 澎峰科技发布大模型推理引擎PerfXLLM
澎峰科技发布大模型推理引擎PerfXLLM
自从2020年6月OpenAI发布chatGPT之后,基于Transformer网络结构的语言大模型(LLM)引发了全世界的注意与追捧,成为了人工智能领域的里程碑事件。
但大模型推理所需要的巨额开销也引发了相关研究者的关注。如何高效地进行推理,并尽可能地减少成本,从而促进大模型应用的落地成为了目前的关键问题。
于是,澎峰科技研发了一款大模型推理引擎—PerfXLLM,并且已经在高通的骁龙8Gen2平台实现了应用。接下来将分为四个部分进行介绍,第一部分将介绍PerfXLLM的整体架构设计,第二部分将展示手机端的性能表现,第三部分将详细地阐述手机端的推理优化方案,最后在第四部分将介绍PerfXLLM的未来规划。
一、PerfXLLM整体架构
目前大模型推理过程主要放在服务器或者云上进行处理。用户发出请求,服务器进行响应,通过GPU等高性能计算部件完成推理计算,并通过网络将结果传输给用户。而随着移动端设备硬件能力的不断进步,并且用户原始数据可能存在敏感隐私信息导致对安全问题有所顾虑,大模型在移动端的应用和落地也成为了实际需求之一。为了兼顾两部分的需求,PerfXLLM设计上采用了云端一体的架构理念。
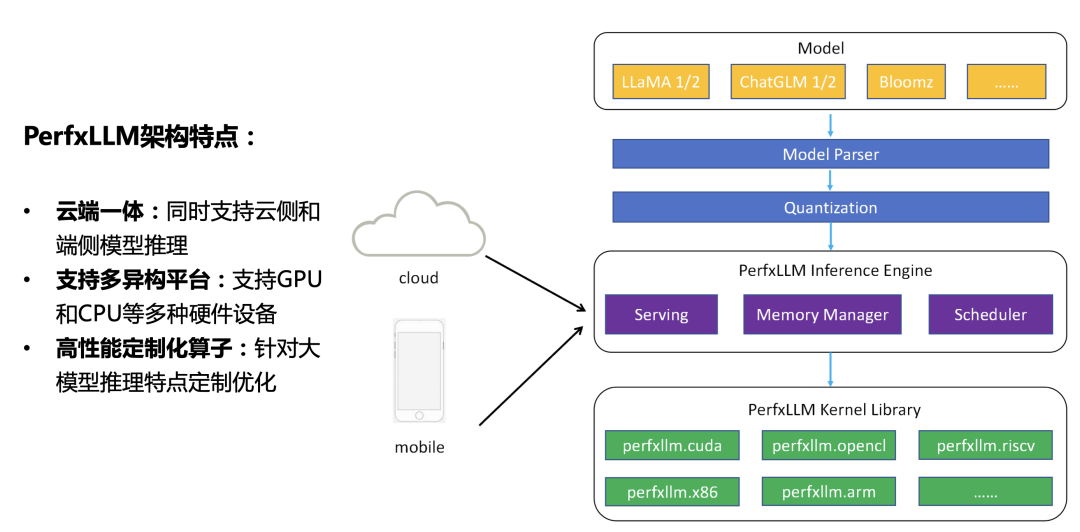
如上图所示,当模型经过解析量化之后被PerfXLLM的推理引擎加载至内存中。不管是云侧还是端侧都是调用同样的一套推理引擎代码。有所区别的地方在于云侧需要进行额外的Serving模块,从而获得更高的硬件利用率和QPS响应。再聚焦到底层Kernel,PerfXLLM中开发了一套针对大模型推理的算子库,可以支持GPU、CPU等多种硬件设备。
二、PerfXLLM应用在手机端
目前,PerfXLLM针对高通骁龙8Gen2芯片进行了定制优化,高通8Gen2芯片进行了定制优化,对LlaMA模型采用了AWQ的int4量化方法,并为模型开发了PerfXChat APP。生成速度为6.7 token/s。模型内存占用为3.7GB。而llama.cpp的生成速度仅为3.2 token/s。
