 清华开发出超高性能计算芯片:速度比高端GPU提升3000倍,能效提升400万倍!
清华开发出超高性能计算芯片:速度比高端GPU提升3000倍,能效提升400万倍!
随着各类大模型和深度神经网络涌现,如何制造出满足人工智能发展、兼具大算力和高能效的下一代AI芯片,已成为国际前沿热点。中国科协发布的2023重大科学问题中“如何实现低能耗人工智能”被排在首位。
2023年10月25日,清华大学团队在超高性能计算芯片领域取得新突破。相关成果以“All-analog photo-electronic chip for high-speed vision tasks”为题发表在Nature上。这枚芯片基于纯模拟光电融合计算架构,在包括ImageNet等智能视觉任务实测中,相同准确率下,比现有高性能GPU算力提升3000倍,能效提升400万倍。

图1 相关论文(来源Nature)
未来已来?光为载体的计算芯片
实现算力飞跃并非易事,特别是当前传统的芯片架构,受限于电子晶体管大小逼近物理极限。全新计算架构成为破局的关键。光计算以其超高的并行度和速度,被认为是未来颠覆性计算架构的最有力竞争方案之一。光计算,顾名思义是将计算载体从电变为光,利用光在芯片中的传播进行计算。面对以光速计算的诱人前景,数年来海内外知名科研团队相继提出多种设计,但要替代现有电子器件实现系统级应用,仍面临重大瓶颈:一是如何在一枚芯片上集成大规模的计算单元(可控神经元),且约束误差累计程度;二是实现高速高效的片上非线性;三是为兼容目前以电子信号为主体的信息社会,如何提供光计算与电子信号计算的高效接口。当前常见的模数转换功耗,较光计算每步乘加运算高出多个数量级,掩盖了光计算本身的性能优势,导致光芯片难以在实际应用中体现出优越性。
系统级算力和能效,超现有芯片万倍
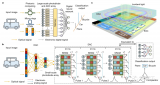
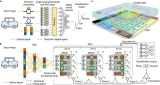
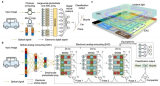
