 如何利用缓存让CPU更有效率地执行代码?
如何利用缓存让CPU更有效率地执行代码?
数组遍历方式
我们先来看一个很经典的例子(例子是C语言写的,其他语言实现也都是差不多的):
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
int main()
{
clock_t begin, end;
double cost;
begin = clock();
int count = 10000;
int* array = (int*)malloc(sizeof(int) * count * count);//2维数组
//代码1 按行遍历
//for (int i = 0;i < count;i++) {
// for (int j = 0; j < count; j++) {
// array[i * count + j] = 0;
// }
//}
//代码2 按列遍历
for (int i = 0;i < count;i++) {
for (int j = 0; j < count; j++) {
array[j * count + i] = 0;
}
}
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
运行结果:
#代码1
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.126000
#代码2
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.301000
CLOCKS_PER_SEC=1000,表示当前电脑1秒是被分成了1000个时间片,也就是说时间测量最小单位为1ms
所以上述代码1,在笔者的电脑运行耗时大约0.126ms;而代码2,运行耗时却高达0.301ms
这2段代码块 基本一致,唯独遍历方式不同 ,代码1是按行遍历,而代码2是按列遍历
无非是遍历方式不一样,但为啥运行效率会差这么多呢?
我们知道在内存中,数组一般是按行存储的,如array[0][0],array[0][1],...,array[2][0],array[2][1],...
上述代码块1是按行遍历,而代码块2是按列遍历,按行遍历时可以由指向数组第一个数的指针一直往下走,就可以遍历完整个数组,而按列遍历则要获得指向每一列的第一行的元素的指针,然后每次将指针指下一行,但是指针的寻址很快,所以在内存中这2种数组遍历方式的效率,不会有明显的区别
那为啥运行效率会差这么多呢
其实这个背后其实是CPU Cache起作用!笔者吐血画了张图帮助大家更直观地了解原理
:
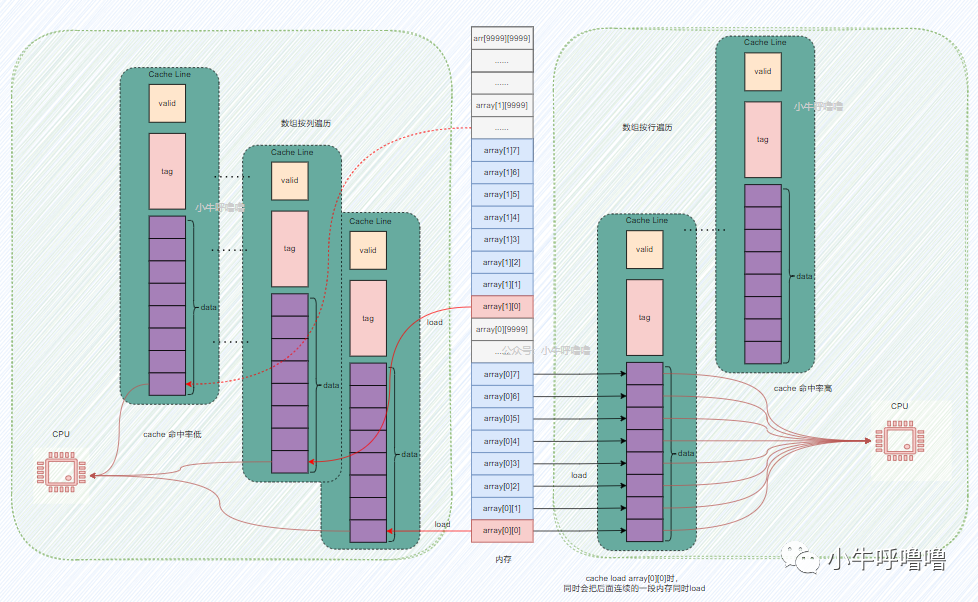
上图,左边是数组按列遍历的情况,右边是按行遍历的情况,笔者把他们合到了一张图上,这样对比度更强
我们知道CPU Cahce利用了空间局部性的原理来提高性能,如果一个内存的位置被引用,那么将来它附近的位置也会被引用
也就是说当数组按行遍历时,当访问第一个数组元素array[0][0],CPU会在缓存中,寻找这个内存地址对应的Cache Line,这时候肯定找不到啊,发生缓存缺失cache miss,会触发CPU把array[0][0]地址处以及后面连续的一段内存都load到Cache Line中,这个时候访问数组中第2~8个元素,会直接在CPU Cache中找到对应的数据,即缓存命中cache hit,这样就不需要访问内存了;直到访问第9个数组元素,再次发生cache miss,周而复始直到程序结束
CPU每次能加载多少内存到Cache Line中,主要取决于Cache Line的容量,上图只是举个例子,一般主流的 CPU 的 Cache Line 大小是64 Byte,过大或者过小都会影响性能
我们可以发现按行遍历时, 访问数组元素的顺序,是与内存中数组元素存放的顺序一致 ,每次发生cache miss,都加载一堆内存区域的数据,数组后续元素都能在缓存中找到对应的数据,这样缓存命中率较高,从而减少缓存缺失导致的开销
而按列遍历时, 访问数组元素的顺序,是和内存中数组元素存放的顺序不一致,跳跃式访问 ,每次发生cache miss,哪怕都加载一堆内存区域的数据,像上图一样每次缓存只能命中1次,会导致频繁发生cache miss,因此缓存命中率特别低
而 缓存读写速度要远远快于内存的读写速度 ,这里笔者再次拿出经典的储存器金字塔图,在冯诺依曼架构下,计算机存储器是分层次的,存储器的层次结构如下图所示,是一个金字塔形状的东西。从上到下依次是寄存器、缓存、主存(内存)、硬盘等等