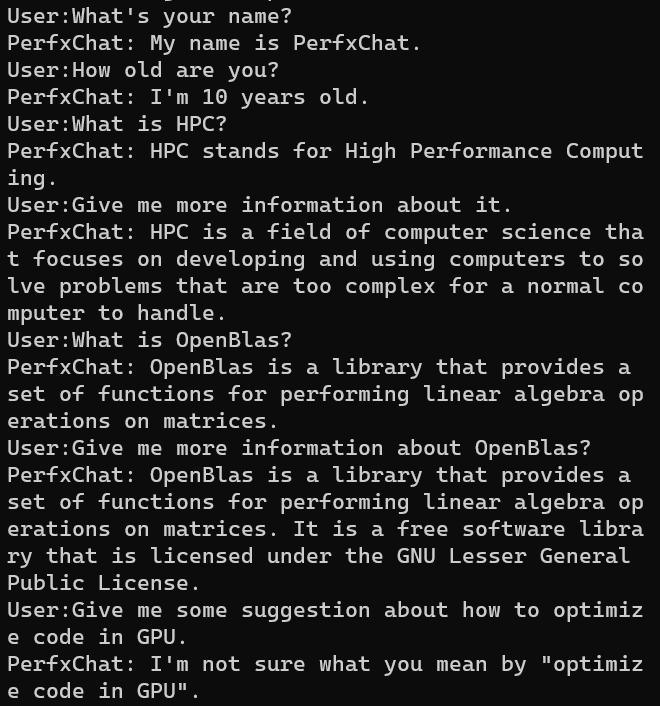
具体而言,通过芯片上的Andreno GPU进行加速,使用了OpenCL编程模型。首先对LlaMA模型进行int4量化,所采用的方式是AWQ量化方法。而后针对LlaMA模型中最耗时的Kernel进行了优化。手机端的输入token和生成token较少时,模型主要瓶颈在于GEMM算子和GEMV算子,研发团队对这两个算子进行了手工调优。模型使用效果如下。
三、手机端推理优化方案介绍
由于手机端的硬件性能与服务器端差距较大,因而在手机端如何将大模型运行起来,并带给用户流畅的使用体验并不是一件容易的事情。为了对手机端的大模型推理进行优化,PerfXLLM目前主要采用的手段有低精度量化、算子融合以及核心算子调优。
3.1.低精度量化
低精度量化指的是将更高精度的数据表示类型转化成低精度的数据表示类型来加快计算过程。常用的低精度量化有fp16、int8、int4等。通过低精度的量化,可以减少访存开销和内存空间,通过特殊计算单元加快运算。因而可以获得比原精度更高的性能表现。PerfXLLM需要将7B的模型运行在手机上。如果是fp16的模型,则需要大概14GB的内存占用。但是目前市面上手机内存一般不超过16GB,再减去系统本身所需要的内存占用以及其他APP可能需要的内存空间,必须使用低精度量化才能满足。
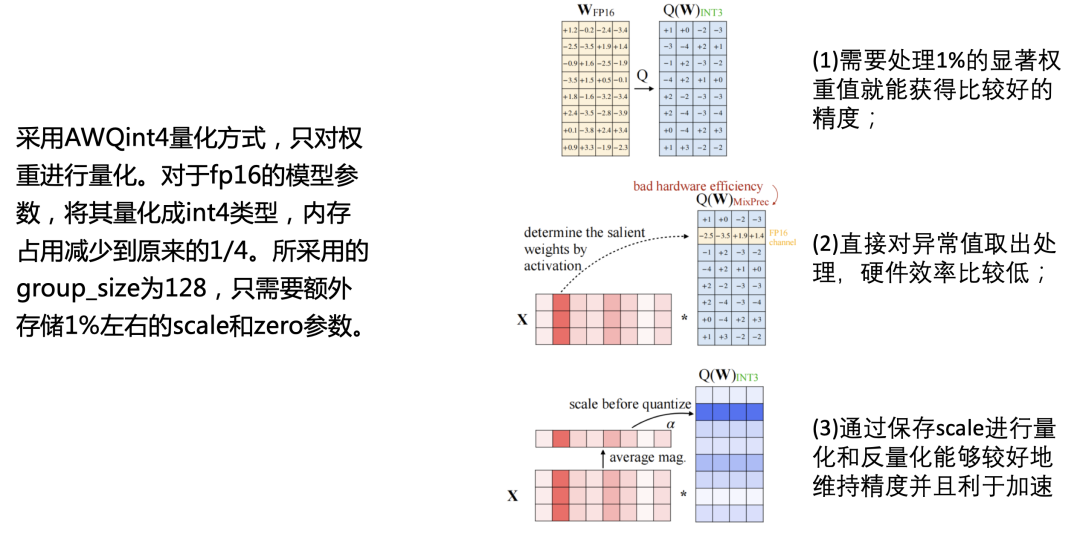
PerfXLLM采用的是AWQ量化方法,只对权重进行量化。对于fp16的模型参数,将其量化成int4类型,内存占用减少到原来的1/4。所采用的group_size为128,只需要额外存储1%左右的scale和zero参数。
3.2.算子融合
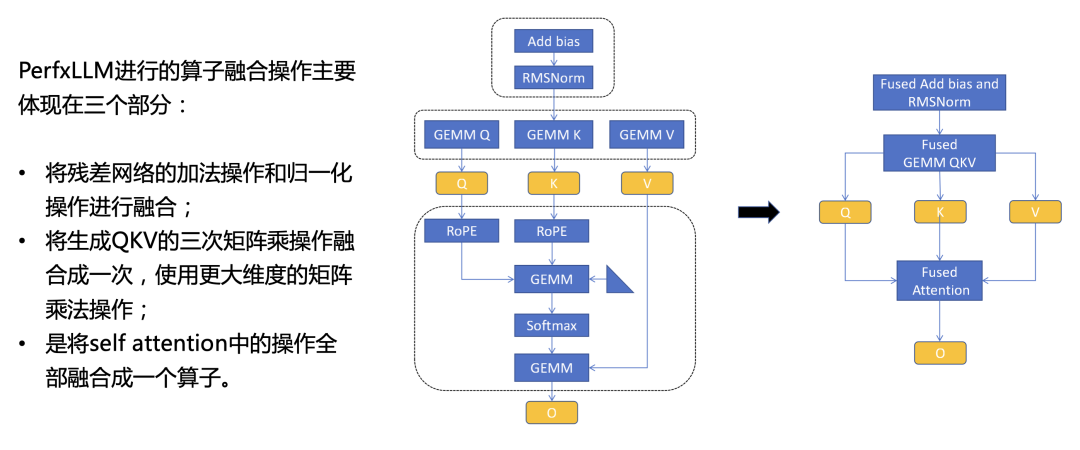
算子融合是将多个算子融合成一个,从而减少中间结果的数据读取和写入操作,并且也能有效地减少Kernel launch所需要的开销。为了提高推理速度,PerfXLLM进行的算子融合操作主要体现在三个部分。第一部分是将残差网络的加法操作和归一化操作进行融合,避免了中间结果在全局内存中的搬运;第二部分是将生成QKV的三次矩阵乘操作融合成一次,使用更大维度的矩阵乘法操作,从而更充分地利用硬件性能;第三部分是将self attention中的操作全部融合成一个算子,这些操作包含针对QK的旋转编码,QKV的两次矩阵乘法以及中间的Softmax操作。具体的示意图如下。
