 DRAM选择为何突然变得更加复杂?
DRAM选择为何突然变得更加复杂?
芯片制造商开始在同一个高级封装中集成多种类型和风格的DRAM,为日益分布式的存储器和更复杂的设计创造了条件。
尽管多年来一直有人预测DRAM将被其他类型的内存所取代,但它仍然是几乎所有计算中的基本组件。它的足迹没有消失,而是在增加,选择的数量也在增加。
有几个因素推动着这种扩张。其中包括:
系统中计算元素的数量和密度不断增加,以更快地处理更多数据,特别是对于AI/ML和数据中心应用。更多的内核需要更多的内存,因为需要有一个地方来存储和处理数据。
通常情况下,这其中的大部分将在缓存中处理,SRAM一直是L1到L3缓存的首选内存。但是SRAM不再以与数字逻辑相同的速度扩展。因此,它在芯片上占据了更大比例的空间,DRAM速度的提高使得一些类型的缓存适合L3缓存。
来回移动数据受到带宽和距离的限制,因此仅仅在一个物理位置添加更多内存并不一定会提高性能。事实上,它可能会适得其反。
出于以上种种原因,芯片制造商正在使用更多的DRAM。在某些情况下,DRAM——尤其是高带宽存储器(HBM)——正在取代一些SRAM。DRAM在耐用性方面有着良好的记录,也有成熟的工艺,而且比SRAM便宜得多。Objective Analysis总经理吉姆汉迪(Jim Handy)表示,根据原始数据,同样容量的SRAM成本可能是DRAM的2500倍以上,具体取决于DRAM的类型。[1]
有一系列的动态随机存取存储器当然可以。有些很快,比如英王陛下,而且还贵。其他类型较慢但便宜,如基本DDR DIMMs。不过,有所改变的是,在异构架构中,两者都可以扮演重要的角色,此外还有多种其他类型的DRAM和更具针对性的内存,例如MRAM或者ReRAM.
“我们正在寻找一种混合模式,在同一个系统中使用不同的DRAM技术,”微软高级技术营销经理科斯·吉切夫说节奏。“如果您真的需要非常高的性能,并且愿意为此付费,那么您可能会选择HBM。您可以将它用于L3缓存,或者您需要立即访问的任何东西。如果您仍然需要更多的内存,但是有一点延迟,您可以在RDIMM(已注册的双列直插式内存模块)或MRDIMM(多路复用器等级的DIMM)。如果您正在寻找大容量,那么您可能会考虑后面的DRAM巨灾超赔分保。该技术开始针对非常特殊的应用,具有真正的高带宽和低功耗,更大的内存占用,但延迟稍长。将所有这些结合在一起是每个人解决这些问题的方向。“
就像高级节点或高级打包中的几乎每一项改进一样,解决一个问题会导致另一个问题。尽管如此,潜在的理论是合理的,在今天的市场上也有证据。例如,可能有必要让一些功能以最高速度运行,如AI,这将使高带宽内存成为最佳选择。但并不是所有的功能都是必不可少的,也不是所有的功能都需要那样的性能。在某些情况下,GDDR5或GDDR6可能就足够了。在其他地方,可能是LPDDR,在其他地方可能是DDR4。所有这些都有不同的相关成本,这些成本可以通过来回移动数据的资源以及内存芯片的货币价值来衡量。
另一方面,并非所有的DRAM都是一样的,只是添加不同风格的DRAM而没有充分了解它们将如何影响其他组件会导致问题。重要的是以避免未来问题的方式集成它们,包括复杂的平面规划,以避免信号完整性和防止热量问题。众所周知,DRAM和heat不太协调。但也有一些以前从未认真考虑过的新问题。
“DRAMs发展的大问题分为两类——常见的问题(更多的带宽和容量、管理电源),以及一些新的问题(更具挑战性的可靠性,导致片内ECC和划船锤保护),”斯蒂芬吴说,研究员和杰出的发明家兰布斯。“对于新的挑战,在芯片上放置更多的电容会增加片内错误的发生率,因此您现在看到的DRAMs会在数据返回控制器之前进行一些片内错误纠正。并且发生像RowHammer这样的相邻单元干扰问题,因为这些单元彼此非常接近,以至于访问一组单元会导致非常接近的相邻单元的位翻转。”
哪里最有效