离CPU越近的存储器,访问速度越来越快,容量越来越小,每字节的成本也越来越昂贵
比如一个主频为3.0GHZ的CPU,寄存器的速度最快,可以在1个时钟周期内访问,一个时钟周期(CPU中基本时间单位)大约是0.3纳秒,内存访问大约需要120纳秒,固态硬盘访问大约需要50-150微秒,机械硬盘访问大约需要1-10毫秒,最后网络访问最慢,得几十毫秒左右。
这个大家可能对时间不怎么敏感,那如果我们把 一个时钟周期如果按1秒算的话,那寄存器访问大约是1s,内存访问大约就是6分钟 ,固态硬盘大约是2-6天 ,传统硬盘大约是1-12个月,网络访问就得几年了 !我们可以发现CPU的速度和内存等存储器的速度,完全不是一个量级上的。
所以尽可能地让代码只访问缓存,避免频繁访问内存,能极大地提高代码性能,所以数组按行遍历要远远快于是按列遍历,当然前提条件数组在内存中是按行储存的
循环的步长
我们这里还是举一个经典例子:
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
int main()
{
clock_t begin, end;
double cost;
begin = clock();
const int LEN = 64 * 1024 * 1024;
int* arr = (int*)malloc(sizeof(int) * LEN);
//代码1
//for (int i = 0; i < LEN; i += 2) arr[i] *= 3;
//代码2
for (int i = 0; i < LEN; i += 8) arr[i] *= 3;
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
代码1这个循环功能是将数组的每2个值乘3,代码2循环则将每8个值乘3,也就是代码1应该比代码少4倍的计算量,那有人可能会认为,时间也会节约4分之三
但真的是这样吗?
我们直接来看运行结果:
#代码1
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.068000
#代码2
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.058000
我们发现在笔者的电脑跑下来,时间分别是:0.068ms,0.058ms;它们的耗时其实差不多,远远没有4倍差距那么大
其实 循环执行时间长短由数组的内存访问次数决定的,而非整型数的乘法运算次数 ;因为这个时候缓存已经起作用了,当缓存丢失时,CPU这个时候会将一段内存加载到缓存中,以Cache Line为单位,一般是64Byte
而上述代码中无论步长是2还是8,都是在一个Cache Line中,CPU访问同一个缓存行内其它值的开销是很小的;另一方面这两个循环的主存访问次数其实是一样的。所以这2个循环耗时相差不大
但这并不意味这步长无论多大都是这样的,是有一个临界点的;在C语言中,一个整型=4个字节,所以16个整型数占用64字节(Byte)=一个Cache Line(64Byte)
因此当Cache Line大小为64Byte时,步长在1~16范围内,循环运行时间相差不大。但从16往后,每次步长加倍,运行时间减半