3.3.核心算子调优
语言大模型中所需要的算子较少,并且绝大部分性能开销都集中在1-2个算子上,因而针对核心算子的细致调优便显得尤为关键。在手机端,当生成token数量较少时,Attention相关算子的耗时占比非常少,而GEMM(通用矩阵乘法)类的算子耗时几乎占据了整个推理过程。对于大模型推理而言,一般会分为两个过程。在第一个过程中,输入的token数量大于1,对应的算子即GEMM。第二个过程中,输入的token数量恒定为1,对应的算子即GEMV(矩阵向量乘法)。因此,推理优化的核心问题在于如何提高GEMM和GEMV的性能。PerxLLM对这两个算子进行了细致的优化。
1)针对GEMM算子。首先介绍GEMM算子的定义,给定矩阵A和B,其维度分别为[m, k]和[k,n],将两者相乘得到矩阵C,维度为[m, n]。根据输入token数量的不同,PerfXLLM将其分为两种情况进行优化。当输入token数量较少时,矩阵B是一个高瘦矩阵,GEMM变成访存密集型算子。当输入token数量较多时,GEMM是一个计算密集型算子。针对两种不同的情况,PerfXLLM采用了两种不同的分块模式,将所需要的数据放置在共享内存之中,以尽可能地减少对全局内存的数据读取。此外,采用了向量化访存来提高访存效率,通过循环展开来避免流水线阻塞提高指令并行度,进行参数调优来获得更好的并行能力和分块配置参数。具体的性能表现如下。固定M为12288,K为4096,N变化。
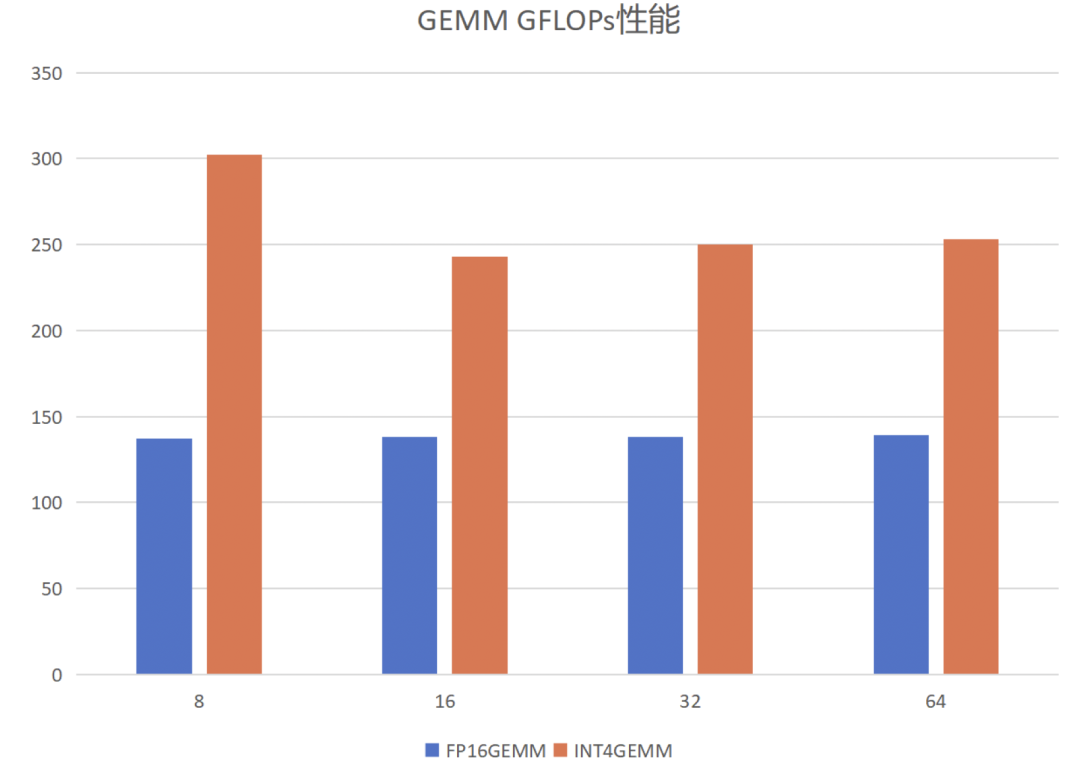
2)针对GEMV算子。需要说明的是,GEMV可以视作GEMM的一种变体,当B矩阵的n等于1时,则GEMM转换为GEMV算子。GEMV是一个典型的访存密集型算子,其优化核心在于如何提高访存效率,并掩盖计算所需要的开销。PerfXLLM通过向量化访存来提高访存效率,通过循环展开来避免流水线阻塞提高指令并行度。并且针对int4类型的GEMV,通过共享内存来存储zero和scale来减少对全局内存的数据访问。此外,对A矩阵的两个维度进行分块来提高并行性。使用Image类型来提高对于B向量的访存性能。
