 大型语言模型的逻辑推理能力探究
大型语言模型的逻辑推理能力探究

最新研究揭示,尽管大语言模型LLMs在语言理解上表现出色,但在逻辑推理方面仍有待提高。为此,研究者们推出了GLoRE,一个全新的逻辑推理评估基准,包含12个数据集,覆盖三大任务类型。
实验对比发现,GPT-4在逻辑推理上的表现远超ChatGPT,但与人类表现和有监督的微调相比,仍有提高空间。
为此,研究者提出了自我一致性探测方法(self-consistency probing method)来进一步提升ChatGPT的准确性,并通过微调策略,进一步增强大型语言模型的逻辑推理能力。
让我们一起看看这篇研究吧!
GLoRE基准
逻辑推理,作为人类智能的核心,长期以来都是AI研究的热点。为了更好地评估LLMs在自然语言中处理复杂信息的能力,研究人员推出了通用逻辑推理评估(GLoRE)基准。与众所周知的GLUE和Super-GLUE评估自然语言理解能力类似,GLoRE汇集了多个逻辑推理数据集。
GLoRE主要包括三大任务:
多项选择阅读理解:系统给定段落和问题,目的是从答案中选择正确的选项。特别地,GLoRE包括五个此类数据集,如LogiQA、ReClor、AR-LSAT等。
自然语言推断(NLI):确定假设与前提之间的逻辑关系。包括ConTRoL、HELP、TaxiNLI等数据集。
真或假问题(TF):如FraCaS、RuleTaker和ProofWriter等数据集。
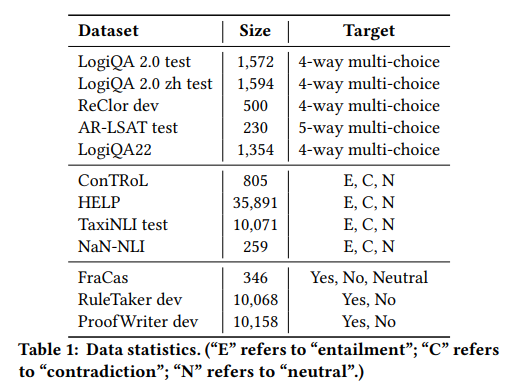
这些数据集涵盖了从简单到复杂的各种逻辑推理情境,为我们评估大型语言模型的逻辑推理能力提供了合适的平替。其中,多项选择阅读理解深入探讨了逻辑MRC问题,而NLI任务关注文本分类中的蕴涵关系。而真或假问题主要测试了模型在多前提上下文的蕴涵问题上的处理能力。
实验设置
在这篇研究中,研究人员针对开源的LLMs和基于封闭API或UI的模型进行了评估,考虑了7种评估场景:
zero-shot评估:模型通过模板转换得到提示,并生成语言化的答案。
few-shot评估:LLMs使用带有答案的示例作为上下文进行推断。
指令调整:LLMs被训练以遵循自然语言指令,进行任务特定的微调。
自我一致性评估:模型需要全面了解上下文中的逻辑关系。
思维链评估:模型进行一步一步的逻辑思考。
聊天UI评估:基于GPT-4的手动聊天UI测试,更真实地反映用户与模型的互动。
生成响应的评估:对模型生成的响应进行质量评估,包括连贯性、完整性、正确性和相关性。
在实验中采用了RoBERTa-base作为基线,对比了数个LLMs如Falcon-40b-instruct和LLaMA-30b-supercot,以及OpenAI的ChatGPT和GPT-4。
评估指标主要以分类精度得分为指标,并设立人类基线,对于LogiQA22数据集特邀五名合著者进行测试。
主要结果
Zero-shot任务
下表展示了主要的zero-shot任务上的实验结果。
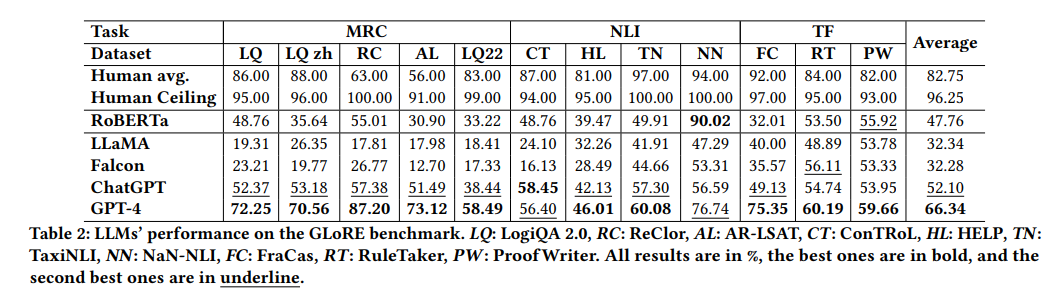
我们主要可以得出以下发现:
人类准确率: 人类在大多数逻辑推理任务上的平均准确率超过80%,尤其是在ReClor和AR-LSAT上,平均准确率分别为63.00%和56.00%。
RoBERTa-base表现: 该模型在多数逻辑推理任务上的表现落后于平均人类表现,但在特定的ProofWriter任务上有55.92%的准确率,显示出处理特定逻辑推理任务的潜力。
