 爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
数以万亿的网页通过链接构成了互联网,爬虫的工作就是从这数以万亿的网页中爬取需要的网页,从网页中采集内容并形成结构化的数据。
1、 爬虫的基本工作原理
爬虫是就是一个程序,这个程序的任务就是从给出的一组种子URL开始爬取网页,并通过网页间的链接爬取更多的网页,根据爬虫任务的需求,最终可能会爬取整个互联网的网页。
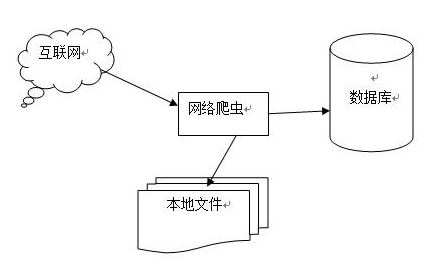
爬虫的工作机制如下图示:

URL就是网页的网址,种子URL就是爬虫要首先爬取的网页网址,确定你的爬虫程序首先从哪些网页开始爬取。一组种子URL是指一个或多个的网页地址。
爬虫程序开始工作后,种子URL会先加入到待爬取网页的队列中,爬虫程序从队列按照先进先出的原则获取网页URL,爬虫程序开始爬取网页,爬虫会下载整个网页内容,然后提取网页内容,分析出网页内容包含的URL,并把新的URL加入到队列。
当队列为空时,爬虫停止工作,否则爬虫会继续从队列获取网页URL,爬取下一个网页。
Python爬虫基础代码如下:
# 导入队列模块
import queue as q
# 定义种子URL
seed_url = ["https://news.baidu.com/","https://money.163.com/"]
# 定义URL队列
url_queue = q.Queue()
# 定义添加种子到队列的函数
def put_seed():
for s in seed_url:
url_queue.put(s)
# 定义网址添加到队列的函数
def put_url(url):
url_queue.put(url)
# 定义判断队列是否不为空函数
def is_queue_noempty():
if url_queue.empty():
return False
return True
# 定义从队列获取URL的函数
def get_url():
return url_queue.get()
# 定义网页下载函数
def download_url(url):
text = "";
# 此处为下载代码
pass
return text
# 定义网页解析函数
def analysis(text):
# 此处为网页内容解析代码
pass
# 网页内容处理与存储代码
process()
# 添加新URL到队列
pass
# 定义网页内容处理与存储函数
def process(objec=None):
# 此处为网页内容处理与存储代码
pass
if __name__ == "__main__":
print("------启动爬虫------")
# 种子URL加入队列
put_seed()
# 循环爬取队列的URL
while is_queue_noempty():
# 从队列获取URL
url = get_url()
# 下载URL
text = download_url(url)
# 解析网页内容
analysis(text)
# 队列为空,爬虫停止
print("------爬虫停止------")
用Scrapy实现一个简单的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。应用框架提供了很多工具和程序,让我们可以轻松开发商业化爬虫,商业化爬虫是指实用的爬虫程序。
下面用Scrapy实现一个简单的爬虫。
(1)创建爬虫项目
使用Scrapy实现爬虫,需要创建一个新的Scrapy项目。创建一个Scrapy项目非常简单,使用Scrapy命令行工具就可以创建Scrapy项目,Scrapy命令行工具可以运行在Windows的命令行窗口或Linux的终端窗口。
运行命令行工具的语法如下:
scrapy < command > [options] [args]
其中,scrapy是工具名称,command是命令,options是命令的选项,args是命令需要的参数,options和args是可选的,依据命令的要求传入。
下面介绍三个主要的命令,创建项目命令、爬虫创建命令和运行项目爬虫命令,因为这三个命令是马上要用到的。其它命令会专门安排一个小节介绍。
创建项目命令
创建项目的语法如下:
scrapy startproject < project_name >
其中startproject是创建项目的命令名称,project_name是项目名称。例如:要创建一个爬取百度新闻网站数据的爬虫,项目名称可以是newsbaidu。
创建newsbaidu项目的命令如下:
scrapy startproject newsbaidu
爬虫创建命令
爬虫创建命令用于在项目中创建一个爬虫,爬虫的英文名称spider。这是创建spider的一种快捷方法,该命令可以使用提前定义好的模板来生成spider,也可以自己创建spider的源码文件。
爬虫创建命令的语法如下:
scrapy genspider [-t template] < name > < domain >
其中genspider是爬虫创建命令的命令名称,template用来设置爬虫源代码的模板名称,这是一个可选项,采用scrapy的默认爬虫模板即可,name是爬虫名称,domain是该爬虫要爬取的网站域名。
运行项目爬虫命令
一个scrapy项目可以运行多个爬虫,运行项目爬虫命令的语法如下:
scrapy crawl < spider >
其中crawl是运行项目爬虫命令的名称,spider是爬虫名称,也就是使用爬虫创建命令创建的爬虫名称。
创建爬虫项目及爬虫
在Windows命令行窗口,将存储项目文件的目录设置为当前目录,使用scrapy工具的startproject命令创建爬虫项目newsbaidu,项目名称也可以是其它名称,在Windows命令行窗口输入下面的命令:
scrapy startproject newsbaidu
在项目中创建爬虫spider_newsbaidu,设置项目所在目录为当前工作目录,在Windows命令行窗口输入下面的命令:
scrapy genspider spider_newsbaidu https://news.baidu.com
(2)定义要抓取的数据
开发爬虫的目的是要爬取网站数据,并提取出结构化数据。要做的第一步工作就是根据要爬取的网站内容构成,定义一个结构化数据,存储从网站提取的数据。
在scrapy中,通过scrapy Items来完成结构化数据的定义。在scrapy创建的爬虫项目中,items.py文件就是一个Items,在Items可以定义要爬取的数据。
例如:要抓取百度新闻网站(news.baidu.com)的热点新闻条目,并获取新闻条目的文章标题、文章链接数据。
可以在项目的items.py文件中定义下面的数据结构:
# 导入scrapy库
import scrapy
#自定义NewsbaiduItem用于存储爬虫所抓取的字段内容
class NewsbaiduItem(scrapy.Item):
# 定义要爬取的数据:
# 文章标题
news_title = scrapy.Field()
# 文章链接
news_link = scrapy.Field()
NewsbaiduItem类继承scrapy.Item类,它是一个Scrapy Items,它定义了两个数据字段,分别是news_title和news_link。
类似这样的Scrapy Items可以定义多个,以适应爬取不同的网站数据。
(3)编写一个爬虫程序
定义了存储爬取数据的Scrapy Items,就可以开始编写爬虫程序了。首先要确定百度新闻网站的起始页,也就是百度新闻网站的种子URL。
爬虫的种子URL:www.news.baidu.com
种子URL是百度新闻网站的首页,需要查看百度新闻网站的首页源码,确定提取新闻条目的规则,编写XPath表达式。
如何查看网页源码?
使用浏览器打开百度新闻网站的首页,单击鼠标右键,在弹出的菜单中选择“查看网页源代码”命令,不同浏览器可能有不同的命令名称。
观察网页源代码,找出数据提取规则
观察首页源代码发现,新闻条目的源代码一般都通过下面的超链接标签实现:
< a href="https://3w.huanqiu.com/a/9eda3d/3zT0a2ZsWaC?agt=8"
mon="ct=1&a=2&c=top&pn=15"
target="_blank" >
英国将法国荷兰列入隔离清单,法国:将采取“对等措施”
< /a >
其中,“a”是超链接标签,也称为a标签。“href”是超链接的目标属性,“mon”应是百度新闻网站自定义的一个超链接属性,每个新闻条目的a标签都带有mon属性,通过a标签的mon属性可以和网页的其它a标签区分开。
提取新闻条目的XPath表达式如下:
//a[contains(@mon,'ct=1')]
a标签的mon属性值的“&”是转义符,表示这是一个“&”字符,在XPath表达式中只有判断mon属性值包含字符串“ct=1”就可以提取网页所有的新闻条目。
编写爬虫代码
项目spiders目录下的spider_newsbaidu.py是scrapy创建的一个爬虫模板文件,可以在此基础上修改代码。
模板文件代码如下:
import scrapy
class SpiderNewsbaiduSpider(scrapy.Spider):
name = 'spider_newsbaidu'
allowed_domains = ['https://news.baidu.com']
start_urls = ['https://news.baidu.com/']
def parse(self, response):
pass
SpiderNewsbaiduSpider类继承scrapy.Spider类。属性name是爬虫名称,该名称可用于运行项目爬虫的crawl命令;属性allowed_domains是要爬取的网站域名,start_urls是种子URL,start_urls是一个列表对象,可以定义多个种子URL。
在SpiderNewsbaiduSpider类可以编写爬取网站的代码,从下载的网页代码中提取超链接,加入爬取队列,以及从网页的内容中提取结构化数据。
类方法parse(response)用于解析网页内容,提取网页的超链接和结构化数据。该方法是一个回调函数,会被Request对象调用,Request对象是向网页发出请求访问的对象,该对象会返回一个response对象,并调用parse(response)方法对response对象进行处理。
传入的参数是response对象,response对象封装了爬虫从网站爬取的内容,通过response对象可以获取爬取的网页内容。
修改后的爬虫代码如下:
import scrapy
# 导入scrapy选择器
from scrapy.selector import Selector
