 盘点一下PostgreSQL的几种常用脱敏方式
盘点一下PostgreSQL的几种常用脱敏方式

数据脱敏是一种广泛采用的保护敏感数据(如信用卡,社保卡,地址等信息)的方法。脱敏数据不仅仅是为了保护你和客户的数据安全,在一些情况下,法律也有相应要求,最著名的例子就是 GDPR。 市面上也有各种不同的数据脱敏方法,例如遮挡,替换,洗牌和加密,适用于不同场景。通过对敏感数据进行脱敏处理,组织能够降低数据泄露和未经授权访问的风险,同时仍然能够使用真实数据进行开发、测试和分析等任务。 本文来盘点一下 PostgreSQL 的几种常用脱敏方式。
PostgreSQL Anonymizer
PostgreSQL Anonymizer 是个社区贡献的扩展 (https://www.postgresql.org/about/news/postgresql-anonymizer-10-privacy-by-design-for-postgres-2452/),可以为 PostgreSQL 添加不同的数据脱敏选项和方法。它将脱敏配置存储在 PostgreSQL 的 SECURITY LABEL(安全标签)中。
动态脱敏
PostgreSQL Anonymizer 实现动态脱敏的方式是通过将定义某个角色为 "MASKED" 以及脱敏规则。被授予 "MASKED" 角色的用户将无法访问原始数据,而其他角色仍然可以访问。它现已支持多种的脱敏语法,你甚至可以编写自己的规则。 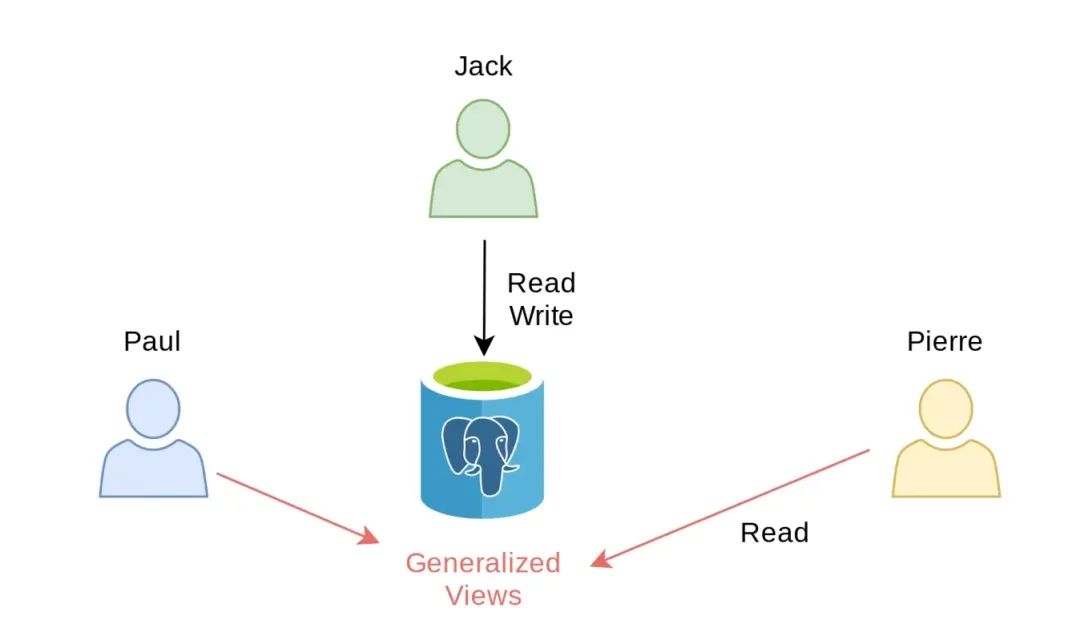 这种方法有一定的局限性,例如在他们文档中 (https://postgresql-anonymizer.readthedocs.io/en/latest/dynamic_masking/#limitations) 有提到,如果你同时使用脱敏插件和 GUI 工具如 DBeaver 或 pgAdmin 进行查询的时候可能会出现问题;对于某些查询来说,动态脱敏可能非常慢。此外,不同的脱敏变体需要不同的视图,在角色或底层表发生变化时,这又很快变得难以管理起来。
这种方法有一定的局限性,例如在他们文档中 (https://postgresql-anonymizer.readthedocs.io/en/latest/dynamic_masking/#limitations) 有提到,如果你同时使用脱敏插件和 GUI 工具如 DBeaver 或 pgAdmin 进行查询的时候可能会出现问题;对于某些查询来说,动态脱敏可能非常慢。此外,不同的脱敏变体需要不同的视图,在角色或底层表发生变化时,这又很快变得难以管理起来。
静态脱敏
