 用上这个工具包,大模型推理性能加速达40倍
用上这个工具包,大模型推理性能加速达40倍
作者:英特尔公司 沈海豪、罗屿、孟恒宇、董波、林俊
编者按:
只需不到9行代码,就能在CPU上实现出色的LLM推理性能。英特尔Extension for Transformer创新工具包中的LLM Runtime为诸多模型显著降低时延,且首个token和下一个token的推理速度分别提升多达40倍和2.68倍,还能满足更多场景应用需求。
英特尔Extension for Transformer是什么?
英特尔Extension for Transformers[1]是英特尔推出的一个创新工具包,可基于英特尔架构平台,尤其是第四代英特尔至强可扩展处理器(代号Sapphire Rapids[2],SPR)显著加速基于Transformer的大语言模型(Large Language Model,LLM)。其主要特性包括:
-
通过扩展Hugging Face transformers API[3]和利用英特尔Neural Compressor[4],为用户提供无缝的模型压缩体验;
-
提供采用低位量化内核(NeurIPS 2023:在CPU上实现高效LLM推理[5])的LLM推理运行时,支持Falcon、LLaMA、MPT、Llama2、 BLOOM、OPT、ChatGLM2、GPT-J-6B、Baichuan-13B-Base、Baichuan2-13B-Base、Qwen-7B、Qwen-14B和Dolly-v2-3B等常见的LLM[6];
-
先进的压缩感知运行时[7](NeurIPS 2022:在CPU上实现快速蒸馏和QuaLA-MiniLM:量化长度自适应MiniLM;NeurIPS 2021:一次剪枝,一劳永逸:对预训练语言模型进行稀疏/剪枝)。
本文将重点介绍其中的LLM推理运行时(简称为“LLM运行时”),以及如何利用基于Transformer的API在英特尔至强可扩展处理器上实现更高效的LLM推理和如何应对LLM在聊天场景中的应用难题。
LLM运行时(LLM Runtime)
英特尔Extension for Transformers提供的LLM Runtime[8]是一种轻量级但高效的LLM推理运行时,其灵感源于GGML[9],且与llama.cpp[10]兼容,具有如下特性:
-
内核已针对英特尔至强CPU内置的多种AI加速技术(如 AMX、VNNI)以及AVX512F和AVX2指令集进行了优化;
-
可提供更多量化选择,例如:不同的粒度(按通道或按组)、不同的组大小(如:32/128);
-
拥有更优的KV缓存访问以及内存分配策略;
-
具备张量并行化功能,可助力在多路系统中进行分布式推理。
LLM Runtime的简化架构图如下:
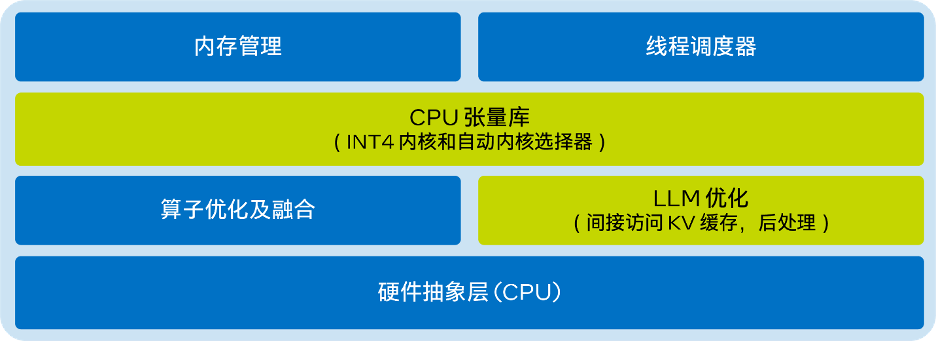
△图1.英特尔 Extension for Transformers的LLM Runtime简化架构图
使用基于Transformer的API,在CPU上实现LLM高效推理
只需不到9行代码,即可让您在CPU上实现更出色的LLM推理性能。用户可以轻松地启用与Transformer类似的API来进行量化和推理。只需将 ‘load_in_4bit’设为true,然后从HuggingFace URL或本地路径输入模型即可。下方提供了启用仅限权重的(weight-only)INT4量化的示例代码:
fromtransformersimportAutoTokenizer,TextStreamer
fromintel_extension_for_transformers.transformersimportAutoModelForCausalLM
model_name="Intel/neural-chat-7b-v3-1”
prompt="Onceuponatime,thereexistedalittlegirl,"
