 聊聊日志即数据库
聊聊日志即数据库
《数据库故障恢复机制的前世今生》[1]一文中介绍过,由于磁盘的的顺序访问性能远好于随机访问,数据库设计中通常都会采用WAL的方式,将随机访问的数据库请求转换为顺序的日志IO,并通过Buffer Pool尽量的合并并推迟真正的数据修改落盘。如果发生故障,可以通过日志的重放恢复故障发生前未刷盘的修改信息。也就是说Log中包含数据库恢复所需要的全部信息。
现代数据库为了追求更高的事务并发度,会显式地区分用户可见的逻辑内容和维护内部的物理结构,在并发控制上支持了Lock和Latch的分层,同时也在故障恢复上区分了User Transaction和System Transaction。在这种设计下, 保证数据库D(Durable)的Redo Log需要能在Crash Recovery的过程中,在完全不感知用户事务的情况下,恢复未提交的System Transaction。因此,Redo Log的设计上天然就是Page Oriented的,也就是说每条Redo Log都被限制在单个Page中,其重放过程不需要感知用户事务的存在,也不需要关心其他的Page。在《B+树数据库故障恢复概述》[2]中详细的讨论过这个过程,也提到这样做的好处使得在Crash Recovery的过程中Page的恢复过程可以实现充分的并发。到这里我们就可以引出本文想要讨论的主要内容:
已知:
特性1(完备):Log中包含数据库恢复所需要的全部信息;
特性2(Page Oriented):Page通过Log的恢复过程只需要关心当前的Page本身;
那么,通过这两个特性,数据库设计能实现哪些实用和有趣的功能呢?
Single Page Recovery
最直接的就是让Single Page Recovery成为可能,当硬件故障导致某些Page的数据损坏或错误时,通常数据库都是将这类Page异常直接当做介质损坏来处理的,比如需要从最近的备份做还原。这样会由于多余的,不必要的数据还原导致较长的恢复时间和空间开销。而Single Page Recovery可以更精准、更快的只恢复损坏的Page。如果再搭配上一些Page Corruption检测机制,比如磁盘、操作系统、DB对数据的Checksum检查,甚至是一些自检的数据结构,就可以实现更可靠的数据库服务。
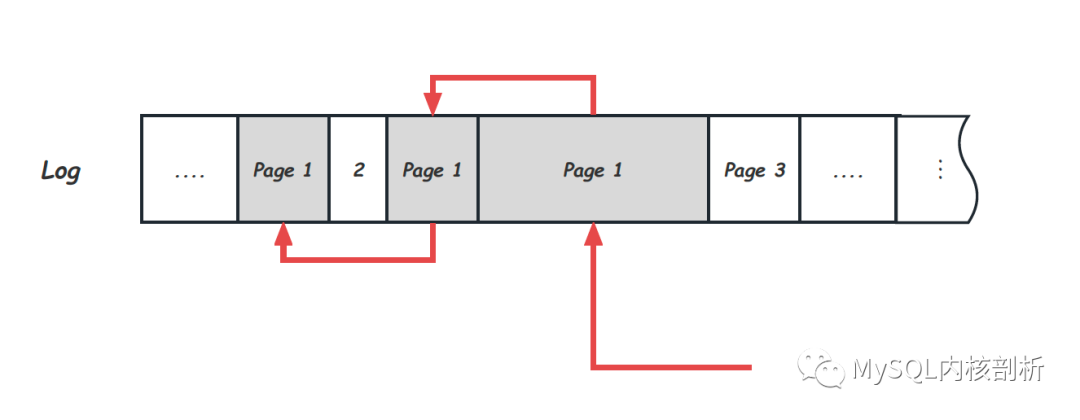
