 美光高性能内存与存储赋能生成式AI和SR技术发展
美光高性能内存与存储赋能生成式AI和SR技术发展
美光云计算高级业务发展经理 Eric Booth 90 岁的祖母患有严重的听力障碍,即使佩戴助听器也很难听清别人在说什么。Eric 注意到,她需要凑近讲话者,识别他们的唇语,努力理解他们的话语。而当多人进行交谈时,她常常会感到迷茫。
Eric 萌生了一个想法:
为何不用祖母的智能手机帮她来“倾听”呢?
他打开手机的记事簿功能,按下麦克风按钮,向她展示了手机如何将他的话转录成屏幕上的文字。
他表示:“我的祖母非常兴奋,笑得合不拢嘴,她现在可以参与到从前无法进行的对话中。”这也让我们看到了该技术如何切实改善了言语、语言和听力障碍者的生活质量。”
将语音转化成文本的技术看似简单,却很容易被忽视。事实上,它的演变过程十分复杂,历经几十年的发展才达到现有水平。
快速发展的技术
距第一台语音识别 (SR) 设备 Audrey 的问世已经过了很久。1962 年,贝尔实验室推出了 Audrey,当时这台约 2 米高的计算机只能识别个位数字,且无法输出文字。它会根据说出的数字闪烁相应次数的灯光,例如听到“9”时闪烁九次。
甚至几年前,SR 技术还不方便用户使用:它难以准确识别声音,无法过滤即使最轻微的环境声,转录速度也很慢。彼时,SR 技术想真正融入日常生活,还有很长的路要走。
如今,人工智能、虚拟助理技术、5G 蜂窝技术与内存、存储和计算机处理技术的进步使 SR 成为可能,帮助我们实现许多从前做不到的事情:比如用陌生的语言进行交流,即时转录长录音,只通过语音就能订购我们想要的任何东西并享受送货上门。
生成式 AI 正进一步提升该技术。语音识别将音频转化为文字,而生成式 AI 则对文字进行处理,让用户真正理解其含义。SR 技术不再仅聚焦于识别说了什么?而是专注于理解这些话是什么意思?是在提问吗?如果是,答案是什么?
这种类型的机器学习能根据用户提示或对话创建文本、视频、图像、计算机代码和其他内容。以语音识别为基础的生成式 AI 将学习提升到了全新水平,赋能 SR 技术以进一步帮助言语和听力障碍人士。
尽管灵活的语音识别可能会接收到不符合常规语音模式的语言,但生成式 AI 和自然语言处理 (NLP) 能理解并将其转化为相关建议。这一过程使全面且高度个性化的语言治疗方案成为可能。
Eric 的女儿曾接受语言治疗,他深知其所需的时间和精力。这一经历促使他攻读位于爱达荷州的博伊西州立大学的博士课程,以研究利用技术帮助语言障碍患儿的方法。
Eric 表示:“在语言治疗中,过去我们认为治疗师会给患者提供阅读内容并利用工具对他们的发音和吐字进行评分。但借助生成式 AI,我们能用工具来管理整个过程。生成式 AI 擅长识别各种语言模式,因此能更好地判断出患者是否经常发错 O 音。”
大语言模型
不久前,语音识别还需依赖大型内存服务器,并将收集到的全部数据上传云端。而如今,语音识别功能已内置在手机中,具有更快的计算速度和更大的内存,过去需要数据中心处理的流程现在能够直接在手机上进行。