tokenizer=AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
inputs=tokenizer(prompt,return_tensors="pt").input_ids
streamer=TextStreamer(tokenizer)
model=AutoModelForCausalLM.from_pretrained(model_name,load_in_4bit=True)
outputs=model.generate(inputs,streamer=streamer,max_new_tokens=300)
△可左滑看完整版
默认设置为:将权重存储为4位,以8位进行计算。但也支持不同计算数据类型(dtype)和权重数据类型组合,用户可以按需修改设置。下方提供了如何使用这一功能的示例代码:
fromtransformersimportAutoTokenizer,TextStreamer
fromintel_extension_for_transformers.transformersimportAutoModelForCausalLM,WeightOnlyQuantConfig
model_name="Intel/neural-chat-7b-v3-1”
prompt="Onceuponatime,thereexistedalittlegirl,"
woq_config=WeightOnlyQuantConfig(compute_dtype="int8",weight_dtype="int4")
tokenizer=AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
inputs=tokenizer(prompt,return_tensors="pt").input_ids
streamer=TextStreamer(tokenizer)
model=AutoModelForCausalLM.from_pretrained(model_name,quantization_config=woq_config)
outputs=model.generate(inputs,streamer=streamer,max_new_tokens=300)
△可左滑看完整版
性能测试
经过持续努力,上述优化方案的INT4性能得到了显著提升。本文在搭载英特尔至强铂金8480+的系统上与llama.cpp进行了性能比较;系统配置详情如下:@3.8GHz,56核/路,启用超线程,启用睿频,总内存 256 GB (16 x 16 GB DDR5 4800 MT/s [4800 MT/s]),BIOS 3A14.TEL2P1,微代码0x2b0001b0,CentOS Stream 8。
当输入大小为32、输出大小为32、beam为1时的推理性能测试结果,详见下表:
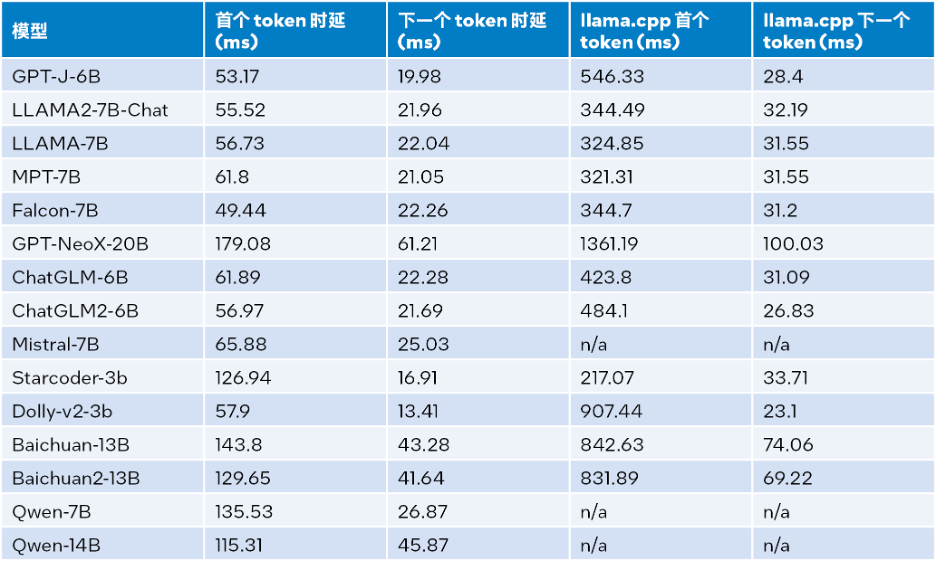
△表1.LLM Runtime与llama.cpp推理性能比较(输入大小=32,输出大小=32,beam=1)
输入大小为1024、输出大小为32、beam为1时的推理性能的测试结果,详见下表:
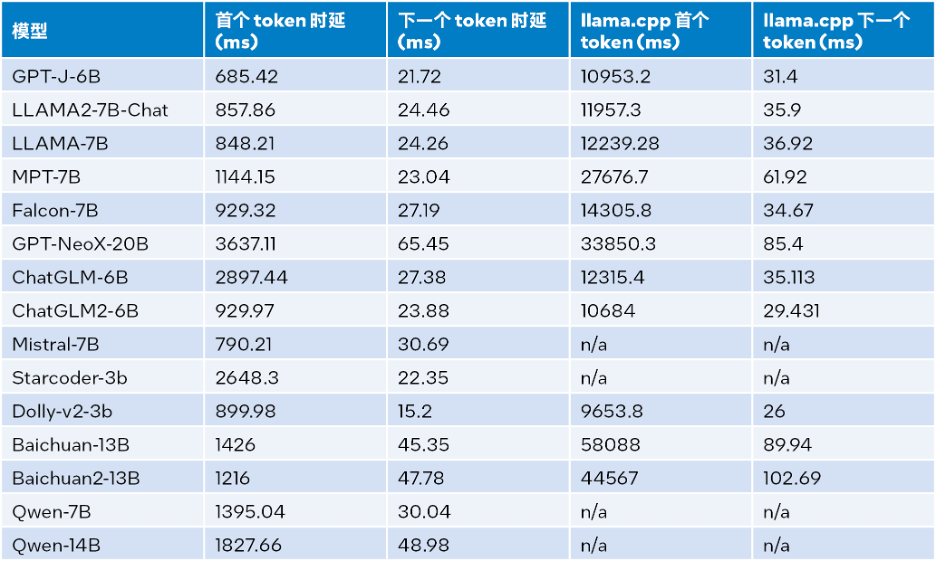
△表2.LLM Runtime与llama.cpp推理性能比较(输入大小=1024,输出大小=32,beam=1)
根据上表2可见:与同样运行在第四代英特尔至强可扩展处理器上的llama.cpp相比,无论是首个token还是下一个token,LLM Runtime都能显著降低时延,且首个token和下一个token的推理速度分别提升多达 40 倍[a](Baichuan-13B,输入为1024)和2.68倍[b](MPT-7B,输入为1024)。llama.cpp的测试采用的是默认代码库[10]。
