 驱动云/边缘侧算力建设的高性能互联接口方案
驱动云/边缘侧算力建设的高性能互联接口方案
9月14-15日,2023全球AI芯片峰会(GACS 2023)在深圳正式举行。奎芯科技应邀出席大会,副总裁王晓阳发表主题为《驱动云/边缘侧算力建设的高性能互联接口方案》的演讲。在演讲中,王晓阳分享了AIGC产业算力需求引发的芯片互联趋势,并对算力芯片瓶颈进行了分析,提出了奎芯内存互联解决方案和Chiplet方案落地案例。
AIGC引爆的芯片互联趋势
最近几年AI模型快速发展,模型规模每年差不多10倍速度增长,当令人惊讶的1750亿参数的GPT3已成为过去式,迎来更大体量的万亿参数时代,AI系统算力需求也随之增加,几乎每季度翻倍增长。最近几年体系结构讨论最多的问题之一就是如何破解两堵墙:内存墙和I/O墙。多年来通过工艺进步,计算架构设计革新等方法,理论算力的增长速度是惊人的,但是内存带宽,互联带宽的增长却相对缓慢,造成了巨大的落差,最近业界也在尝试很多方法来缩小这些差距比如:增加缓存,多级缓存架构,堆叠缓存;尽量提高单节点算力减少互联的overhead;用高速的芯片互联和系统互联的SerDes做芯片互联等等。
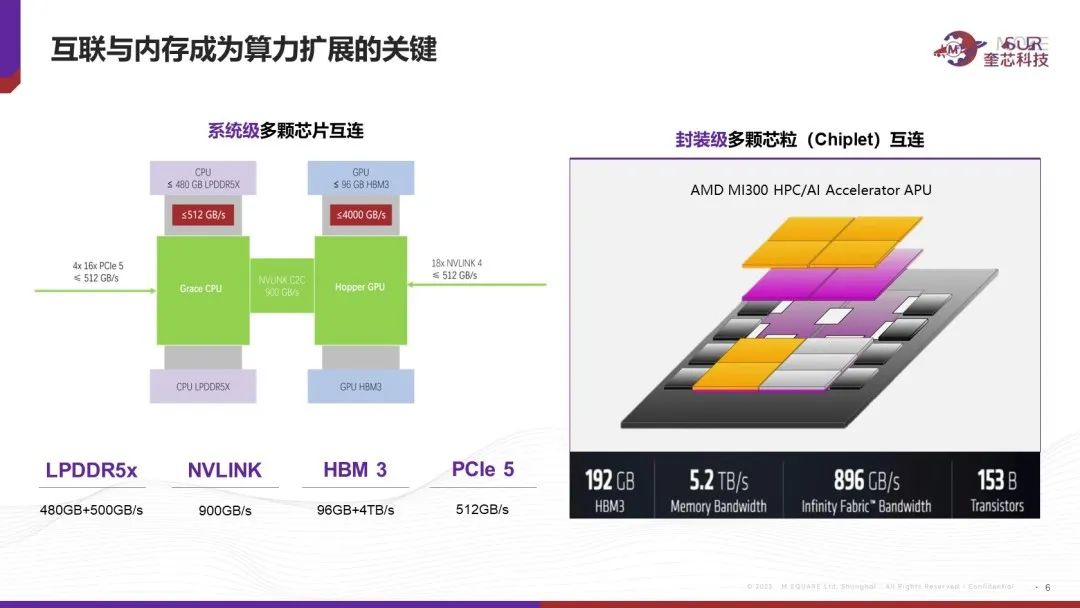
英伟达GH200非常重点的强调HBM带宽,LPDDR容量,以及NVLINK的速度。AMD发布的MI300X对算力指标提都不提,只提内存容量、内存带宽以及互联带宽。因此可以看到在LLM的游戏规则下,内存容量、内存带宽以及互联带宽成了最核心的竞争力,而算力的重要性相对下降。
算力芯片瓶颈分析
目前主流AI大芯片采用HBM为主,它的价格相对其他内存要贵,但单位带宽成本较低。