越来越多的选择也让人们很难决定使用哪些内存。DRAM的选择通常基于性能、功耗、成本、可靠性(纠错码,以及充分测试和供应链安全)和容量。因此,如果DRAM将用于L3缓存,它可能需要高性能和低功耗。如果它将用于高级封装中的低级功能,它可能是标准的DIMM。
但这些选择中的每一种都会影响整体芯片或系统级封装设计,并带来特定的设计考虑。
“过去,DDR4和LPDDR4并不复杂,”产品营销高级经理Graham Allan说新思科技。“一个客户会启用DDR4,另一个客户会启用LPDDR4,因此存在重叠。随着DDR5和LPDDR5一代代的发展,这些应用领域已经完全不同,接口协议和物理信号也是如此。DDR5通常希望与成吨成吨的DRAMs(大容量)进行通信,因此您主要是与寄存器DIMMs进行接口。使用LPDDR,您通常只能与一个包装或设备对话,并且该设备中最多有两个负载。LPDDR也是地面终端。DDR端接到正电压轨。这些是非常不同的物理接口和协议,这意味着客户需要选择一个或另一个。”
还有一些中间选项可以帮助在多个应用程序中使用相同的设计。例如,根据工作负载的不同,MRDIMMs可以用于将容量或带宽翻倍。Allan表示:“多路复用器级DIMMs的容量和速度是SDRAM(同步DRAM)的两倍。“它的美妙之处在于DRAMs不会改变。它以两种不同的模式运行。它的运行方式类似于负载减少的DIMM,但速度不会翻倍。在这种模式下,您可以使用它来获得更高的容量。或者它以多路排列模式工作,这使DRAMs和外部接口之间的带宽加倍。”
那是画面的一部分。另一部分是PHY或物理层,它为内存提供物理接口。phy因使用的DRAM类型而异,随着数据量的增加和设计的日益多样化,phy变得尤为重要。
phy还可以链接在一起成为一种主堆栈,以便管理复杂设备中的内存资源,无论该设备是GDDR6还是LPDDR4。这样,所有类型的DRAM都可以被视为可用资源并进行集中管理。
公司副总裁兼总经理Balaji Kanigicherla表示:“通过管理带宽的某种结构,一切都是可见和可寻址的瑞萨科技(公司名称)基础设施事业部。“这不仅仅是关于提高密度或记忆的物理学,这是材料科学。存储器的应用架构是行业的发展方向。密度需要提高,因为您希望在相同的带宽下获得更大的容量。我们可以根据每美元或每千兆字节的路径进行混合搭配,并且可以在SSD、DRAM和本地片上SRAM缓存之间使用分层。这将转变为整个系统的总拥有成本,并考虑我们将为每一层支付的成本。”
这实质上提高了内存管理的抽象级别。Kanigicherla说:“你可以从当前的模式发展到在全球层面解决内存问题,并基本上创建足够有效的互连来管理缓存或减少延迟。“这就像是全局可寻址内存的一个分区。很明显,你需要提供带宽。但好消息是,对于人工智能工作负载,它们对延迟不太敏感,对带宽更敏感。所以你可以把这项技术放大。在CXL和UCIe之间,应该有一种更渐进的方式来分解内存,可能包括光学互连,并实现内存的完整全局视图。但这需要整个行业来实现。这可不简单。”
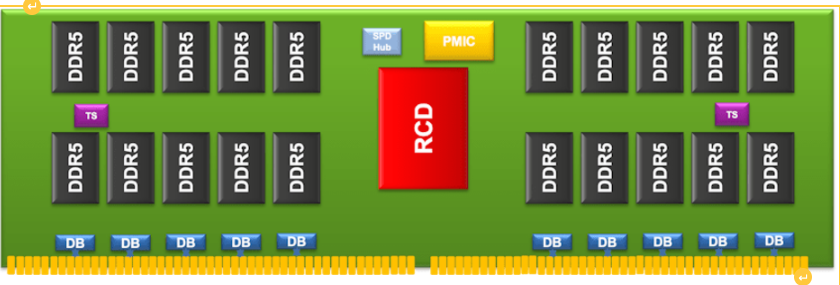
图:系统DRAM的集中控制。来源:瑞萨
内存池是另一种选择,并且在数据中心越来越受欢迎。内存池对DRAM的作用相当于超大规模扩展对处理器内核的作用。当需要额外的内存时,可以通过与额外的计算核心相同的方式获得,通常通过CXL接口。
Rambus‘ Woo在最近的一次演讲中说:“池化背后的想法是,如果我有一组服务器,它们每个都有内存,那么它们每个都不太可能同时使用所有的内存容量。”卡斯帕事件。“更有意义的做法是,将部分容量放入外部机箱,并像资源池一样对待它。当处理器需要的内存超过机箱内的容量时,它们可以在短时间内取出并配置一些内存,将其用于计算,然后将其放回池中。这是让很多业内人士感到兴奋的新功能之一。再远一点,一旦你做了这些类型的事情,你就可以开始考虑通过开关连接内存和池。CXL标准也允许多级交换。这种灵活性将有助于提高各种应用的性能和总拥有成本。”