为解决这一国际难题,清华大学团队创造性地提出了模拟电融合模拟光的计算框架,构建可见光下的大规模多层衍射神经网络实现视觉特征提取,利用光电流直接进行基于基尔霍夫定律的纯模拟电子计算,两者集成在同一枚芯片框架内,完成了“传感前 传感中 近传感”的新型计算系统。极大地降低了对于高精度ADC的需求,消除传统计算机视觉处理范式在模数转换过程中速度、精度与功耗相互制约的物理瓶颈,在一枚芯片上突破大规模集成、高效非线性、高速光电接口三个关键瓶颈。
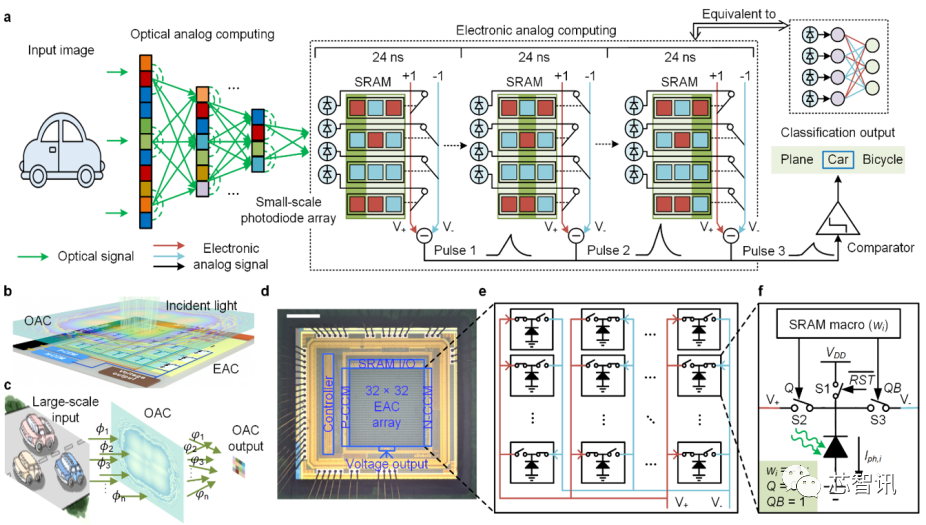
图2. 光电计算芯片ACCEL的计算原理和芯片架构(来源Nature)
实测表现下,ACCEL芯片的系统级算力达到现有高性能芯片的数千倍。同时系统级能效达74.8 Peta-OPS/W,较现有的高性能GPU、TPU、光计算和模拟电计算架构,提升了两千到数百万倍。
在超低功耗下运行的ACCEL将有助于大幅度改善发热问题,对于芯片的未来设计带来全方位突破,并为超高速物理观测提供算力基础。同时对无人系统、自动驾驶等续航能力要求高的场景带来重大利好。
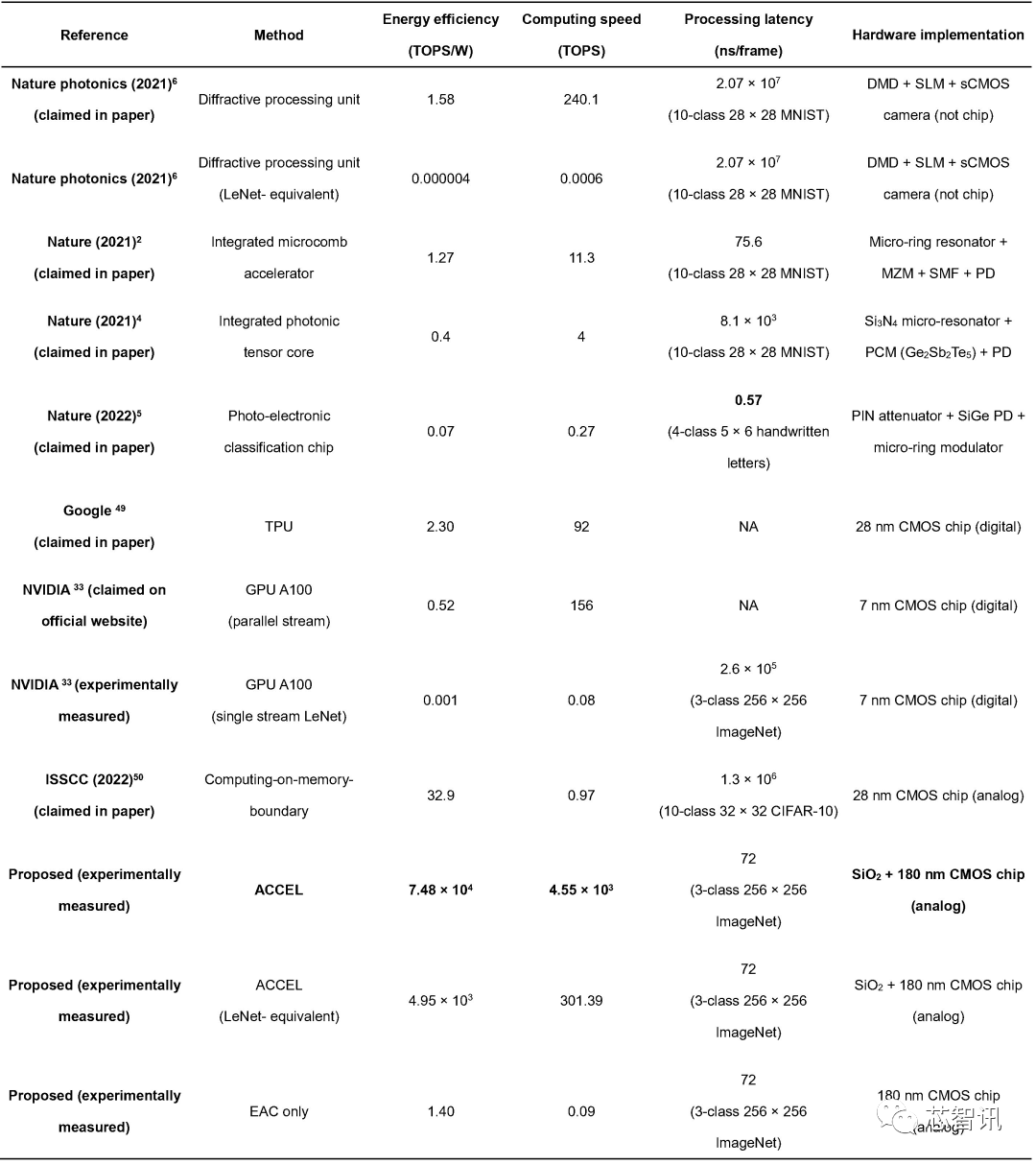
表1. ACCEL和现有高性能芯片的系统级实测性能指标对比 (来源:Nature)非相干光直接计算
更进一步,ACCEL芯片还支持非相干光视觉场景的直接计算,如论文中演示的交通场景实验。显著拓展了ACCEL的应用领域,有望颠覆目前自动驾驶、机器人视觉、移动设备等领域先将图片拍摄并保存在内存中后进行计算的思路,避免传输和ADC带宽限制,在传感过程中完成计算。

图3. ACCEL可用于电子设备超低功耗人脸唤醒示意动图(来源:清华大学)
开辟新路径:颠覆性架构有望真正落地
清华攻关团队提出的新型计算架构不仅对于光计算技术的应用部署意义重大,对未来其他高效能计算技术与当前电子信息系统的融合,亦深有启发。