为Log建立按Page索引(Log Index)
发现损坏的Page后,下一步就是对该Page的恢复,即Single Page Recovery过程本身。这个时候最主要的是需要有根据Page号查找所有需要的Log的能力。而正常的Log写入是Append Only的,所有Page的Log会穿插在一起,因此这里需要Log有按照Page的索引存在。比如,可以通过在Log中添加信息维护如下Page的Log链,当需要恢复Page时,可以沿着这个Log链一路找到所有需要的Log Record:
More Than Single Page Recovery
Single Page Recovery其实是让DB拥有了:在任何时候,通过较老的Page版本及之后的Log,在线获得Page的最新版本的能力。 那么,利用和这个能力,DB能做的就不只是单个Page的故障恢复。甚至转变一下思路,如果通过主动的引入Page故障,并在需要的时候再做这个Page的Recovery是否能获得更多的东西呢?本文将从这个角度出发介绍几个DB可能的工作,其中很多其实已经在慢慢变成包括PolarDB在内的现代数据库的标配。
写省略(Write Elision):
省略部分Page刷盘操作,主动让Page成为“Corrupt Page”, 并在需要的使用再通过Single Page Recovery来拿到需要的Page。
快速重启(Instant Recovery):
当发生System Failure后,DB重启过程中,跳过需要的Log应用,主动保持这些Page的“Corrupt”状态,在后续需要访问的时候再通过Single Page Recovery恢复。
快速还原(Instant Restore):
当发生Media Failure后,DB还原的过程中,跳过Page的修复过程,同样在后续需要时再恢复。
写省略(Write Elision)
一次很小的Page修改通常会对应一条很短的Log Record,但却会导致整个Page在Buffer Pool中变成脏页,在《庖丁解Innodb之Buffer Pool》[3]中介绍过,Buffer Pool本身大小是受限的,当没有空闲的Page空间时,为了承载新的请求,就需要通过例如LRU算法来选择Page换出,如果换出的Page本身是脏页,就需要先将这个脏页刷盘,也就是触发一次Page大小的写IO。当总数据量远大于Buffer Pool的场景中,这种现象频繁的发生:每个Page被换入Buffer Pool后做了很少的修改,又很快因为被换出而刷盘。很小的修改导致很大的写IO,而IO的带宽资源又是很宝贵的,这种场景中很容易就变成了整个DB的性能瓶颈,这也就是所谓的IO-Bound场景。
