 SAFA:高效时空视频超分辨率的尺度自适应特征聚合
SAFA:高效时空视频超分辨率的尺度自适应特征聚合
去年底我在迭代插帧开源模型时有一些发现,准备写 paper 的时候感觉更合适放进时空超分里,也顺便讨论了一些我们之前论文的遗留问题,在 WACV2024 发表。
项目主页:
github.com/megvii-research/WACV2024-SAFA
作者和他们的主页:Zhewei Huang, Ailin Huang, Xiaotao Hu, Chen Hu, Jun Xu, Shuchang Zhou
TLDR:时空超分任务通常输入两帧 RGB,插出中间的若干帧,并且要把所有的帧以长宽四倍的分辨率输出,SAFA 在推理时根据输入会调整模型的处理分辨率,实验基准跟随 VideoINR,用仅 1/3 计算量取得平均 0.5dB 的提升。
背景:
本来其实是刷了一个插帧的涨点后,再把技术搬到视频时空超分上的。因为插帧这边竞争太多了,把对比实验做扎实不容易。时空超分的训练测试调试好大概单独花了两周,主要是一些细节上对齐麻烦。Zooming Slomo 一系的工作训练时间长达一周,VideoINR 设的基准训练会简便一些(训练集不一样)。好在这个领域大部分作者都能联系到,特别感谢 Gang Xu,Zeyuan Chen, Mengshun Hu 在我刷实验的时候提供的讨论意见,Jun Xu 老师恰好也是 TMNet 的作者帮改了很多。
介绍:
视频插帧和时空超分的联系:
在视频插帧中,对于帧 I0 和 I1,给定时间 t,目标是出一个中间帧 It。我们把视频时空超分也写成类似的形式:对于低分辨率的帧 I0{LR} 和 I1{LR},给定时间 t,输出四倍分辨率的 It{HR}。
在时空超分中,除了 I0.5{HR}, 我们还要得到 I0{HR}, I1{HR},如果把它们看成三次类似的推理,即 t=0, 0.5, 1 的情况各推理一次,这样就和视频插帧非常像了。对于升分辨率的问题,考虑把插帧做到特征图上,即 低分辨率帧 -> 编码成特征 -> 特征图上插帧 -> 解码得到高分辨率帧。
