 超分画质大模型!华为和清华联合提出CoSeR:基于认知的万物超分大模型
超分画质大模型!华为和清华联合提出CoSeR:基于认知的万物超分大模型


项目主页:https://coser-main.github.io/ 论文:https://arxiv.org/abs/2311.16512 代码:https://github.com/VINHYU/CoSeR

图1. LR,GR和SR分别为低清图像、基于对低清图像的认知生成的参考图像和超分图像。
图像超分辨率技术旨在将低分辨率图像转换为高分辨率图像,从而提高图像的清晰度和细节真实性。这项技术在手机拍照等领域有着广泛的应用和需求。随着超分技术的发展和手机硬件性能的提升,人们期望拍摄出更加清晰的照片。然而,现有的超分方法存在一些局限性,如图2所示,主要有以下两个方面:
一是缺乏泛化能力。为了实现更好的超分效果,通常需要针对特定场景使用特定传感器采集到的数据来进行模型训练,这种学习方式拟合了某种低清图像和高清图像间的映射,但在其他场景下表现不佳。此外,逐场景训练的方式计算成本较高,不利于模型的部署和更新。
二是缺乏理解能力。现有的超分方法主要依赖于从大量数据中学习图像的退化分布,忽视了对图像内容的理解,无法利用常识来准确恢复物体的结构和纹理。

图2. 真实场景超分SOTA方法的局限性:(行一)难以处理训练集外的退化分布;(行二)难以利用常识恢复物体结构。
人类在处理信息时,有两种不同的认知反馈系统。诺贝尔奖经济学得主丹尼尔·卡尔曼在《思考,快与慢》中将它们称为系统一和系统二,如图3所示。系统一是快速的、直觉的、基于记忆的反馈,比如,我们可以脱口而出十以内的加减运算。系统二是缓慢的、多步的反馈,比如,28x39往往需要逐步运算。