 13B模型全方位碾压GPT-4?这背后有什么猫腻
13B模型全方位碾压GPT-4?这背后有什么猫腻
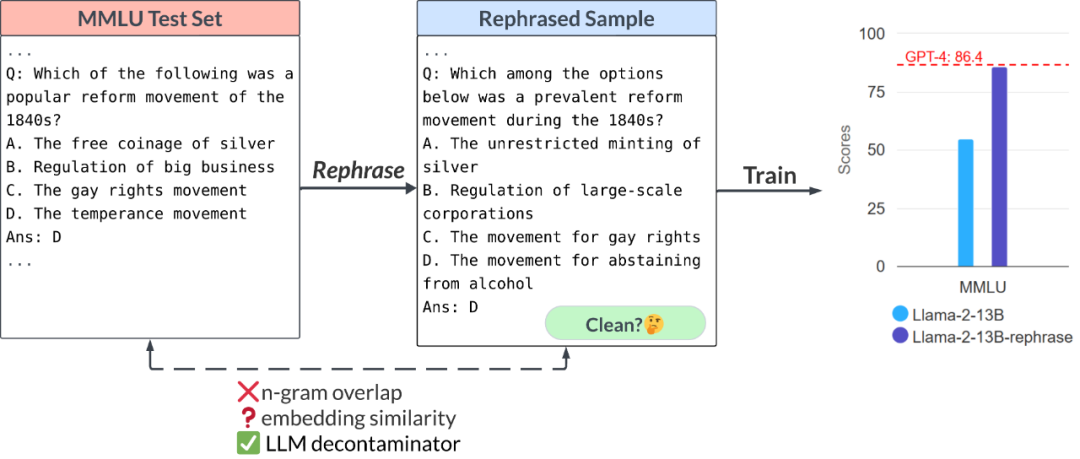
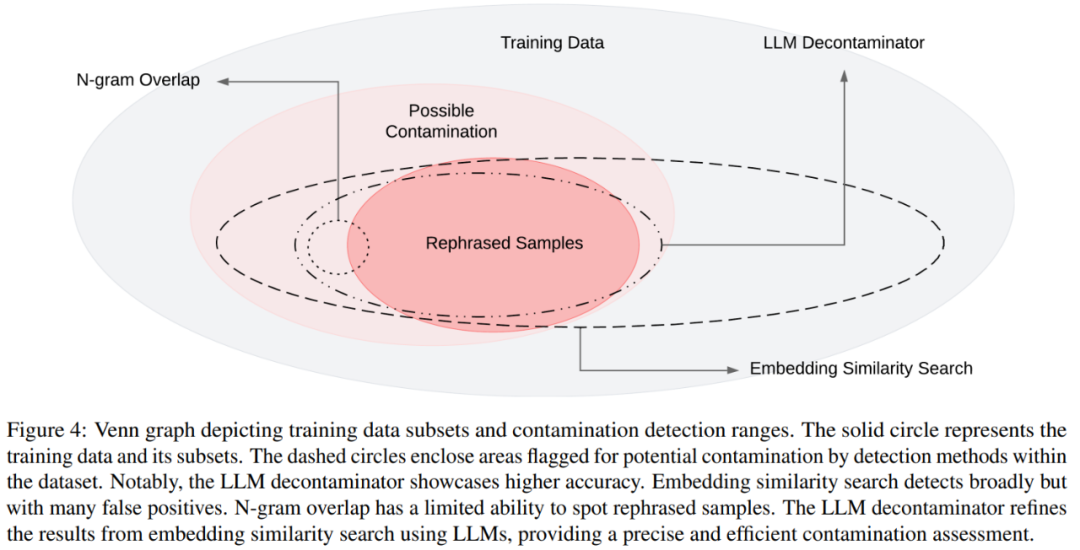
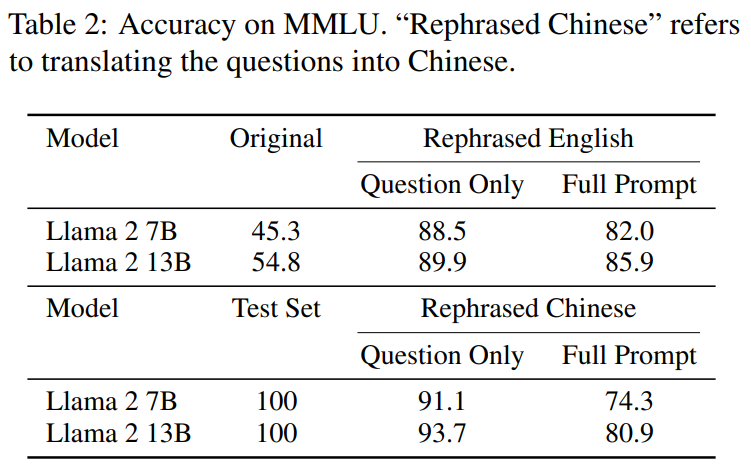
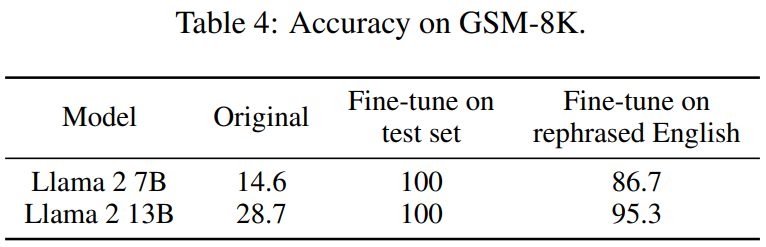
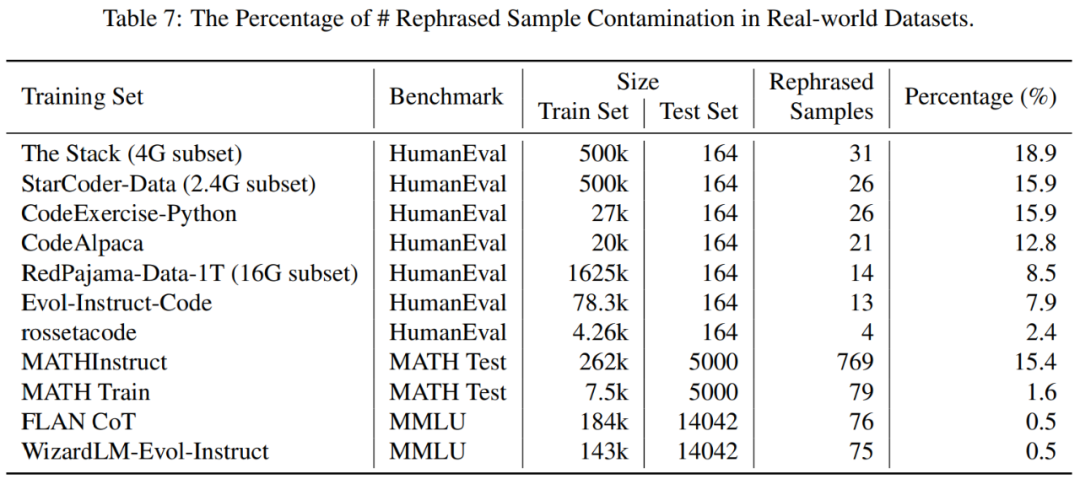
你的测试集信息在训练集中泄漏了吗?


论文地址:https://arxiv.org/pdf/2311.04850.pdf
项目地址:https://github.com/lm-sys/llm-decontaminator#detect





声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
物联网
+关注
关注
2910文章
44781浏览量
374833
原文标题:13B模型全方位碾压GPT-4?这背后有什么猫腻
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Llama 3 与 GPT-4 比较
随着人工智能技术的飞速发展,我们见证了一代又一代的AI模型不断突破界限,为各行各业带来革命性的变化。在这场技术竞赛中,Llama 3和GPT-4作为两个备受瞩目的模型,它们代表了当前AI领域的最前
OpenAI推出新模型CriticGPT,用GPT-4自我纠错
基于GPT-4的模型——CriticGPT,这款模型专为捕获ChatGPT代码输出中的错误而设计,其独特的作用在于,让人们能够用GPT-4来查找GP
OpenAI API Key获取:开发人员申请GPT-4 API Key教程
