 用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单
用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单

在博士毕业就有10篇ACL一作的师兄指导下是种什么体验
北京大学与腾讯等机构的研究者们提出了多模态对齐框架 ——LanguageBind。该框架在视频、音频、文本、深度图和热图像等五种不同模态的下游任务中取得了卓越的性能,刷榜多项评估榜单,这标志着多模态学习领域向着「大一统」理念迈进了重要一步。
在现代社会,信息传递和交流不再局限于单一模态。我们生活在一个多模态的世界里,声音、视频、文字和深度图等模态信息相互交织,共同构成了我们丰富的感知体验。这种多模态的信息交互不仅存在于人类社会的沟通中,同样也是机器理解世界所必须面对的挑战。
如何让机器像人类一样理解和处理这种多模态的数据,成为了人工智能领域研究的前沿问题。
在过去的十年里,随着互联网和智能设备的普及,视频内容的数量呈爆炸式增长。视频平台如 YouTube、TikTok 和 Bilibili 等汇聚了亿万用户上传和分享的视频内容,涵盖了娱乐、教育、新闻报道、个人日志等各个方面。如此庞大的视频数据量为人类提供了前所未有的信息和知识。为了解决这些视频理解任务,人们采用了视频 - 语言(VL)预训练方法,将计算机视觉和自然语言处理结合起来,这些模型能够捕捉视频语义并解决下游任务。
然而,目前的 VL 预训练方法通常仅适用于视觉和语言模态,而现实世界中的应用场景往往包含更多的模态信息,如深度图、热图像等。如何整合和分析不同模态的信息,并且能够在多个模态之间建立准确的语义对应关系,成为了多模态领域的一个新的挑战。
为了应对这一难题,北大与腾讯的研究人员提出了一种新颖的多模态对齐框架 ——LanguageBind。与以往依赖图像作为主导模态的方法不同,LanguageBind 采用语言作为多模态信息对齐的纽带。

论文地址:https://arxiv.org/pdf/2310.01852.pdf
GitHub 地址:https://github.com/PKU-YuanGroup/LanguageBind
Huggingface 地址:https://huggingface.co/LanguageBind