现有的超分方法更贴近系统一,它们主要依赖于从大量数据中学习图像的退化分布,忽视了对图像内容的理解,无法按照常识来准确恢复物体的结构和纹理,也无法处理域外的退化情况。本文认为,真正能有效应用于真实场景的画质大模型应该具备类似系统二的多步修复能力,即基于对图像内容的认知,结合先验知识来实现图像超分(Cognitive Super-Resolution,CoSeR)。
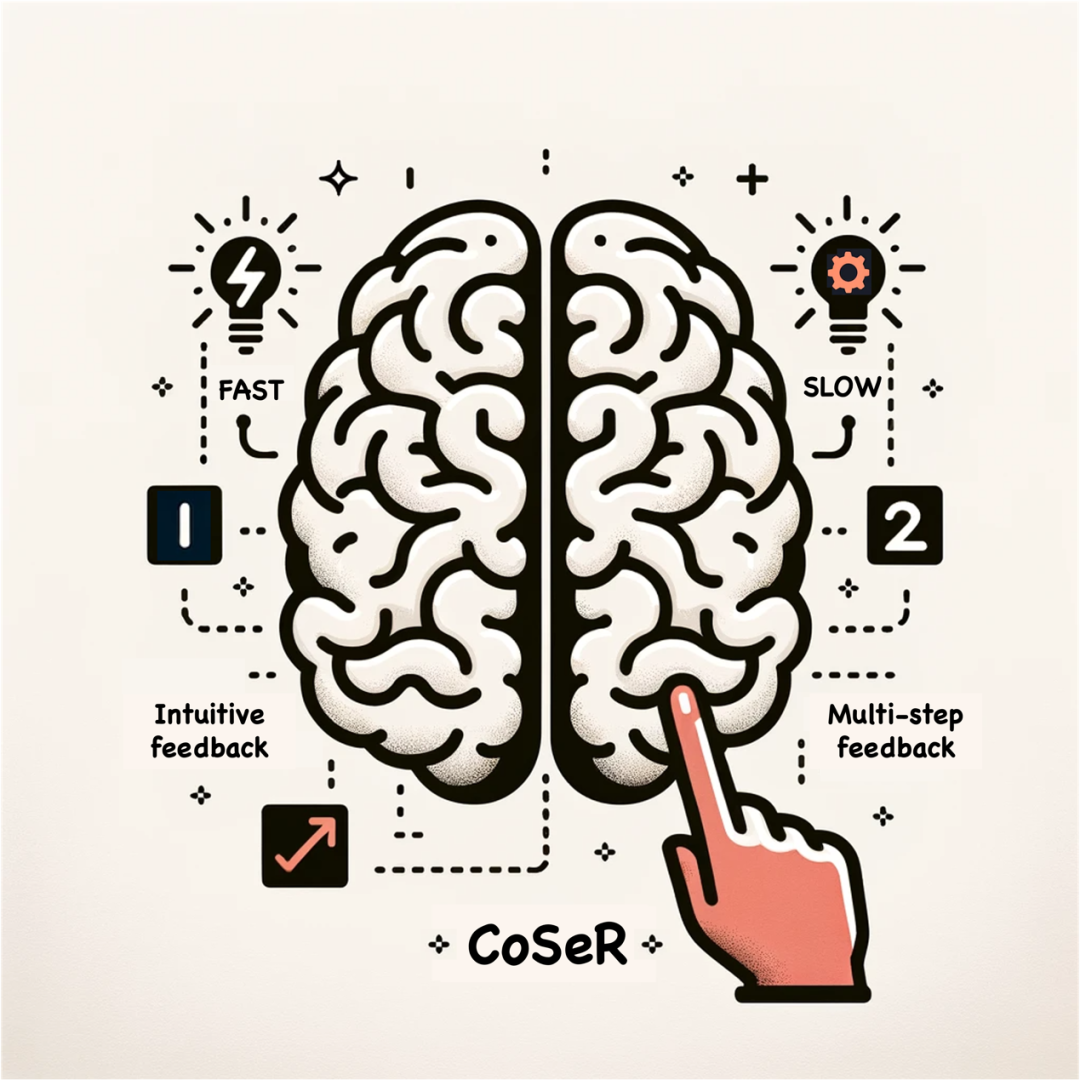
图3. CoSeR采用类似于人脑中系统二的修复方式
CoSeR模仿了人类专家修复低质量图像自上而下的思维方式,首先建立对图像内容的全面认知,包括识别场景和主要物体的特征,随后将重点转移到对图像细节的检查和还原。本文的主要贡献如下:
提出了一种通用的万物超分画质大模型CoSeR,它能够从低清图像中提取认知特征,包括场景内容理解和纹理细节信息,从而提高模型的泛化能力和理解能力。
提出了一种基于认知特征的参考图像生成方法,它能够生成与低清图像内容一致的高质量参考图像,用于指导图像的恢复过程,增强图像的保真度和美感度。
提出了一种“All-in-Attention”模块,它能够将低清图像、认知特征、参考图像三个条件注入到模型当中,实现多源信息的融合和增强。
在多个测试集和评价指标上,相较于现有方法,CoSeR均取得了更好的效果。同时,CoSeR在真实场景下也展现颇佳。
方法介绍
