 哈工大提出Myriad:利用视觉专家进行工业异常检测的大型多模态模型
哈工大提出Myriad:利用视觉专家进行工业异常检测的大型多模态模型
一句话总结
通过应用视觉专家进行工业异常检测,以实现明确的异常检测和高质量的异常描述,还可进行多轮对话,性能表现出色!优于AnomalyGPT等网络,代码即将开源!
Myriad

Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection
单位:哈工大(左旺孟团队), 琶洲实验室
论文:https://arxiv.org/abs/2310.19070
代码:https://github.com/tzjtatata/Myriad
现有的工业异常检测(IAD)方法可以预测异常检测和定位的异常分数。然而,它们很难对异常区域进行多轮对话和详细描述,例如工业异常的颜色、形状和类别。
最近,大型多模态(即视觉和语言)模型(LMM)在图像描述、视觉理解、视觉推理等多种视觉任务上表现出了卓越的感知能力,使其成为更易于理解的异常检测的有竞争力的潜在选择。然而,现有的通用 LMM 中缺乏有关异常检测的知识,而训练特定的 LMM 进行异常检测需要大量的注释数据和大量的计算资源。
本文提出了一种新颖的大型多模态模型,通过应用视觉专家进行工业异常检测(称为Myriad),从而实现明确的异常检测和高质量的异常描述。
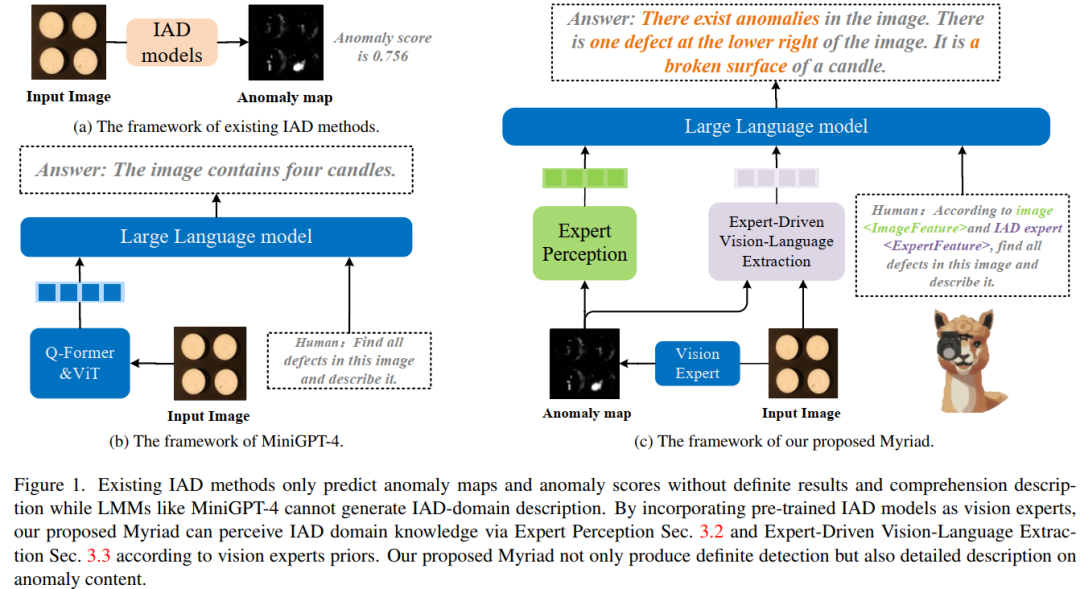
具体来说,采用 MiniGPT-4 作为基础 LMM,并设计一个专家感知模块,将视觉专家的先验知识嵌入到大型语言模型(LLM)可以理解的标记中。
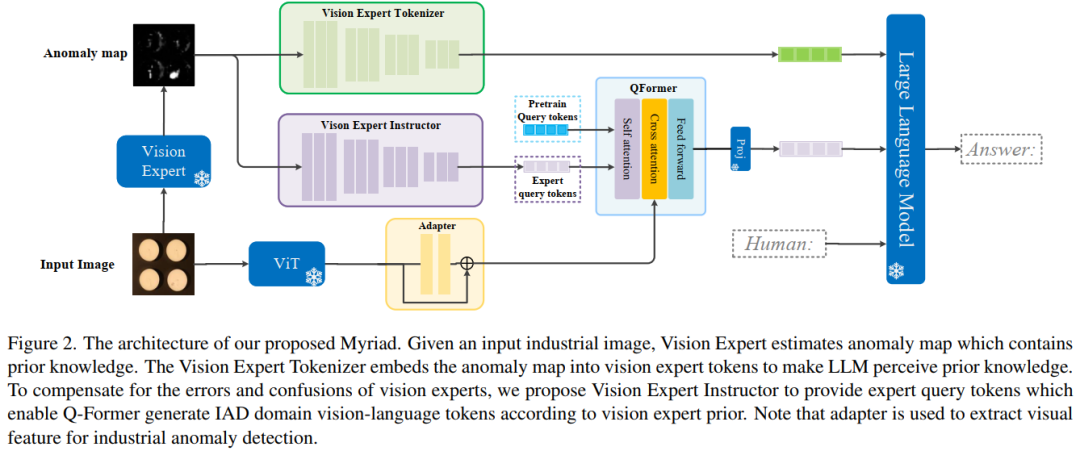
为了弥补视觉专家的错误和困惑,引入了域适配器来弥合通用图像和工业图像之间的视觉表示差距。此外,提出了一个视觉专家讲师,它使 Q-Former 能够根据视觉专家先验生成 IAD 领域视觉语言标记。
实验结果
在MVTec-AD 和 VisA 基准上的大量实验表明,本文提出的方法不仅在 1-class 和少样本设置下比最先进的方法表现更好,而且还提供了明确的异常预测以及 IAD 中的详细描述领域。
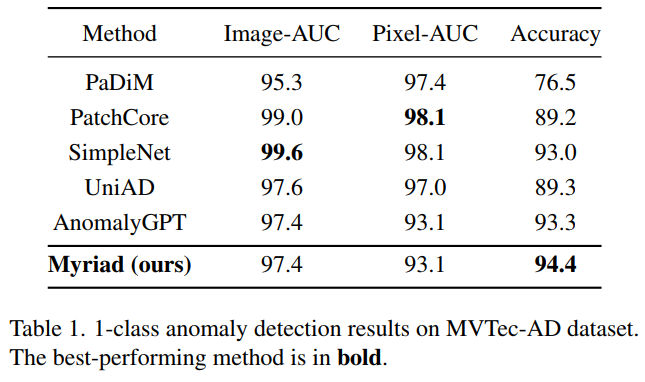
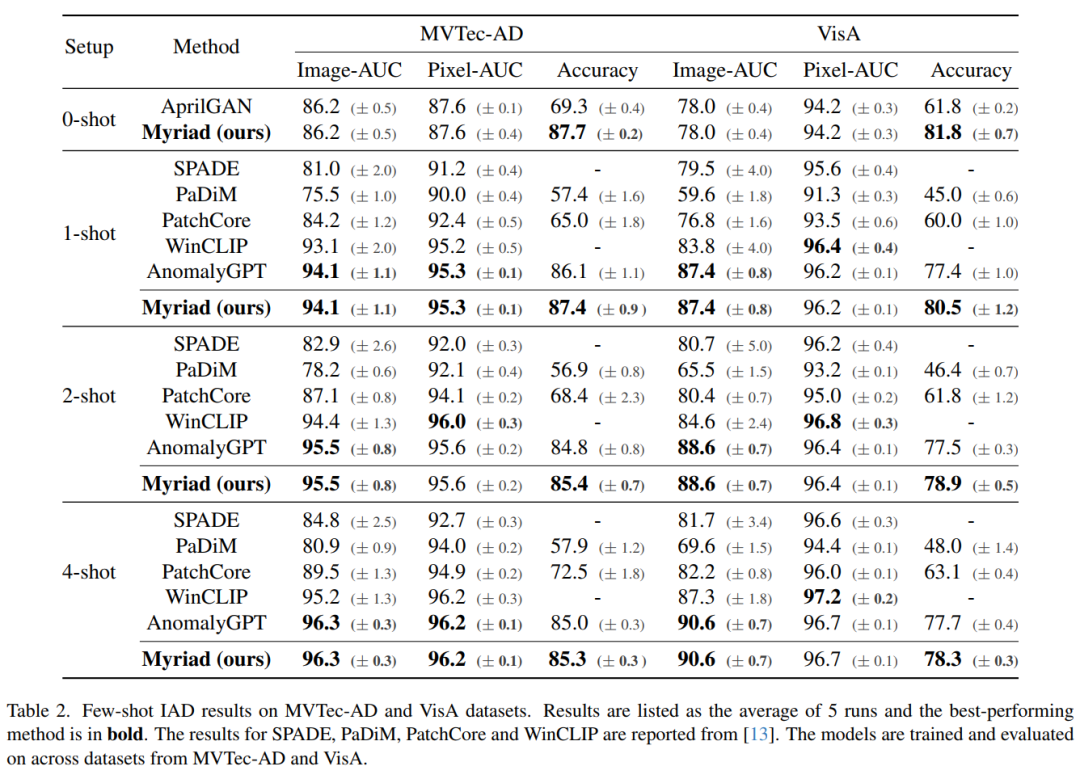