AI 模型训练不仅能生成更复杂的模型,还可以将这些模型简化,从而在手机或个人电脑等终端设备上运行。很快,生成式 AI 程序就会出现在您的手机或其他终端设备上。随着大语言模型的快速发展,他们难以在云环境之外进行训练。然而,一旦模型通过训练并进行简化后,就能转移到终端设备上。
过去几年,大语言模型取得了巨大进步。Eric 表示:“大语言模型拥有数万亿个参数,是实现生成式 AI 聊天机器人和高级搜索功能的关键。几年前,万亿级的参数量难以想象,我们根本无法处理,而如今,这一数字已是基准线。当然,模型越大,就越智能,这正是拉动计算和内存需求的因素。”
NLP 和生成式 AI 需要大量大语言模型训练,其所使用的参数越多,所需的内存容量就越大(见下图)。
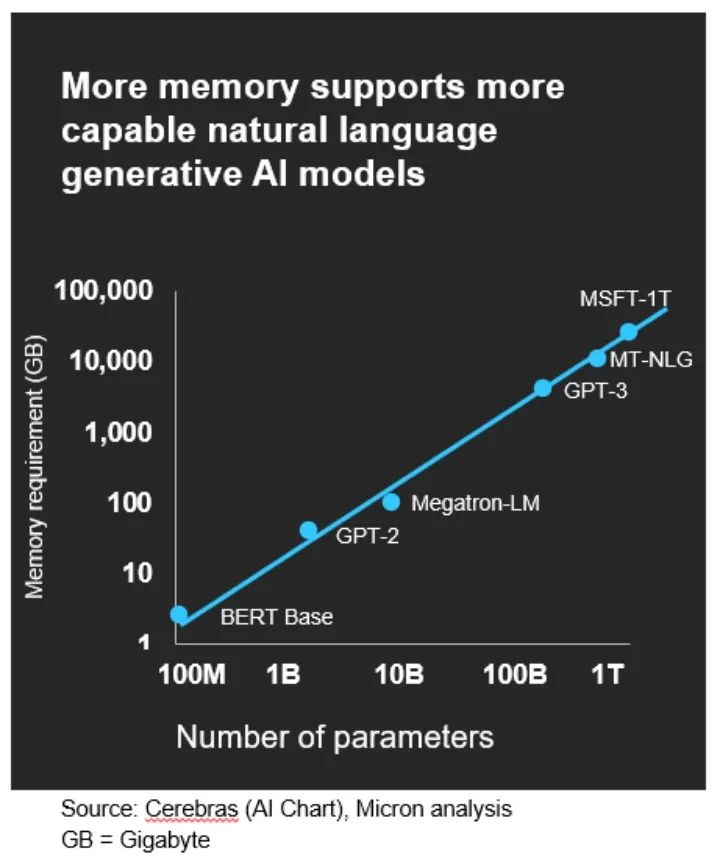
为了处理这些不断扩大的模型,迁移学习越来越流行。该思路是在一个特定的环境中使用大量数据训练模型,然后对该模型的参数进行微调以适应另一个具有较小数据集的环境。假设大的数据集是成人语音,小的数据集是儿童语音,迁移学习可以提供一个精准匹配两个数据集的模型。而如果您想训练的模型是以成人语音为主,同时包括少量的儿童语音,那么准确性就会降低。在一种环境中进行大数据集训练,然后将数据微调并转移到另一个具有较少数据的环境中,这一组合非常有效。Eric 在他的论文《评估和改进儿童定向自动语音识别》中阐释了关于这方面的进展。
预训练神经网络遵循了同样的思路,在一个任务或数据集上训练模型,然后将这些参数转移到另一个任务或数据集上进行不同的模型训练。以 ChatGPT 为例,(ChatGPT 中的“P”代表预训练),它通过大量互联网对话数据进行了预训练,因此能够回答常规问题,并能根据提供给它的额外语境来更好地适应当前对话。这为该模型发展提供了有利条件,避免了从零开始,因为您只需少量数据就能创建强大的模型。
如今,许多 AI 研究人员都专注于生成式 AI。这不仅源于 ChatGPT 所带动的热潮,还因为生成式 AI 在医疗保健和其他行业具有潜在的深远影响。
为所需之人提供帮助
根据美国言语语言听力协会(American Speech-Language-Hearing Association)的数据,美国有超过 100 万儿童在学校接受专业的言语和语言障碍帮助。Eric 表示,总体而言,8% 的儿童存在语言发育迟缓或障碍问题。
“您当前无法在市场上接触到儿童言语治疗技术。因为该技术尚未实现,但它尤为重要,尤其对低收入家庭的患儿而言。”Eric 表示,对儿童进行治疗评估至少需要两小时,但美国政府可能只会承担 30 分钟的费用。
“电脑可以承担很多工作,为治疗师腾出时间来做更长远的规划和更有针对性的治疗。”
学习障碍资源基金会 (Learning Disabilities Resources Foundation)认为,患有学习障碍(如阅读障碍)的儿童也可受益于语音转录文字技术。正如巧妙地利用语音转录文字技术帮助 Eric 的祖母参与到交谈中,这项关键 AI 技术还有大量尚待开发和探索的应用空间。