Single Page Recovery给了这种场景一种新的选择,当脏页被换出时,直接跳过刷脏过程,从而完全避免了Page大小的IO。当下次该Page再次被换入时,这个Page会被看做是一个“Corrupt Page”,通过Log的按Page索引找到需要的Log Record,并完成应用。这种实现由于避免了大量的Page IO,可以显著的提升这种IO-Bound场景下的DB性能。这种实现中,可以在写入过程中,在内存中维护Log的按Page索引。
快速重启(Instant Recovery)
数据库发生故障或运维操作需要重启时,中断服务的时间直接影响数据库的可用性,因此这个阶段是希望尽可能短暂的。《数据库故障恢复机制的前世今生》[1]中介绍过,ARIES实现的数据库在恢复过程中会经历Log Analysis、Redo Phase以及Undo Phase三个阶段,其中回滚未提交事务的Undo阶段可以在数据库提供服务之后,在后台进行。
因此主要影响不可服务时间的,就是Log Analysis阶段及Redo Phase阶段,其中应用Log恢复Page的Redo Phase的时间占比又显著高于仅仅扫描Redo的Log Analysis阶段。实践中,Redo Phase的时间可能因为Active Redo的量及Buffer Pool的大小限制变得不可接受。Redo Phase主要的任务是要将所有的未刷盘的Page通过重放Redo恢复到最新的状态,如果我们暂时接受这种未恢复Page的“Corrupt”状态,并利用Single Page Recovery的能力,在需要的时候再在后台完成,那么,我们就可以将数据库提供服务的时间提前到Redo Phase开始之前,如下图所示:
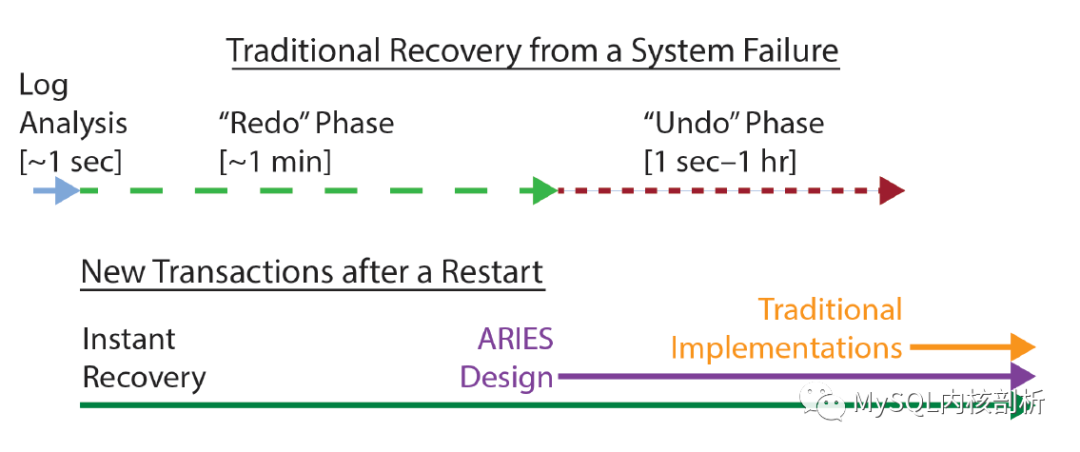
重启阶段