以上一些披露的信息,表明了PerfXLLM已经完成了整个计算系统架构的设计,并将紧密跟随大模型算法的更迭速度,这弥补了计算芯片迭代慢的弊端(>2年)。
四、未来规划
4.1.更多的模型支持
4.2.支持更多的硬件
4.3.性能优化
4.4.框架优化
欢迎联系我们wangjh@perfxlab.com。一起探索大模型的软件基础建设。
原文标题:澎峰科技发布大模型推理引擎PerfXLLM
文章出处:【微信公众号:澎峰科技PerfXLab】欢迎添加关注!文章转载请注明出处。
-
RISC-V
+关注
关注
45文章
2322浏览量
46481 -
澎峰科技
+关注
关注
0文章
57浏览量
3208
原文标题:澎峰科技发布大模型推理引擎PerfXLLM
文章出处:【微信号:perfxlab,微信公众号:perfxlab】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
澎峰科技与沐曦完成联合测试,实现全面兼容
澎峰科技计算软件栈与沐曦GPU完成适配和互认证
澎峰科技校园行走进湖南开放大学
澎峰科技携手湖南第一师范,开启大模型AI学习新模式

澎峰科技PerfXCloud平台获海光DCU生态兼容性认证
澎峰科技助力中国移动 重磅发布智算“芯合”算力原生基础软件栈2.0

喜报 祝贺澎峰科技荣获“2024中国算力卓越企业奖”

第一届“澎峰云・大模型AI校园应用创新赛完美结束
“澎峰云”校园行:湖南科技职业学院站,共启校园创新之旅!

澎峰科技高性能大模型推理引擎PerfXLM解析

澎峰科技受邀参加全球AI芯片峰会,探讨大模型推理引擎PerfXLM面向RISC-V的移植和优化

澎峰科技受聘为“主权级大模型”创新联合体学术委员会委员
澎峰科技CA100智能计算一体机核心优势解读
澎峰科技与并行科技共拓AI大模型技术创新应用服务






 工商网监
工商网监
评论