 数据库having的用法
数据库having的用法
HAVING是SQL中用于在GROUP BY子句之后对结果集进行筛选的关键字。它可以根据聚合函数的结果来过滤结果集,只保留符合特定条件的行。HAVING可以用于对GROUP BY子句中聚合函数的结果进行筛选,并且它可以使用的操作符包括比较操作符(如等于、大于、小于等)、逻辑操作符(如AND、OR、NOT)以及数学运算符 (如加、减、乘、除)。
在介绍HAVING的用法之前,我们先来了解一下GROUP BY子句的作用。GROUP BY子句用于将结果集按照一个或多个列进行分组,并根据分组后的结果执行聚合函数。聚合函数可以对每个分组生成一个单一的值,如COUNT、SUM、AVG等。
有了GROUP BY子句之后,我们可以使用HAVING对聚合函数的结果进行进一步筛选。HAVING子句可以包含以下几种形式的表达式:
- 单个聚合函数的结果,例如:HAVING COUNT(*) > 100,表示只返回满足条件的行,即满足条件的分组至少有100行。
- 多个聚合函数的结果之间的比较操作,例如:HAVING COUNT(*) > AVG(salary),表示只返回满足条件的行,即满足条件的分组的行数大于平均工资。
- 聚合函数结果和常量之间的比较操作,例如:HAVING SUM(salary) >= 1000000,表示只返回满足条件的行,即满足条件的分组的工资总和大于等于1000000。
- 聚合函数结果和子查询之间的比较操作,例如:HAVING AVG(salary) > (SELECT AVG(salary) FROM employees WHERE department = 'IT'),表示只返回满足条件的行,即满足条件的分组的平均工资大于IT部门的平均工资。
需要注意的是,HAVING子句在执行查询时是在WHERE子句之后进行的。WHERE子句在查询中起到了先过滤行的作用,然后根据GROUP BY子句将行进行分组,最后在HAVING子句中对分组后的结果进行过滤。
下面我们通过一个示例来说明HAVING的用法:
假设我们有一个employees表,包含以下列:id、name、department、salary。现在我们想要找出平均工资大于5000的部门,我们可以使用以下SQL语句:
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 5000;
在上述SQL语句中,我们首先根据department列对employees表进行分组,然后计算每个分组的平均工资,并将其命名为avg_salary。最后,我们使用HAVING子句将平均工资大于5000的部门筛选出来。
另外,HAVING子句还可以与其他关键字一起使用,如ORDER BY和LIMIT。例如,我们可以根据平均工资降序排列,并只返回前5个部门,可以使用以下SQL语句:
SELECT department, AVG(salary) as avg_salary
FROM employees
GROUP BY department
HAVING AVG(salary) > 5000
ORDER BY avg_salary DESC
LIMIT 5;
在上述SQL语句中,我们首先根据department列分组,并计算每个分组的平均工资。然后,在使用HAVING子句筛选出平均工资大于5000的部门之后,使用ORDER BY子句将结果按照平均工资降序排列,并使用LIMIT子句限制结果集的大小为5。
综上所述,HAVING是SQL中用于在GROUP BY子句之后对结果集进行筛选的关键字。通过使用HAVING子句,我们可以根据聚合函数的结果来过滤结果集,只保留符合特定条件的行。在使用HAVING时,我们可以使用比较操作符、逻辑操作符以及数学运算符来构建表达式。同时,HAVING子句还可以与其他关键字一起使用,如ORDER BY和LIMIT,来对结果集进行排序和限制。
-
数据库
+关注
关注
7文章
3816浏览量
64482 -
函数
+关注
关注
3文章
4333浏览量
62712 -
运算符
+关注
关注
0文章
172浏览量
11093
发布评论请先 登录
相关推荐
数据库使用教程下载
什么是支持数据库,什么是中宏数据库
数据库教程之如何进行数据库设计
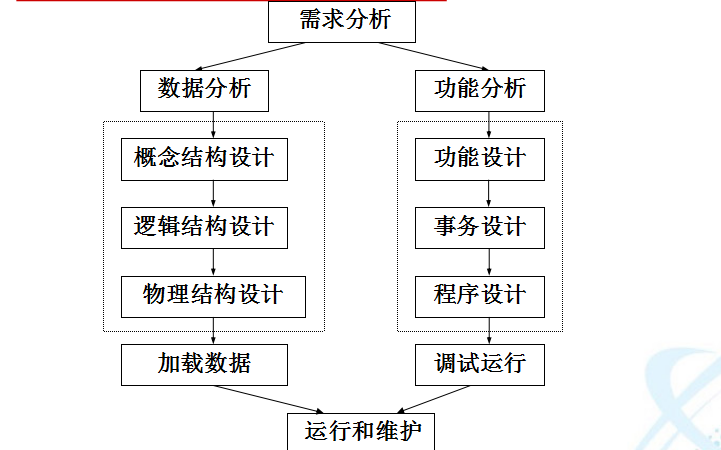
数据库学习教程之数据库的发展状况如何数据库有什么新发展
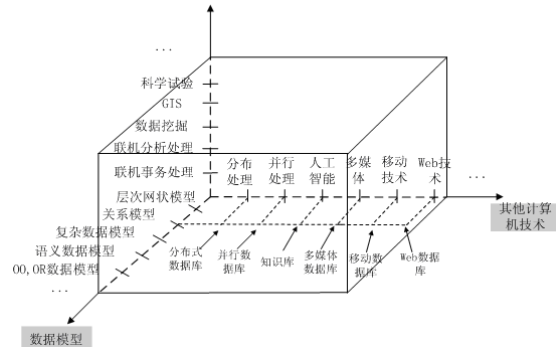
云数据库和自建数据库的区别及应用
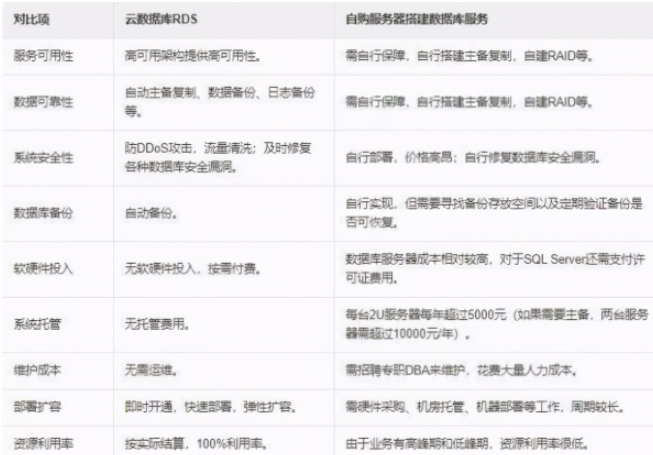

华为云数据库-RDS for MySQL数据库
云数据库和普通数据库区别?|PetaExpress云端数据库
python读取数据库数据 python查询数据库 python数据库连接
数据库应用及其特点 数据库数据的基本特点
数据库select语句的基本用法
数据库orderby 和groupby用法

数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库






 工商网监
工商网监
评论