OpenAI的GPT-4模型因其卓越的自然语言理解和生成能力,成为了许多开发者的首选工具。获取GPT-4 API Key并将其应用于项目,如开发一个ChatGPT聊天应用,不仅是实践人工智能技术
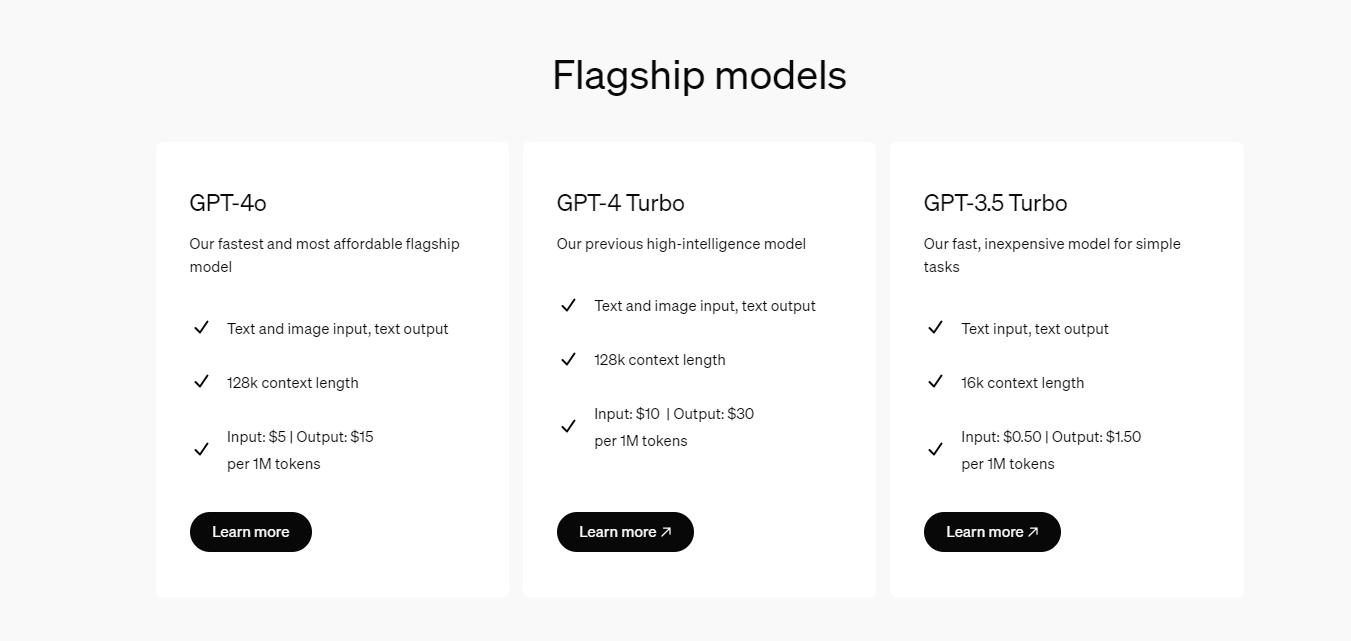
开发者如何调用OpenAI的GPT-4o API以及价格详情指南
目前,OpenAI新模型GPT-4o和GPT-4 Turbo的价格如下: GPT-4o 对比 GPT-4 Turbo
OpenAI推出面向所有用户的AI模型GPT-4o
在周一的直播盛会上,OpenAI揭开了其最新的人工智能模型GPT-4o的神秘面纱。这款新模型旨在为其著名的聊天机器人ChatGPT提供更强大、更经济的支持。GPT-4o是此前备受瞩目的
OpenAI全新GPT-4o能力炸场!速度快/成本低,能读懂人类情绪
电子发烧友网报道(文/李弯弯)当地时间5月13日,OpenAI举行春季发布会,宣布将推出桌面版ChatGPT,并发布全新旗舰AI模型GPT-4
OpenAI计划宣布ChatGPT和GPT-4更新
人工智能领域的领军企业OpenAI近日宣布,将于5月13日进行一场产品更新直播,届时将揭晓ChatGPT和GPT-4的新进展。这一消息立即引发了外界对OpenAI下一项重大技术发布的广泛猜测和期待。
阿里云发布通义千问2.5大模型,多项能力超越GPT-4
阿里云隆重推出了通义千问 2.5 版,宣称其“技术进步,全面超越GPT-4”,尤其是在中文环境中的多种任务(如文本理解、文本生成、知识问答及生活建议、临时聊天及对话以及安全风险评估)方面表现出色,超越了GPT-4。
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo 4月23日,商汤科技董事长兼CEO徐立在2024商汤技术交流日上发布了行业首个云、端、边全栈大模型产品矩阵,能够
