 低成本扩大输入分辨率!华科大提出Monkey:新的多模态大模型
低成本扩大输入分辨率!华科大提出Monkey:新的多模态大模型
低成本扩大输入分辨率:探秘98亿参数多模态大模型--Monkey眼中的世界
【导读】11月,华中科技大学团队发布了新的多模态大模型——Monkey,通过专注于大分辨率,使得Monkey能够处理分辨率高达1344×896的图像,并加入了有着详细描述的高质量图文数据进行训练,帮助Monkey炼就洞察图像细节的火眼金睛,取得了与Caption和QA任务相关的16个数据集的SOTA,甚至与GPT4V相比,在密集文本问答任务上也有着亮眼的表现。
论文链接:https://arxiv.org/abs/2311.06607
代码地址:https://github.com/Yuliang-Liu/Monkey
官方demo效果展示:
Monkey在密集文本的问答任务上取得了很不错的效果,可以根据问题的要求进行推理,能够适配中文问答

在文本较少的场景中Monkey也展现了不俗的问答能力,自身拥有丰富的知识库,可以根据问题进行外推,从而回答出正确的答案
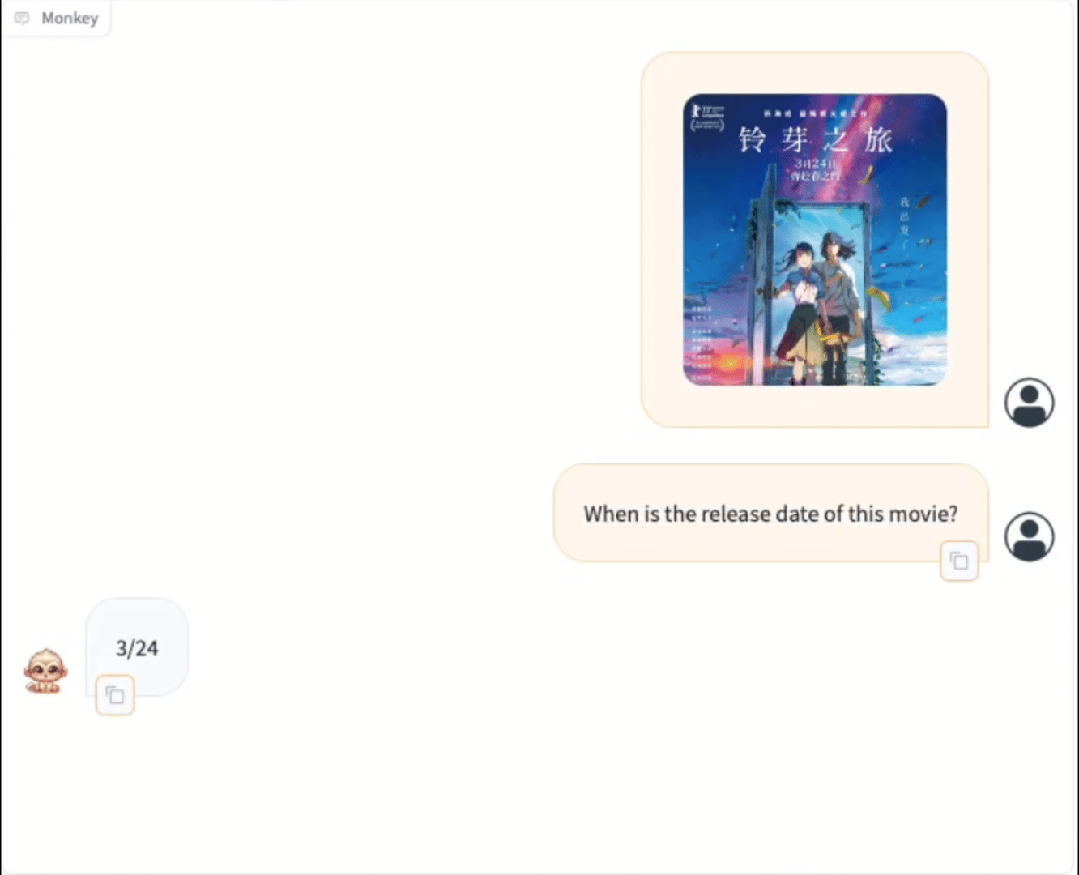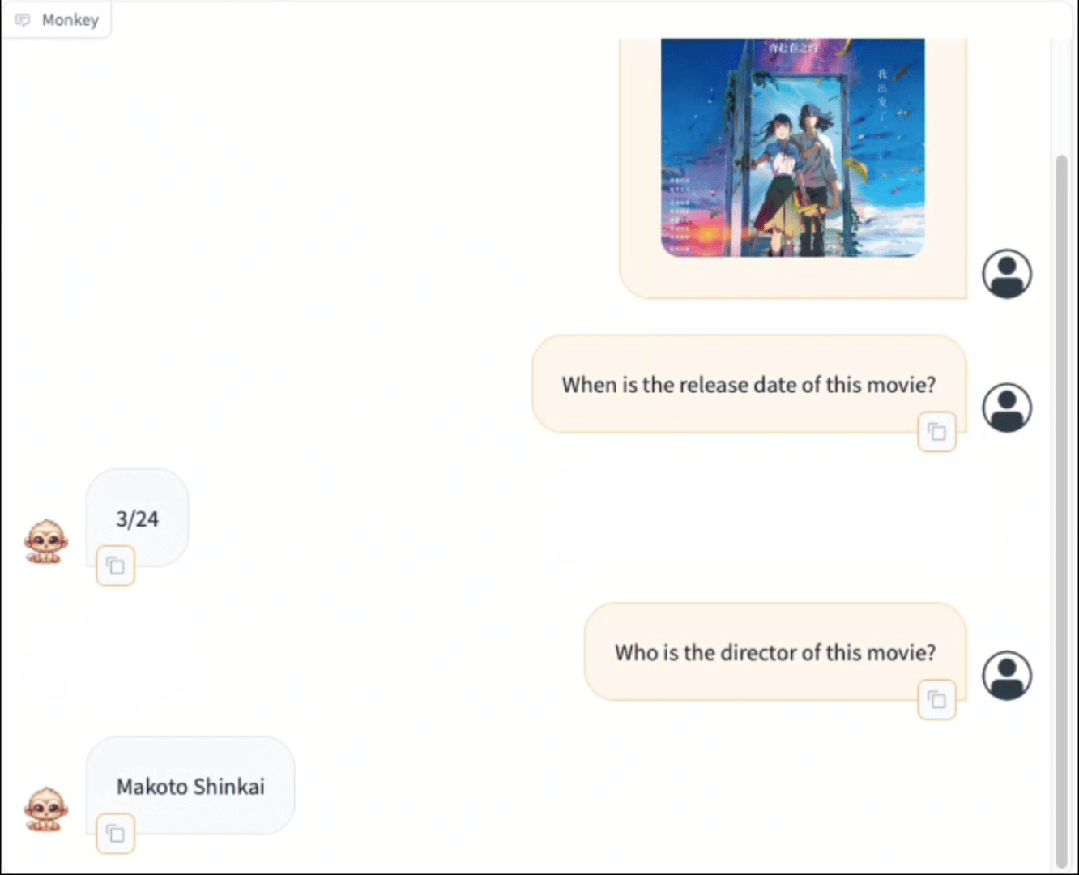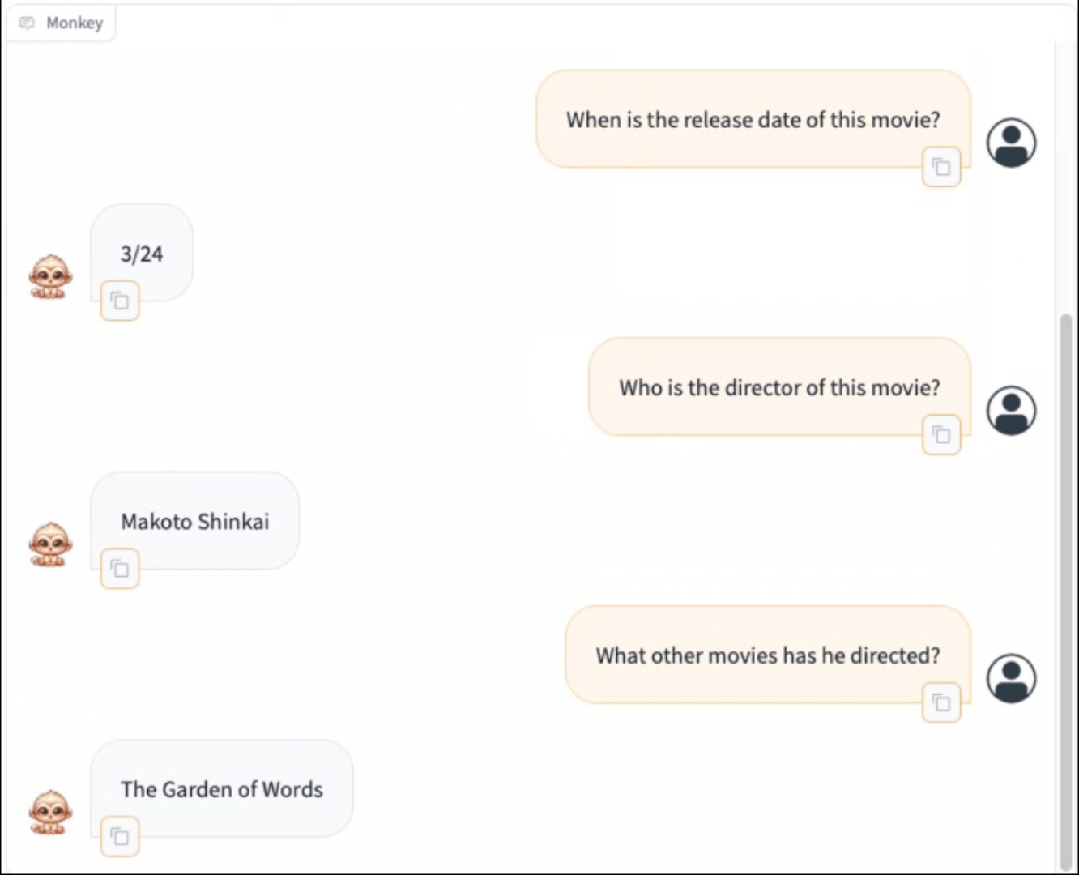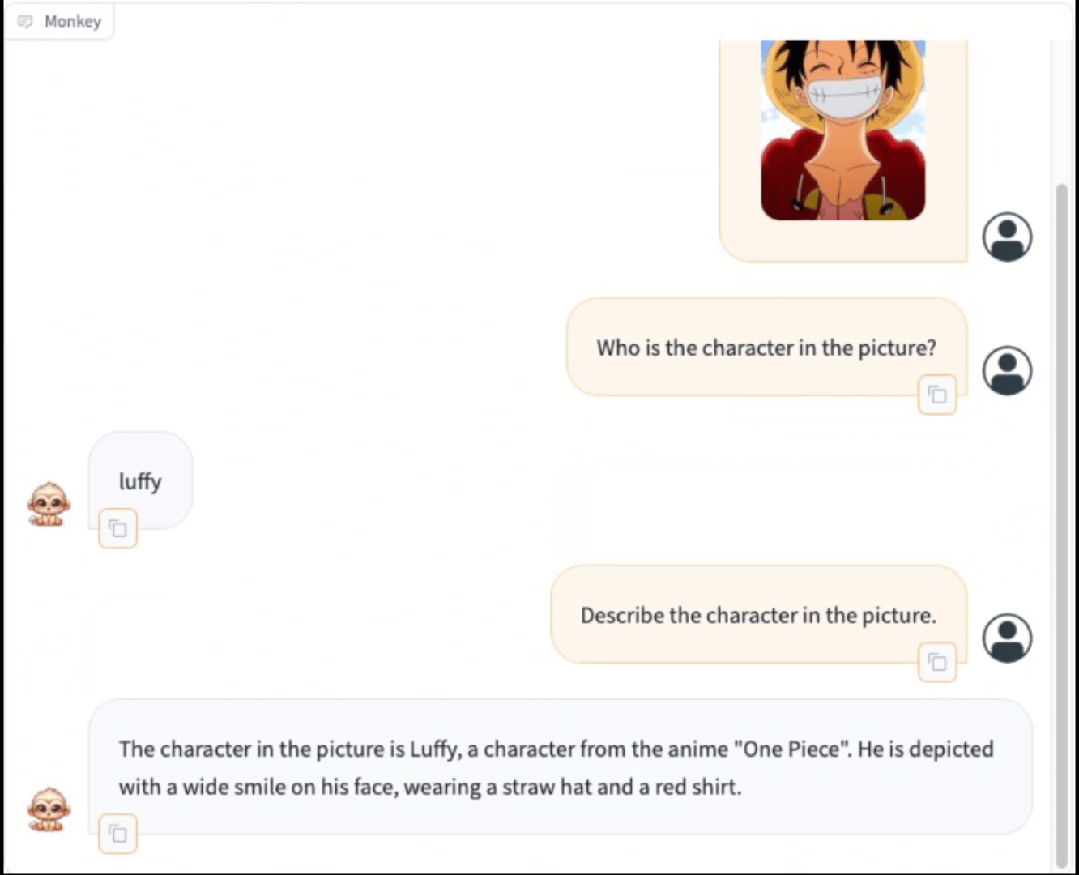
Monkey在Caption任务上同样取得了出色的结果,不仅仅是对图片进行准确详细的描述,同时能够合理发散,分析出图片所传达的一些抽象含义
以下是Monkey同GPT4V在密集文本与图表上进行问答的可视化结果展示。

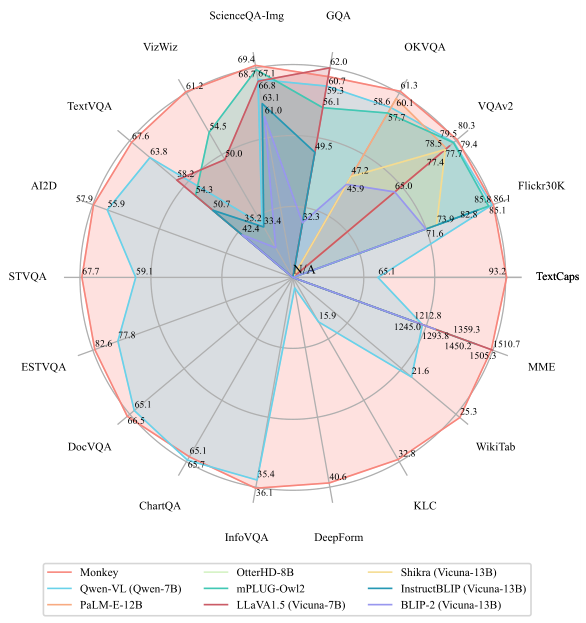
下图展示了Monkey的卓越性能,在 18 个不同的数据集上进行测试的结果表明,Monkey能够很好地胜任图像描述生成、场景问答、以场景文本为中心的视觉问答和面向文档的视觉问答等任务,并在16个数据集上取得SOTA。