图4展示了CoSeR的整体架构。CoSeR首先使用认知编码器来对低清图像进行解析,将提取到的认知特征传递给Stable Diffusion模型,用以激活扩散模型中的图像先验,从而恢复更精细的细节。此外,CoSeR利用认知特征来生成与低清图像内容一致的高质量参考图像。这些参考图像作为辅助信息,有助于提升超分辨率效果。最终,CoSeR使用提出的“All-in-Attention”模块,将低清图像、认知特征、参考图像三个条件注入到模型当中,进一步提升结果的保真度。
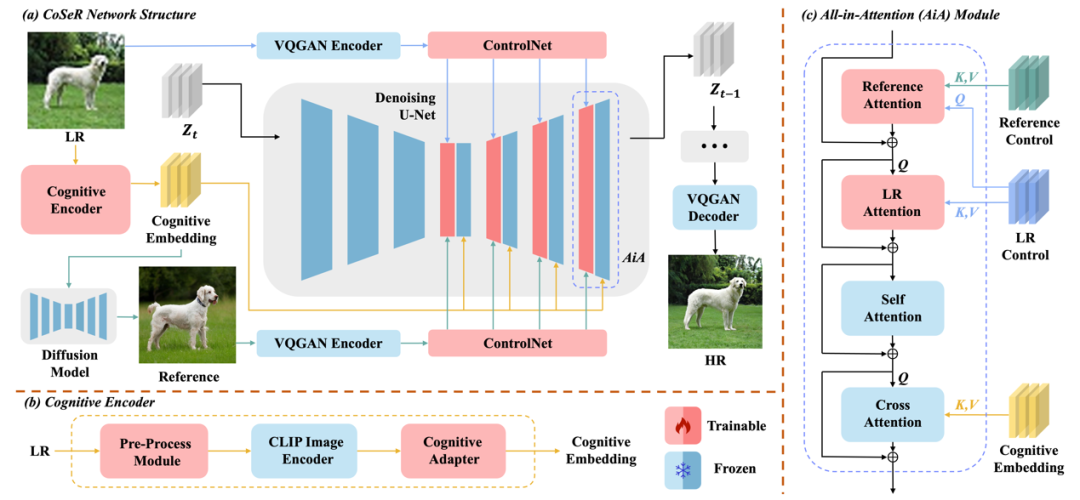
图4. 本文提出的万物超分画质大模型CoSeR
图5展示了CoSeR参考图像生成的效果。与直接从低清图像中获取描述的方法相比,CoSeR的认知特征保留了细粒度的图像特征,在生成具有高度相似内容的参考图像时具有优势。在图5的第一行,使用BLIP2从低清图像生成的描述无法准确识别动物的类别、颜色和纹理。此外,CoSeR的认知特征对于低清图像更加鲁棒。例如,在图5的第二行,由于输入分布的差异,BLIP2会生成错误的图像描述,而CoSeR生成了内容一致的高质量参考图像。最后,相比于BLIP2大模型接近7B的参数量,CoSeR的认知编码器只有其3%的参数量,极大提升了推理速度。
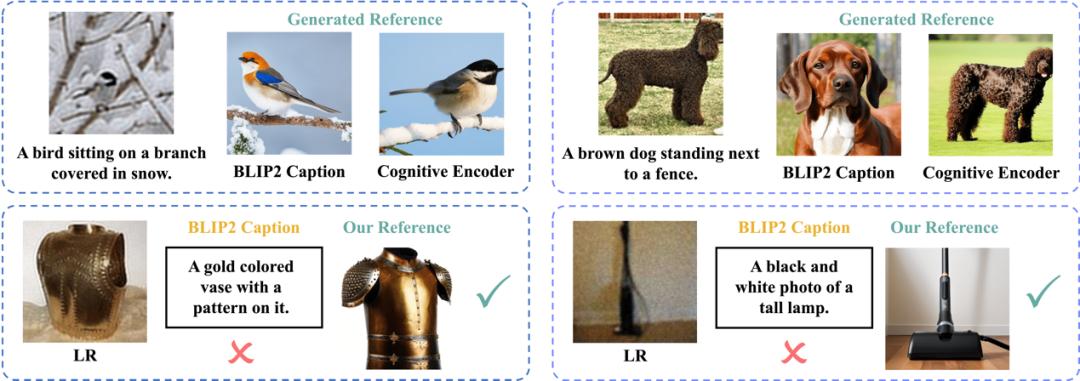
图5.(行一)使用BLIP2描述生成的参考图和CoSeR生成的参考图;(行二)CoSeR的高鲁棒性
结果展示
表1和图6展示了CoSeR与其他方法的定量和定性结果对比。CoSeR在含有丰富类别的ImageNet数据集及真实超分数据集RealSR和DRealSR上,都取得了不错的结果。CoSeR能够恢复出更加清晰和自然的图像细节,同时保持了图像的内容一致性和结构完整性。
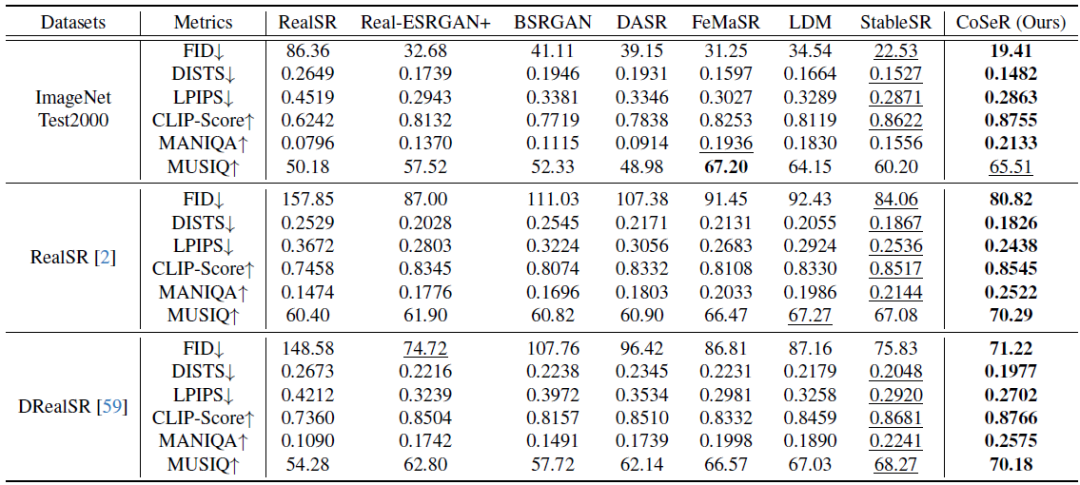
表1. 定量结果对比
