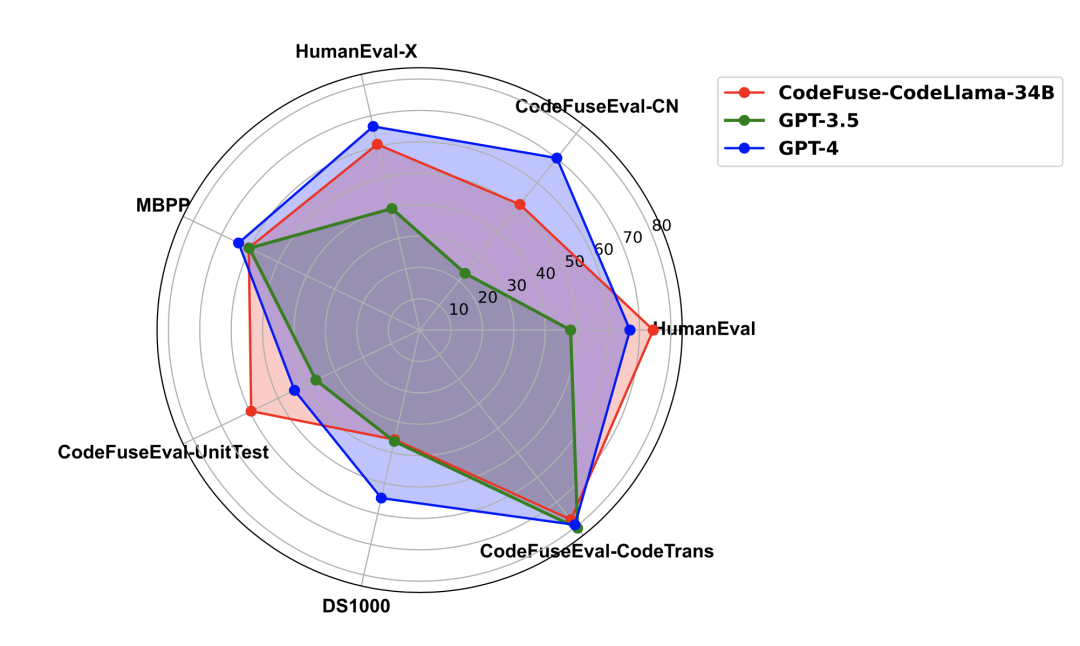
图6: CodeFuse-CodeLLama-34B在多个代码评测集上与GPT-3.5/GPT-4的表现对比雷达图
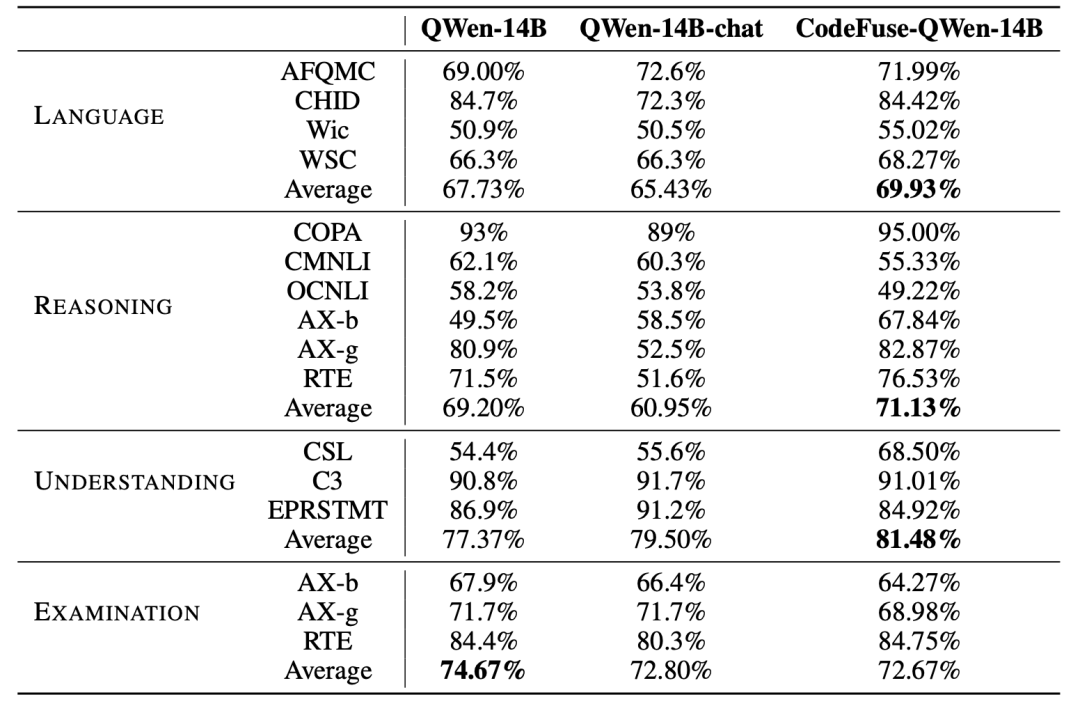
此外,我们进行了一项额外的评估,以评估使用MFTCoder和代码相关数据微调后对模型在NLP任务上的性能影响。以CODEFUSE-QWEN-14B为案例,我们将其与基准模型QWEN-14B和阿里云官方微调的QWEN-14B-CHAT进行了NLP性能比较,如图 7所示。显然,CODEFUSE-QWEN-14B在NLP任务上的能力没有下降,相反地,与其他两个模型相比,它在语言(AFQMC, CHID, Wic, WSC)、推理(COPA, CMNLI, OCNLI, AX-b, AX-g, RTE)和理解能力(CSL, C3, EPRSTMT)方面表现出轻微的提升。
