 一种基于MySQL实现的stream队列
一种基于MySQL实现的stream队列
EMS
Extend MySQL Stream;一种基于 MySQL 实现的 stream 队列。
功能
集群消费、广播消费
自动重试、死信队列
快速重置消息位点,快速回放消息,快速查询消息
消息可基于磁盘积压、消息可快速清理
监控 group 积压,topic 消息量排行,消息链路追踪,消息消费超时告警;
读写性能 1200-3000 QPS 左右
写入设计
msg id 就是 topic 维度的自增 id,可对多个 topic 并发写入
针对一个 topic,需要有物理 physics offset, 每次写入,topic 维度的 physics_offset 自增加一
如果使用 redis 自增特性实现, 为每个 topic 配置一个自增 key, 则可以避免加锁.
redis 实现虽然性能好, 如为配置aof,宕机则可能导致丢失数据, 此时,会出现 offset 重复异常, 过一会随着继续自增, 也就恢复了.
写入需要上锁吗? 看怎么写, 如果使用非原子的形式自增 id,比如数据的的方式,先查出最大 id,再加一,那么必须加锁
topic 维度的自增 id 如果使用 mysql 实现, 性能不堪受辱,因此,此处使用 redis 自增实现(可配置为 mysql 实现);
经过测试,笔记本电脑,单 topic 20 并发写入,qps 在 1000-1500 左右(local mysql & local redis),基本满足业务需求。
考虑到高可用性和业务场景,此处无法使用批量插入
所有的 topic 和 msg 都写入的这一张表中,表数据定时清理,消费完的消息,可提前删除。
注意,本方案写入性能瓶颈是 MySQL Server 的性能瓶颈。
读取设计
假设针对一个 topic,只有一个 consumer,只需循环读取,然后更新 offset 即可。
但结合实际业务场景,这种基本不存在,所以,忽略这种场景。
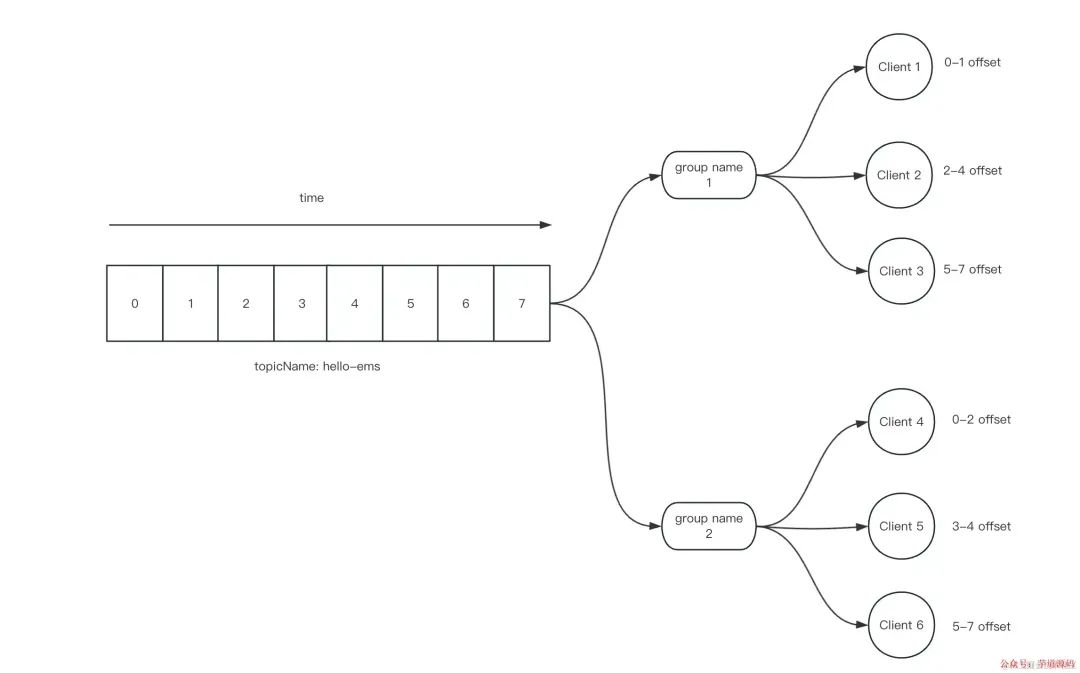
通常,一个 topic 有多个 consumer group(简称 tg), 一个 consumer group 有多个 client(jvm or thread)
如果一个 topic + group(简称 tg),有多个 consumer,每个 consumer 有多个线程,读取和更新 offset 则会有并发问题, 如下图。
这个 client id,我们将其设计为,ip + pid + uuid + thread id;
ip 和 pid 可帮助我们追溯问题
uuid 简单防重复
thread id,一种性能优化,下面细说。
结合实际业务场景,且遵循 simple is better 原则,读取时,使用上锁的方式解决并发问题。锁的粒度就是 tg
考虑到要实现基本的顺序读取和防止重复消费,多线程并发时,我们应当实现基于自增的形式读取 msg;每个 clientid 读取消息后,都会记录一个简单的log,并在 tg 维度增加一个 max offset
每次读取消息时,每个 client 都需要去检查当前想要读取的 tg 是否已经有【其他 client】在操作 max offset。即,我们将锁的粒度缩小到了 max offset;
对这个 tg 维度的 max offset + n
批量插入这个 tg + clientid offset log,表明这个消息被这个 clientid 读取了,同时也间接更新了 max offset(order by offset)
释放锁
拉取刚刚读取的 msg id list 里面的消息体
交给业务处理消息