其他记忆方法
除了更传统的方法之外,DRAM正在向不同的方向发展。这部分是因为向异构集成和高级打包的转变,以及更多的领域特定设计,部分是因为处理更接近数据源的好处。
“比较计算和DRAM,我们用17%的能量进行计算,用63%的能量将数据从一点移动到另一点,”的内存技术专家Jongsin Yun说西门子数字工业软件。“这是相当大的能量。我们可以节约成本,提高速度和能效。当前的解决方案是在缓存中增加更多的内存,但这是一个昂贵的解决方案。我们不需要将所有数据都转移到DRAM。我们可以在内存中进行一些计算,或者使用一些基于GPU的人工智能卷积,这样我们就可以在不转移内存的情况下进行计算。”
如今的选择比以往任何时候都多,处于开发阶段的选择也更多。华邦例如,开发了一些基于DRAM的内存解决方案,但它们超越了传统的DRAM使用模式。一个是该公司的单模立方体(定制超带宽元件)架构。另一种是伪静态DRAM,它介于SRAM和DRAM之间,不需要外部数据重写。这两者都是针对可穿戴设备和边缘服务器等特定市场。
“现在最热门的话题是生成式人工智能,”华邦电子美国公司的营销主管CS林说。“但是,数据中心中发生的事情与我们关注的地方有着不同的要求,并且有着非常不同的密度。我们专注于16千兆字节/秒及以下的密度,但该解决方案可扩展至256千字节/秒。它以非常接近HBM2的带宽运行,但具有非常低的功耗优势。”
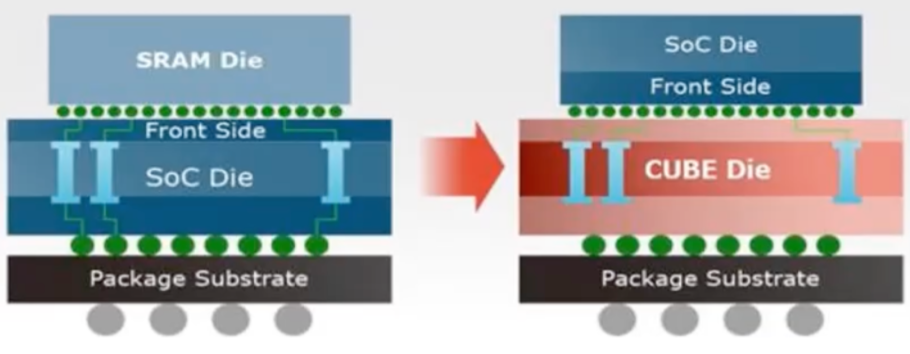
图:立方体方法,延迟约25ns,5X单位密度高于14纳米SRAM。来源:华邦
Lin说,这种方法的好处是能够使用标准DRAM来提高性能,而不是依赖最先进的处理节点。通常,更高的密度会产生延迟,但CUBE架构使用数千个硅通孔来传输数据,这些通孔可以根据对更高带宽或更高速度的需求进行灵活分配。这允许更细粒度的系统架构,以及更小的占用空间。
另一种方法是均衡化。这个计划已经酝酿了一段时间,但最终似乎越来越有吸引力。Synopsys的Allan解释说:“均衡改善了您在信道末端接收的数据。“简单来说,这就像符号间干扰。当一系列位通过通道传输时,当一位完成时,实际上已进入下一位的时域。信号上升和下降以及从1到0的转换需要超过一个单位的时间间隔。你不是从稳态低电位开始的。你正从一个更高的状态开始。您使用决策反馈均衡来偏移输入接收器中的采样点。那么,我现在如何优化我的输入接收器,使1和0检测具有相似的裕量呢?我真的没有感觉到有什么东西会把基准电压正好放在中间。”
内存计算也即将出现。虽然已经有一些使用MRAM的商业方法,但普林斯顿大学的研究人员在2019年纸展示了FPGA中的外部DRAM控制器,它可以与现成的DRAM一起使用,以创建大规模并行计算。研究人员声称,这种方法克服了所谓的内存墙,即逻辑性能超过了内存带宽。
权衡
那么,与DRAM相比,SRAM的使用量有多大呢?这没有简单的公式,因为这不是苹果与苹果的比较。
“真的没有什么神奇的方法可以做到这一点,”首席技术官和联合创始人王乘说Flex Logix。“我们的大部分设计权衡来自模拟SRAM带宽、SRAM容量和DRAM带宽的性能评估。这是我们的三个主要旋钮。基本上,我们有四种标准规模的计算,不同数量的SRAM和DRAM带宽适用于我们的标准IP产品。这是基于我们运行模型的经验数据,以确定什么更好。如果我们有两倍的SRAM容量,一些型号可以运行得更好。如果通过将SRAM增加一倍,您的性能几乎可以增加一倍,并且您将另外20%的面积用于2倍性能,那就太好了。但是,还有许多其他型号无法从额外的SRAM中受益,这样一来,你就白白增加了那个区域。这就是拥有准确的周期性能评估非常重要的原因。在我们的例子中,它不精确到单个周期,但它精确到8%,这超过了我们所需要的。然后,您可以对适当的SRAM/DRAM计算权衡进行大量架构分析,这可能因工作负载类型而异。”