语言因其内在的语义丰富性和表现力,被赋予了整合和引导其他模态信息对齐的能力。在这个框架下,语言不再是附属于视觉信息的标注或说明,而是成为了联合视觉、音频和其他模态的中心通道。
LanguageBind 通过将所有模态的信息映射到一个统一的语言导向的嵌入空间,实现了不同模态之间的语义对齐。这种对齐方法避免了通过图像中介可能引入的信息损失,提高了多模态信息处理的准确性和效率。更重要的是,这种方法为未来的扩展提供了灵活性,允许简单地添加新的模态,而无需重新设计整个系统。
此外,该研究团队构建了 VIDAL-10M 数据集,这是一个大规模、包含多模态数据对的数据集。
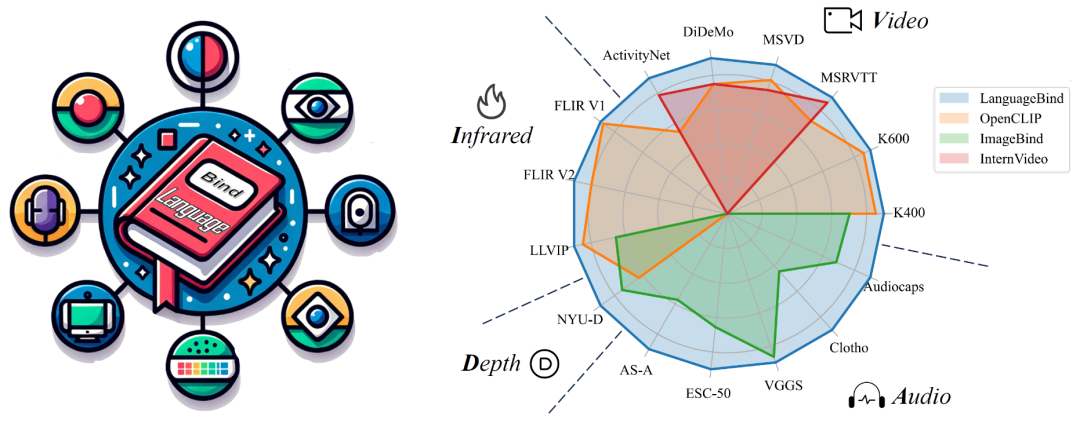
VIDAL-10M 涵盖了视频 - 语言、红外 - 语言、深度 - 语言和音频 - 语言配对,以确保跨模态的信息是完整且一致的。通过在该数据集上进行训练,LanguageBind 在视频、音频、深度和红外等 15 个广泛的基准测试中取得了卓越的性能表现。
方法介绍
在多模态信息处理领域,主流的对齐技术,如 ImageBind,主要依赖图像作为桥梁来实现不同模态之间的间接对齐。这种方法在对其他模态和语言模态的对齐上可能会导致性能次优化,因为它需要两步转换过程 —— 首先是从目标模态到图像模态,然后是从图像模态到语言模态。这种间接对齐可能导致语义信息在转换过程中的衰减,从而影响最终的性能表现。
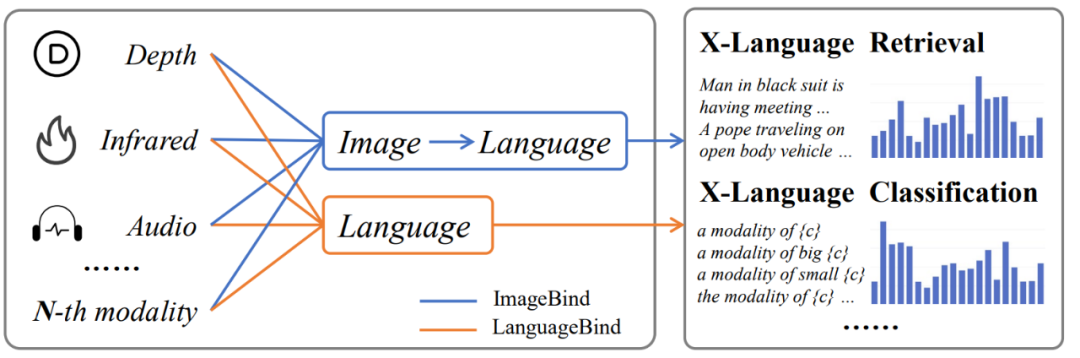
针对这一问题,该团队提出了一种名为 LanguageBind 的多模态语义对齐预训练框架。该框架摒弃了依赖图像作为中介的传统模式,而是直接利用语言模态作为不同模态之间的纽带。语言模态因其天然的语义丰富性,成为连接视觉、音频、深度等模态的理想选择。LanguageBind 框架通过利用对比学习机制,将不同模态的数据映射到一个共享的语义嵌入空间中。在这个空间里,不同模态的信息可以直接进行语义层面的理解与对齐。
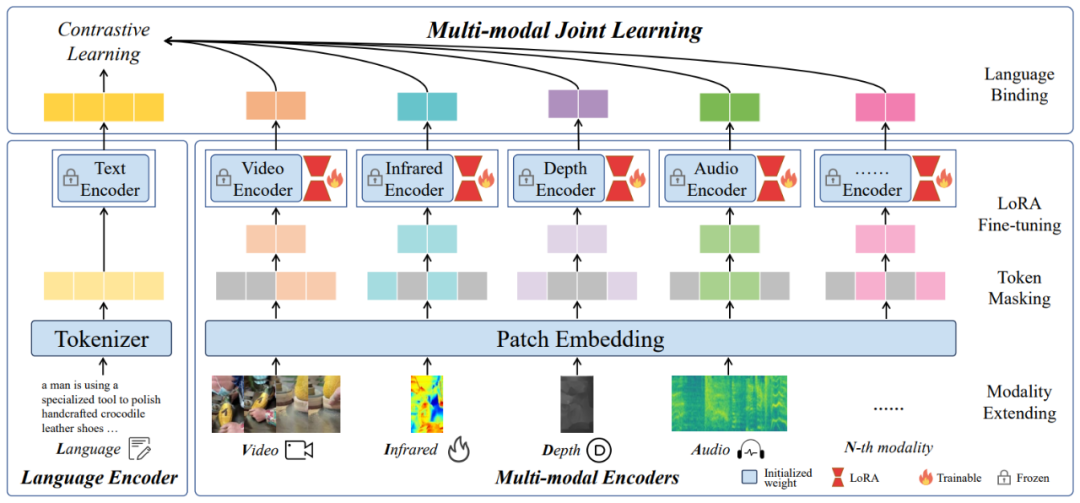
LanguageBind 概览图
具体而言,LanguageBind 通过锚定语言模态,采用一系列优化的对比学习策略,对多模态数据进行预训练。这一过程中,模型学习将来自不同模态的数据编码到与语言模态相兼容的表征中,确保了模态间的语义一致性。这种直接的跨模态语义对齐避免了传统方法中的性能损失,同时提高了模型在下游多模态任务中的泛化能力和适用性。