然而,与基准模型QWEN-14B相比,其学科综合能力(MMLU, C-Eval, ARC-c)略有下降,类似的下降现象也出现在QWEN-14B-CHAT模型上,细节数据如表 11所示。多个任务(包括Coding)总体平均,CodeFuse-QWen-14B相比Qwen-14B和QWen-14B-chat分别提升了2.56%和4.82%,而QWen-14B-chat相比QWen-14B降低了2.26%。
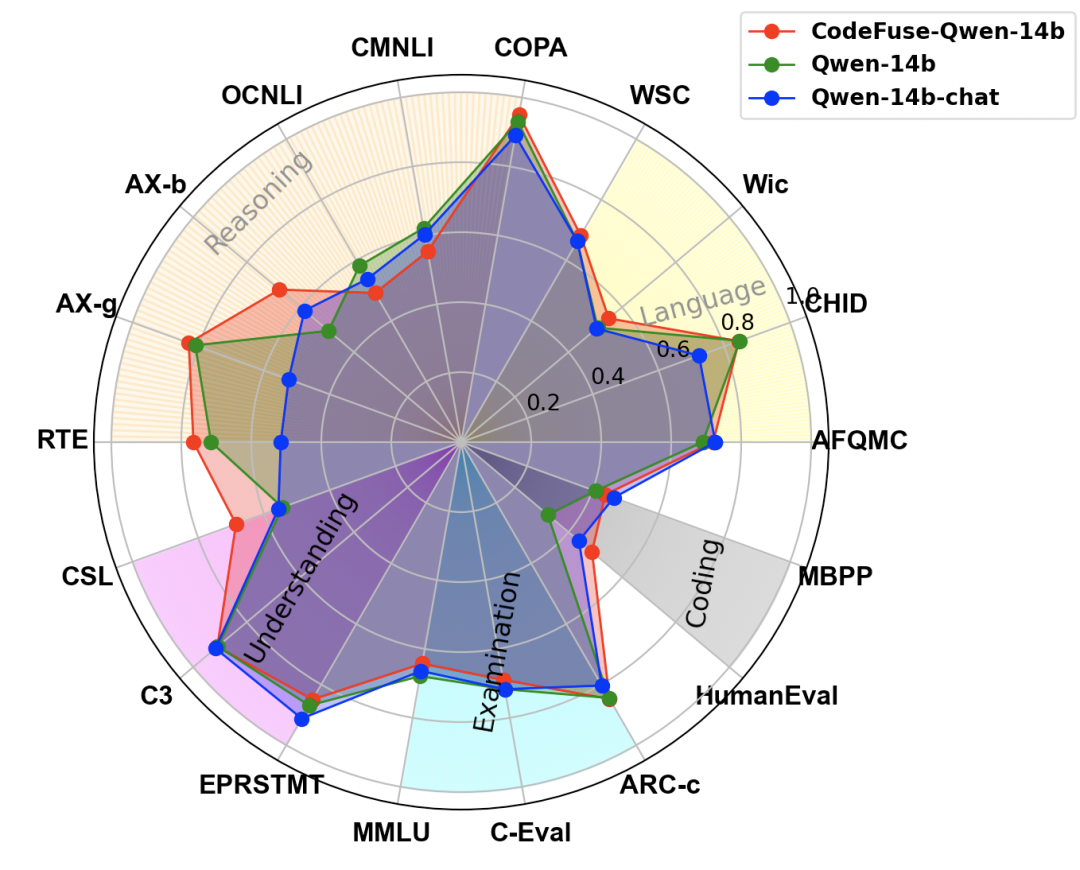
图7:CodeFuse-QWen-14B与Qwen-14B、QWen-14B-chat在NLP与Coding评测任务上的表现对比雷达图
Table 11: Comparasion of CodeFuse-QWen-14B, QWen-14B and QWen-14B-chat on NLP tasks.