多尺度处理:
视频有不同分辨率、运动幅度等等,所以相关工作往往都包含手工设计多尺度多阶段的网络结构,我们认为这是模型越做越复杂的原因之一。我们先反思了先前工作:
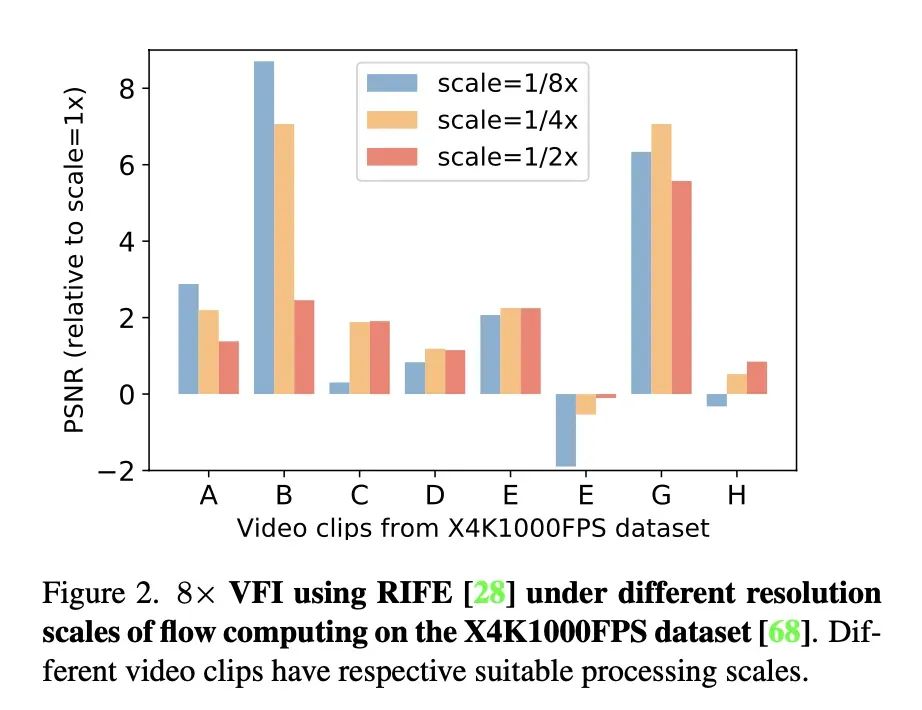
在推理 4K 视频的时候,把视频先缩放再估计光流可能更准
即使 RIFE 模型中做了多尺度设计,但是我们发现每个视频都要手动指定一个光流推理尺度:即要把原始帧先缩小,推理光流,再把光流放大,光流结果才会更准。这启发我们去设计自适应的动态网络来缓解推理尺度问题。
主体结构:
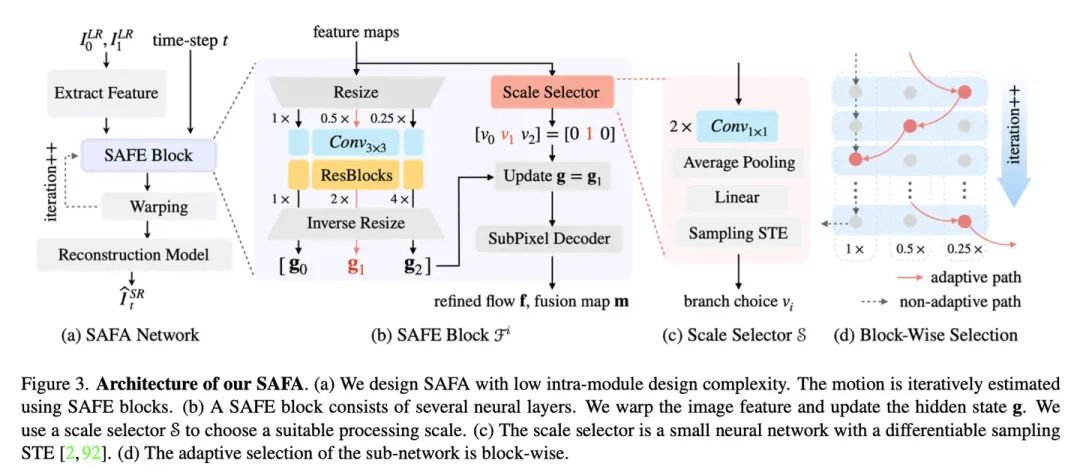
主要结构
(a) 是整个网络结构:用了类似 RAFT 的迭代试错方式来估计光流 Ft->0, Ft->1,用光流插帧特征图,然后解码。