HBM使用有诸多限制,其一是因为HBM的颗粒必须和SOC的Die要对齐,合封在一起,所以它是一个紧耦合的状态,会带来如下限制:在HBM数量方面,SoC与HBM必须保持贴合,导致HBM颗粒数量受限于芯片边缘长度;在热管理方面,DRAM的温度敏感性会限制SoC的工作频率,从而影响性能,而SoC与HBM之间的热交互对测试提出了更高的要求;在设计实施方面,HBM IP的布局和适配性相对不够灵活;另外,工艺限制要求SoC与HBM HOST IP必须采用相同的工艺制程;最后,需要注意的是SoC的面积占用问题,在12纳米工艺下每个HBM HOST IP大约占据30mm2,限制了计算单元的面积。
其二是主流HBM的应用还是以先进封装为主,包括Silicon interposer 或者Silicon Bridge等,也带来了不少限制:Interposer尺寸受限制,最大只能有3到4个曝光面积;2.5D封装的成本较高,与标准封装相比价格高出4倍,近期台积电的CoWoS单价上涨了20%;采用uBump作为连接点时,测试覆盖率有限,当封装中包含超过6个HBM和2个ASIC时,良率明显下降;最后,CoWoS产能有限,台积电的CoWoS产能紧缺,国内2.5D封装技术还不够成熟。
奎芯基于UCIe接口的HBM互联方案
针对这些问题,奎芯科技打造一站式解决方案—M2LINK,用于将HBM和SoC解耦。基本做法是利用一颗Chiplet将HBM接口协议转成UCIE接口协议,然后用RDL interposer 把Chiplet和HBM内存封装成一个标准模组,最后通过普通基板来和主SoC进行封装。这样主SoC和标准模组间距离预计可以拉远到2.5cm,克服了原先主SoC和HBM紧耦合和绑定的限制,同时也无需受限于先进封装的高成本和Si Interposer的有限尺寸。除此之外还有诸多好处,比如以UCIe IP取代HBM IP,节省了主芯片面积,主芯片成本降低;单位边长可以连接更多的HBM标准模组,内存容量和带宽都可以得到提升等等。