而综合表1和表2的测试结果,可得:与同样运行在第四代英特尔至强可扩展处理器上的llama.cpp相比,LLM Runtime能显著提升诸多常见LLM的整体性能:在输入大小为1024时,实现3.58到21.5倍的提升;在输入大小为32时,实现1.76到3.43倍的提升[c]。
准确性测试
英特尔Extension for Transformers可利用英特尔Neural Compressor中的SignRound[11]、RTN和GPTQ[12]等量化方法,并使用lambada_openai、piqa、winogrande和hellaswag数据集验证了 INT4 推理准确性。下表是测试结果平均值与FP32准确性的比较。
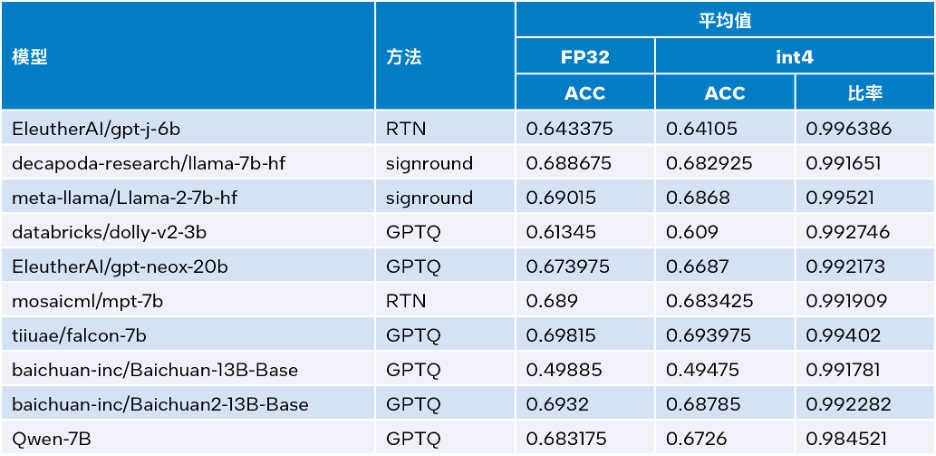
△表3.INT4与FP32准确性对比
从上表3可以看出,多个模型基于LLM Runtime进行的INT4推理准确性损失微小,几乎可以忽略不记。我们验证了很多模型,但由于篇幅限制此处仅罗列了部分内容。如您欲了解更多信息或细节,请访问此链接:https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176。
更先进的功能:满足LLM更多场景应用需求
同时,LLM Runtime[8]还具备双路CPU的张量并行化功能,是较早具备此类功能的产品之一。未来,还会进一步支持双节点。
然而,LLM Runtime的优势不仅在于其更出色的性能和准确性,我们也投入了大量的精力来增强其在聊天应用场景中的功能,并且解决了LLM 在聊天场景中可能会遇到的以下应用难题:
-
对话不仅关乎LLM推理,对话历史也很有用。
-
输出长度有限:LLM模型预训练主要基于有限的序列长度。因此,当序列长度超出预训练时使用的注意力窗口大小时,其准确性便会降低。
-
效率低下:在解码阶段,基于Transformer的LLM会存储所有先前生成的token的键值状态(KV),从而导致内存使用过度,解码时延增加。
关于第一个问题,LLM Runtime的对话功能通过纳入更多对话历史数据以及生成更多输出加以解决,而llama.cpp目前尚未能很好地应对这一问题。
关于第二和第三个问题,我们将流式LLM(Steaming LLM)集成到英特尔Extension for Transformers中,从而能显著优化内存使用并降低推理时延。
Streaming LLM
与传统KV缓存算法不同,我们的方法结合了注意力汇聚(Attention Sink)(4个初始token)以提升注意力计算的稳定性,并借助滚动KV缓存保留最新的token,这对语言建模至关重要。该设计具有强大的灵活性,可无缝集成到能够利用旋转位置编码RoPE和相对位置编码ALiBi的自回归语言模型中。
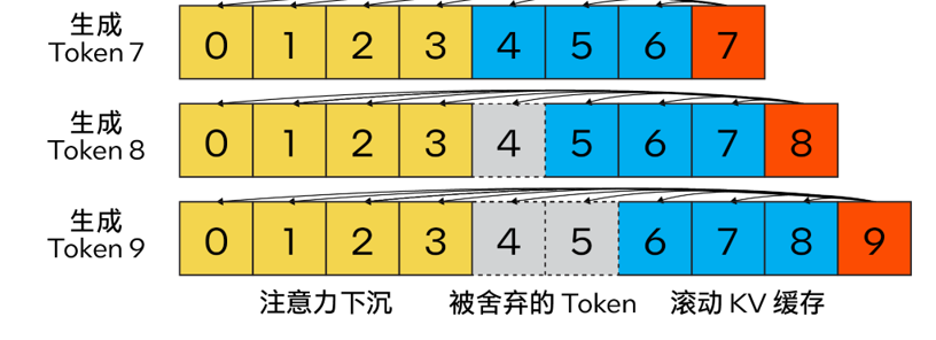
△图2.Steaming LLM的KV缓存(图片来源:通过注意力下沉实现高效流式语言模型[13])
此外,与llama.cpp不同,本优化方案还引入了“n_keep”和“n_discard”等参数来增强Streaming LLM策略。用户可使用前者来指定要在KV缓存中保留的token数量,并使用后者来确定在已生成的token中要舍弃的数量。为了更好地平衡性能和准确性,系统默认在KV缓存中舍弃一半的最新token。
同时,为进一步提高性能,我们还将Streaming LLM添加到了MHA融合模式中。如果模型是采用旋转位置编码(RoPE)来实现位置嵌入,那么只需针对现有的K-Cache应用“移位运算(shift operation)”,即可避免对先前生成的、未被舍弃的token进行重复计算。这一方法不仅充分利用了长文本生成时的完整上下文大小,还能在KV缓存上下文完全被填满前不产生额外开销。
“shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θifor i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θifori ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可通过以下代码启动Streaming LLM:
fromtransformersimportAutoTokenizer,TextStreamer
fromintel_extension_for_transformers.transformersimportAutoModelForCausalLM,WeightOnlyQuantConfig
model_name="Intel/neural-chat-7b-v1-1"#HuggingFacemodel_idorlocalmodel
woq_config=WeightOnlyQuantConfig(compute_dtype="int8",weight_dtype="int4")
prompt="Onceuponatime,alittlegirl"
tokenizer=AutoTokenizer.from_pretrained(model_name,trust_remote_code=True)
inputs=tokenizer(prompt,return_tensors="pt").input_ids
streamer=TextStreamer(tokenizer)
model=AutoModelForCausalLM.from_pretrained(model_name,quantization_config=woq_config,trust_remote_code=True)
#Recommendn_keep=4todoattentionsinks(fourinitialtokens)andn_discard=-1todrophalfrencetlytokenswhenmeetlengththreshold
outputs=model.generate(inputs,streamer=streamer,max_new_tokens=300,ctx_size=100,n_keep=4,n_discard=-1)△可左滑看完整版
结论与展望
本文基于上述实践经验,提供了一个在英特尔至强可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔Extension for Transformers[1],并在英特尔平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
参考链接:
[1]英特尔Extension for Transformers
https://github.com/intel/intel-extension-for-transformers
[2]Sapphire Rapids
https://www.intel.cn/content/www/cn/zh/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html
[3]Hugging Face transformers
https://github.com/huggingface/transformers
[4]英特尔Neural Compressor
https://github.com/intel/neural-compressor
[5]NeurIPS 2023:在CPU上实现高效LLM推理
https://arxiv.org/pdf/2311.00502.pdf
[6]常见LLM:
Falcon:https://falconllm.tii.ae/