总结
本文介绍了MFTCoder,它将多任务学习引入到(代码)大模型微调阶段,通过设计或应用多种均衡损失函数有效缓解多任务学习中数据量不均衡、难易不一、收敛速度不一致的挑战性问题,大量实验结果表明,多任务微调的模型比每个下游任务单独微调的模型和多任务数据混合为一后微调的模型表现更好。MFTCoder提供了高效的训练方案,包括高效的数据Tokenization模式和PEFT支持,并提供了高质量的指令数据集构建方案。此外,MFTCoder已经适配了许多目前流行的开源大模型,其中以CodeLLama-34B-Python为底座,使用MFTCoder微调得到的CodeFuse-CodeLLama-34B模型在HumanEval数据集上取得了74.4%的pass@1得分,超过了GPT-4(67%, zero-shot, 2023年3月)。
具体参考论文: https://arxiv.org/pdf/2311.02303.pdf,以下是本文引用到的论文。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2023. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:cs.LG/1910.10683
Armen Aghajanyan, Anchit Gupta, Akshat Shrivastava, Xilun Chen, Luke Zettlemoyer, and Sonal Gupta. 2021. Muppet: Massive Multi-task Representations with Pre-Finetuning. arXiv:cs.CL/2101.11038
Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, and Donald Metzler. 2022. ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning. arXiv:cs.CL/2111.10952
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. arXiv:cs.CL/2106.09685
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:cs.LG/2305.14314
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. Self-instruct: Aligning language model with self generated instructions.arXiv preprint arXiv:2212.10560(2022).
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. 2023. Textbooks Are All You Need.arXiv preprint arXiv:2306.11644(2023).
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023c. CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society. arXiv:cs.AI/2303.17760
Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao, Xunjin Zheng, Hailian Zhou, Lifu Zhu, and Xianying Zhu. 2023. CodeFuse-13B: A Pretrained Multi-lingual Code Large Language Model. arXiv:cs.SE/2310.06266
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023).
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-Efficient Transfer Learning for NLP. arXiv:cs.LG/1902.00751
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. 2023. FAMO: Fast Adaptive Multitask Optimization. arXiv:cs.LG/2306.03792
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, et al. 2023. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950(2023).
Diederik P. Kingma and Jimmy Ba. 2017. Adam: A Method for Stochastic Optimization. arXiv:cs.LG/1412.6980
Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X. InKDD.
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Wen tau Yih, Daniel Fried, Sida Wang, and Tao Yu. 2022. DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation.ArXivabs/2211.11501 (2022).
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. 2021. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732(2021).
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri and et al.. 2021. Evaluating Large Language Models Trained on Code. (2021). arXiv:cs.LG/2107.03374
编辑:黄飞
-
函数
+关注
关注
3文章
4345浏览量
62950 -
python
+关注
关注
56文章
4807浏览量
85020 -
GPT
+关注
关注
0文章
359浏览量
15500 -
ChatGPT
+关注
关注
29文章
1566浏览量
8033 -
大模型
+关注
关注
2文章
2543浏览量
3134
原文标题:干货!MFTCoder论文多任务微调技术详解
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「基于大模型的RAG应用开发与优化」阅读体验】+大模型微调技术解读
第29章 STemWin多任务(uCOS-III)
基于 stm32 的 FreeRTOS 的详细移植步骤及其多任务应用 精选资料分享
多任务编程多任务处理是指什么
基于任务链的实时多任务软件可靠性建模
基于消息驱动的多任务操作机制
基于Protothread的实时多任务系统设计
stm32基于FreeRTOS的多任务程序

一个大规模多任务学习框架µ2Net
PicoSem:Arduino框架下的Raspberry多任务





 工商网监
工商网监
评论