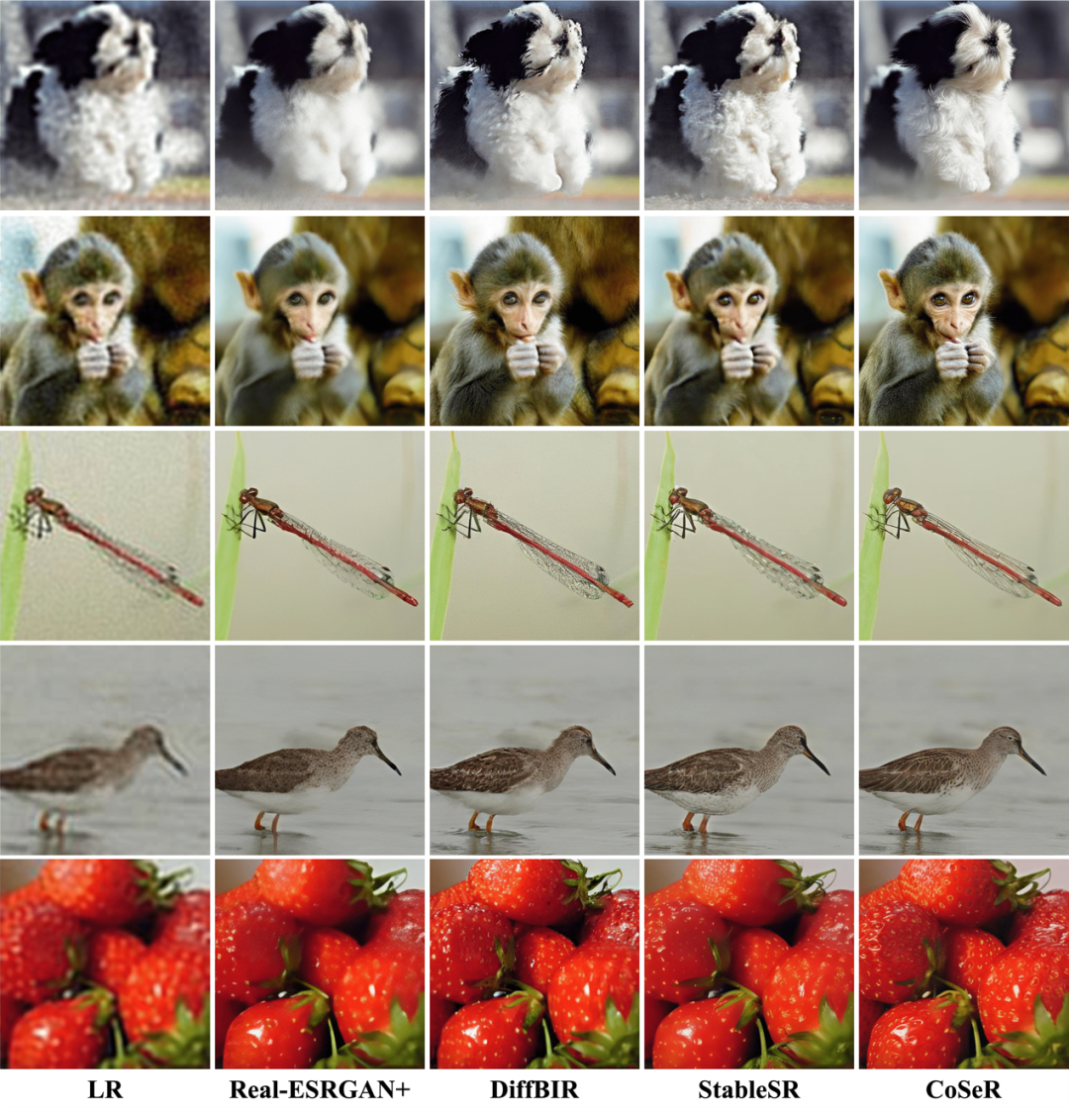
图6. 定性结果对比
本文提出的CoSeR模型为图像超分辨率技术提供了一种新的思路和方法,它能够从低清图像中提取认知特征,用于激活图像先验、生成参考图像,从而实现高质量的万物超分效果。我们未来的研究重点是如何在不影响超分性能的情况下加速采样,以获得更高的视觉质量。此外,我们还将探索统一模型在更多样化的图像修复任务中的表现。
-
传感器
+关注
关注
2577文章
55505浏览量
793953 -
图像
+关注
关注
2文章
1096浏览量
42438 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:超分画质大模型!华为和清华联合提出CoSeR:基于认知的万物超分大模型
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
IoT物联网课程清单
万物互联时代引领者—微物联网云服务平台
鸿蒙是什么?他是兼容万物的斗战胜佛
HarmonyOS IoT首著,走进万物互联的世界!
HarmonyOS IoT首著,走进万物互联的世界!
鸿蒙座舱子品牌来了,华为发布 HarmonySpace:万物互联的智能出行空间
ARM用以解决图像超分模型过参数问题
介绍一种MobileAI2021的图像超分竞赛的最佳方案
介绍一种Any-time super-Resolution Method用以解决图像超分模型过参数问题
如何使用TensorFlow Hub的ESRGAN模型来在安卓app中生成超分图片
OpenHarmony分论坛-图库应用数据加载显示模型



评论