比较有意思的是 (b):我们刚才提到一种做法,把视频帧缩小,在小图上估计光流,再把光流放大可能可以更准。那这里就给网络设计三条路,即 1x, 0.5x, 0,25x 的处理分辨率,具体选哪条让尺度选择器(一个计算量很小的网络来决定)。全选 1x 就是在原始分辨率上处理,0.5x 和 0.25x 在小图上处理(会更快)。
(c) 尺度选择器是两个 conv1x1、池化、全连接加上一个 STE。这里 STE 的技术是为了让路径选择过程变成可微分的。我们在前一个工作 DMVFN 中用 STE 构建了双分支选择,这里构建了多分支选择:实验发现比较有效的做法是把 K 分支选择看成 K-1 次双分支选择,具体见论文。
(d) 强调一下,每个迭代块都会给自己选处理尺度。
实验:
论文里所有实验,在空间上做的都是四倍超分,主要实验结果:
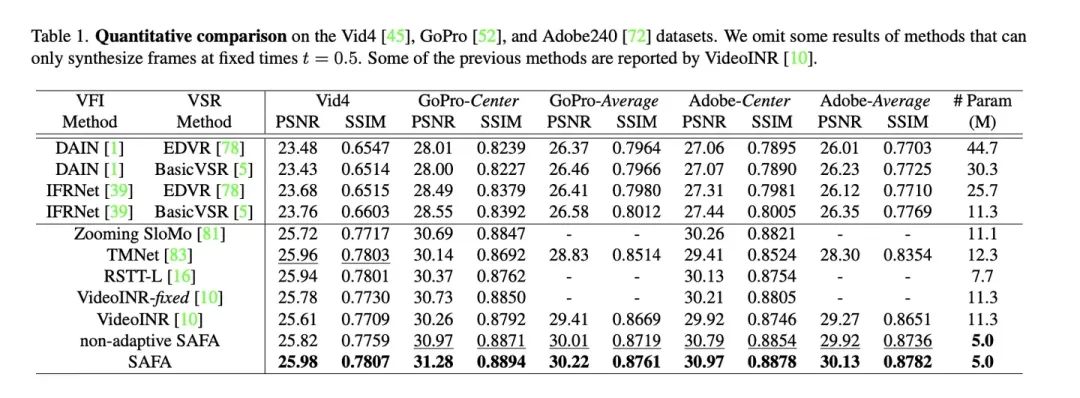
2x时间4x空间实验
以上是 2x 时间,4x 空间的实验,不同时间倍数和 VideoINR、TMNet 的对比:
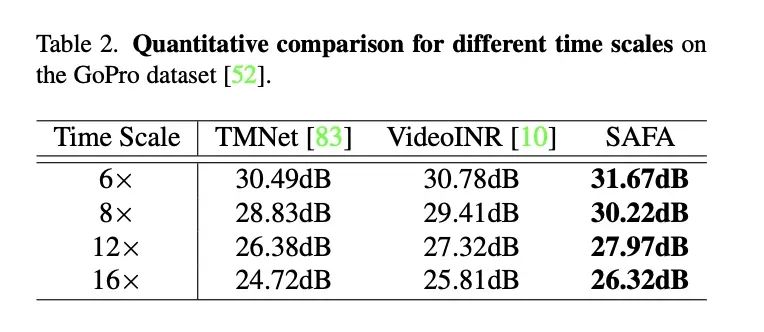