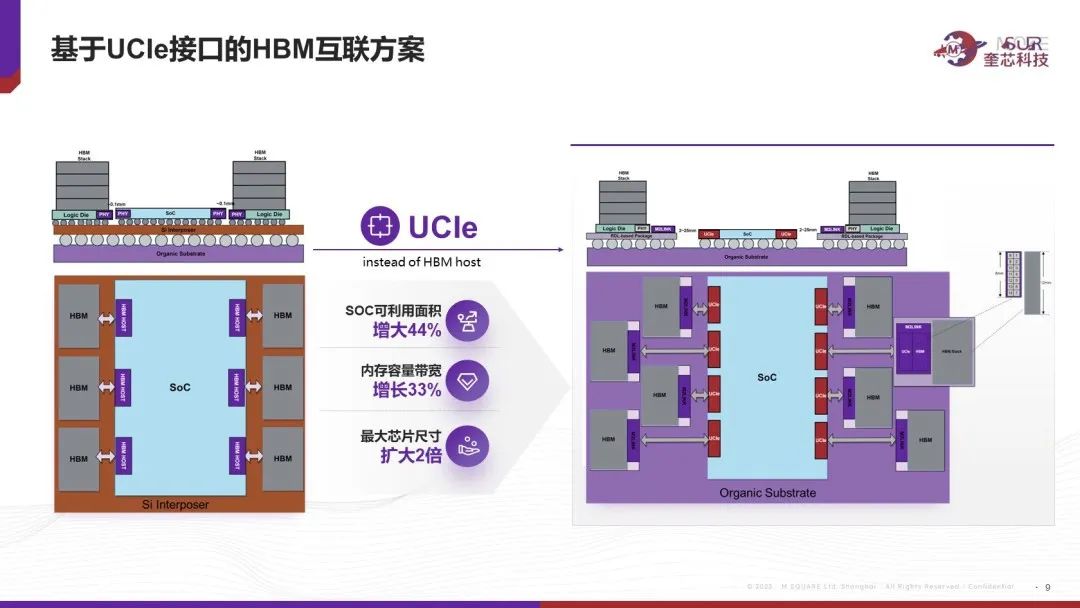
以目前主流芯片为例,SoC近HBM的边长为30mm的话,可以摆放6个HBM颗粒,利用M2LINK方案的话,双边共可以摆放8个HBM模组,同等大小的SoC可利用面积增大44%,内存容量带宽增加1/3, 最大封装面积可以增加一倍以上。
奎芯Chiplet落地解决方案
奎芯科技作为国内领先的互联IP产品及Chiplet产品供应商,国产自研内存及互联解决方案,奎芯LPDDR5X接口速率可达8533Mbps,业界领先。奎芯D2D接口则具有高速率、低功耗、低延迟等优势。而奎芯HBM接口可支持国产工艺 PHY+ Controller 全套方案,速率可达6.4Gbps。目前,奎芯已经有70件知识产权申请,以及16件荣誉奖项。
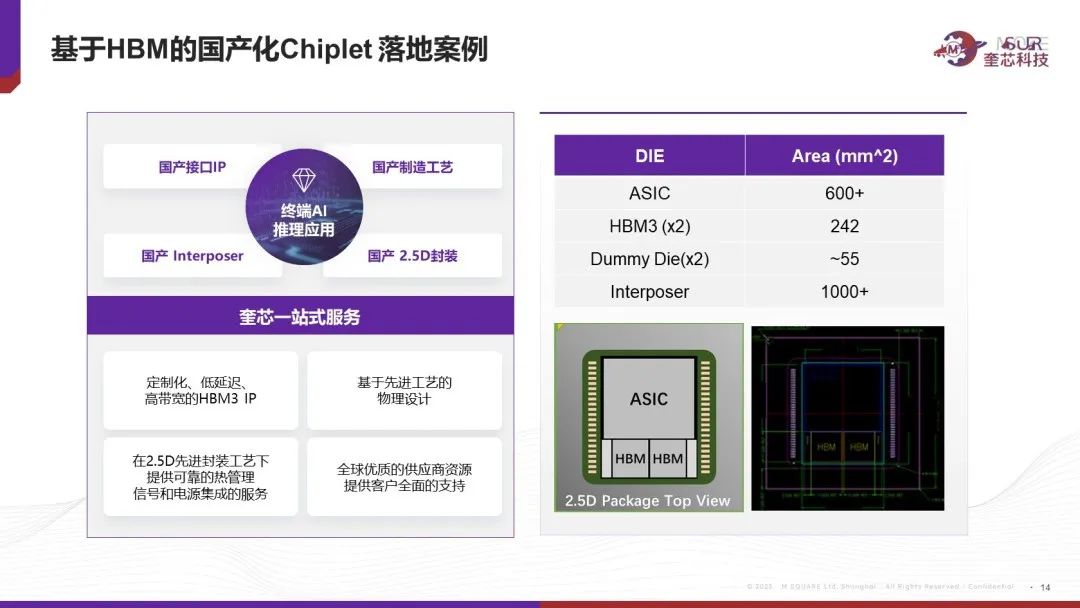
奎芯科技基于对于整个封装供应链的整合能力,目前和客户一起打造一款标准的带HBM3的2.5D全国产封装大芯片,将会提供包含HBM IP, interposer设计,2.5D封装的设计的完整的turn key solution。
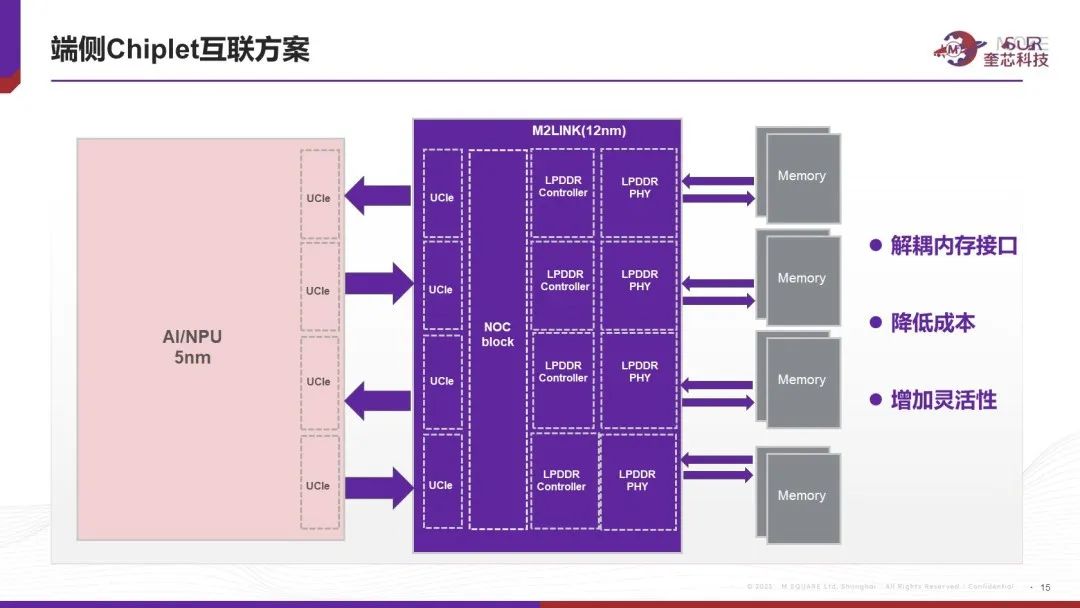
同时,奎芯科技基于D2D(UCIe)解耦SoC和HBM HOST的思路不仅适用于云端训练和推理的大算力芯片,在端侧已经有具体实践的案例,目前在给客户打造的是一款低功耗计算产品的IO die。对于此场景,客户希望计算部分用最先进的制程,考虑到昂贵的成本,客户还是希望解耦内存接口放到成熟工艺上实现,因此我们给客户打造一颗包含 LPDDR host 的完整IO die, 实现内存接口解耦,降低成本,为客户未来产品升级增加灵活性。
