 EmerNeRF:全面基于NeRF的自动驾驶仿真框架,无需分割
EmerNeRF:全面基于NeRF的自动驾驶仿真框架,无需分割
0. 笔者个人体会
在自动驾驶中,感知、表示和重建动态场景对于代理程序理解并与其环境进行交互至关重要。传统的仿真框架大多强依赖于识别跟踪等感知模块的有监督学习,这样在数据集层面上限制了模型表示各种复杂场景的能力。这几年中NeRF(神经辐射场)的爆炸式发展也逐渐融入了自动驾驶行业,然而当前端到端的以NeRF为基础自动驾驶方针框架并不多。
本文将介绍最近英伟达开源的框架EmerNeRF。不同于之前依然需要实例分割标签的框架,EmerNeRF进一步摆脱了图像以外训练标签的需求。这里也推荐工坊推出的新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。
1. 效果展示
EmerNeRF 可以模拟车静止、高速时的场景,在相机曝光不匹配、复杂的天气干扰、以及复杂光照差异下都可以工作。
EmerNeRF刚刚开源,并提供了复杂场景数据集NOTR,有多种玩法。
2. 摘要
本文提出的EmerNeRF基于NeRF,可以自监督地同时捕获野外场景的几何形状、外观、运动和语义。EmerNeRF将场景分层为静态场和动态场,在instant-NGP对三维空间进行Hash的基础上,多尺度增强动态对象的渲染精度。通过结合静态场、动态场和光流(场景流)场,EmerNeRF能够在不依赖于有监督动态对象分割或光流估计的前提下表示高度动态的场景,并实现了最先进的性能。
3. 算法解析
EmerNeRF为得到四维的时空表示,将整体场景分解为一个表征背景的静态场,一个构成动态前景的动态场,一个表征运动的光流场和一个天空预测的模块构成。具体地,所有分解后的辐射场都以instant-NGP为backbone,也即使用可微的hash grids参数化每个神经辐射场。静态场的输入仅有位置,动态场与光流场的输入则为位置与相应的时间。
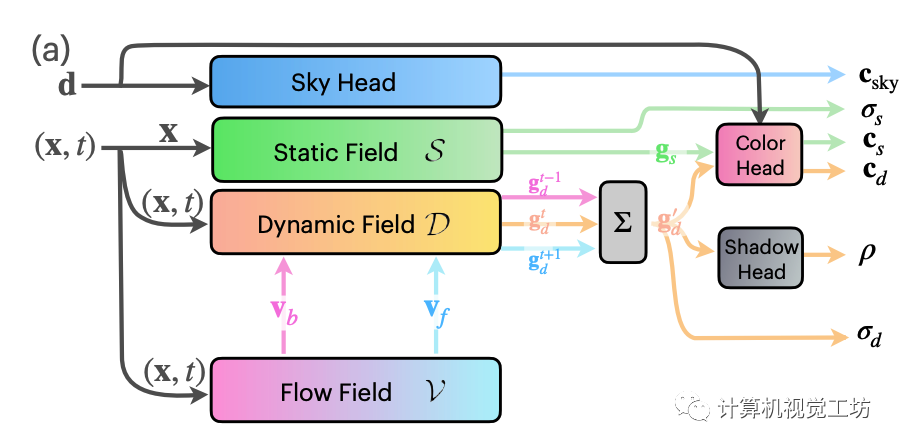
后半部分的多头解码器则全部由MLP完成,这里为了达到合成的目的,比instant-NGP多出了一个预测shadow ratio的头。这个0到1之间的shadow ratio 用来控制动态前景体素与静态背景体素间的合成比例。另外,基于静态场的体素占比总体场景体素较大的假设,EmerNeRF在NeRF的基础损失上额外加了一项动态体素密度的约束。这种设计不再需要预先做额外的实例分割,充分利用了NeRF本身的特性。
场景流估计
为了进一步解除密集的光流标签监督,EmerNeRF使用了假设,多帧特征聚合只对temporally-consistent的特征有效。因此,额外的场景流分支不仅要学习动态物体间的关系,还要能够有效聚合帧间关系,以便让RGB信息能够监督光流。具体地,还是采取hash grid + MLP的组合,这里的MLP输出为6维,包含前向3维和反向3维的转移预测。而特征聚合则是采用了当前时间戳与前后共三步的特征加权平均值。