不同时间倍数的时空超分实验
视觉效果可以看论文里的图和演示视频
因为比较节制地选用了简单的设计组件和简洁的结构,运行效率也会好一些:
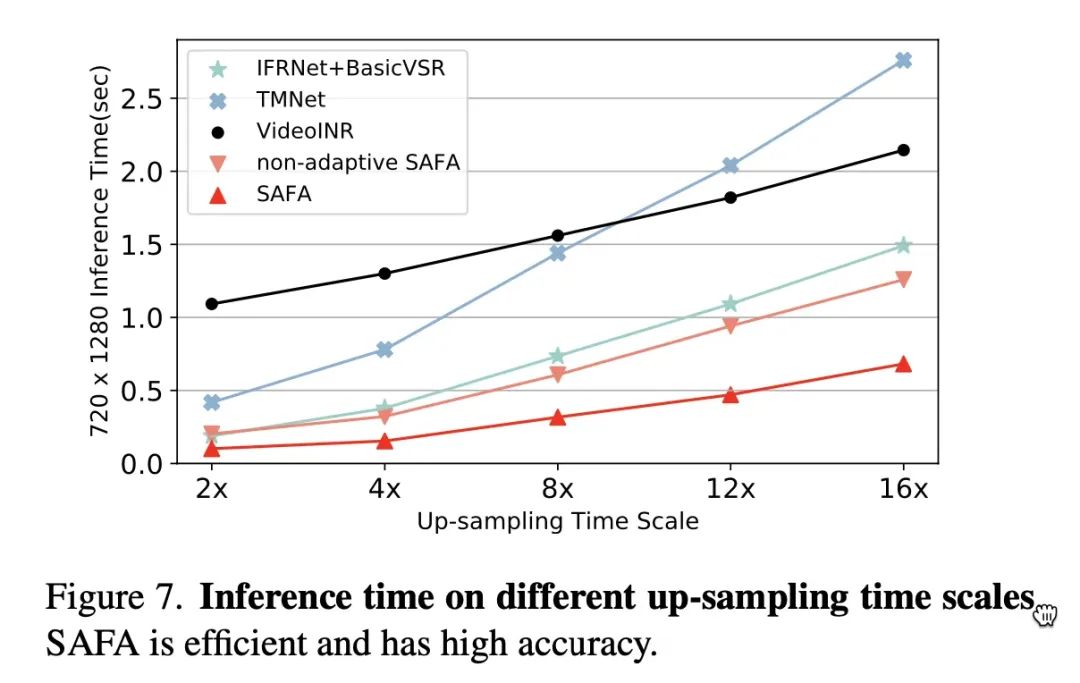
随着倍数增加,推理开销比线性略低一些
在消融实验中,我们讨论一些 trick。
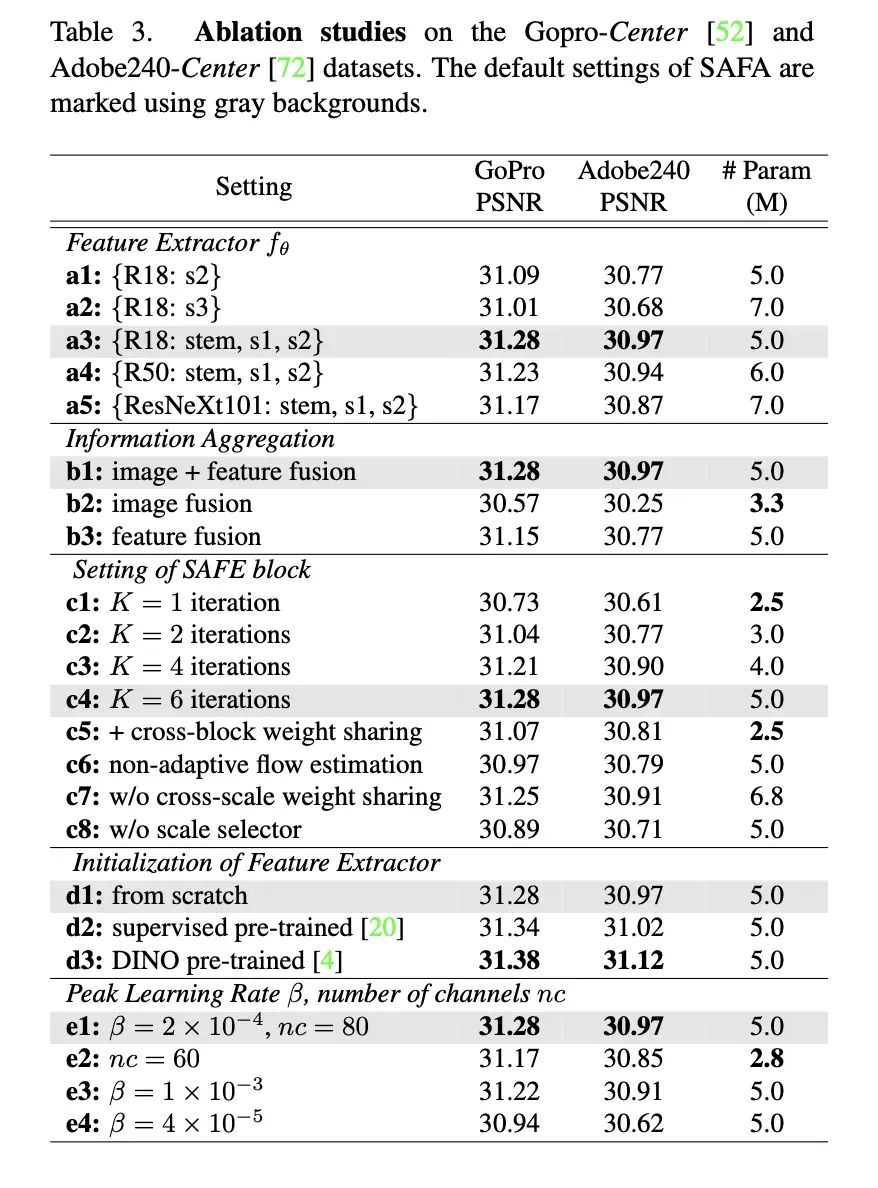
各种消融实验
a1-a5: 特征提取器怎么选?最后选中的是 ResNet18 的 stem(最前面的卷积和池化)的输出和前两个 block 的特征层的混合。选更复杂的网络会掉点,我个人感觉是因为 BottleNeck 的设计在空间信息的保存上有负面效果。
b1-b3: 这里是说生成最后的结果的时候,最好拿两部分信息,一方面是从原始的低分辨率图 + 光流得到一个中间帧打底,另一方面再用插帧出的特征图来修:

图片信息融合和特征信息融合