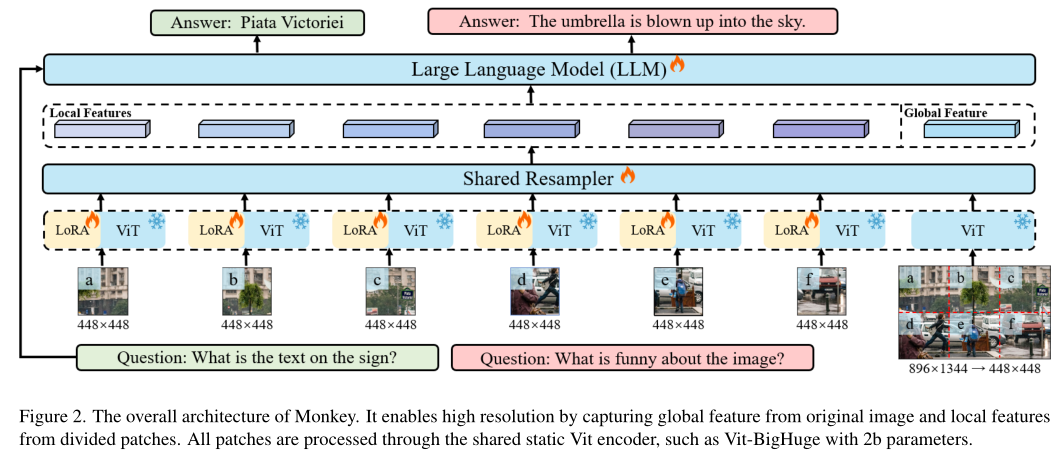
方法介绍:
1. 增大输入分辨率
将原始输入图片裁剪成多个图片块,再将这些图片块和原始输入图片统一到448*448的尺寸。每个图片块经过视觉编码时会加入一个专属的Lora以此更好地提取图片块的局部视觉特征,训练时仅训练Lora部分,而原始的输入图像则用于提取全局特征,以此方法达到增大输入分辨率的目的。
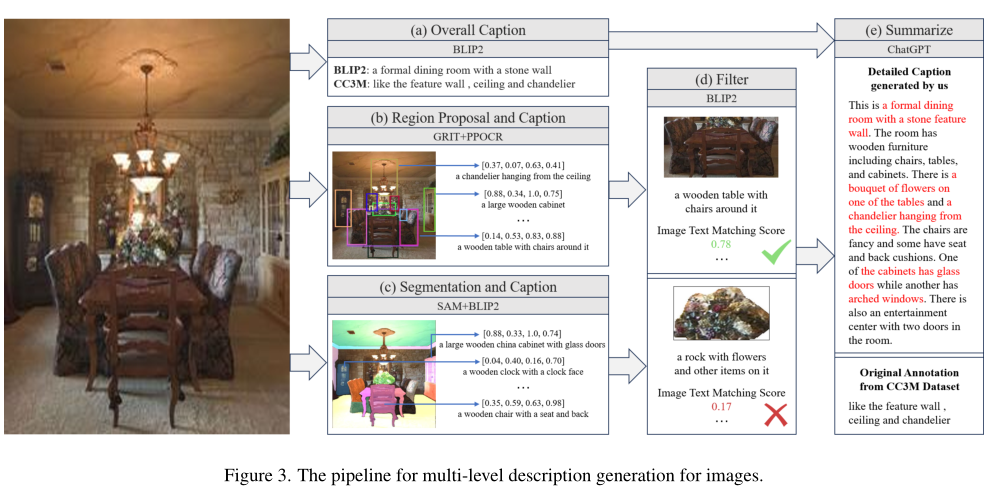
2. 多级特征融合的详细描述生成方法生成高质量图文数据
主要分为五个步骤:第一步,使用BLIP2对整张图生成全局描述;第二步用 GRIT生成区域框,并提供区域中对象的名称和详细描述,同时使用PPOCR提取区域的文本框坐标和文本内容;第三步使用SAM进行分割,并送入BLIP2生成对各个物体及其组成部分的详细描述;第四步使用BLIP-2 评估过滤掉低分匹配;最后使用ChatGPT 对上述得到的描述进行总结从而得到图像的详细描述。