论文通讯作者之一,清华大学戴琼海院士介绍道,“采用全新原理研发出计算系统是一座大山,而将新一代计算架构真正落地到现实生活,解决国计民生的重大需求,是攀过高峰后更重要的攻关。”Nature杂志特邀在Research Briefing发表的该研究专题评述也指出,“或许这项工作的出现,会让新一代计算架构,比预想中早得多地进入日常生活(ACCEL might enable these architectures to play a part in our daily life much sooner than expected.)”。
清华大学戴琼海院士、方璐副教授、乔飞副研究员、吴嘉敏助理教授为本文的共同通讯作者;博士生陈一彤、博士生麦麦提·那扎买提、许晗博士为共同一作;孟瑶博士、周天贶助理研究员、博士生李广普、范静涛研究员、魏琦副研究员共同参与了这项研究。
-
晶体管
+关注
关注
77文章
9678浏览量
138049 -
人工智能
+关注
关注
1791文章
47137浏览量
238113 -
智能视觉
+关注
关注
0文章
100浏览量
9205
原文标题:清华开发出超高性能计算芯片:速度比高端GPU提升3000倍,能效提升400万倍!
文章出处:【微信号:wc_ysj,微信公众号:旺材芯片】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华为云MongoDB弹性伸缩能力提升100倍
爱知制钢开发出比MR 灵敏度高100 万倍的微型地磁传感器
麻省理工研发新神经网络芯片,速度提升6倍,功耗减少94%!
研究人员开发出半导体测量新技术,灵敏度比以往测量技术提升了10万倍!
德州大学开发出半导体测量新技术 比以往提升10万倍
MIT设计新型光子芯片 效率比电子芯片高1000万倍
Imagination推出全新A系列GPU,性能将提升2.5倍
AMD:用于AI训练及高性能计算能效将在2025年提高30倍
清华大学开发出超高速光电计算芯片,性能是商用芯片的3000倍!
中国开发新芯片,算力提升3000倍!
国际首个全模拟光电智能计算芯片的算力可提升3000倍





 工商网监
工商网监
评论