c1-c8: 对光流组件的设计进行一些讨论,比如迭代次数 1 (c1) 的时候效果会很差,不同分支如果不共享参数 (c7),效果差不多但增大参数量。
这里插一个验证性实验,尺度选择器真的会根据处理视频的分辨率出合理的路线选择:
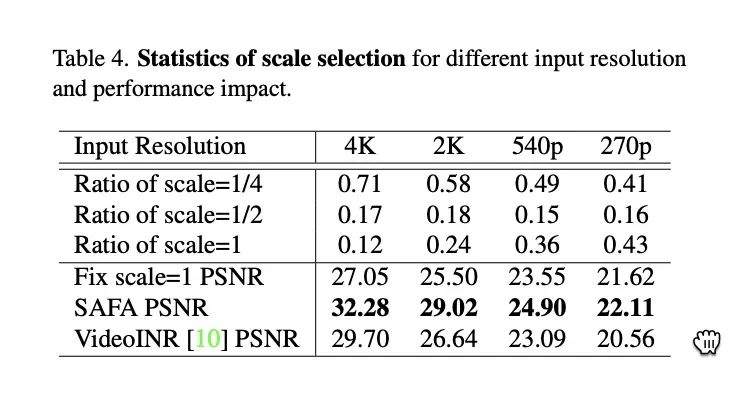
关于尺度选择的统计
可以看到对于 4K 视频,模型就会选更多的 scale=1/4。
d1-d3: 这里是想提一下,如果把特征提取器做的更好是能涨点的,比如换成 ImageNet 训练过的提取器或者无监督方法训练的提取器。
e1-e4: 学习率太小会掉点;因为设计很规整,所以改通道数 nc 能很方便地控制设计出的网络的计算量。
方法限制:
首先因为沿用 VideoINR 的实验基准,这里没做多帧输入,像 BasicVSR 类似的作品在离线处理的时候是可以用非常多的帧来提高性能的,我们还是想探索一下这种穷人版的视频超分;做论文的时候因为都比 PSNR、SSIM,感知损失相关的探索没有做,加个 vgg loss 等肯定视觉效果会更好一些