开源模型对比: LLaMA和Falcon在多数逻辑推理任务上的表现都不如微调的RoBERTa-base,特别是在MRC任务上。
ChatGPT和GPT-4: 两种模型在多数MRC基准测试中超过了RoBERTa-base。GPT-4在处理一些逻辑MRC数据集上展现出了显著的能力。
LogiQA 2.0深度分析: ChatGPT和GPT-4在分类推理上都展现出了超高的准确率,但在处理涉及析取的前提上面临挑战。
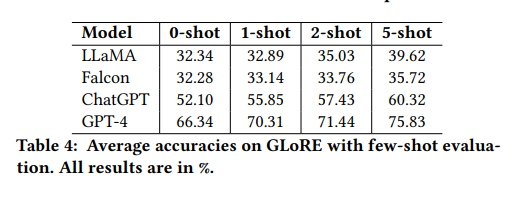
Few-shot任务
下表展示了不同模型在few-shot任务上的实验结果。GPT-4在与zero-shot相比的few-shot场景中获得了超过9个百分点的准确率提升。
推理任务
下表展示了不同推理类型的统计分析。
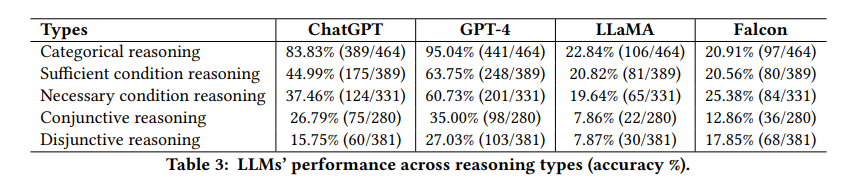
ChatGPT和GPT-4在分类推理上表现出了超高的准确率,分别为83.83%和95.04%。
两模型在涉及析取的前提上面临挑战,可能是因为这些逻辑结构的固有复杂性和潜在的模糊性。
社区模型在分类推理上没有展现出特别强的表现,连词推理和析取推理对它们来说仍然是个挑战。
指令微调的有效性
使用Alpaca的指令进行微调后,所有任务的性能都得到了显著提高,证明了指令调整的强大效果。这种改进主要归因于模型增强的一般指令理解能力。
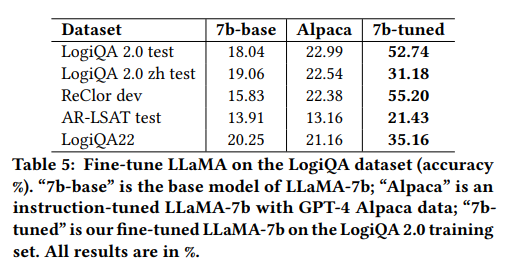
经过调整的LLaMA-7B模型明显优于基线的LLaMA-7B模型和Alpaca。在LogiQA 2.0数据集上,模型的准确率从18.04%增加到52.74%,高于微调后的RoBERTa-base的48.76%。
尽管微调仅使用了LogiQA 2.0的训练数据集,但经过调整的模型成功地将其能力推广到其他数据集。在ReClor数据集上,经过调整的模型达到了55.20%的准确率,比Alpaca高出32.82个百分点。
Self-Consistency Probing评估
逻辑推理任务通常涉及处理一系列相关的陈述或事实,然后根据这些信息进行推断。这些任务需要理解不同信息之间的相互作用,而不是独立地处理它们。这意味着,即使事实的顺序或句子的结构发生变化,真正的逻辑结论也应该保持不变。因此,研究人员在实验中通过打乱句子为ChatGPT引入多样性,特别是对于那些固有地不是顺序的数据集。
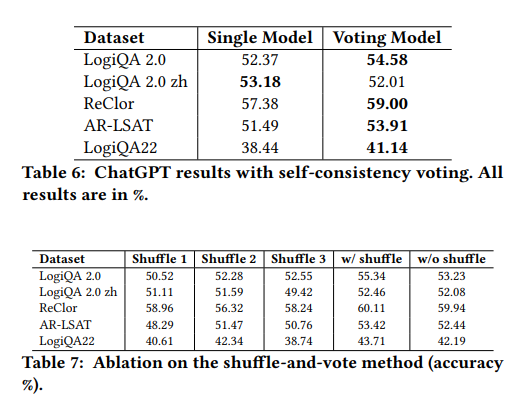
由表可观察到,投票模型在多数数据集上优于单一模型。在LogiQA 2.0 zh数据集上,单一模型有更高的准确率,可能因为中文语言结构的特殊性。
打乱文本不会对ChatGPT的性能产生负面影响。在某些情况下,打乱的文本甚至提高了性能。类似的趋势也出现在其他CoT数据中,其中CoT序列的扰动对整体效率的影响很小。
CoT评估
下表展示了在GLoRE上使用/不使用CoT的结果。
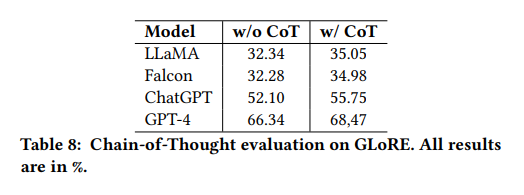
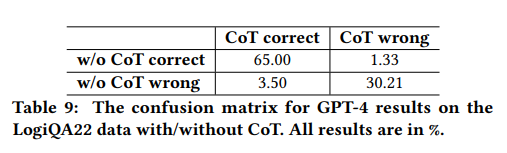
除此之外,实验还计算了GPT-4结果的混淆矩阵。所有模型在使用CoT提示时都有性能提升,范围在2%到3%之间。混淆矩阵进一步说明了使用CoT提示提高性能的重要性。