LanguageBind 框架的另一个优点是其扩展性。由于直接使用语言作为核心对齐模态,当引入新的模态时,无需重构整个对齐机制,只需通过相同的对比学习过程,将新模态的数据映射到已经建立的语言导向嵌入空间。这使得 LanguageBind 不仅适用于现有的模态,也能轻松适应未来可能出现的新模态,为多模态预训练技术的发展奠定了坚实基础。
数据集介绍
在跨模态预训练领域,数据集的构建及其质量对于预训练模型的性能与应用效能具有决定性影响。传统的多模态数据集大多局限于二模态或三模态的配对数据,这种限制导致了对更丰富模态对齐数据集的需求。
因而,该团队开发了 VIDAL-10M 数据集,这是一个创新的五模态数据集,包含了视频 - 语言(VL)、红外 - 语言(IL)、深度 - 语言(DL)、音频 - 语言(AL)等数据对。每个数据对都经过了精心的质量筛选,旨在为跨模态预训练领域提供一个高品质、高完整性的训练基础。

VIDAL-10M 数据集示例
VIDAL-10M 数据集的构建主要包括三步:
视觉相关搜索词库构建。设计一种创新的搜索词获取策略,该策略综合利用了各类视觉任务数据集中的文本信息,如标签和标题,以构建一个丰富视觉概念且多样化的视频数据集,从而增强了数据多样性和覆盖度。
视频和音频数据的收集、清洗与筛选:在数据的收集过程中,该研究采取了基于文本、视觉和音频内容的多种过滤机制,这些机制确保收集到的视频和音频数据与搜索词高度相关,并且满足高标准的质量要求。这一步骤是确保数据集质量的关键环节,它直接影响模型训练的效果和后续任务的性能。
红外、深度模态数据生成与多视角文本增强。此阶段,利用多种先进的生成模型技术合成了红外和深度模态数据,并对文本内容进行了多角度的生成和增强。多视角文本增强包括了标题、标签、关键帧描述、视频概要等多个维度,它为视频内容提供了全面且细致的描述,增强了数据的语义丰富性和描述的细粒度。

VIDAL-10M 数据集的构建过程
实验