还有就是实验环境下,低分辨率图片是直接把高分辨率图片 bicubic 下采样得到的,因此它和带有复杂退化的真实视频是很不一样的,这里肯定是需要加入 Real-ESRGAN 等方法的退化模拟和更多的数据集才能真正把这项工作推向实用的。我最近也在训练这样的模型,希望不久以后能整合进我们的插帧应用里。
部分附录:
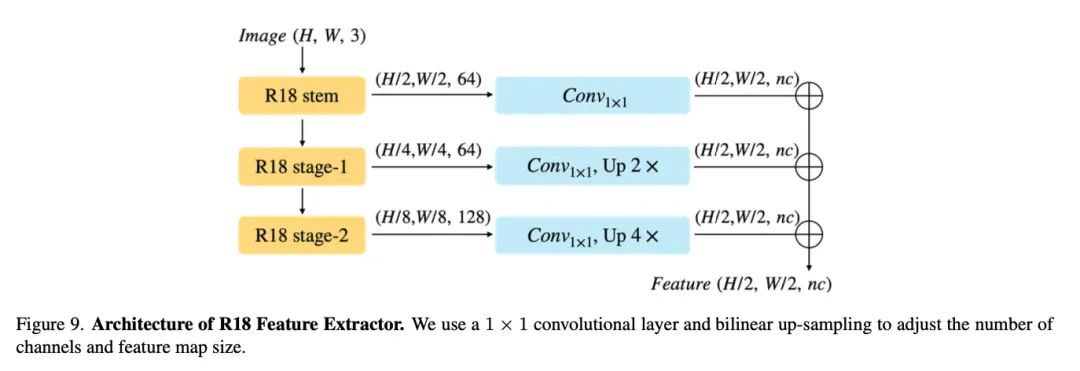
特征提取的具体结构
和 ZoomingSlomo、VideoINR 的对比,希望能让读者感受到 SAFA 概念上的简化:
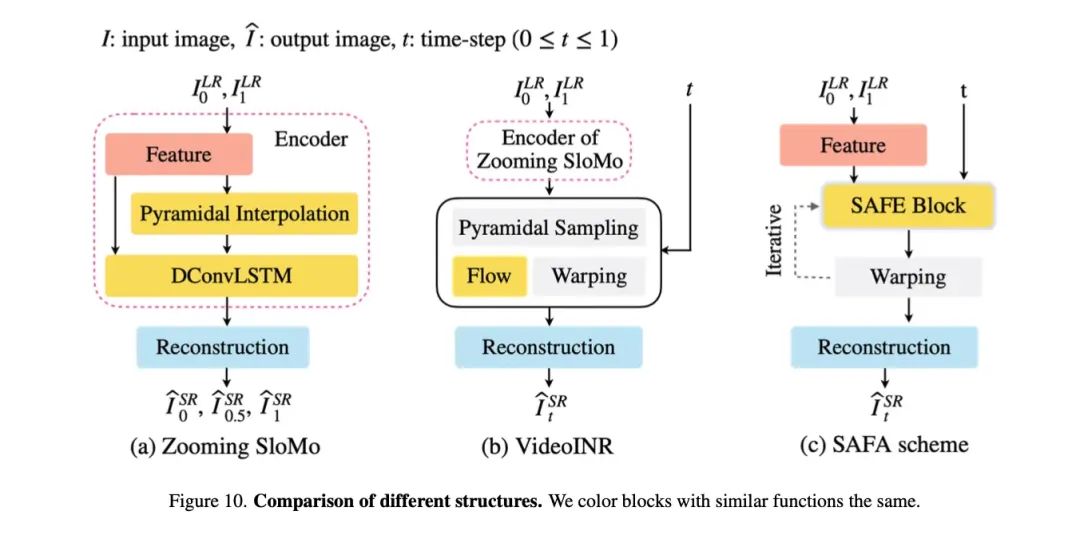
和之前一些框架对比
通过可视化,我们发现 zooming slomo 中求出的流并不像光流,因此认为在 VideoINR 中,部分运动预测的任务实际上被 Encoder 吸收了,导致主体网络部分只需要承担小部分的运动预测任务:
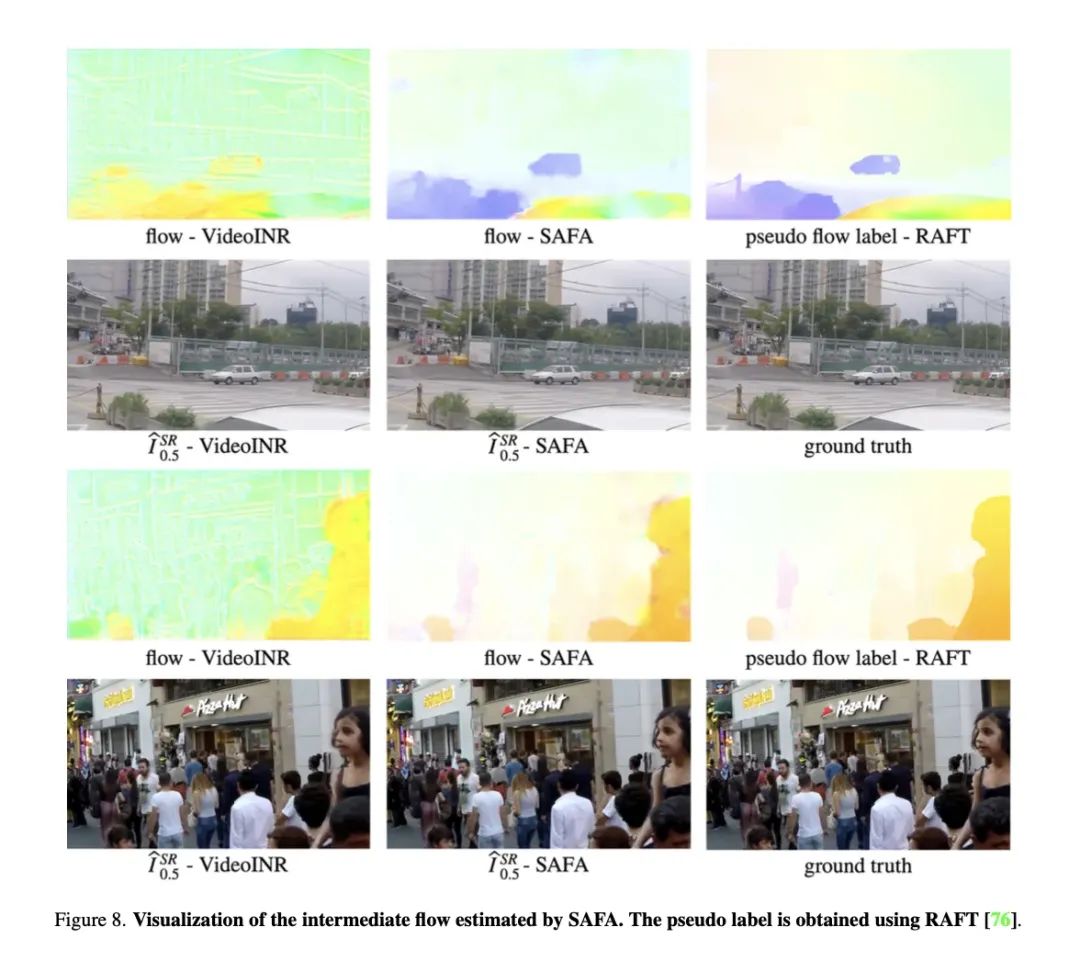