GPT4的Chat UI评估
实验还对GPT-4模型在Chat UI界面上的性能进行了深入探索,并通过案例研究揭示了其在回答和推理上的特点。
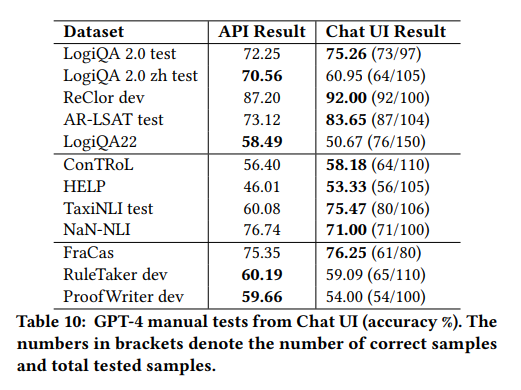
实验结果表明,没有观察到基于UI的输出和基于API的输出之间的明显质量差异。基于UI的评估结果在大多数数据集上略高于基于API的结果。评估指标可能是造成这种差异的一个原因。
案例研究主要有以下发现:
GPT-4在一些情况下能够正确地回答和推理,例如通过选择新证据来解决专家观点和证据之间的矛盾。
GPT-4有时会生成不正确的答案,如对人类起源的问题的回答。
在某些情况下,提供上下文示例可以帮助GPT-4更准确地回答问题。
CoT推理过程通过为GPT-4提供更相关的上下文来工作,但也可能依赖于表面的模式而不是深入的抽象。
人工评估
实验对模型的表现进行了人工评估,GPT-4在所有指标上都稳定地排名第一,ChatGPT紧随其后。评注者之间的一致性良好,Cohen's Kappa值为0.79。
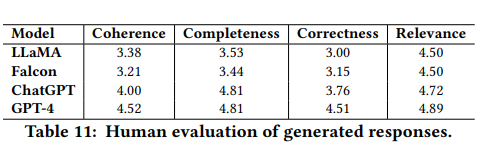
连贯性: GPT-4得分最高,为4.52,表现出其逻辑连贯输出的能力。ChatGPT紧随其后,得分为4.00。
完整性: ChatGPT和GPT-4并列第一,得分均为4.81,展示了其详尽的回应能力。
正确性: GPT-4得分为4.51,领先于其他模型,其回应准确率高。
相关性: GPT-4略微领先,得分为4.89,与ChatGPT得分4.72相当接近。
此外,使用GPT-4 API作为评估器对LLaMA-30-supercot模型进行了实验,其评估得分与人工评估得分相近,为逻辑推理任务的自动评估提供了信心。
结语
在这项研究中,研究团队提出了一个名为GLoRE的数据集,专门用于评估LLMs在处理多种逻辑推理任务上的表现。研究发现ChatGPT和GPT-4在大部分逻辑推理基准测试上都显著超越了传统的微调方法。尽管商业模型在GLoRE测试中的表现相对较弱,但通过对相似数据进行指令调整,模型的性能得到了显著提高。此外,通过监督微调、上下文学习和投票技术,研究团队成功地实现了更为出色的结果。在对模型进行量化和定性评估后,该团队指出,现有的LLMs在解决逻辑推理任务时,似乎更多地依赖于表面模式。因此,他们认为,对底层推理机制进行深入研究和增强,将是一个有益的方向。
审核编辑:汤梓红
-
语言模型
+关注
关注
0文章
575浏览量
11369 -
自然语言
+关注
关注
1文章
293浏览量
14041 -
ChatGPT
+关注
关注
31文章
1608浏览量
10426
原文标题:GLoRE:大型语言模型的逻辑推理能力探究
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【大语言模型:原理与工程实践】大语言模型的应用
基于逻辑推理的网络攻击想定生成系统
深入理解语言模型的突显能力
利用大语言模型做多模态任务
基于Transformer的大型语言模型(LLM)的内部机制

腾讯发布混元大语言模型

基于归结反演的大语言模型逻辑推断系统

基于CPU的大型语言模型推理实验

百度发布文心大模型4.5和文心大模型X1
逻辑推理AI智能体的实际应用
LLM推理模型是如何推理的?




评论