整体原则是,一个 t + g 的 max offset,同时只能有一个 thread 操作(写和更新)
如果有其他人在读取,则阻塞
如果没有其他人在读取,则锁住这个 tg, 并批量拉取一定数量的消息 id,
ack
对于集群消息,如何保证在断电情况下,消息不丢失,使用数据库存储消息, 写入即不会丢失, 但消费时, 如果刚刚读进内存就立刻宕机,则需要在重启时恢复消息.
每个 client get 到消息后,都需要记录 msg pid,consumer group,state(start、done,retry)为 start 状态
ack success,将 log update 为 done 状态
ack fail 后,将 log update 为 retry 状态,同时将消息存入重试队列
如果 client 还存活,超过 1 分钟(可配),则将其捞出,放进重试队列,并在 10s 进行第一次重试
如果 client 还存活,则立刻将其捞出,放进重试队列,并在 10s 进行第一次重试
这里需要上锁吗?其实是不需要的,因为更新的维度是 client id 的 log,不存在并发更新. 这里更新状态是表示这些消息已经处理结束了,否则无法判定宕机场景。
对于 start 状态的消息,定时任务会去检查
ack 是批量的,ack 失败,仅会导致重复消费。
广播消息
是否为广播消息由 topic 确定
广播消息不需要上锁,每一个订阅该 topic 的 client 都会读取到该消息
广播消息不需要 ack,不需要记录成功或失败或重试,仅需要内存里记录 offset
client id
只有 consumer 需要 client id
client id 由 ip pid uuid + thread id 组成, 可溯源.
client id 需要续约(5s),如果机器宕机,则会被自动清除,且他的 start 状态的消息会进入重试队列,交给同 group 的其他 client
client id 可以自己主动注销,注销前,自己内存的消息应当被优雅消费结束,一般来讲,kill -15 的 jvm 都会主动注销 client id;
核心表设计
topic 表:记录topic 元信息
group 表:记录 group 订阅元信息
msg 表:msg总表,记录写入的信息,包含 body 和 topic 维度的自增 offset,类似 rocketmq commit log
该表会被多个 consumer 消费的消息
该表会被定制删除过期数据
retry msg 表,消费失败、超时的消息,会进入该表,并按阶梯定时消费
dead msg 表,消费重试 16(any config) 次的消息,会进入该表
topic_group_log 表:记录 consumer group client 的 msg 消费记录,包含 state(start、done,retry) 字段,可 ack
该表的记录行数会非常多,单行数据较少,可自动删除 done 的记录
锁
如上文所说,由于本方案未采用常见的多 queue 和多 partition 的设计,因此瓶颈在于上图提到的分布式锁的设计上,具体链路为 consumer group client 在集群消费时, 为了让并发读取的 thread 拉取到的消息尽可能准确,使用上锁的方式来实现。
总体看下来,可以简单理解为,ems 失去了性能,却拥有了所有。
审核编辑:刘清
-
MySQL
+关注
关注
1文章
804浏览量
26542 -
QPS
+关注
关注
0文章
24浏览量
8800
原文标题:如何设计一款基于 MySQL 实现的 Message Queue
文章出处:【微信号:芋道源码,微信公众号:芋道源码】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论