光流可视化,和伪标签对比
不同时间下,光流和遮挡图的可视化:
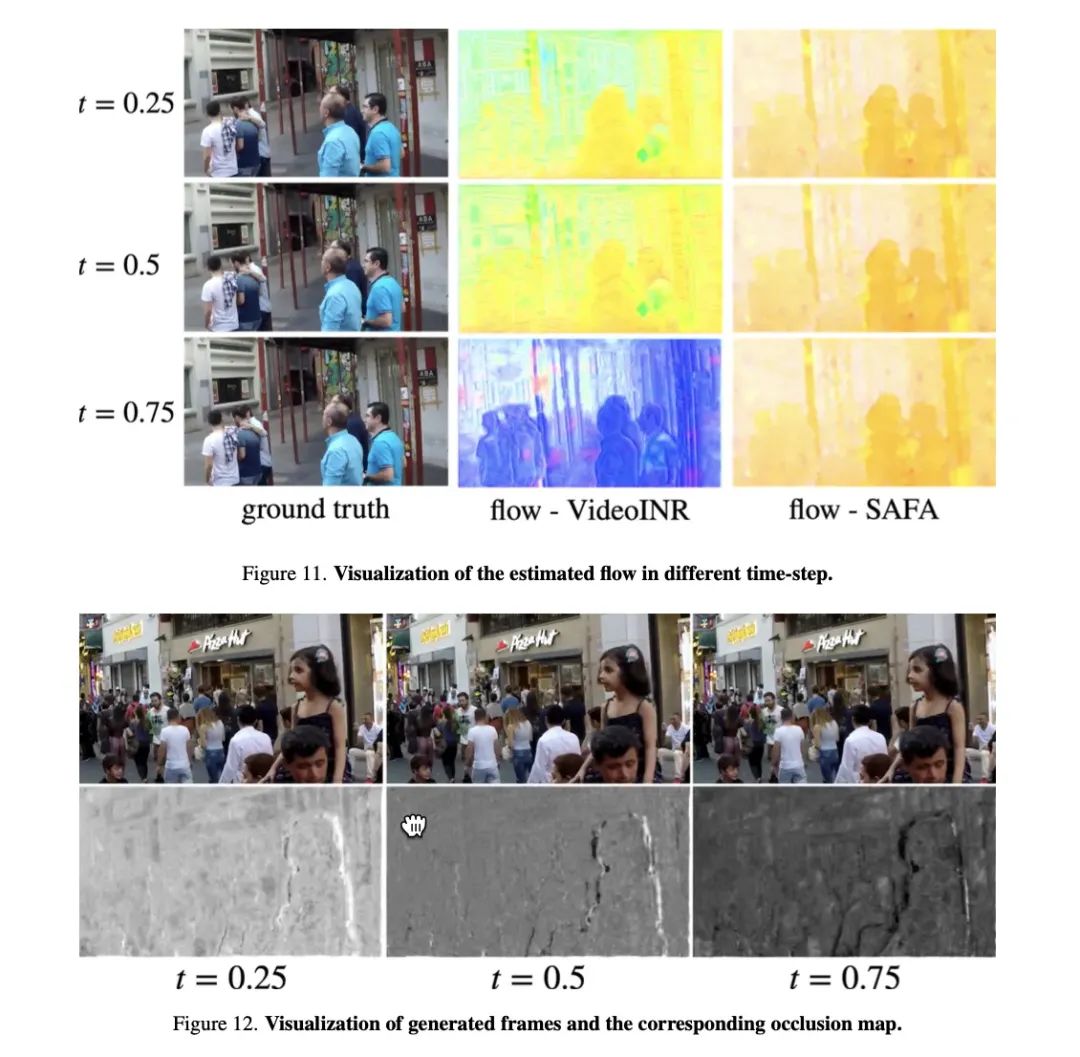
-
视频
+关注
关注
6文章
1932浏览量
72805 -
模型
+关注
关注
1文章
3158浏览量
48701 -
超分辨率
+关注
关注
0文章
26浏览量
9921
原文标题:WACV 2024 | SAFA:高效时空视频超分辨率的尺度自适应特征聚合
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
超分辨率图像重建方法研究
高分辨率合成孔径雷达图像的直线特征多尺度提取方法
怎样让labview 内的控件自适应屏幕分辨率
基于混合先验模型的超分辨率重建
基于正则化超分辨率的自适应阈值去噪方法
一种结合多阶导数数据的视频超分辨率重建算法
实时视频超分辨率重建
基于结构自相似性和形变块特征的单幅图像超分辨率算法






 工商网监
工商网监
评论