上图来源于Gallery of Processor Cache Effects
伪共享和缓存行对齐
我们再来看一个多线程的例子:
#include < stdio.h >
#include < stdlib.h >
#include < time.h >
#include < pthread.h >
struct S {
long long a;
//long long noop[8];
long long b;
} s;
void* threadA(void* p)
{
for (int i = 0; i < 100000000; i++) {
s.a++;
}
return NULL;
}
void* threadB(void* p)
{
for (int i = 0; i < 100000000; i++) {
s.b++;
}
return NULL;
}
int main()
{
clock_t begin, end;
double cost;
begin = clock();
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, threadA, NULL);
pthread_create(&thread2, NULL, threadB, NULL);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
end = clock();
cost = (double)(end - begin) / CLOCKS_PER_SEC;
printf("constant CLOCKS_PER_SEC is: %ld, time cost is: %lf", CLOCKS_PER_SEC, cost);
return 0;
}
运行结果:
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.194000
上述例子,表示2个线程同时修改两个相邻的变量(在一个结构体内),而在C语言中,long类型占8个字节,所以这2个变量a、b都在同一个Cache Line中;另外在如今多核CPU的时代,2个线程可能由不同核心分别执行,那么缓存一致性的问题不可避免。
我们知道, 缓存的加载更新不是以字节为单位,而是以Cache Line为单位 ,在基于mesi协议下,当2个线程同时修改两个相邻的变量,整个Cache Line都会被整个刷新

这会出现一个伪共享现象:当线程A读取变量a,并修改a,线程A在未写回缓存之前,同时另一个线程B读取了b,读取这个b所在的缓存,由于缓存一致性协议,其实该缓存行处于无效状态,需要重新加载缓存。这就是 缓存伪共享false-sharing 。使用缓存的本意是为了提高性能,但是现在场景下,多个线程在不同的CPU核心上高频反复访问这种CacheLin伪共享的变量,会严重牺牲性能
所以我们写代码的时候需要注意伪共享问题,那如何解决呢?
其实也很简单,我们只要保证多线程需要同时操作的变量不在同一个Cache Line中即可,我们这里Cache Line的大小为64字节,最简单的方法我们只需在这个例子的结构体中,再加一行代码
struct S {
long long a;
long long noop[8];
long long b;
} s;
long long noop[8];占用8*8=64字节,也就是一个Cache Line的大小,这样就能保证变量a、b不在同一个Cache Line中,这样就不会再出现伪共享现象
最后我们校验一下,从最终执行结果来看,时间确实节约了不少:
constant CLOCKS_PER_SEC is: 1000, time cost is: 0.148000
当然还有其他优化方式,比如编译器直接优化,如果我们对伪共享现象 反向思考 ,当有多个小变量并不涉及到很复杂的读写依赖,那么我们应该尽可能将这些小变量放在同一个缓存行Cache Line上,这个也叫做缓存行对齐
因为这些小变量可能散落在内存的各个地方,降低缓存命中率,就得多次加载到缓存,那如果能一起加载到同一个缓存行上,缓存命中率就能大大提高,从而提升代码的性能
在C语言中,为了避免伪共享,编译器会自动将结构体,字节补全以及 内存对齐 (内存对齐就不展开讲了,感兴趣地自行去了解一下);另外对齐的大小最好是缓存行的长度,这样缓存只要load一次即可
#define CACHE_LINE 64 //缓存行长度
struct S1 {int a, b, c, d;} __attribute__ ((aligned(CACHE_LINE)));//__align用于显式对齐,这种方式使得结构体字节对齐的大小为缓存行的大小
最后再补充一个,Linux提供一个函数,sched_setaffinity可以在多核CPU系统中,设置线程的CPU亲和力,使线程绑定在某一个或几个CPU核心上运行,避免在多个核心之间来回切换,因为L3 Cache 是多核心之间共享的,但L1 和 L2 Cache都是每个核心独有的,如果线程都在同一个核心上执行,能够减少保证缓存一致性的操作,从而减少访问内存的频率,提升程序性能。
-
寄存器
+关注
关注
31文章
5342浏览量
120323 -
存储器
+关注
关注
38文章
7490浏览量
163818 -
C语言
+关注
关注
180文章
7604浏览量
136787 -
Cache
+关注
关注
0文章
129浏览量
28342 -
缓存器
+关注
关注
0文章
63浏览量
11659
发布评论请先 登录
相关推荐
重大进展!辉瑞新冠疫苗有效率达到90% 明年产能13亿
如何才能有效率的学习单片机
画PCB封装的方法哪个更有效率
请问CH579有效率比较高的量产烧录工具吗?
如何实现更有效率的产线各工业设备数据采集?
六个助你创建运行更有效率Python应用的窍门

CPU缓存是什么意思_CPU缓存有什么作用

缓存如何工作,如何设计CPU缓存
如何有效整理和利用现有的空间,建造更有效率的停车空间?
CPU缓存的作用及原理有哪些
工业设备的数据如何更有效率的采集?





 工商网监
工商网监
评论