下图为使用使用多级特征融合的详细描述生成方法后得到的标注与原始CC3M标注的对比,不难看出,两种标注之间存在着较大的差距,生成的详细标注尽可能地包含了图片中的各种细节,而不像是CC3M地原始标注那样一句带过。利用这样高质量的图文数据进行训练,使得Monkey能够更好地把握图文之间的关系。

更多的可视化对比结果与展示:
通过下图展示的Monkey在QA任务上与多种大模型的对比结果,从中我们能够更加直观地感受到Monkey强大的问答能力,能够准确地把握住问题并给出正确的回答,尤其是在密集文本问答任务上,目前的大模型或多或少都面临着一定的问题,Monkey为解决这一难题提供了一条可行的出路。

总结
Monkey提出了一种训练高效的方法,无需预训练即可有效地提高模型的输入分辨率,最高可达896 x 1344像素。为了弥补简单文本标签和高分辨率输入之间的差距,Monkey提出了一种多级特征融合的详细描述生成方法,它可以自动提供丰富的信息,以引导模型学习图像中各个物体的属性及其联系。通过这两种设计的协同作用,Monkey练就了一双火眼金睛,在多个基准测试中取得了出色的结果。
-
高分辨率
+关注
关注
0文章
47浏览量
15389 -
图像
+关注
关注
2文章
1091浏览量
40669 -
大模型
+关注
关注
2文章
2762浏览量
3413
原文标题:低成本扩大输入分辨率!华科大提出Monkey:新的多模态大模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
请问SAR ADC有效分辨率与采样率有关吗?
TVP7002 VGA输入分辨率支持1280 x 1536吗?
如何提高透镜成像的分辨率
如何选择扫描电镜的分辨率?

商汤日日新多模态大模型权威评测第一
请问ISO7720的时间分辨率有多少?
HDMI接口支持哪些视频分辨率
视频处理器的分辨率是如何管理的


利用OpenVINO部署Qwen2多模态模型
什么是高分辨率示波器?它有哪些优势?
VR显示器分辨率的选择
伺服编码器分辨率是什么意思
基于CNN的图像超分辨率示例





 工商网监
工商网监
评论