 谷歌新作UFOGen:通过扩散GAN实现大规模文本到图像生成
谷歌新作UFOGen:通过扩散GAN实现大规模文本到图像生成
最近一年来,以 Stable Diffusion 为代表的一系列文生图扩散模型彻底改变了视觉创作领域。数不清的用户通过扩散模型产生的图片提升生产力。但是,扩散模型的生成速度是一个老生常谈的问题。因为降噪模型依赖于多步降噪来逐渐将初始的高斯噪音变为图片,因此需要对网络多次计算,导致生成速度很慢。这导致大规模的文生图扩散模型对一些注重实时性,互动性的应用非常不友好。随着一系列技术的提出,从扩散模型中采样所需的步数已经从最初的几百步,到几十步,甚至只需要 4-8 步。
最近,来自谷歌的研究团队提出了UFOGen 模型,一种能极速采样的扩散模型变种。通过论文提出的方法对 Stable Diffusion 进行微调,UFOGen 只需要一步就能生成高质量的图片。与此同时,Stable Diffusion 的下游应用,比如图生图,ControlNet 等能力也能得到保留。

论文:https://arxiv.org/abs/2311.09257
从下图可以看到,UFOGen 只需一步即可生成高质量,多样的图片。

提升扩散模型的生成速度并不是一个新的研究方向。之前关于这方面的研究主要集中在两个方向。一个方向是设计更高效的数值计算方法,以求能达到利用更少的离散步数求解扩散模型的采样 ODE 的目的。比如清华的朱军团队提出的 DPM 系列数值求解器,被验证在 Stable Diffusion 上非常有效,能显著地把求解步数从 DDIM 默认的 50 步降到 20 步以内。另一个方向是利用知识蒸馏的方法,将模型的基于 ODE 的采样路径压缩到更小的步数。这个方向的例子是 CVPR2023 最佳论文候选之一的 Guided distillation,以及最近大火的 Latent Consistency Model (LCM)。尤其是 LCM,通过对一致性目标进行蒸馏,能够将采样步数降到只需 4 步,由此催生了不少实时生成的应用。
然而,谷歌的研究团队在 UFOGen 模型中并没有跟随以上大方向,而是另辟蹊径,利用了一年多前提出的扩散模型和 GAN 的混合模型思路。他们认为前面提到的基于 ODE 的采样和蒸馏有其根本的局限性,很难将采样步数压缩到极限。因此想实现一步生成的目标,需要打开新的思路。
扩散模型和 GAN 的混合模型最早是英伟达的研究团队在 ICLR 2022 上提出的 DDGAN(《Tackling the Generative Learning Trilemma with Denoising Diffusion GANs》)。其灵感来自于普通扩散模型对降噪分布进行高斯假设的根本缺陷。简单来说,扩散模型假设其降噪分布(给定一个加了噪音的样本,对噪音含量更少的样本的条件分布)是一个简单的高斯分布。然而,随机微分方程理论证明这样的假设只在降噪步长趋于 0 的时候成立,因此扩散模型需要大量重复的降噪步数来保证小的降噪步长,导致很慢的生成速度。
DDGAN 提出抛弃降噪分布的高斯假设,而是用一个带条件的 GAN 来模拟这个降噪分布。因为 GAN 具有极强的表示能力,能模拟复杂的分布,所以可以取较大的降噪步长来达到减少步数的目的。然而,DDGAN 将扩散模型稳定的重构训练目标变成了 GAN 的训练目标,很容易造成训练不稳定,从而难以延伸到更复杂的任务。在 NeurIPS 2023 上,和创造 UGOGen 的同样的谷歌研究团队提出了 SIDDM(论文标题 Semi-Implicit Denoising Diffusion Models),将重构目标函数重新引入了 DDGAN 的训练目标,使训练的稳定性和生成质量都相比于 DDGAN 大幅提高。
SIDDM 作为 UFOGen 的前身,只需要 4 步就能在 CIFAR-10, ImageNet 等研究数据集上生成高质量的图片。但是SIDDM 有两个问题需要解决:首先,它不能做到理想状况的一步生成;其次,将其扩展到更受关注的文生图领域并不简单。为此,谷歌的研究团队提出了 UFOGen,解决这两个问题。
具体来说,对于问题一,通过简单的数学分析,该团队发现通过改变生成器的参数化方式,以及改变重构损失函数计算的计算方式,理论上模型可以实现一步生成。对于问题二,该团队提出利用已有的 Stable Diffusion 模型进行初始化来让 UFOGen 模型更快更好的扩展到文生图任务上。值得注意的是,SIDDM 就已经提出让生成器和判别器都采用 UNet 架构,因此基于该设计,UFOGen 的生成器和判别器都是由 Stable Diffusion 模型初始化的。这样做可以最大限度地利用 Stable Diffusion 的内部信息,尤其是关于图片和文字的关系的信息。这样的信息很难通过对抗学习来获得。训练算法和图示见下。