为了实现快速重启,在ARIES的基础上,Log Analysis阶段需要额外维护一些必要的信息,主要包括Register Pages及Log Index。其中Register Pages中记录所有Checkpoint之后的Active Redo所涉及到的Page,这些是所有需要恢复的Page。DB提供服务后,在后台异步完成Redo Phase之前,如果有用户请求访问到Register Pages中的Page才需要触发Single Page Recovery的恢复流程,并在Page恢复完成后从Register Pages中删除。另一个需要的信息就是Single Page Recovery过程中需要的Log index,参考ARIES中为Undo Phase维护的Per-Transaction Log链,这里也可以维护出Per-Page Log链,如下图所示:

需要做Recovery的Page可以沿着这个链表,一路找到当前Page LSN的位置或者找到Page Initial位置为止,并顺序应用所有需要的Page。
后台Redo Phase
DB完成Log Analysis并开始提供服务之后,后台的Redo Phase会比之前同步的Redo Phase有更多的选择。比如,是立刻恢复所有的Resister Pages,还是等待这些Page真正被用户请求使用时再恢复,亦或是二者结合。又比如,是按照Log中Page的排列顺序恢复,还是按照Page的某种优先级恢复(大/小事务优先、大/小表优先,或者某种用户定义的优先级),亦或是多种策略相结合。同时后台Redo Phase过程由于Page恢复之间相互独立,也天然更容易实现并发。因此,更高的灵活度和可能更高的并发度,也是Instant Recovery除了快速恢复服务之外新增优势。
不过需要注意的是,由于在恢复同时接受用户新的请求,完整的恢复过程可能会拉长,而在这个过程中,用户请求的性能也是会有下降的,如下图所示是一个传统ARIES Restart和Instant Restart的DB可用性及性能效果:
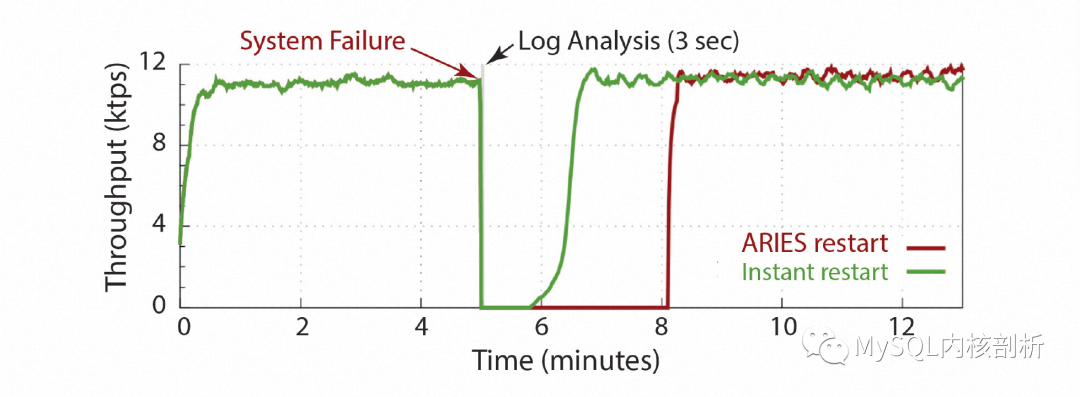
快速还原(Instant Restore)
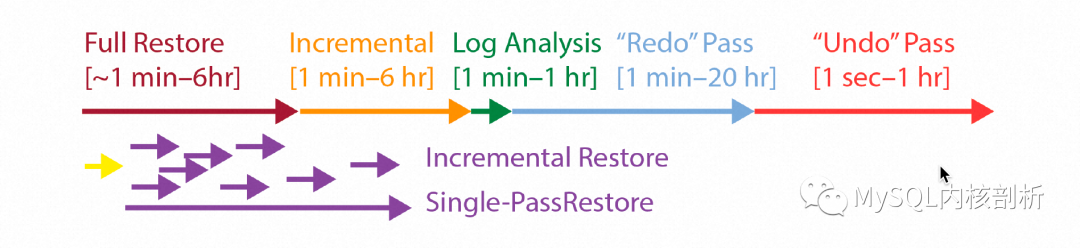
备份还原通常是数据库应对磁盘故障的保底手段。为了实现这一点,正常运行过程中,数据库就需要周期性的对数据和日志进行备份,权衡恢复时间和对正常运行的影响,其中数据备份又包括全量备份和增量备份。当遇到磁盘故障需要做备份还原时,会先从全量备份和增量备份在新的磁盘上还原一份数据,之后应用备份时间点之后的日志,全部完成后切换这个新的数据库实例提供服务。整个过程如下图所示:
可以看出,备份还原有非常长的周期,包括拷贝全量备份即增量备份的Full Restore及Incremental Restore阶段,以及跟重启类似的Log Analysis、Redo Phase和Undo Pass阶段,其恢复时间跟数据及日志总量相关,并受网络带宽及磁盘IO的限制。因此,尽可能让DB提前提供服务是非常必要的,类似于上面讲的快速重启,ARIES通过事务Lock的方式,让数据库可以在Undo Phase阶段完成前就提供服务。同样的,我们可以通过暂时接受“Corrupt Page”,将真正的Page Recovery推迟到需要的时候,从而将DB整体提供服务的时间提前,如下图所示:
我们甚至可以将这个时间点提前到备份还原的一开始。这个时候,新的磁盘上甚至还没有任何Page数据,当一个Page被访问的时候,会先从最近的全量及增量备份中去找到该Page的历史版本,再从Log备份中找到这个Page之后的所有Log完成应用。因此,能够快速找到需要Page对应的备份数据位置及需要的增量Logs非常重要,也就是在正常的备份过程中,为备份和Log维护按Page的索引。
为数据备份及Log备份建立按Page的索引
正常数据库写入过程中会以Append Only的方式写WAL Log,为可能发生的Crash做Recovery准备,这里称为Recovery Log。随着Checkpoint的推进,陈旧的Recovery Log不再被Recovery需要,可以被清理。但为了可能的备份还原,这部分Log还需要被保留,可能是在成本更低的存储介质上,这部分Log这里称为Archive Log。在转存Archive Log的过程中,便可以为Archive Log建立按Page索引。最理想的情况是需要还原的时候,有全局的Archive Log索引,但因为Log本身流式产生的特性,这样显然是不可能的。因此,分区排序的Archive Log就成为非常好的选择,如下图所示:
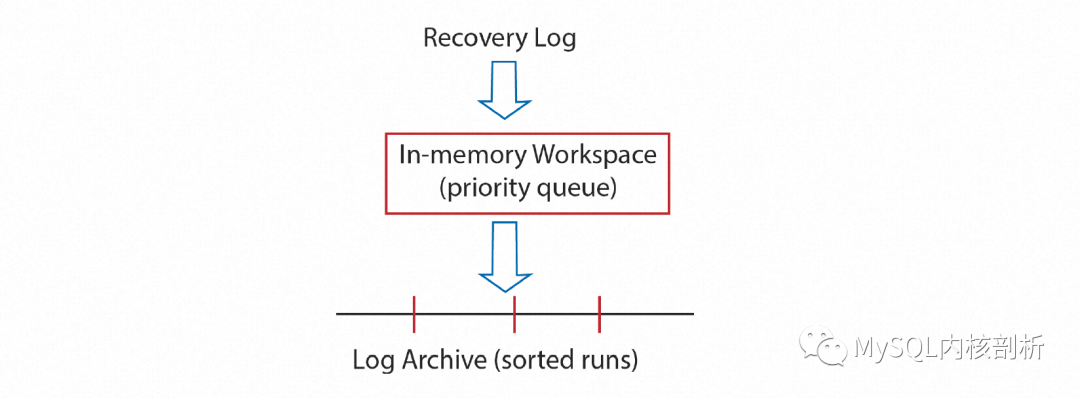
后台的Archive任务会在内存中对顺序生成的Recovery Log中的一段按Page排序,这部分内存超过某个大小时,已经排序的部分会落盘生成一个按Page号有序的Archive Log分片。重复这个过程就有了许许多多的排序分区。根据分片号及Page号就可以访问到需要Page的所有Archive Log。除了Log以外,为了支持Instant Restore的按需Page恢复,全量备份及增量备份也需要按照Page号建立索引。