# 导入NewsbaiduItem
from newsbaidu.items import NewsbaiduItem
class SpiderNewsbaiduSpider(scrapy.Spider):
name = 'spider_newsbaidu'
allowed_domains = ['https://news.baidu.com']
start_urls = ['https://news.baidu.com/']
def parse(self, response):
# 获取爬取下来的网页内容
html = response.text
# 使用xpath表达式搜寻指定的a标签节点,节点以列表方式返回
item_nodes = response.xpath("//a[contains(@mon,'ct=1')]").extract()
# 遍历节点
for item_node in item_nodes:
# 使用xpath表达式获取节点的href属性值
a_href = Selector(text=str(item_node)).xpath('//@href').extract()
# 使用xpath表达式获取节点的文本内容
a_text = Selector(text=str(item_node)).xpath('//text()').extract()
# 实例化NewsbaiduItem对象
item = NewsbaiduItem()
item["news_title"] = a_text
item["news_link"] = a_href
# 使用yield语句返回item给parse的调用者
yield item
主要修改了parse()方法,在parse()方法内,通过response对象的text属性获取scrapy下载的网页内容,通过response对象的xpath()方法执行XPath表达式选取网页节点或节点文本,将提取的网页数据存储到NewsbaiduItem对象。
parse()方法使用了yield语句,因此parse()方法是一个生成器函数,当parse()方法的调用者需要一个迭代对象时,parse()方法会返回这个迭代对象。
parse()方法返回的迭代对象主要是两类:一类是scrapy Items类型的实例对象;一类是scrapy Request类型的实例对象,Request对象封装了请求的URL。
(4)运行爬虫
当前创建的SpiderNewsbaiduSpider爬虫还是非常简单的,在爬虫内并没有处理网页内新闻条目外的超链接,因此爬虫处理完该网页内容后,就会自行结束爬取过程。随着对scrapy框架的深入了解,会逐渐完善SpiderNewsbaiduSpider爬虫。
现在可以运行爬虫了,爬取的数据暂时存储到json文件,在后面的课程会存储到数据库。
在Windows命令行窗口,将当前目录切换到项目的根目录,输入下面的命令:
scrapy crawl spider_newsbaidu -o items.json
其中spider_newsbaidu是爬虫名称,选项-o是将Items输出到文件,选项-o后面的参数是文件名称。
执行运行爬虫的命令后,爬虫爬取的数据会存储到项目根目录下的items.json文件,可以使用记事本查看items.json文件内容。
若items.json文件的中文内容显示为文字编码,需要在setting.py文件中添加FEED_EXPORT_ENCODING配置项,该配置项用于设置输出文件的字符编码方式,scrapy输出文件的默认字符编码是ASCII。
通过在setting.py文件添加下面的配置项将scrapy输出文件字符编码设置为utf-8。
FEED_EXPORT_ENCODING = 'utf-8'
** Scrapy爬虫的工作机制**
基于当前学到的scrapy知识,整理出scrapy的工作机制,在后面的课程会逐步完善scrapy的工作机制。

Scrapy引擎是Scrapy框架的核心,它可以启动多个爬虫,并管理爬虫的运行。
它会将爬虫提取的Request对象放入到Scrapy调度器(可以把Scrapy调度器看作是URL队列管理),同时它会调用Items数据处理器处理爬虫提取的Items数据。
Scrapy引擎会维持爬虫的运行,维持爬虫运行的机制就是不断从URL队列管理器获取Request对象,调用下载管理器向Request对象指定的URL发出Request请求,下载URL所在服务器返回的内容,并返回Responses对象。
Request对象会回调在Request对象设置的回调函数,并传入Responses对象。若Request对象没有设置回调函数,将会调用Spider的parse()方法。
-
互联网
+关注
关注
54文章
11158浏览量
103341 -
代码
+关注
关注
30文章
4789浏览量
68642 -
python
+关注
关注
56文章
4797浏览量
84715 -
爬虫
+关注
关注
0文章
82浏览量
6889
发布评论请先 登录
相关推荐
Python数据爬虫学习内容
Python爬虫与Web开发库盘点
Python爬虫初学者需要准备什么?
什么语言适合写爬虫
什么语言适合写爬虫
Python爬虫速成指南让你快速的学会写一个最简单的爬虫
爬虫是如何实现数据的获取爬虫程序如何实现






 工商网监
工商网监
评论