这是复杂的数学,随着系统被分解成异构元素,如小芯片,它变得更加复杂。“SRAM需要每比特更多的晶体管来实现。的首席产品经理Takeo Tomine说:“与DRAM相比,它的密度更低,价格更贵,读写时的功耗也更高。”Ansys。“目前,SRAM是在CPU通常采用的先进finFET技术节点上设计的,由于finFET器件的热阻较高,因此更容易受到热效应(自热)的影响。”
在某些情况下,使用什么类型的内存,以及在哪里使用,可能会归结为设备的预期寿命。“有两个主要的可靠性问题会导致记忆寿命的缩短,”Tomine说。“一个是互连可靠性与技术节点缩小导致存储器的寿命,因为自热导致严重的电迁移(EM),这是最关键的可靠性问题之一。随着技术的发展,材料和工艺技术不断提高电磁寿命。第二是来自不同设备架构的可靠性挑战。在将器件架构从finFETs转移到纳米片再到CFETs的过程中,热阻率急剧增加,这意味着器件沟道的δT更高。器件自热将与金属焦耳热耦合。器件的自热会影响栅氧化层击穿(时间相关的介电击穿),还会降低HCI(热载流子注入),这会恶化器件的BTI(偏置温度不稳定性)。”
可靠性是对存储器设备在给定时间内无故障运行的能力的度量。智能手机的预期寿命为4年,而汽车、军事或金融服务器应用的预期寿命可能为10至15年(或更长),因此这一时间框架可能会有很大不同。能够理解可能影响存储器寿命的潜在交互是至关重要的,并且它们可能因架构、存储器类型和使用而异。
这也会影响所使用的内存类型和整个系统架构。因此,如果记忆可以被交换,那么寿命就没有那些记忆被嵌入某种高级包装并密封起来那么重要。“这就像有一个DRAM卡池,今天就可以升级,”瑞萨的Kanigicherla说。“使用HBM,如果出现问题,你什么也做不了,所以你扔掉了一个非常昂贵的芯片。在CPU方面,服务器连接得非常紧密,您无法做太多事情来升级任何东西。这就是为什么这个全局共享内存的概念是可行的。其中一些解决方案会自动出现。”
延迟增加了另一个权衡。“尤其是HBM,你把处理器和DRAM放得很近,”Cadence IP Group产品营销总监Frank Ferro说。“这样做有很多好处。HBM发展相当迅速。我们几乎每两年就会看到性能的提高。所以曲线很陡。但是从系统设计的角度来看,2.5D仍然是一个挑战。优化内插器并帮助客户设计,这确实是对话的关键部分。”
结论
自1967年发明以来,DRAM一直是计算的关键。虽然多年来无数的内存技术对它提出了挑战,但没有什么能取代它。鉴于围绕这项技术的狂热活动,在可预见的未来,没有什么能取代它。
现在的DRAM不止一种类型,而是多种类型,每种类型都在不断发展,并产生新的想法。从内存到处理元件的物理连接,到服务器机架外的内存池,每个层面都有创新。目前正在努力缩短信号在内存和处理器内核之间的传输距离,这将减少传输数据所需的电量和每个周期所需的时间。
总的来说,DRAM仍然是一个充满活力和创新的领域,而且还会有更多的创新和不同的方法来整合一个对性能、成本、可靠性和寿命有重大影响的内存解决方案。
审核编辑:黄飞
-
DRAM
+关注
关注
40文章
2337浏览量
184226 -
sram
+关注
关注
6文章
777浏览量
115099 -
数据中心
+关注
关注
16文章
4951浏览量
72641 -
芯片制造
+关注
关注
10文章
645浏览量
29058 -
HBM
+关注
关注
0文章
392浏览量
14896
发布评论请先 登录
相关推荐
为了延长DRAM存储器寿命 必须短时间内采用3D DRAM


【内存知识】DRAM芯片工作原理
笔记本触摸板为何突然不动了?

北斗为何突然要同意与美国GPS兼容?
未来电源系统的时序设计和调试将会变得更加复杂
如何让VR和AR系统变得更加实用?
芯片设计中DRAM类型如何选择





 工商网监
工商网监
评论