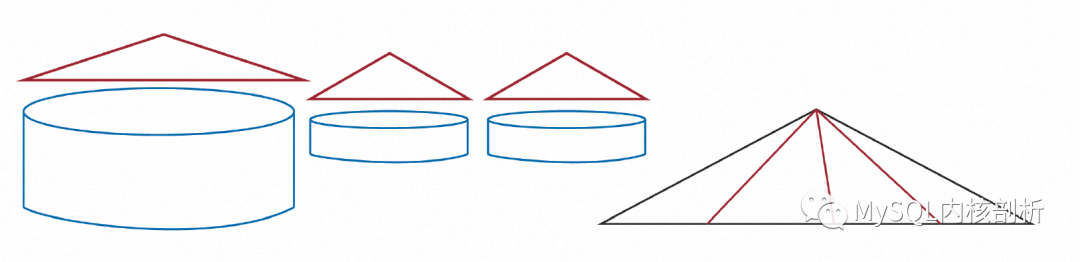
最终,如上图所示,无论是数据备份还是日志部分都存在一个索引方式可以方便的按照Page号查找。当一个Page需要真正做Restore时,就可以利用这些索引快速找到其对应的备份Page版本及后续Log,完成真正的Page重建。
后台Restore过程
类似于快速重启,实践上通常也会搭配一个后台运行的Restore任务,即使没有用户请求访问,所有的Page也会在一个有限的时间窗口全部完成Restore。下图展示的就是从全量备份,增量备份和日志备份中不断还原Page到目标新磁盘的过程。
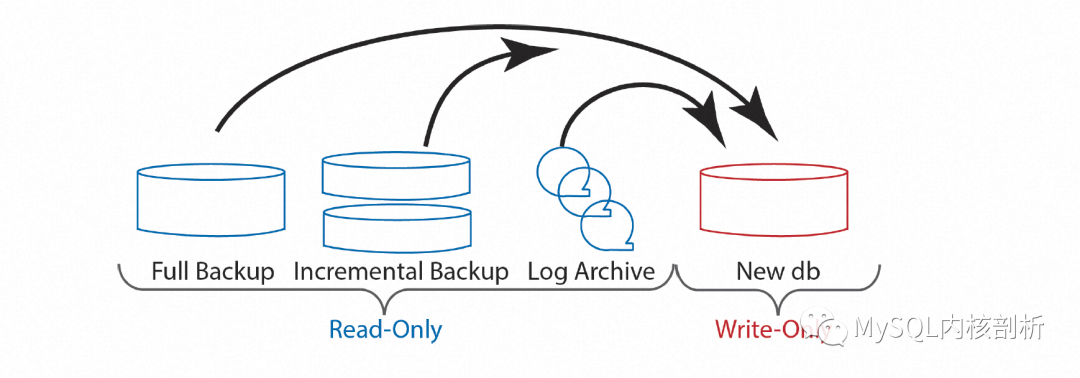
有了上面所说的数据备份及日志备份的按Page索引,后台的这个Restore过程也可以抛弃之前按Log顺序进行的限制,有了更多的选择和灵活性。举个很实用的例子,Backup相对于最新的DB位置,受Backup周期及写入压力的影响,中间的日志量可能非常多,而这些日志通常又会反复修改同一个Page,按照Log顺序的还原策略,会导致同一个Page可能会不断的读写,造成很大的IO浪费,也因此受到IO带宽限制。而采用Single Page Recovery方式的后台Restore过程,天然的可以按照Page的顺序进行还原,每个Page的一次读写都可以完成全部的日志应用,这样就可能很大程度的提升Page的IO效率和还原的速度。
应用 - Aurora
Aurora作为共享存储数据库的佼佼者,其设计和实现中大量的利用了日志即数据库的思路。Aurora认为计算节点与存储节点分离后,整个DB系统的IO瓶颈会转移到计算节点与存储节点及存储节点副本间的网络上,为此Aurora的设计中,计算节点和存储节点,及存储节点之间只传递日志,如下图所示:
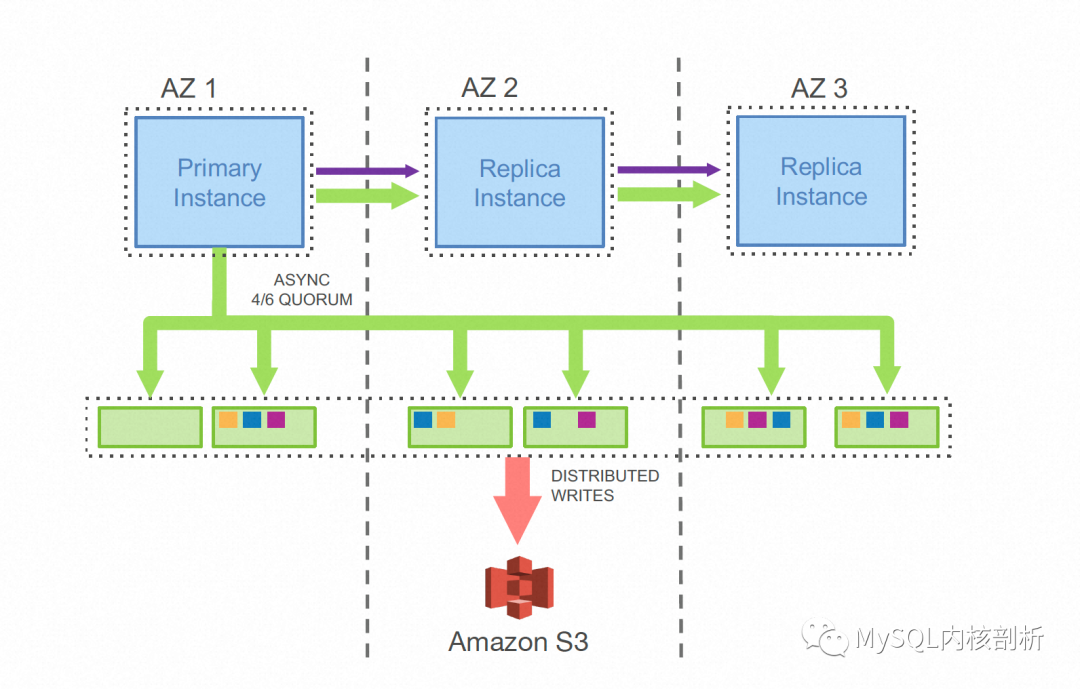
Aurora也把这种设计设计称为日志即数据(The Log is The Database)[4] 。这种实现会在日志量远小于Page修改量的场景下非常的有效,可以看出网络上传递的只有Log而没有任何Page数据。每个存储节点在收到流式的Log之后,会独立完成一遍Page的修改过程。下图所示的是其存储节点的工作流程:
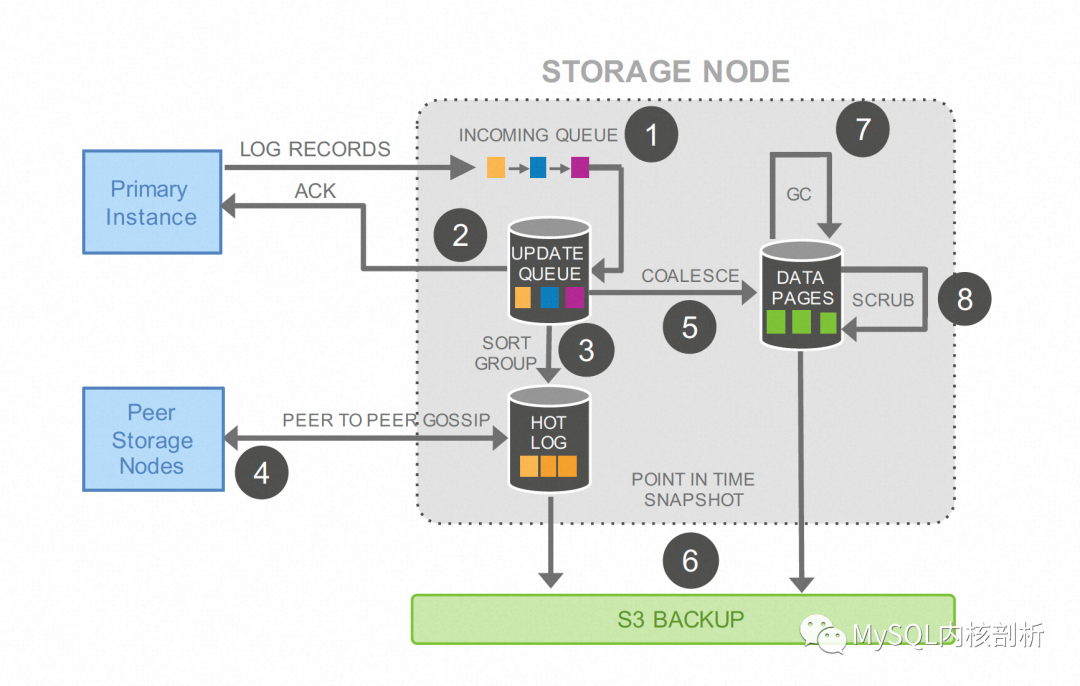
存储节点不断的从计算节点接受Log写入并持久化90(1),完成日志在Update Queue中的持久化,并返回计算节点确认(2),同其他存储节点通信补全Log(3),当某些Page收到的连续日志量超过某个阈值,或者整体的Update Queue中的日志量达到某个阈值后,这些Page会在后台周期性的应用Page的修改并写入Data Pages,这个过程称为日志到Page的合并(COALESCE)(5)。最后历史的日志和数据会备份到S3为后续可能的按时间点还原做准备。
写省略(Write Elision)
可以看出,当某个Page的收到的日志量比较少的情况下,Aurora的存储节点并不基于将其真正的修改到Data Pages中,这个时候,如果计算节点需要读这个Page,存储节点会应用Update Queue中的Log到需要的Page上并返回用户。这个熟悉的过程其实就是本文提到的写省略(WRITE ELISION)。理想情况下,一个Page的多次修改对应的Log会一直积累在Update Queue中而没有真正产生Page,直到足够的Log量触发Page 的COALESCE。
快速重启(Instant Recovery)
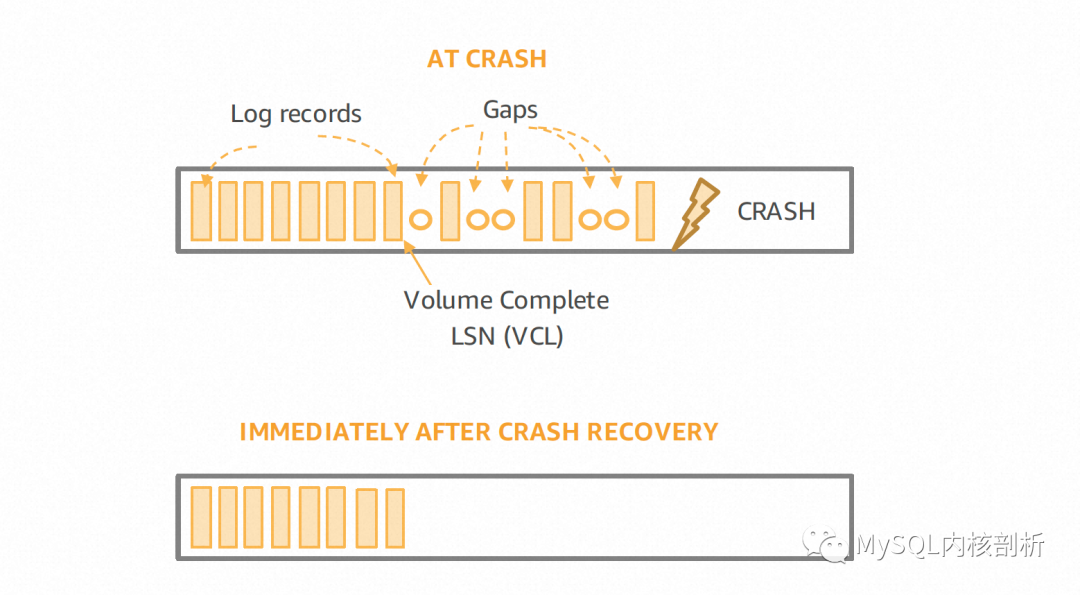
由于Aurora的计算节点不维护Log也不负责Page的更新,其重启过程可以非常迅速,不需要传统数据库的Log Analysis,Redo Phase及Undo Phase,而这部分需求其实是下放到了存储节点上的。Aurora存储节点的重启恢复过程,第一步要确定VDL or the Volume Durable LSN[5],这个位置可以认为对应单机数据库的有效Log结尾,之后这个存储节点就可以恢复向计算节点提供服务。这其实就是天然的Instant Restart实现,真正的Page Apply被推迟到用户请求,或收到更多的Log出发Page的Coalesce。
快速还原(Instant Restore)
云数据库通常都会会提供诸如按时间点还原的功能,来还原一个新的指定历史时间点的实例。这个过程其实就是典型的备份还原场景,需要结合历史的Page版本和后续增量Log完成。除此之外,Aurora还提供了Backtrack的能力,可以让当前实例分钟级的快速还原到Backtrack Window内的任意时间点,并且这个动作还可以向前向后反复重复执行。这部分的具体实现细节没有太多的公开资料,不过测试中Aurora在这些功能良好的表现以及合理的实现推测,也让我们相信其受益于其日志即数据库的设计。