LanguageBind 框架被应用于多个模态的零样本分类任务,并与其他模型进行了性能比较。实验结果显示,LanguageBind 方法在包括视频、音频、深度图像、热成像等多模态数据上的 15 个零样本分类与检索任务中均展示了显著的性能提升。这些实验成果强调了 LanguageBind 方法在理解和处理不同模态数据中的潜在能力,尤其是在没有先前样本可供学习的情况下。为了更深入地了解 LanguageBind 方法的性能,可以参照以下详细的实验结果。
表 2 显示,LanguageBind 的性能在 MSR-VTT 上超过 VideoCoca 和 OmniVL ,尽管仅使用 300 万个视频 - 文本对。
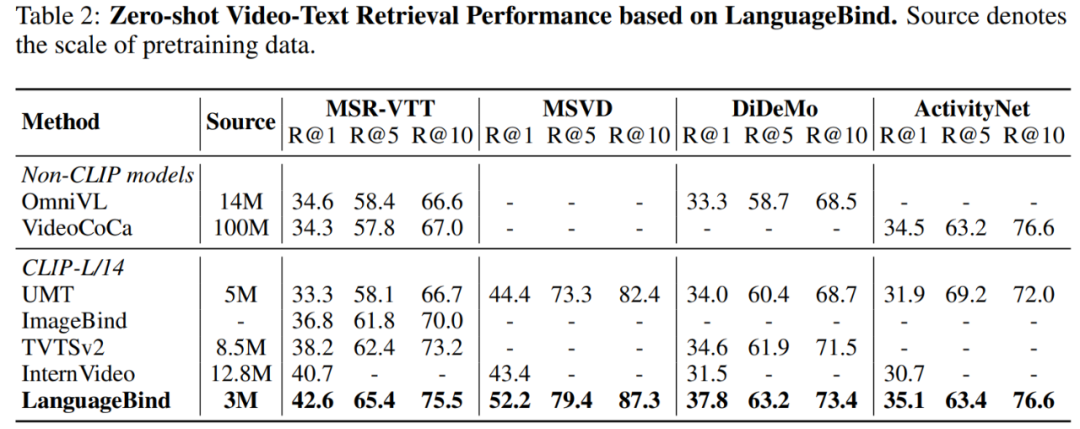
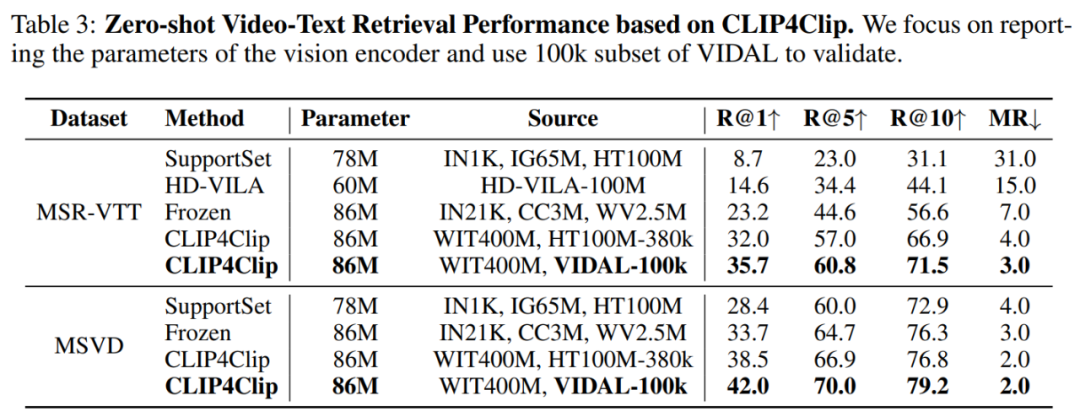
在两个经典数据集 MSR-VTT 和 MSVD 上进行的零样本视频 - 文本检索实验结果如表 3 所示:
该研究还将本文模型与 SOTA 多模态预训练模型 OpenCLIP、ImageBind 在多模态理解任务上进行了比较,结果如表 4 所示:
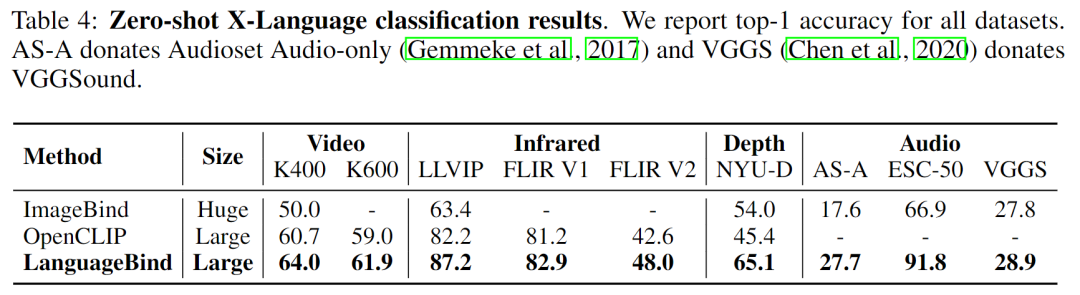
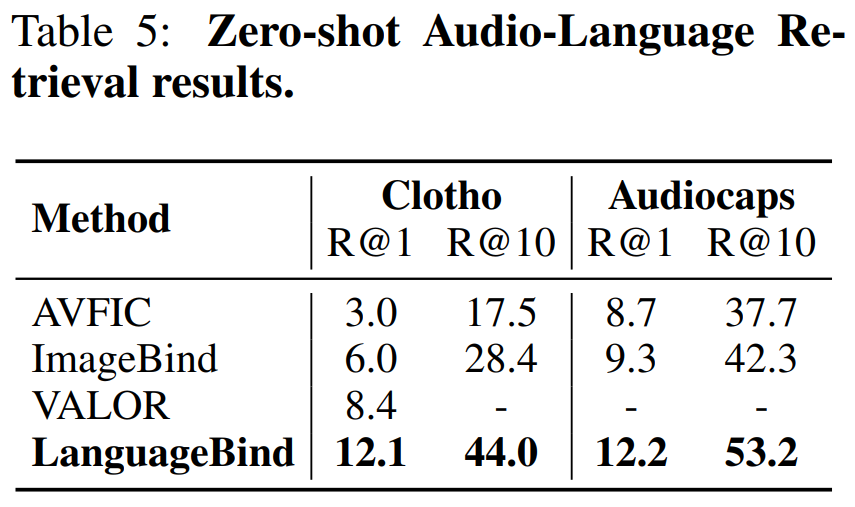
表 5 比较了在 Clotho 数据集和 Audiocaps 数据集上的零样本文本 - 音频检索性能:
-
图像
+关注
关注
2文章
1097浏览量
42481 -
模型
+关注
关注
1文章
3865浏览量
52324 -
智能设备
+关注
关注
5文章
1191浏览量
53630 -
数据集
+关注
关注
4文章
1242浏览量
26286
原文标题:用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
关于C语言对齐的一些总结
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介
ADPD4100/ADPD4101多模态传感器前端:功能特点与应用解析
海光DCU完成Qwen3.5多模态MoE模型全量适配
天数智芯完成阿里云通义千问Qwen3.5系列多模态模型全量适配
格灵深瞳多模态大模型荣登InfoQ 2025中国技术力量年度榜单
多模态感知大模型驱动的密闭空间自主勘探系统的应用与未来发展
格灵深瞳多模态大模型Glint-ME让图文互搜更精准

亚马逊云科技上线Amazon Nova多模态嵌入模型




评论