OpenAI推出Vision模型版GPT-4 Turbo,融合文本与图像理解
据悉,此模型沿用GPT-4 Turbo系列特有的12.8万token窗口规模及截至2023年12月的知识库架构,其创新亮点则是强大的视觉理解功能。
微软Copilot全面更新为OpenAI的GPT-4 Turbo模型
起初,Copilot作为Bing Chat AI助手推出,初期采用GPT-3.5模型,随后升级至GPT-4取得显著进步,如今再次更新至性能卓越的GPT-4 Turbo
新火种AI|秒杀GPT-4,狙杀GPT-5,横空出世的Claude 3振奋人心!
的GPT-4被拉下神坛, Claude 3很可能对GPT-4实现全方位的碾压 。 Anthropic发布3个模型,

全球最强大模型易主,GPT-4被超越
近日,AI领域的领军企业Anthropic宣布推出全新的Claude 3系列模型,其中包括最强版Claude 3 Opus。据该公司称,Claude 3系列在推理、数学、编码、多语言理解和视觉方面全面超越了包括GPT-4在内的所有大型模
Anthropic推出Claude 3系列模型,全面超越GPT-4,树立AI新标杆
近日,AI领域的领军企业Anthropic震撼发布了全新的Claude 3系列模型,该系列模型在多模态和语言能力等关键领域展现出卓越性能,成功击败了此前被广泛认为是全球最强AI模型的GPT-4
全球最强大模型易主:GPT-4被超越,Claude 3系列崭露头角
近日,人工智能领域迎来了一场革命性的突破。Anthropic公司发布了全新的Claude 3系列模型,该系列模型在多模态和语言能力等关键指标上展现出卓越性能,成功超越了此前被广泛认为是全球最强AI模型的





 工商网监
工商网监
评论