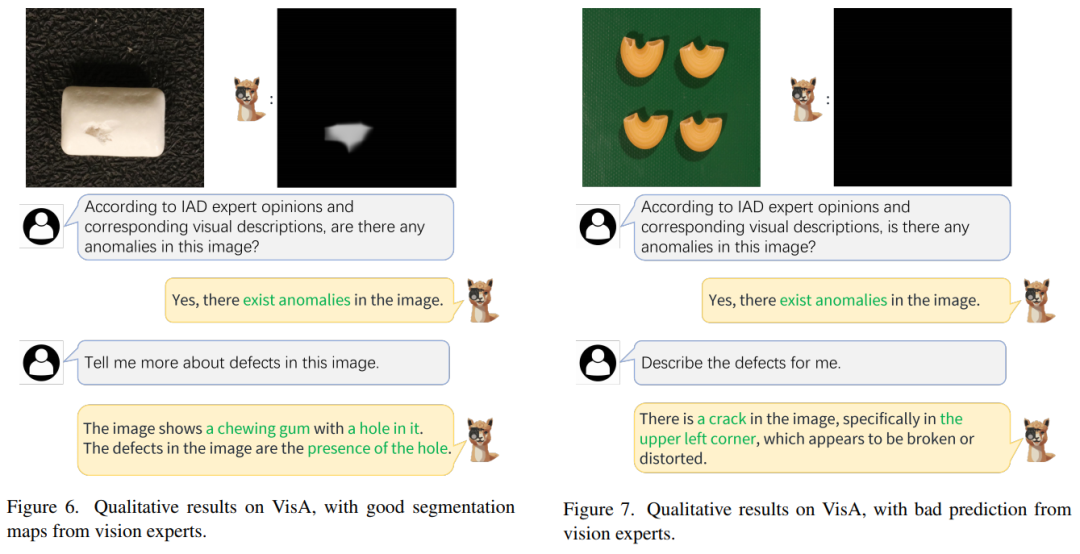
-
模型
+关注
关注
1文章
3372浏览量
49313 -
视觉
+关注
关注
1文章
147浏览量
24043 -
大模型
+关注
关注
2文章
2652浏览量
3267
原文标题:工业异常检测大模型来了!哈工大提出Myriad:利用视觉专家进行工业异常检测的大型多模态模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐


商汤日日新多模态大模型权威评测第一
一文理解多模态大语言模型——下

利用OpenVINO部署Qwen2多模态模型
华工科技联合哈工大实现国内首台激光智能除草机器人落地
云知声推出山海多模态大模型
依图多模态大模型伙伴CTO精研班圆满举办
聆思CSK6视觉语音大模型AI开发板入门资源合集(硬件资料、大模型语音/多模态交互/英语评测SDK合集)
智谱AI发布全新多模态开源模型GLM-4-9B
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo
李未可科技正式推出WAKE-AI多模态AI大模型






 工商网监
工商网监
评论