PostgreSQL Anonymizer 还支持静态脱敏,可以直接转换原始数据集。比如可以用虚假数据替换原始数据,添加噪音或者混淆数据以隐藏敏感信息。 静态脱敏的原则是更新包含至少一个被脱敏列的所有表的所有行。基本上意味着 PostgreSQL 将重写磁盘上的所有数据。所以请注意,这种方法会破坏原始数据,并且是一个比较缓慢的过程。因此,在使用静态脱敏之前,请三思而后行。
Bytebase 动态数据脱敏
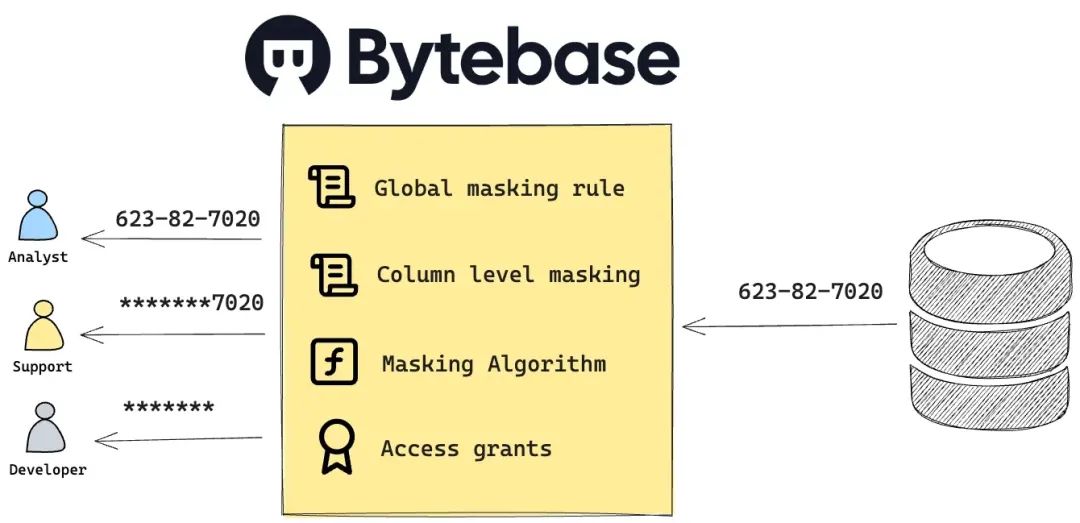 Bytebase 动态数据脱敏 (https://www.bytebase.com/docs/security/data-masking/overview/)不依赖于 PostgreSQL 视图或其用户,而是通过 Bytebase 内部管理脱敏策略和授权管理。当用户通过 SQL 编辑器查询时,会自动应用动态脱敏策略。
Bytebase 动态数据脱敏 (https://www.bytebase.com/docs/security/data-masking/overview/)不依赖于 PostgreSQL 视图或其用户,而是通过 Bytebase 内部管理脱敏策略和授权管理。当用户通过 SQL 编辑器查询时,会自动应用动态脱敏策略。 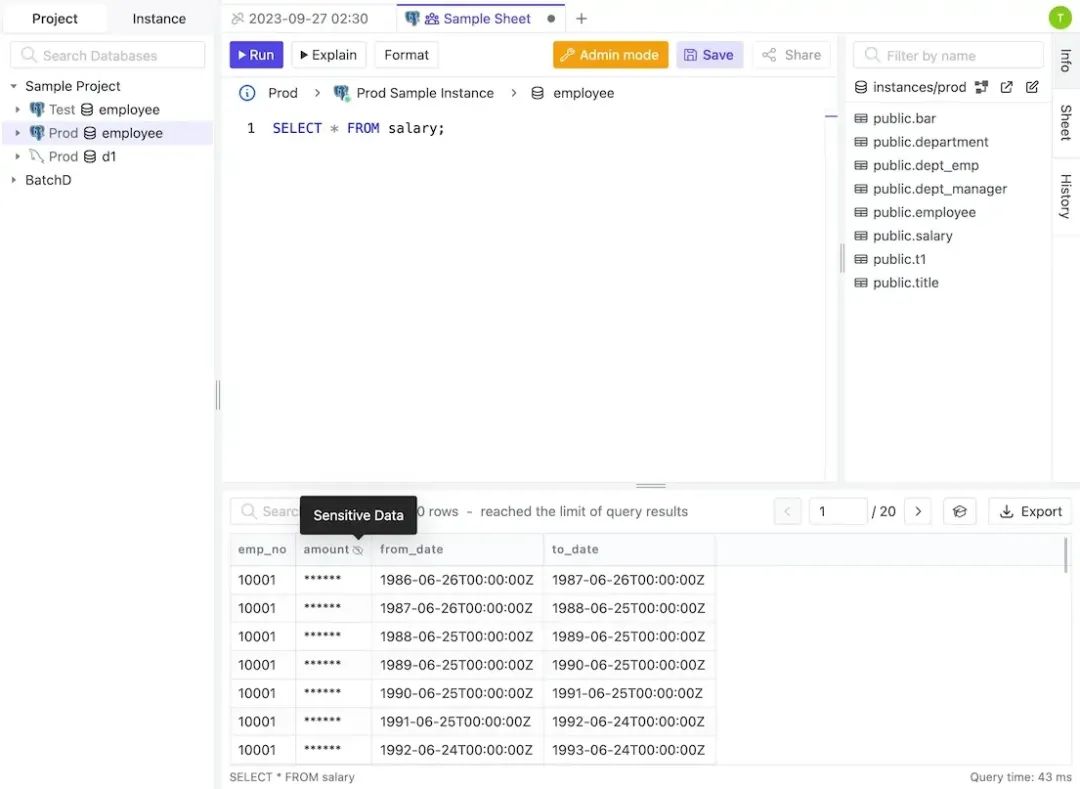 Bytebase 动态数据脱敏包括以下组件:
Bytebase 动态数据脱敏包括以下组件:
全局脱敏规则:工作空间的「管理员」和「DBA」可以批量定义全局脱敏规则。例如,可以将所有名为 email 的列脱敏程度设置为「半脱敏」。这样,修改脱敏策略就无需手动修改数千列了,还节省了维护视图的麻烦。
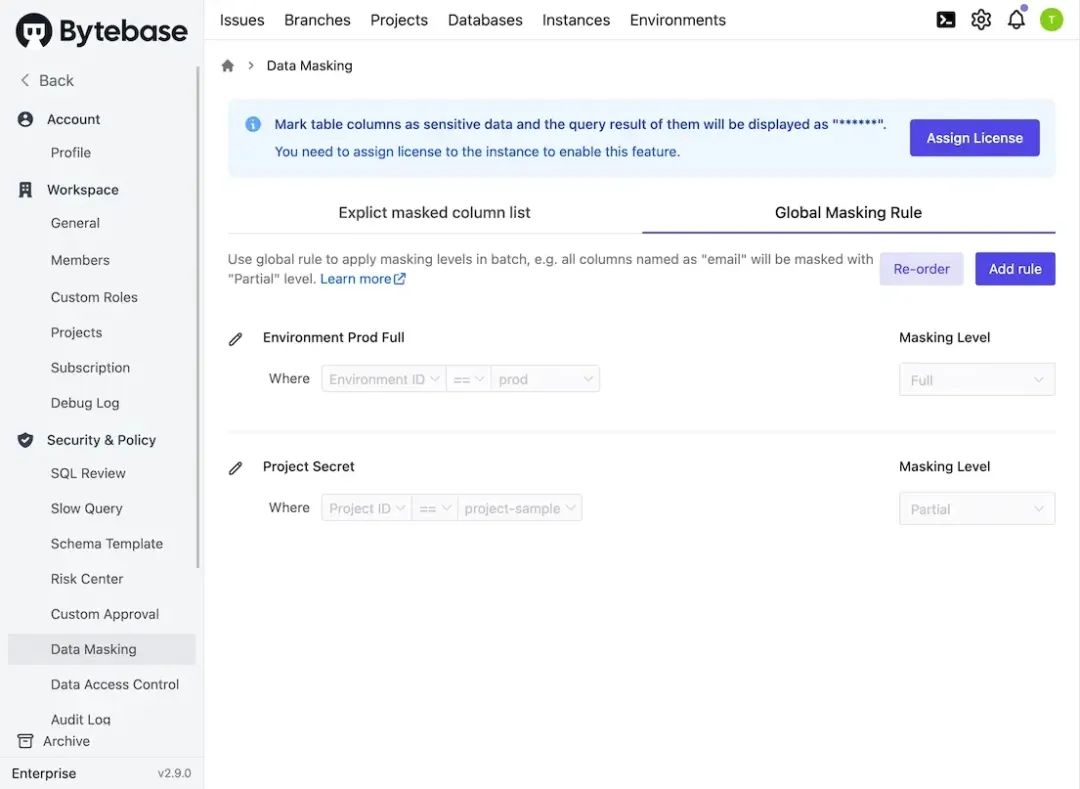
列脱敏规则:工作空间的「管理员」和「DBA」可以将列设置为不同的脱敏级别。列脱敏规则优先于全局脱敏规则。
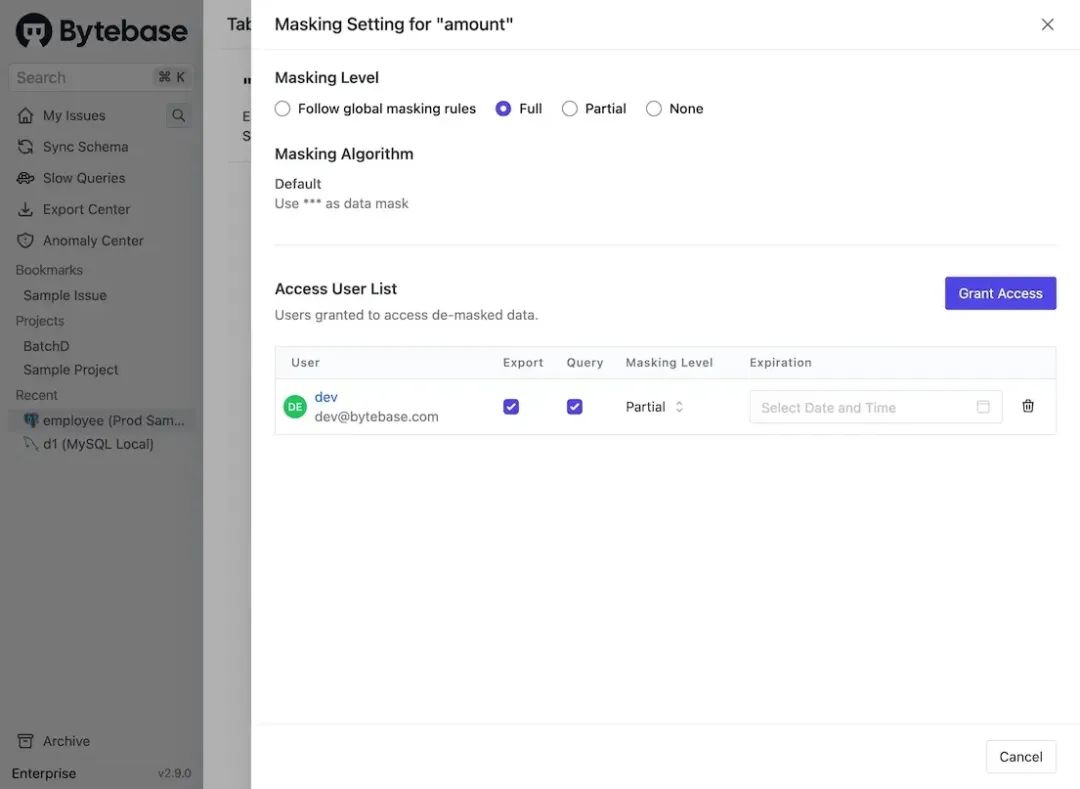
访问未脱敏数据:对于脱敏数据,工作空间的「管理员」和「DBA」可以授予特定用户访问未脱敏数据的权限。
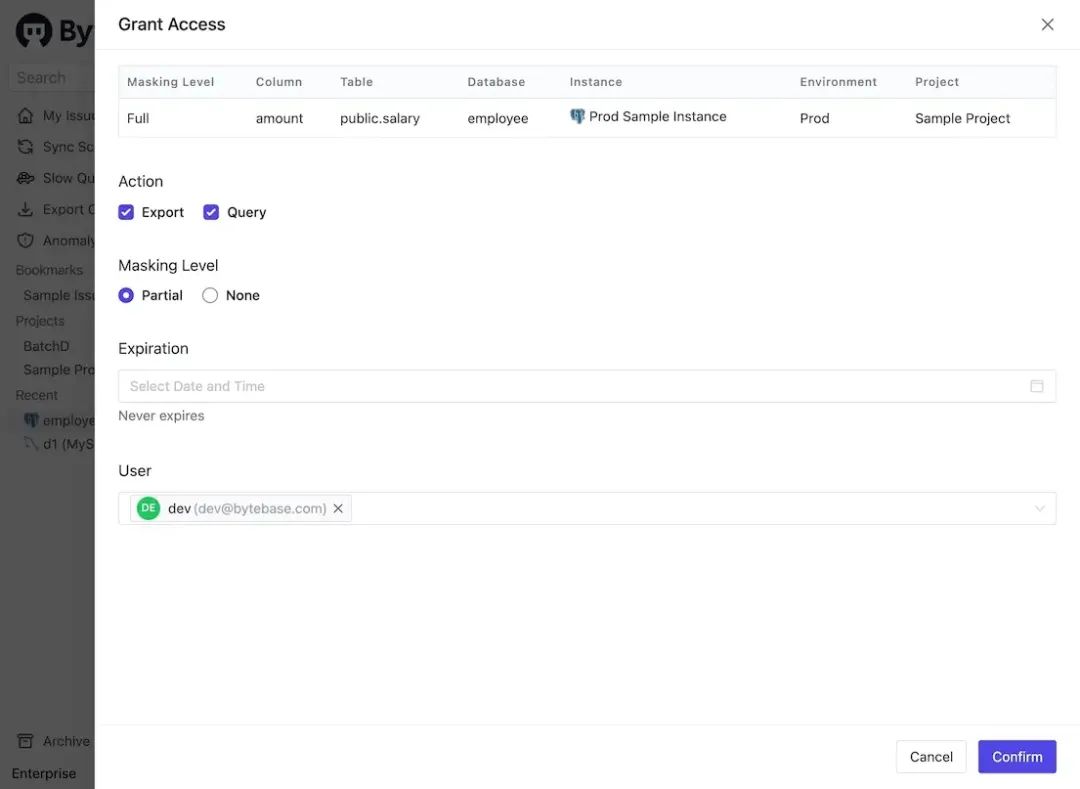 工作空间的「管理员」和「DBA」均为 Bytebase 的角色 (https://www.bytebase.com/docs/concepts/roles-and-permissions/)。
工作空间的「管理员」和「DBA」均为 Bytebase 的角色 (https://www.bytebase.com/docs/concepts/roles-and-permissions/)。
对比
PostgreSQL Anonymizer 的优势在于它是在数据库本身中实现的。因此,无论查询如何发送到数据库,数据脱敏规则都会被强制执行。对于 Bytebase 动态数据脱敏,查询必须通过 SQL 编辑器才会强制执行。 Bytebase 动态数据脱敏的优势在于其与所有 PostgreSQL 发行版都兼容,且支持细粒度的脱敏策略和访问权限。只要团队通过 Bytebase SQL 编辑器来查询数据库,那么 Bytebase 动态数据脱敏可以保障组织敏感数据的安全。
审核编辑:黄飞
-
数据库
+关注
关注
7文章
4083浏览量
68538 -
postgresql
+关注
关注
0文章
29浏览量
644
原文标题:PostgreSQL数据脱敏方式盘点
文章出处:【微信号:OSC开源社区,微信公众号:OSC开源社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
简单介绍一下常用的几种无位置传感器的控制方式
常用的几种无线网络组网方式介绍
SpringBoot日志脱敏的方式介绍
总结一下OpenCV遍历图像的几种方法
盘点国内目前常用的几种重金属检测方法
分享一下Cortex-M裸机环境下临界区保护的几种实现方法





评论