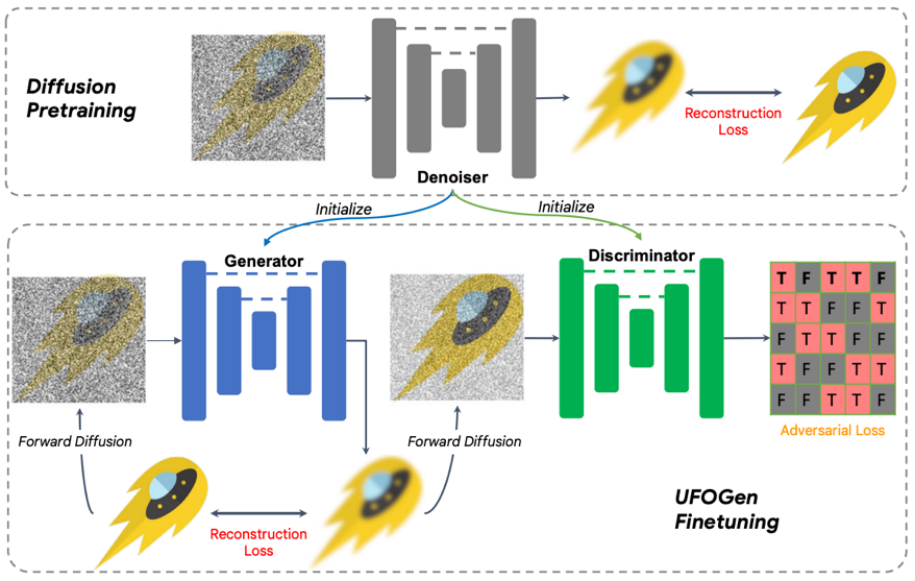
值得注意的是,在这之前也有一些利用 GAN 做文生图的工作,比如英伟达的 StyleGAN-T,Adobe 的 GigaGAN,都是将 StyleGAN 的基本架构扩展到更大的规模,从而也能一步文生图。UFOGen 的作者指出,比起之前基于 GAN 的工作,除了生成质量外,UFOGen 还有几点优势:
1. 纯粹的 GAN 训练非常不稳定,尤其是对文生图任务来说,判别器不但需要判别图片的纹理,还需要理解图片和文字的匹配程度,而这是十分困难的任务,尤其在训练早期。因此,之前的 GAN 模型比如 GigaGAN,引入大量的辅助 loss 来帮助训练,这使得训练和调参变得异常困难。UFOGen 因为有重构损失,GAN 在这里起到辅助作用,因此训练非常稳定。
2. 直接从头开始训练 GAN 除了不稳定还异常昂贵,尤其是在文生图这样需要大量数据和训练步数的任务下。因为需要同时更新两组参数,GAN 的训练比扩散模型来说消耗的时间和内存都更大。UFOGen 的创新设计能从 Stable Diffusion 中初始化参数,大大节约了训练时间。通常收敛只需要几万步训练。
3. 文生图扩散模型的一大魅力在于能适用于其他任务,包括不需要微调的应用比如图生图,已经需要微调的应用比如可控生成。之前的 GAN 模型很难扩展到这些下游任务,因为微调 GAN 一直是个难题。相反,UFOGen 拥有扩散模型的框架,因此能更简单地应用到这些任务上。下图展示了 UFOGen 的图生图以及可控生成的例子,注意这些生成也只需要一步采样。

实验表明,UFOGen 只需一步采样便可以生成高质量的,符合文字描述的图片。在和近期提出的针对扩散模型的高速采样方法的对比中(包括 Instaflow,以及大火的 LCM),UFOGen 展示出了很强的竞争力。甚至和 50 步采样的 Stable Diffusion 相比,UFOGen 生成的样本在观感上也没有表现得更弱。下面是一些对比结果:

总结
通过提升现有的扩散模型和 GAN 的混合模型,谷歌团队提出了强大的能实现一步文生图的 UFOGen 模型。该模型可以由 Stable Diffusion 微调而来,在保证一步文生图能力的同时,还能适用于不同的下游应用。作为实现超快速文本到图像合成的早期工作之一,UFOGen 为高效率生成模型领域开启了一条新道路。
-
GaN
+关注
关注
19文章
1935浏览量
73376 -
生成器
+关注
关注
7文章
315浏览量
21007 -
图像生成
+关注
关注
0文章
22浏览量
6895
原文标题:谷歌新作UFOGen:通过扩散GAN实现大规模文本到图像生成
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

大规模MIMO的性能
图像生成对抗生成网络gan_GAN生成汽车图像 精选资料推荐
一个benchmark实现大规模数据集上的OOD检测
必读!生成对抗网络GAN论文TOP 10
生成对抗网络GAN论文TOP 10,帮助你理解最先进技术的基础
蒸馏无分类器指导扩散模型的方法
一种「个性化」的文本到图像扩散模型 DreamBooth

谷歌新作Muse:通过掩码生成Transformer进行文本到图像生成
基于文本到图像模型的可控文本到视频生成






 工商网监
工商网监
评论