总结
本文从AIRES及现代数据库的逻辑、物理分层实现,推导出数据库的Redo Log会具有,完备及Page Oriented两个特性,有了这两个特性,就可以很好的支持精准的Single Page Recovery。而更广泛一点的是让数据库拥有了:按需在线恢复单个Page的能力。而利用这个能力并主动引入”Page Corrupt”就可以实现更广义上的Single Page Recovery。本文从 写省略(Write Elision)、快速重启(Instant Recovery)以及快速还原(Instant Restore)三个方向介绍了利用Single Page Recovery可以让数据库获得的如性能提升、可用性提高、灵活性提高等优势。最后,通过介绍Amazon的共享存储数据库Aurora是如何在设计中应用这些优化的。最后的最后,同样作为共享存储数据库,后起之秀PolarDB与他的前辈Aurora有很多相似的地方,但也有着大不相同的硬件环境和架构设计,后续有机会会详细介绍PolarDB中是如何利用Single Page Recovery能力获得这些优势的。
审核编辑:汤梓红
-
内核
+关注
关注
3文章
1382浏览量
40394 -
数据库
+关注
关注
7文章
3845浏览量
64632 -
日志
+关注
关注
0文章
138浏览量
10667
原文标题:参考
文章出处:【微信号:inf_storage,微信公众号:数据库和存储】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
提高Oracle的数据库性能
基于数据库日志复制和故障恢复

数据库教程之如何进行数据库设计
数据库教程之SQL Server数据库管理的详细资料说明
尽可能限制NVM写操作的数据库日志方案NVRC

华为云数据库稳定可靠-即开即用
【数据库数据恢复】SQL server数据库被加密的数据恢复方案
python读取数据库数据 python查询数据库 python数据库连接
数据库优化那些事
SQL Server数据库备份方法
Oracle数据恢复—异常断电后Oracle数据库启库报错的数据恢复案例





 工商网监
工商网监
评论