奎芯科技致力于建立开放生态的一站式Chiplet服务平台,提供接口IP,Chiplet,系统设计和先进封装设计等服务,配套强大的供应链资源及高效的系统整合服务,为客户提供完整的一站式解决方案。
来源: 奎芯科技
审核编辑 黄宇
-
芯片
+关注
关注
458文章
51410浏览量
428533 -
AI芯片
+关注
关注
17文章
1918浏览量
35292 -
算力
+关注
关注
1文章
1031浏览量
15017 -
chiplet
+关注
关注
6文章
436浏览量
12646
发布评论请先 登录
相关推荐
GPU算力租用平台是什么
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
米尔STM32MP2核心板首发新品上市!高性能+多接口+边缘算力
ST系列-米尔STM32MP257核心板开发板-高性能+多接口+边缘算力
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
广和通端侧AI解决方案驱动性能密集型场景商用型场景商用
广和通端侧AI解决方案驱动性能密集型场景商用型场景商用

名单公布!【书籍评测活动NO.41】大模型时代的基础架构:大模型算力中心建设指南
IaaS+on+DPU(IoD)+下一代高性能算力底座技术白皮书
曙光携手“算力互联公共服务平台”提高全国算力匹配效率
深度践行“IaaS on DPU”理念,中科驭数正式发布“驭云”高性能云异构算力解决方案!






 工商网监
工商网监
评论