赋能生成式AI和SR技术发展
如今,美光正在开发密度更高、速度更快的内存和存储,助力手机取代云端直接进行语言处理,以节省数据传输时间。
为了提升终端设备的性能,美光低功耗 LPDDR5X内存具有双倍数据传输速率,可实现功耗与性能的平衡和流畅的用户体验。LPDDR5X 移动内存采用了业界先进技术,峰值速度可达 8.533 GB/秒,较上一代产品提高 33%。LPDDR5X 的高速与高带宽对于实现高性能终端生成式 AI 至关重要。
借助生成式 AI,SR 技术的处理速度和准确度逐渐接近人脑,但距离真正实现目标还存在较大困难,尤其是在处理儿童语言和发音问题,以及帮助听力或语言障碍者。Eric 正在进行的研究能够切实改善生成式 AI 技术,丰富全人类生活体验。
生成式 AI 通过深度学习正在将语音转化为更加自然的文字。过去,AI 模型擅长挖掘大量数据、识别模式、诊断并确定原因;如今,生成式 AI 能够“读取”文字,并通过数据推断人类交流的语境。本质上,生成式 AI 是在“训练”自己。为了做到这一点,AI 需要能同时访问并获取大量数据,并从海量内存中提取数据以做出适当的响应。美光正在积极推动这些技术进步。
美光高密度 DDR5 DRAM 模块和 TB 级 SSD 存储可提供超高速度与超高带宽,满足在数据中心训练生成式 AI 模型的需求。最新发布的第二代 HBM3 (HBM3E)进一步提升了性能,容量扩大超过 50% ,带宽超过 1.2 TB/秒,可将百万亿级参数的 AI 模型训练时间缩短 30% 以上。随着这些技术的速度和准确度不断提高,未来,更多的语言障碍人士将能进行正常的沟通,发出自己的声音。
Eric 预测:“在不久的将来,我们将看到生成式 AI 和 SR 技术在性能上取得飞跃式发展。我很高兴能看到这项技术不断丰富全人类生活体验。”
-
内存
+关注
关注
8文章
3080浏览量
74549 -
AI
+关注
关注
87文章
32332浏览量
271431 -
美光
+关注
关注
5文章
718浏览量
51604
原文标题:美光高性能内存与存储,推动 AI 丰富残障人士生活体验
文章出处:【微信号:gh_195c6bf0b140,微信公众号:Micron美光科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
美光加入16-Hi HBM3E内存竞争
美光科技推出新款存储解决方案

美光高管:AI PC存储远超“基准要求”,两大策略应对数据中心“存储池”

美光高管看2024年AI数据中心、AI PC的存储趋势
美光MRDIMM内存发布,加速数据中心工作负载
美光科技推出多路复用双列直插式内存模块(MRDIMM)
美光内存助力未来AI技术更强大、更智能
美光率先出货用于 AI 数据中心的关键内存产品

以信任为基,围绕AI,美光推动存储革命






 工商网监
工商网监
评论