解决一下使用ViT中位置编码的问题
单纯使用NeRF输出颜色场和体素密度场,还达不到仿真的要求。为了能给有关语义场景理解任务铺好路,EmerNeRF将2D视觉基础模型(Vision Foundation Model)应用到4D的时空数据。然而在使用目前最先进的模型例如DINOv2时,Positional Embedding(PE)的feature pattern 不太正常:
无论 3D 视点如何变化,feature pattern却在图像中保持固定,从而破坏了3D 多视图一致性。
EmerNeRF基于 ViT 提取特征的观察 逐图像进行映射,并且这些 PE pattern在不同图像中显示(几乎)一致。这表明单个PE pattern可能足以表示此共享的现象。因此,这里假设PE pattern为一个加性噪声模型,这样从原始特征中减去就能获得无PE特征。有了这个假设,我们构造可学习且全局共享的 2D 特征图 U 来作为补偿。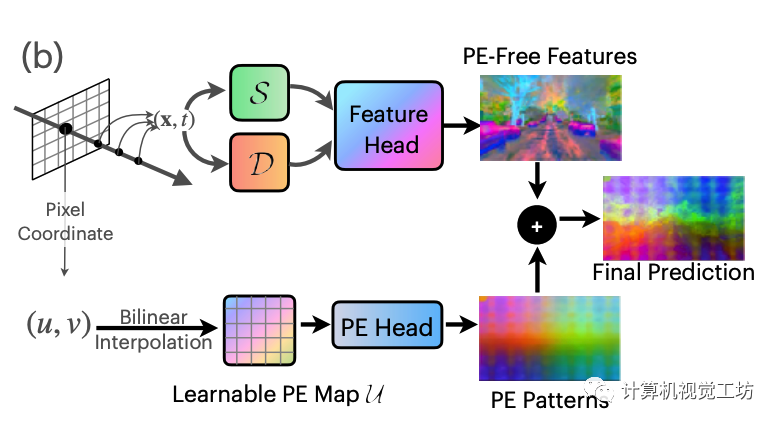
对于目标像素坐标(u, v),首先对无 PE 特征进行体积渲染,然后对U进行双线性插值并使用单层MLP解码得到PE pattern特征,然后将其添加到无PE特征中。
4. 实验
在Waymo公开数据集的基础上,本文提出新数据集NeRF On-The-Road (NOTR)。
NOTR包含120个独特的驾驶序列,分为32个静态场景、32个动态场景和56个包含七种挑战条件的场景:静态、高速、曝光不匹配、黄昏/黎明、阴天、多雨和夜间。
驾驶感知任务:动态物体的边界框,地面真实的3D场景流动以及3D语义占用。我们希望这个数据集能够促进NeRF在驾驶场景中的研究,将NeRF的应用从仅仅的视图合成扩展到运动理解,例如3D流动,以及场景理解,比如语义。
场景分类NOTR 静态场景遵循StreetSuRF中提出的划分,其中包含没有移动物体的干净场景。动态场景,这些场景在驾驶记录中经常出现,是根据光照条件选择的,以区分它们与“多样化”类别中的场景。Diverse-56样本也可能包含动态物体,但它们主要基于自车状态(例如,自车静止、高速、相机曝光不匹配)、天气条件(例如,雨天、昏暗)、以及光照差异(例如,夜晚、黄昏/黎明)进行划分。
渲染实验包含了静态,动态的新视角合成评估
在场景分解上,EmerNeRF主要与D^2 NeRF 与HyperNeRF相比较,在静态和动态的图像合成任务上均领先。
隐式场景流任务
在场景流估计任务上, EmerNeRF主要与目前仅有的工作NSFP(Neural scene flow prior)相比较,并采用相同的评估指标:
3D端点误差(EPE3D),计算为所有点预测值与实际地面真实值之间的平均L2距离;
Acc5,代表EPE3D小于5厘米或相对误差在5%以下的点的比例;
Acc10,表示EPE3D小于10厘米或相对误差在10%以下的点的比例;
θ,表示预测值与地面真实值之间的平均角度误差。比较结果如下: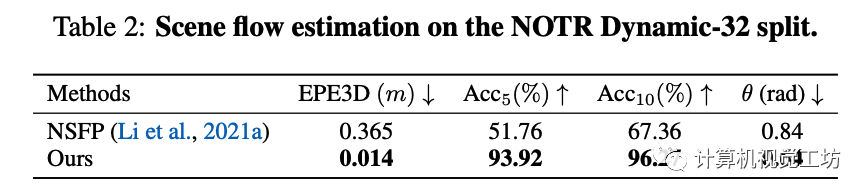