LLaMA:https://ai.meta.com/blog/large-language-model-llama-meta-ai/
MPT:https://www.mosaicml.com/blog/mpt-7b
Llama2:https://ai.meta.com/llama/
BLOOM:https://huggingface.co/bigscience/bloom
OPT:https://arxiv.org/abs/2205.01068
ChatGLM2:https://github.com/THUDM/ChatGLM2-6B
GPT-J-6B:https://huggingface.co/EleutherAI/gpt-j-6b
Baichuan-13B-Base:https://huggingface.co/baichuan-inc/Baichuan-13B-Base
Baichuan2-13B-Base:https://huggingface.co/baichuan-inc/Baichuan2-13B-Base
Qwen-7B:https://huggingface.co/Qwen/Qwen-7B
Qwen-14B:https://huggingface.co/Qwen/Qwen-14B
Dolly-v2-3B:https://huggingface.co/databricks/dolly-v2-3b
[7]先进的压缩感知运行时
NeurIPS 2022:在 CPU 上实现快速蒸馏
https://arxiv.org/abs/2211.07715
QuaLA-MiniLM:量化长度自适应 MiniLM
https://arxiv.org/abs/2210.17114
NeurIPS 2021:一次剪枝,一劳永逸:对预训练语言模型进行稀疏/剪枝
https://arxiv.org/abs/2111.05754
[8]LLM Runtime
https://github.com/intel/intel-extension-for-transformers/tree/main/intel_extension_for_transformers/llm/runtime/graph
[9]GGML
https://github.com/ggerganov/ggml
[10]llama.cpp
https://github.com/ggerganov/llama.cpp
[11]SignRound
https://arxiv.org/abs/2309.05516
[12]GPTQ
https://arxiv.org/abs/2210.17323
[13]通过注意力下沉实现高效流式语言模型
http://arxiv.org/abs/2309.17453
本文转载自:量子位-
英特尔
+关注
关注
61文章
10043浏览量
172595 -
cpu
+关注
关注
68文章
10929浏览量
213456
原文标题:用上这个工具包,大模型推理性能加速达40倍
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
云计算开发工具包的功能
C#集成OpenVINO™:简化AI模型部署


中国电提出大模型推理加速新范式Falcon

基于EasyGo Vs工具包和Nl veristand软件进行的永磁同步电机实时仿真
FPGA和ASIC在大模型推理加速中的应用

澎峰科技高性能大模型推理引擎PerfXLM解析


开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能

魔搭社区借助NVIDIA TensorRT-LLM提升LLM推理效率
LLM大模型推理加速的关键技术
自然语言处理应用LLM推理优化综述

瑞萨电子宣布推出一款面向高性能机器人应用的新产品—RZ/V2H






 工商网监
工商网监
评论