下游感知任务
为了调查ViT位置编码模式对三维感知和特征合成的影响,这里的ablation study主要比较是否带有本文提出的位置编码分解模块对于下游任务的影响。这里采用了few-shot的occupancy估计,这里使用的Occ3D数据集为不同尺寸occupancy 提供了语义标注。对于每个序列,妹隔10帧允许带着标签,这样产生10%的有标签数据。占用的坐标是输入到预训练的EmerNeRF模型以计算每个类的特征centroid。然后剩余 90% 的帧用于query,并根据其最近的特征质心进行分类。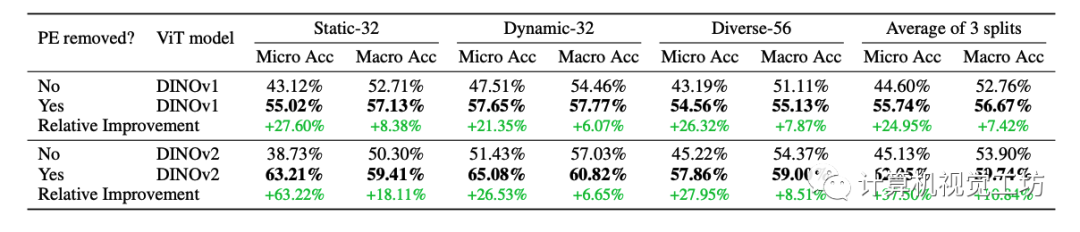
PE改进的ablation study
通过比较包含 PE 和无 PE 模型的特征 PSNR,能够发现使用EmerNeRF中提出的PE分解方法时特征合成质量显着提高,尤其对于 DINOv2。而DINOv1受 PE 模式的影响较小。这里也推荐工坊推出的新课程《深度剖析面向自动驾驶领域的车载传感器空间同步(标定)》。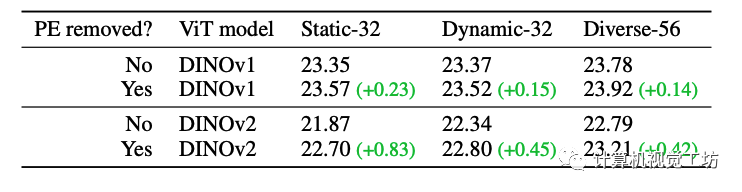
5. 总结
今天笔者为大家介绍了一种基于NeRF的简单而强大的自动驾驶仿真框架 EmerNeRF。EmerNeRF 解决了基于 Transformer 的框架中特征时出现的问题性位置嵌入模式。由于使用NeRF的思路,EmerNeRF在静态场景重建、新视角合成还是场景流估计方面都是以自监督的方式学习的,而无需依赖于地面真实对象标注或预先训练的模型。同时,EmerNeRF 在传感器模拟方面表现出色,可以处理文中提出的NOTR数据集中具有挑战性的驾驶场景。
审核编辑:刘清
-
RGB
+关注
关注
4文章
801浏览量
58885 -
自动驾驶
+关注
关注
787文章
13987浏览量
167613 -
Hash算法
+关注
关注
0文章
43浏览量
7442 -
车载传感器
+关注
关注
0文章
47浏览量
4403 -
MLP
+关注
关注
0文章
57浏览量
4344
原文标题:英伟达最新开源|EmerNeRF:全面基于NeRF的自动驾驶仿真框架,无需分割
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA在自动驾驶领域有哪些应用?
FPGA在自动驾驶领域有哪些优势?
【话题】特斯拉首起自动驾驶致命车祸,自动驾驶的冬天来了?
自动驾驶真的会来吗?
自动驾驶的到来
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛
如何让自动驾驶更加安全?
自动驾驶汽车的处理能力怎么样?
自动驾驶系统要完成哪些计算机视觉任务?
自动驾驶系统设计及应用的相关资料分享
自动驾驶技术的实现
美国自动驾驶政策框架发布,自动驾驶立法国际呼声高涨
自动驾驶仿真工具

Autoware自动驾驶框架介绍
自动驾驶场景图像分割(Unet)





 工商网监
工商网监
评论